测一测现有 ai 生成视频是否符合物理运动规律!
来自阿里 - 高德、中科院的研究人员提出一个面向感知对齐的视频运动生成基准。
名为vmbench,是首个开源的运动质量评测基准,通过整合运动评估指标与人类感知对齐的评测方法,揭示现有模型在生成物理合理运动方面的不足。
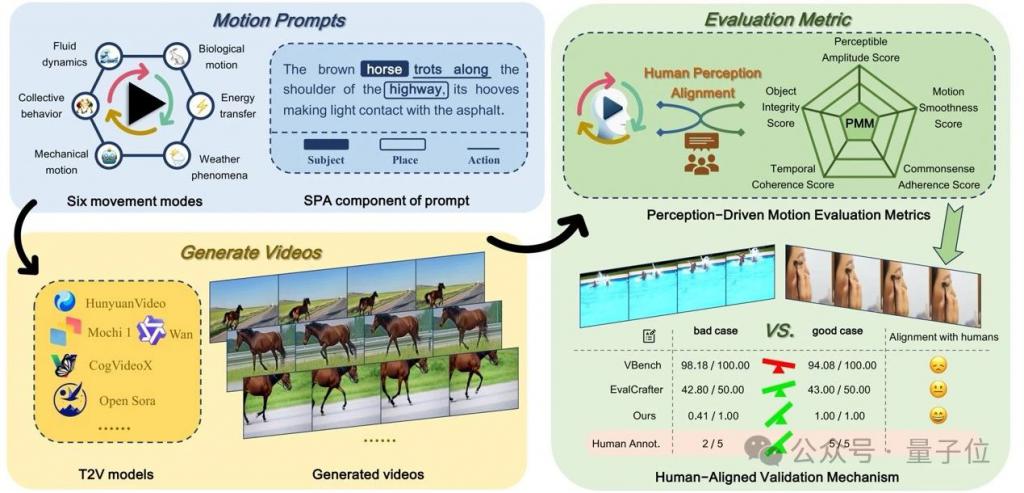
△图 1 vmbench 的整体结构
新基准测试涵盖了六种主要的运动模式类别,每个提示都构建为围绕三个核心组件(主体、地点和动作)的综合运动。
作者提出了一种新颖的多维视频运动评估方法,包含五个源自感知偏好的以人类为中心的质量指标。利用由流行的 t2v 模型生成的视频进行了系统的人类评估,以验证其指标在捕捉人类感知偏好的有效性。
总体而言,vmbench 具有以下几大优势:
基于感知的运动评估指标:作者从人类感知的角度出发,设计了五个核心维度,并据此制定精细化的评估指标,从而更深入地分析模型在运动质量上的优势与不足。
基于元信息的运动提示生成:作者提出一种结构化的方法,通过提取元信息、利用 llm 生成多样化的运动提示,并结合人机协同验证进行优化,最终构建了涵盖六大动态场景维度的分层提示库。
人类感知对齐的验证机制:作者提供人类偏好标注来验证基准的有效性,实验结果表明,其评估指标相较于基线方法,在 spearman 相关性上平均提升 35.3%。这是首次从人类感知对齐的角度对视频运动质量进行评估。
此外,团队已将 vmbench 代码及相关资源开源至 github。

以下是更多细节。
感知对齐的评估体系
视频动态生成的评估面临两大核心挑战:
现有指标未能充分对齐人类感知,且评测提示的多样性有限,导致模型动态生成潜力未被充分探索。
为此,团队提出 vmbench ——首个融合感知对齐指标与多样化动态类型的视频运动评测基准。
人类观察视频时,首先基于先验经验和物理规律构建场景的整体理解,随后选择性关注运动物体的平滑性与时序一致性(尤其在遮挡场景)。
受此分层感知机制启发(图 2),pmm 设计了从全局到局部的五维评估体系:
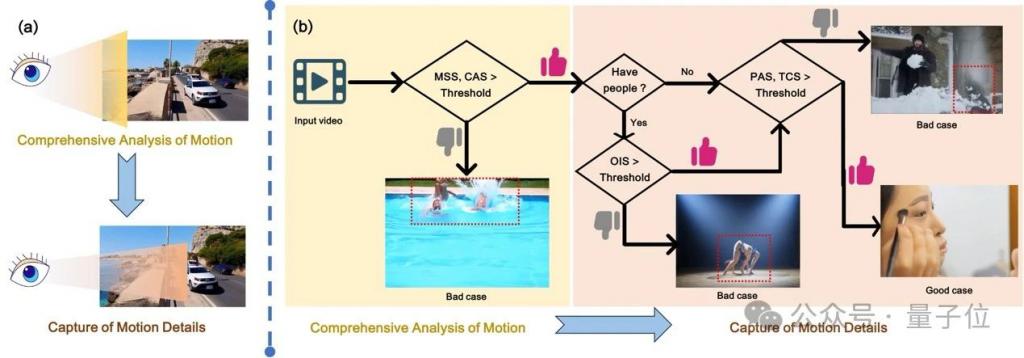
△图 2 用于评估视频运动的指标框架
上图框架灵感源自人类对视频中运动感知的机制。(a)人类对视频中运动的感知主要涵盖两个维度:运动的综合分析和运动细节的捕捉。(b)作者提出的用于评估视频运动的指标框架。
具体而言,mss 和 cas 对应于人类对运动的综合分析过程,而 ois、pas 和 tcs 则对应于运动细节的捕捉。
