1、需求
老项目,实时数据还是用mysql去存储的,而且又没有定时去清理数据的程序。目前这些实时数据只需保留近半年的即可。
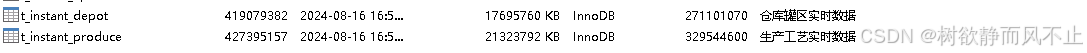
其他几张实时表数据量没有这么夸张。
我随即用
delete from table_name where id < 39000000 limit 10000
但是几亿条记录用这个方法太慢了。
2、方案
虽然之前也处理过类似问题,但还是随手问了一下ai,有无更优解。
在mysql中删除一个大表(例如含有几亿条记录)中的数据时,需要特别注意操作的性能和对系统的影响。如果您的目标是删除半年前的数据,您可以采用以下几种策略来高效地完成这项任务:
1. 使用 delete 语句分批删除
一种常见的方法是使用 delete 语句,并通过分批删除数据来减轻数据库的压力。这可以通过在 delete 语句中添加 limit 子句来实现。
示例 sql 语句
-- 定义每批删除的数量
set @batch_size = 100000; -- 每次删除 10 万条记录
set @counter = 0;
-- 确定半年前的日期
set @six_months_ago = date_sub(curdate(), interval 6 month);
-- 分批删除数据
repeat
delete from your_table
where time < @six_months_ago
limit @batch_size;
set @counter = @counter + 1;
until @counter = 0 end repeat;2. 使用 inplace alter table
对于innodb表,可以使用 alter table 来删除数据,这通常比 delete 更快。然而,此方法要求您能够确定删除的行不会被引用(例如通过外键)。此外,这种方法可能不是所有版本的mysql都支持。
示例 sql 语句
-- 确定半年前的日期 set @six_months_ago = date_sub(curdate(), interval 6 month); -- 创建一个临时表,只包含需要保留的数据 create table temp_table as select * from your_table where time >= @six_months_ago; -- 删除原始表 drop table your_table; -- 重命名临时表为原始表的名字 rename table temp_table to your_table;
3. 使用 truncate table 和重新插入数据
如果您可以接受删除所有数据并重新插入数据,那么可以使用 truncate table 来清空整个表,然后只插入最近六个月的数据。这种方法适用于那些可以承受完全清空表的场景。
-- 确定半年前的日期 set @six_months_ago = date_sub(curdate(), interval 6 month); -- 清空表 truncate table your_table; -- 重新插入最近六个月的数据 insert into your_table select * from your_table where time >= @six_months_ago;
注意事项
- 备份数据:在执行任何大规模删除操作之前,一定要做好数据备份以防万一。
- 监控性能:在执行删除操作时,应密切监控mysql服务器的性能指标,如cpu使用率、磁盘i/o等。
- 禁用外键检查:如果表上有外键约束,可以暂时禁用外键检查。
- 禁用自动提交:在开始删除操作之前,可以关闭自动提交,然后在删除完成后手动提交事务。
示例 sql 脚本
以下是一个完整的sql脚本示例,使用分批删除的方式删除半年前的数据:
-- 设置变量
set @batch_size = 100000; -- 每次删除 10 万条记录
set @counter = 0;
-- 确定半年前的日期
set @six_months_ago = date_sub(curdate(), interval 6 month);
-- 分批删除数据
repeat
delete from your_table
where time < @six_months_ago
limit @batch_size;
set @counter = @counter + 1;
until @counter = 0 end repeat;总结
选择哪种方法取决于您的具体需求和资源。如果数据量非常大,建议先在一个较小的数据集上测试所选方法的性能,然后再应用到整个表。此外,在执行此类操作时,最好在业务低峰期进行,以减少对应用程序的影响。
看来也没有更好的办法,还是这些老办法。
3、实战
先新建一张copy的表。
注意:新建表的自增索引id,还是会从1开始的。
create table new_table_name like existing_table_name;
接下来二个方案
1、实时数据不能停的,先改名,把名称互换。等数据插入一波,再启动迁移。主要是为了插入一波后自增索引自动调整。避免冲突
rename table temp to users;
2、实时数据能停的,那么就先停掉。再名称互换,再改动自增索引起点值。这时候其实可以开启插入程序了。
3.1转移
一张表近半年的数据是从390000000差不多开始。那么就好处理了
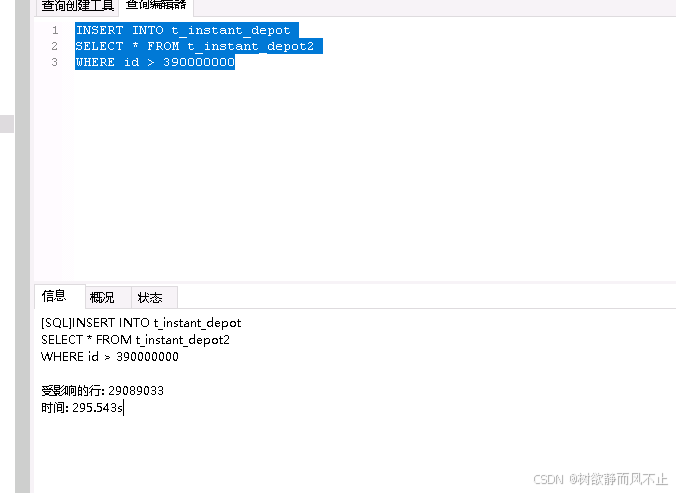
几千万条数据也是比较快的。
另一张表更大,有近1-2个亿的数据,那么我是2kw-3kw 批量一次,也就半小时。即可完成。
到此这篇关于mysql删除几亿条数据表中的部分数据的方法实现的文章就介绍到这了,更多相关mysql删除亿条数据表部分数据内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论