多模态ai模型评估:冗余测试的系统性分析
近期,上海ai lab、上海交大和浙江大学的研究团队发现,当前流行的多模态大模型基准测试存在大量冗余。该团队对20多个主流基准和100多个模型进行了系统性分析,结果显示,许多测试的效率低下,存在大量重复劳动。
△图表 1 quick look
研究发现,减少一半的测试实例,并不会显著影响模型排名。一些任务,例如图像情感和社会关系,其评估能力存在高度重叠;而像名人识别这样的知识型任务,则相对独立。
研究方法
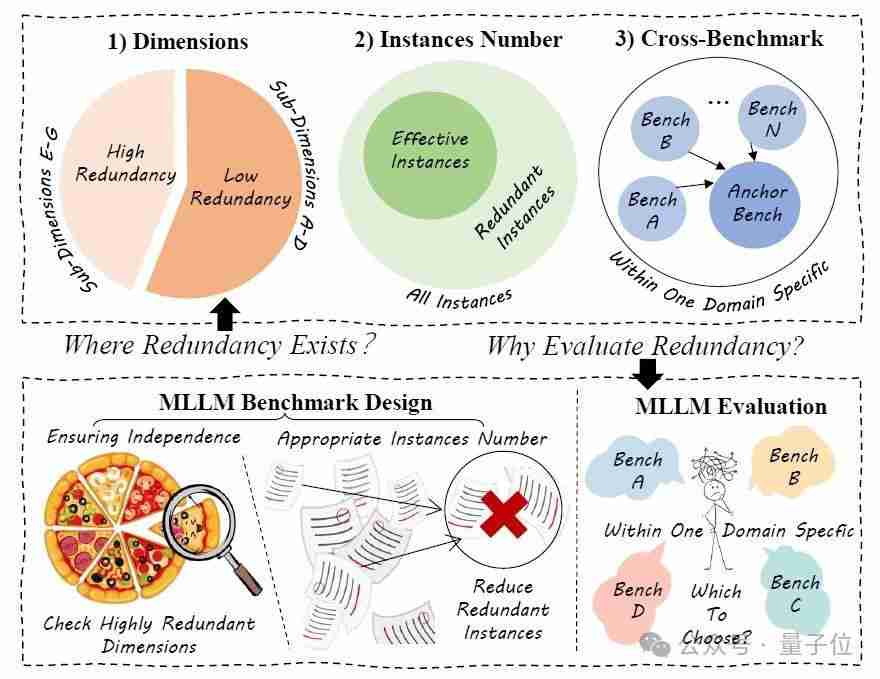
多模态大模型的性能评估依赖于复杂的基准测试。然而,研究团队发现基准测试本身存在冗余:一些维度虽然名称不同,但测试能力高度相似;一些实例高度相似,信息冗余;一些领域内的基准也存在重叠。
为此,研究团队提出了一个衡量基准冗余度的框架,涵盖三个层面:
- 维度冗余: 评估不同维度间的排序相似性,相似性越高,冗余度越高。
- 实例冗余: 通过随机抽取实例子集,计算其与完整数据集排序的相关性,相关性越高,冗余度越高。
- 跨基准冗余: 评估不同基准间的排序相关性,相关性越高,冗余度越高。
该框架利用斯皮尔曼排名相关系数(srcc)、皮尔逊线性相关系数(plcc)和r²分数来量化相关性。 此外,研究还进行了top-k分析,分别分析了性能最佳和最差的模型的冗余情况。
实验结果
研究团队以mmbench基准测试为例,分析了维度冗余。结果显示,图像情感和社会关系任务高度冗余;结构化图像-文本理解与空间关系、ocr和自然关系任务也存在显著冗余;而名人识别任务则相对独立。 top-50模型的维度冗余度低于bottom-50模型,这表明高性能模型在不同任务上的表现差异更大。