1、常识遵守性评分(cas)
通过构建多层级分类模型量化视频内容是否符合物理规律。
具体流程包括:
首先从主流生成模型中收集 10,000 个视频构建数据集,结合 videoreward 模型对视频质量进行五级分类(bad 到 perfect);随后采用 videomaev2 架构的时空建模网络预测视频的常识合理性概率分布,最终通过加权平均各类别概率得出综合评分。
该指标解决了传统方法对物理规律违反(如物体反重力运动)的漏检问题。
2、运动平滑度评分(mss)
针对传统光流法对视觉感知不敏感的问题,提出场景自适应的质量骤降检测机制。
基于 q-align 美学评分模型,分析相邻帧间的质量降低幅度,当超过动态阈值(通过 kinetics 等真实视频统计建模获得)时判定为异常帧。
最终以异常帧占比的补数作为平滑度得分,有效捕捉人类敏感的低帧率卡顿和高动态模糊。
3、对象完整性评分(ois)
为检测运动中的非自然形变(如人体关节错位),基于 mmpose 提取关键点轨迹,结合解剖学约束规则(如四肢长度比例容差)分析形状稳定性。
通过统计自然运动数据集设定各部位形变阈值,计算所有帧中符合解剖学约束的比例。
相比仅关注语义一致性的 dino 方法,该指标更贴近人类对肢体协调性的敏感度。
4、可感知幅度评分(pas)
通过多模态定位技术分离主动运动主体与背景位移。
首先用 groundingdino 锁定语义主体,借助 groundedsam 生成时序稳定的实例掩膜,再通过 cotracker 追踪关键点位移轨迹。
结合场景类型(如机械运动 vs. 流体运动)设定感知敏感阈值,计算帧级位移幅度与阈值的归一化比值。
该方法克服了传统光流法因相机运动导致的幅度高估问题。
5、时间一致性评分(tcs)
针对物体异常消失 / 出现问题,提出轨迹验证双阶段检测。
第一阶段用 groundedsam2 实现像素级实例分割与跨帧 id 追踪,记录物体的可见状态;第二阶段通过 cotracker 追踪物体运动轨迹,构建连续性规则(如遮挡重现需满足空间连贯性),过滤合法消失事件 / 出现(如移出画面边界)。
最终以异常消失实例占比的补数作为评分,相比 clip 特征相似度方法更加贴合人眼的视觉感知。
整体的评估流程如图 3 所示。
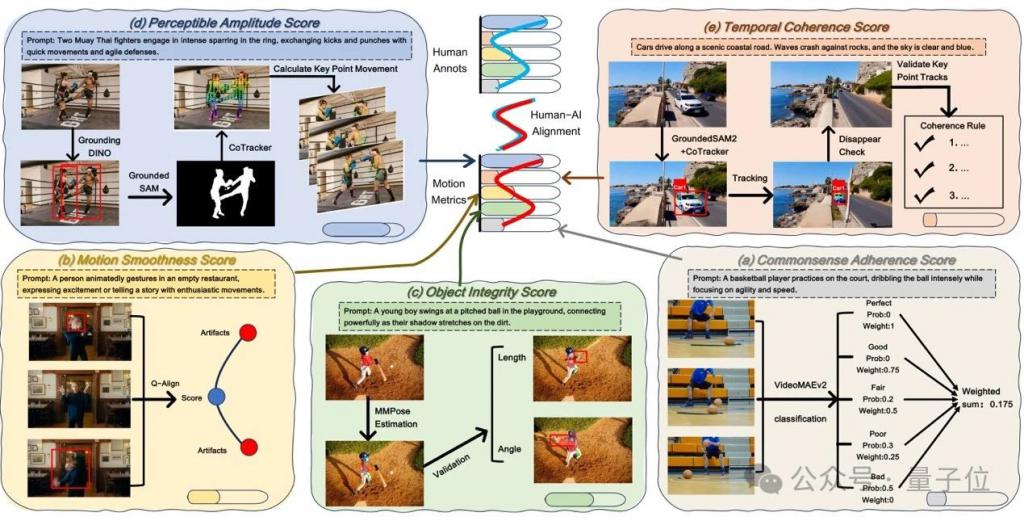
△图 3 感知驱动的运动指标(pmm)框架。
pmm 包含多个评估指标:常识一致性得分(cas)、运动平滑度得分(mss)、物体完整性得分(ois)、可感知幅度得分(pas)以及时间连贯性得分(tcs)。
上图(a-e)是每个指标的计算流程图。
pmm 生成的得分呈现出与人类评估一致的变化趋势,表明与人类感知高度契合。
元信息引导的 prompt 自动生成
针对现有基准因提示类型单一而无法充分评估模型运动生成能力的问题,作者提出了元信息引导的 prompt 生成框架(mmpg),通过结构化元信息提取与大语言模型协同优化,构建了目前覆盖最广、描述最细的运动提示库,涵盖六大动态场景维度(如生物运动、流体动态等)。
该框架包含以下核心步骤:
元信息结构化提取
作者将运动描述拆解为三个核心元信息要素:主体(subject,s)、场景(place,p)、动作(action,a)。
基于现有视频文本数据集,利用大语言模型(qwen-2.5)构建包含数万条元信息的数据库,并通过多维度扩展策略提升多样性:
主体扩展:分类为人类、动物、物体,结合目标检测模型筛选可识别实体,并通过 gpt-4o 生成不同实体数量(单 / 多主体)的变体描述;
场景扩展:从 places365 等数据集中提取多样化场景,过滤重复或模糊的地理信息;
动作扩展:从动力学数据集中采样真实动作,并通过 llm 推理生成动物与物体的合理运动模式。
自优化提示生成与验证
从元信息库中随机组合三元组(s,p,a),利用 gpt-4o 评估其逻辑一致性,并通过迭代优化生成自然流畅的运动描述。
例如,将 " 人类(s)- 厨房(p)- 切菜(a)" 转化为 " 一位厨师在现代化厨房中快速切菜,刀具与砧板碰撞发出规律声响 "。
为提升物理合理性,作者引入双阶段过滤机制:
llm 逻辑验证:通过 deepseek-r1 推理剔除违背物理规律或语义矛盾的描述(如 " 汽车在湖面飞行 ");
人机协同校验:结合专家标注与自动化筛选,从 5 万候选提示中精选 1,050 条高质量提示,确保覆盖复杂交互(如多主体协作)、精细动作(如手指弹奏)及特殊场景(如微观流体)。
构建提示词的流程如图 4 所示。
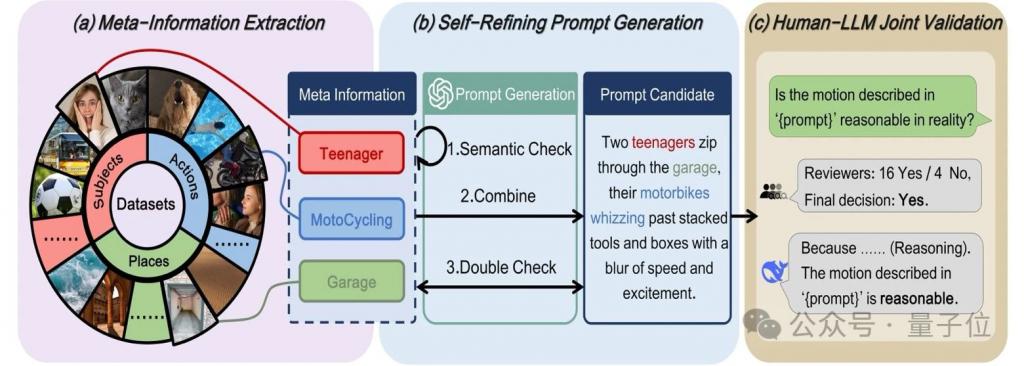
△图 4 元指导运动提示生成(mmpg)框架。
mmpg包含三个阶段:
元信息提取:从 vidprom、didemo、msrvtt、webvid、place365 和 kinect-700 等数据集中提取主体、场所和动作信息。
自优化提示生成:基于提取的信息生成提示,并通过迭代优化提示内容。
人类 -llm 联合验证:通过人类与 deepseek-r1 的协作过程验证提示的合理性。