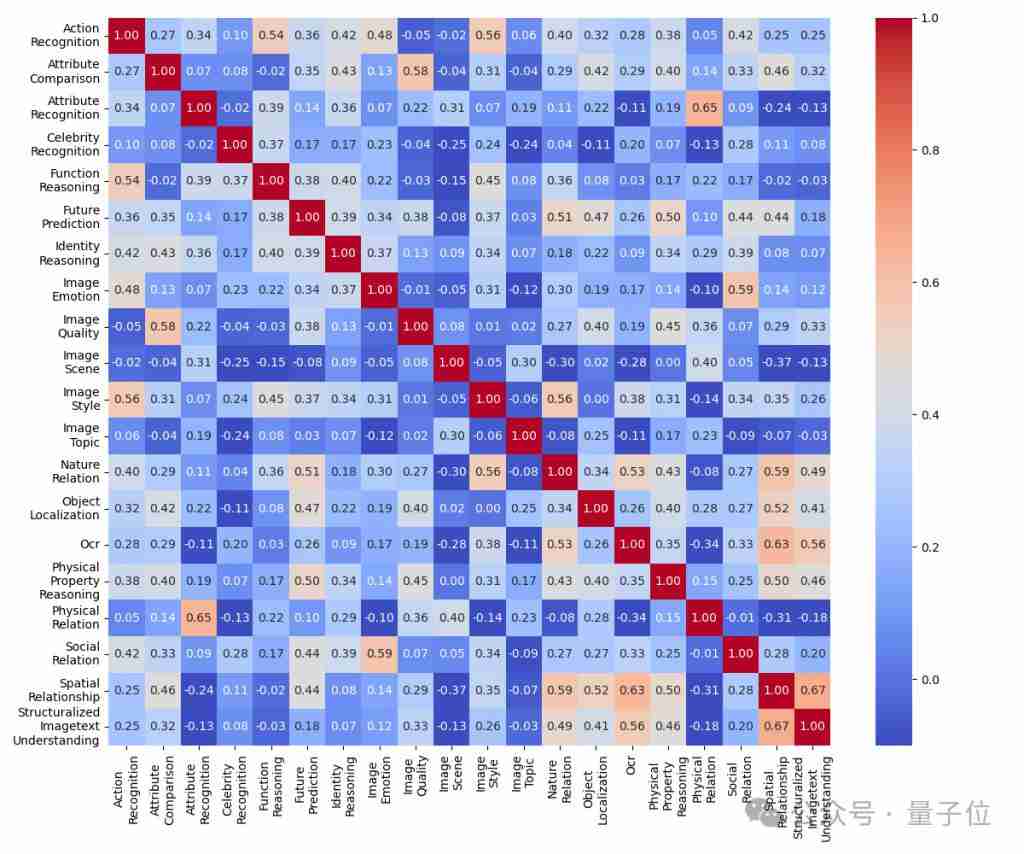
△ 图表 3 mmbench top-50 srcc 子维度热图
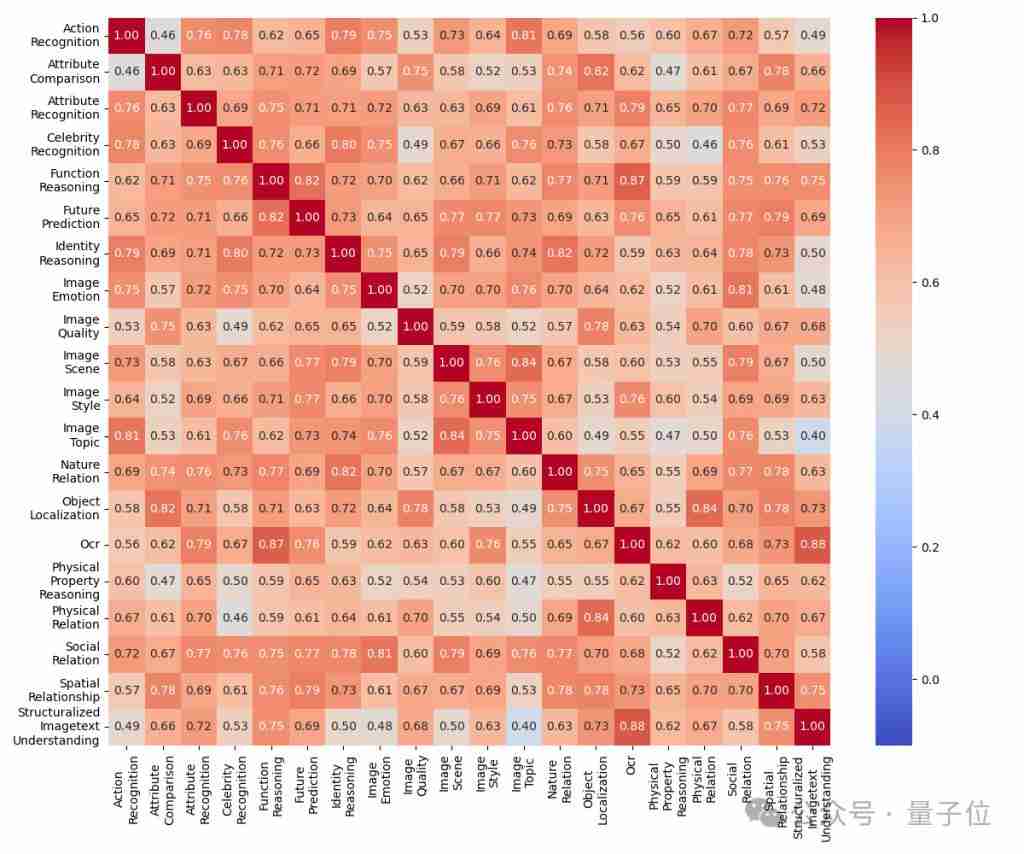
△ 图表 4 mmbench bottom-50 srcc 子维度热图
实例冗余分析显示,至少50%的实例是冗余的,减少一半实例不会显著影响排名。 bottom-50模型所需的实例数量少于top-50模型。
跨基准冗余分析以数学领域为例,研究发现不同数学基准测试的相关性差异较大,mathvista基准测试的冗余度最低。 通过去除mathvista中与数学能力关联性较弱的任务,其与其他基准的冗余度显著增加。
结论与建议
这项研究揭示了多模态大模型基准测试中普遍存在的冗余问题,并提出了一个衡量冗余度的框架。 该框架可以用于优化基准设计,提高评估效率,并最终构建更精简有效的评估生态系统。 研究建议根据领域核心能力和独特能力,设计更有效的基准测试,减少冗余,提高评估效率。
论文链接:https://www.php.cn/link/ffb5597397de30f24dfafbf479c92861
github 链接:https://www.php.cn/link/ffb5597397de30f24dfafbf479c92861
以上就是你正在做的大模型评测,可能有一半都是无用功的详细内容,更多请关注代码网其它相关文章!




发表评论