作者用这样的方式一共构建了 1050 条高质量的提示词,其具体的统计如图 5 所示。
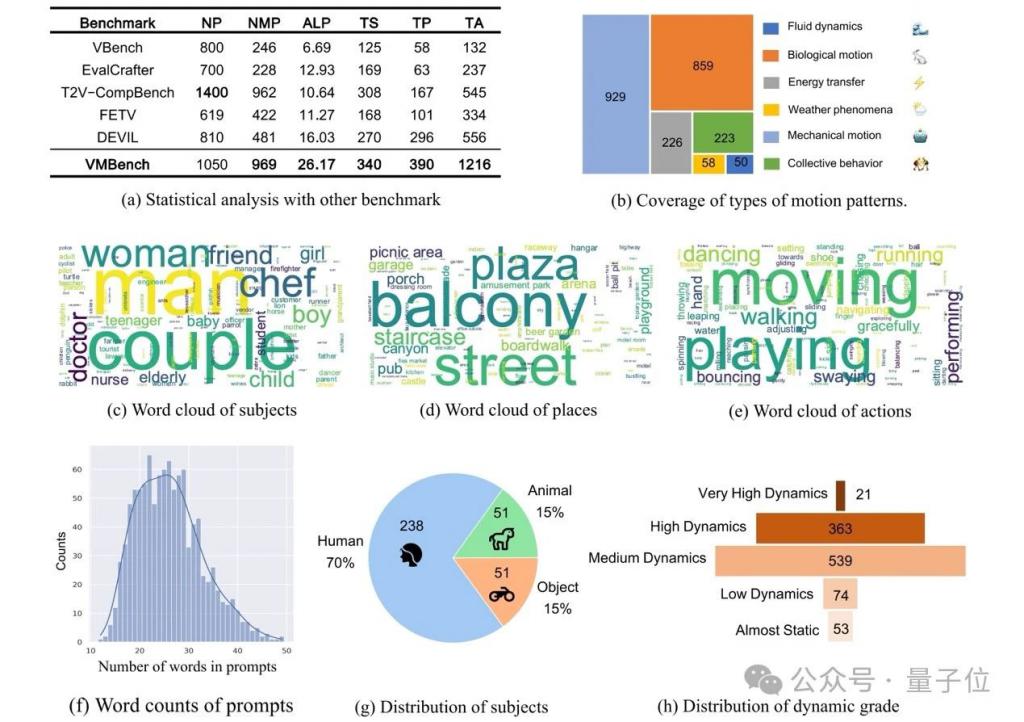
△图 5 vmbench 中运动提示的统计分析
( a-h ) :从多个角度对 vmbench 中的提示进行统计分析。
这些分析展示了 vmbench 的全面评估范围,涵盖运动动态、信息多样性以及对现实世界常识的符合度。
实验实验设置
研究基准测试对六个流行的文本生成视频(text-to-video, t2v)模型进行评估,包括 opensora、cogvideox、opensora-plan、mochi 1、hunyuanvideo 和 wan2.1。
为了提供更丰富的运动类型,作者构建了 mmpg-set(meta-guided motion prompt generation 数据集),该数据集涵盖六种运动模式,共 1,050 个运动提示(prompts),用于评估模型的运动生成能力。
每个模型基于 mmpg-set 生成 1,050 个视频,最终总计 6,300 个视频。
为了保证公平比较,作者严格按照各模型官方项目的超参数设定进行实验。每个提示词(prompt)仅生成一段视频,并且固定初始种子(seed)以保证可复现性。推理过程运行在 8 张 nvidia h20 gpu 上。
此外,作者从每个模型的输出结果中随机抽取 200 段视频,共 1,200 段视频,用于人类感知对齐验证实验(human-aligned validation experiments)。
以下是比较指标(comparison metrics)。
1 ) 基于规则的指标
基于规则的方法评估四个维度:
可感知动态幅度(perceptible amplitude):采用 raft 光流幅值分析 结合 结构运动一致性检测(基于 4 帧 ssim 平均值) 进行评估,遵循既定评测协议。
时间一致性(temporal coherence):使用 dino 和 clip 特征跟踪,通过计算 相邻帧余弦相似度 来衡量帧间一致性。
运动平滑度(motion smoothness):结合 插值误差与 dover 视频质量评估的混合方法进行测量。
物体完整性(object integrity):通过 光流扭曲误差(optical flow warping error)与 语义一致性检查 进行双重验证。
2 ) 多模态大语言模型(mllm)评估
团队选取五个前沿的多模态大模型进行运动评测:
llava-next-video
minicpm-v-2.6
internvl2.5
qwen2.5-vl
internvideo2.5
这些模型的评估采用标准化流程,即对每个视频以 2 帧 / 秒(fps)的采样率进行处理,以保持运动模式完整性并控制计算成本。
mllm 评估涵盖五个关键维度:运动幅度(amplitude)、时间一致性(coherence)、物体完整性(integrity)、运动平滑度(smoothness)、常识性(common-sense adherence)。
每个维度采用 1-5 分制进行评分。为保证公平性,在所有模型间保持 一致的帧序列与评估标准。
接下来是评估指标(metrics)。
1 ) 斯皮尔曼相关系数(spearman correlation)
斯皮尔曼秩相关系数(spearman ’ s rank correlation coefficient, ρ)用于衡量两个变量之间的单调关系。该方法是非参数统计方法,特别适用于变量不服从正态分布的数据集。
与 皮尔逊相关系数(pearson correlation) 不同,皮尔逊主衡量线性关系,而 斯皮尔曼相关性关注基于排名的关联性,因此对异常值(outliers)更加鲁棒,并适用于有序数据(ordinal data) 或非线性依赖关系的场景。
2 ) 准确性(accuracy)
为了验证运动评估指标与人类偏好的一致性,作者在 1,200 段带有人类标注的视频(200 个提示 × 6 个模型)上进行了成对比较(pairwise comparisons)。
对于每个提示(prompt),作者比较所有 15 种可能的视频对(由不同模型生成的 6 选 2 组合),最终得到 3,000 组视频对进行评估。
人类偏好标注(ground truth)通过比较五个核心维度(ois, mss, cas, tcs, pas)下的平均专家评分确定。得分较高的视频被认定为 " 偏好样本 "(preferred sample)。
pmm 评估指标计算各视频在相同标准下的综合 pmm 评分,并基于此进行视频对比。
一致性准确率(alignment accuracy)计算 pmm 偏好与人类标注结果一致的比率(不包括评分相同的样本,以确保决策的明确性)。
这一过程确保本研究的评估指标能够更好地对齐人类感知,并提供精确的运动质量评估方法。
实验结果
人类感知对齐验证机制(human-aligned validation mechanism)
作者邀请了三位领域专家对每个样本进行独立标注,基于 pmm 评估标准,包括可感知动态幅度(perceptible amplitude, pas)、时间一致性(temporal coherence, tcs)、物体完整性(object integrity, ois)、运动平滑度(motion smoothness, mss)和常识一致性(commonsense adherence, cas)。
最终,共收集到 6,000 条详细评分,并达到了高度的标注一致性(high inter-annotator agreement)。
为了评估评测指标与人类感知的一致性,作者计算了斯皮尔曼相关系数(spearman correlation),用于衡量评测指标分数与专家评分之间的对齐程度。较高的 spearman 相关系数意味着更强的与人类感知的一致性。
与其他评测指标的比较(comparison with alternative metrics)
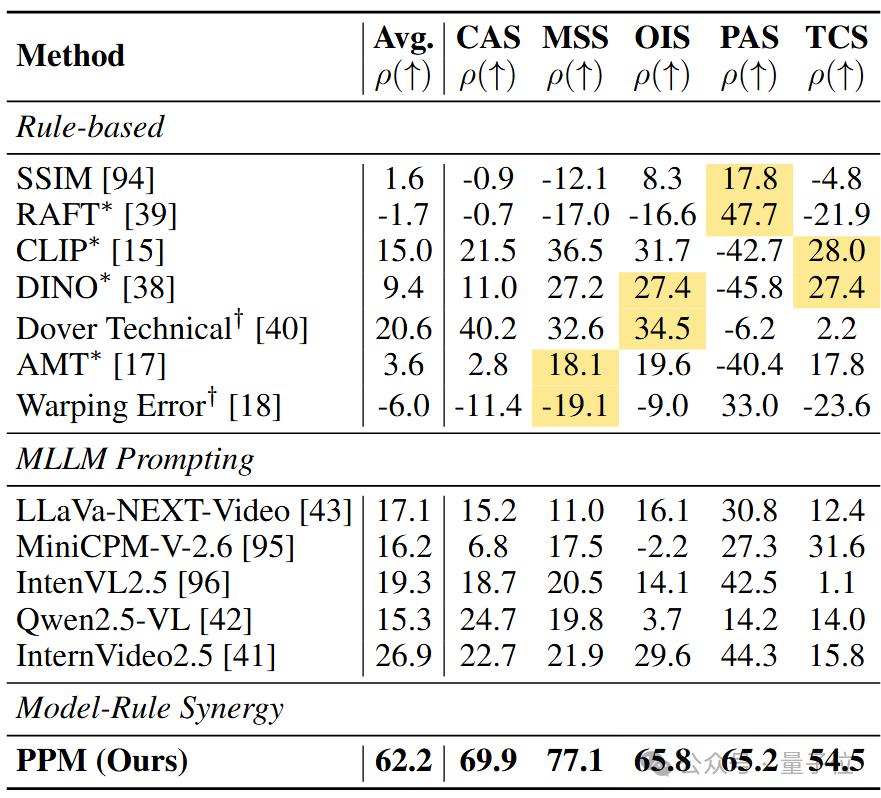
△表 1 基于斯皮尔曼相关系数(ρ × 100)的人类评分与评估指标之间的相关性分析
上标 * 和分别表示遵循 vbench 和 evalcrafter 的实现。在规则基(rule-based)方法中,黄色背景表示特定维度的基线。
从表 1 可以看出,在运动平滑度(mss) 评估方面,即便是先进的指标,如 amt(18.1%)和 warping error(-19.1%),在面对复杂形变时仍然表现出有限的区分能力,并产生了违反直觉的评估结果。
在物体完整性(ois) 评估中,也存在类似问题。例如,dino 的对齐度仅为 27.4%,而 dover 仅为 34.5%,二者都未能有效捕捉人类对运动中结构保持性的敏感度。
在可感知动态幅度(pas) 评估中,基于规则的方法,如 ssim 和 raft ,其人类对齐度分别仅为 17.8% 和 47.7%。
相比之下,本研究方法达到了 65.2% 的对齐度,表现出明显优势。对于时间一致性(tcs)评估,基于规则的指标,如 clip 和 dino,其对齐度仅为 28.0% 和 27.4%,无法准确反映人类对轻微不一致性的容忍度,同时也未能维持物理合理性。
而本研究评测方法达到了 54.5% 的对齐度,大幅领先。
与现有基准(vbench 和 evalcrafter)的比较
vbench 评测方法包含 raft、clip、dino 和 amt。
evalcrafter 采用 dover 技术评估和 warping error。
然而,从表中数据可以看出,与本研究方法相比,vbench 和 evalcrafter 的运动评估指标与人类感知的相关性明显较低,表明它们无法有效评估运动质量。
与多模态大语言模型(mllms)的比较
尽管多模态大模型(mllms)在物理适应性评分(pas)方面表现出一定能力(例如 internvideo2.5 取得 44.3%),但整体来看,mllms 在所有维度上的平均相关性仅为 10.0% - 30.0%。
这表明当前的 mllms 在运动质量评估方面存在根本性的不匹配(fundamental misalignment),难以准确对齐人类的感知标准。
消融实验
运动评估指标的消融研究(ablation study of motion metrics)
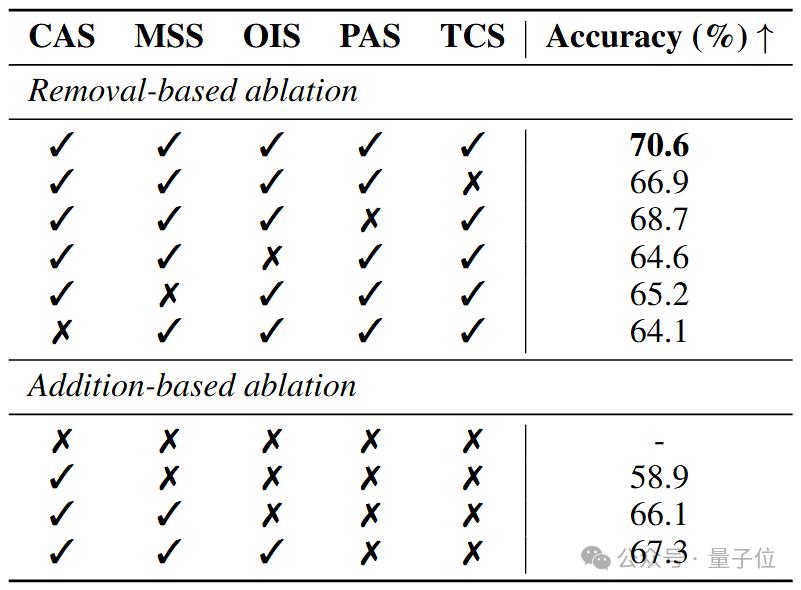
△表 2 本研究评价指标消融实验计算了不同度量组合相对于人类偏好的预测准确率(%)
基于移除的消融实验展示了单独去除每个度量的影响,而基于添加的消融实验则逐步加入各个度量,以观察其影响。
根据表 2,去除任意单一指标 都会导致整体评估准确率显著下降,凸显出 每个评估维度 在整体框架中的重要性。
值得注意的是,去除 cas(常识一致性,commonsense adherence, cas) 指标后,准确率下降最为显著,降至 64.1%,其影响超过其他单个维度的消融效果。
这表明 cas 指标在评估视频质量中的关键作用,并且高度契合人类在感知视频质量时优先关注的关键因素。
对于面向性能优化的变体(performance-oriented variants),作者模拟人类的感知信息处理流程,通过逐步增加评估维度,结果显示每新增一个评估维度,整体准确率均有显著提升。
这一结果不仅验证了增量评估方法的有效性,还进一步证明了本研究提出的评估框架与人类感知机制的一致性。
定性分析
pmm 评估与人类感知的一致性(alignment of pmm with human perception)
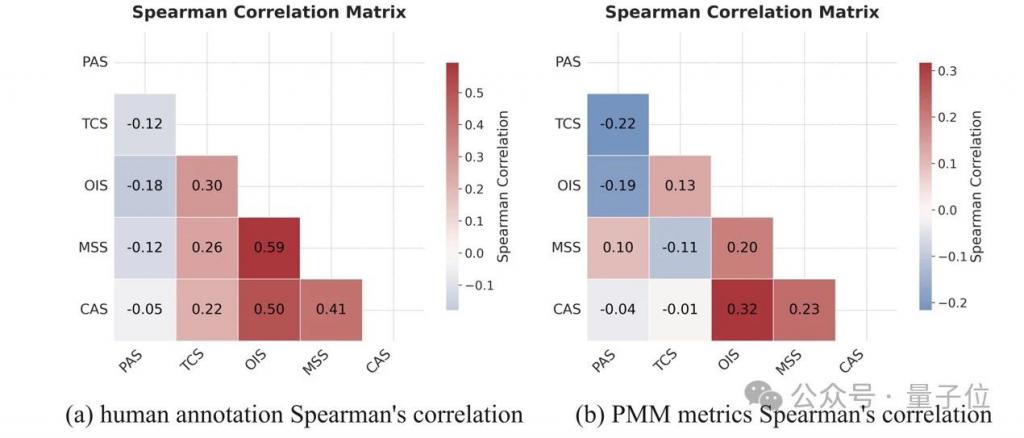
△图 6 不同评估机制下指标的相关性矩阵分析
( a ) 人类标注的斯皮尔曼相关性矩阵; ( b ) pmm 指标的斯皮尔曼相关性矩阵。
如图 6 所示,人类评分在五个评估维度(ois、cas、mss、tcs、pas)与 pmm 评估指标之间的相关性保持一致。
例如,ois(物体完整性)、cas(常识一致性)和 mss(运动平滑度)之间存在较强的相关性,而 pas(可感知动态幅度)与其它指标的相关性较弱。
具体来看:
图 6 ( a ) 显示,pas 与其它维度呈负相关,例如与 ois 的相关系数 ρ =-0.18。
可能的原因是,视频中的高动态振幅(high dynamic amplitudes)会导致形变和伪影,进而降低结构完整性(ois)和时间一致性(tcs)评分。
ois 与 mss 及 cas 之间存在较强的正相关性,分别为 ρ =0.59 和 ρ =0.50,表明 ois 能很好地反映物理合理性(physical plausibility)和运动合理性(motion rationality)。
tcs(时间一致性)与其它维度的相关性较低,表明该指标可提供更加独立和全面的评估视角。
pas 与结构 / 时间相关指标的负相关性挑战了传统基于光流(optical-flow-based)的视频运动评估框架,突显出在运动视频评估中,单独衡量运动幅度的重要性。
此外,图 6 ( b ) 显示,作者提出的评估指标相互关联性符合人类感知特性,进一步验证了 pmm 评估框架的合理性。
使用 pmm 评估视频生成模型(assessing video generation models with pmm)
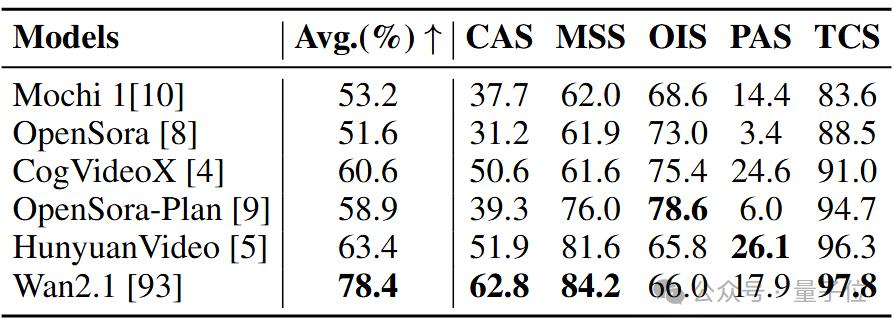
△表 3 视频生成模型在 vmbench 上的表现。
使用 vmbench 评估了六个开源视频生成模型。分数越高表示该类别的性能越优。
如表 3 所示,作者使用 pmm 评估指标对多个领先的视频生成模型进行了评测,包括 mochi 1、opensora、cogvideox、opensora-plan、hunyuanvideo 和 wan2.1。
评测结果表明,wan2.1 在运动视频生成方面表现最佳,其生成的视频在视觉真实性(realism)方面优于其它模型。
论文链接:https://arxiv.org/pdf/2503.10076
代码仓库链接:https://github.com/gd-aigc/vmbench
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明,告诉我们:
你是谁,从哪来,投稿内容
附上论文 / 项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

点亮星标
科技前沿进展每日见
以上就是ai 视频是否符合物理规律,量化基准来了,实现人类感知对齐的详细内容,更多请关注代码网其它相关文章!




发表评论