golang 实现比特币内核之处理椭圆曲线中的天文数字
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 76
在比特币密码学中,我们需要处理天文数字,这个数字是如此巨大,以至于它很容易超出我们宇宙中原子的总数,也许 64 位的值不足以表示这个数字,而...
Go中log包异或组合配置妙用详解
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 80
log 中的这种用法,你一定见过:log.setflags(log.ldate | log.ltime | log.llongfile)没见...
go集成gorm数据库的操作代码
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 84
一、什么是gormgorm 是一个用于 go 语言的 orm(对象关系映射)库,它提供了一种简单而强大的方式来与数据库进行交互。gorm 支...
深入理解Golang中的Protocol Buffers及其应用
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 88
初识protobufprotocol buffers简称protobuf,是一个无关语言,无关平台的用于序列化结构化数据的工具,于2008年...
通过client-go来操作K8S集群的操作方法
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 84
client-go一、client-go介绍1. 什么是client-go?client-go是kubernetes官方提供的,用于操作ku...
如何使用go实现创建WebSocket服务器
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 83
使用go语言创建websocket服务器可以利用现有的库来简化开发过程。gorilla/websocket 是一个非常流行且功能强大的库,适...
golang进行xml文件解析的操作方法
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 70
查阅了些资料自己记录一下一、小文件简单解析对于小文件的 xml 解析,我们可以使用 go 标准库中的encoding/xml包来实现。假设我...
使用Go语言编写一个NTP服务器的流程步骤
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 84
ntp服务介绍ntp服务器【network time protocol(ntp)】是用来使计算机时间同步化的一种协议。应用场景说明为了确保封...
Golang中类型转换利器cast库的用法详解
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 74
在golang开发中,类型转换是一个常见且不可避免的过程。无论是将字符串转换为整数,还是将接口转换为布尔值,类型转换都贯穿在代码的各个角落。...
go-zero创建RESTful API 服务的方法
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 77
在 go-zero 中,创建 restful api 服务可以通过 goctl 命令快速完成。go-zero 提供了一种高效的方式来生成服务...
Go 数据库查询与结构体映射的示例详解
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 94
下面是关于如何使用 go 进行数据库查询并映射数据到结构体的教程,重点讲解 结构体字段导出 和 db 标签 的使用。go 数据库查询与结构体...
go语言中的log 包示例详解
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 83
go语言的log包提供了用于记录日志的基本功能。相比fmt包,log包增加了时间戳、日志级别等日志管理功能,非常适合用于调试和记录运行信息。...
gorm 结构体中 binding 和 msg 结构体标签示例详解
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 76
binding 和 msg 是结构体标签(struct tags),主要用于数据验证和错误信息提示。它们通常与 gin 框架的 should...
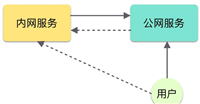
Golang实现内网穿透详解
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 76
我们经常会遇到一个问题,如何将本机的服务暴露到公网上,让别人也可以访问。我们知道,在家上网的时候我们有一个 ip 地址,但是这个 ip 地址...
Golang 并发编程入门Goroutine 简介与基础用法小结
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 83
一、什么是 goroutine?goroutine 是 golang 中的一种轻量级线程,用于实现并发操作。与传统线程相比,goroutin...
Go语言使用Zap轻松搞定结构化日志
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 81
在开发现代应用程序时,日志记录是一个不可或缺的部分。它不仅能帮助我们跟踪程序的运行状态,还能在出现问题时提供宝贵的调试信息。在 go 语言中...
Go语言使用sqlx操作MySQL
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 80
go 语言以其高效和简洁的语法逐渐受到开发者的青睐。在实际开发中,数据库操作是不可避免的任务之一。虽然标准库提供了 database/sql...
Go使用Redis实现分布式锁的常见方法
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 80
实现分布式锁的方法使用 redis 的set命令redis 的set命令支持设置键值对,并且可以通过nx和ex参数来实现原子性操作,从而实现...
如何在Go语言中高效使用Redis的Pipeline
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 82
在构建高性能应用时,redis 经常成为开发者的首选工具。作为一个内存数据库,redis 可以处理大量的数据操作,但如果每个命令都单独发送,...
获取Golang环境变量的三种方式小结
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 76
环境变量是应用软件参数配置的最佳方式,可以定义系统级,如开发、测试以及生成阶段。配置参数主要有数据库配置、第三方url等。因此环境变量对于开...
浅谈Golang的GC垃圾回收机制
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 85
前言在现代编程语言中,垃圾回收(garbage collection, gc)机制是一个至关重要的特性。它帮助开发者自动管理内存,避免内存泄...
基于golang编写一个word/excel/ppt转pdf的工具
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 72
需求公司客户有需求,需要转换doc文件为pdf文件,并且保持格式完全不变。工程师用各种java类库,无论是doc4j、poi还是aspose...
在Go中动态替换SQL查询中的日期参数的完整步骤
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 94
完整指南:在go中动态替换sql查询中的日期参数在处理数据库查询时,经常需要根据不同的输入条件动态地构造sql语句。尤其是在涉及日期范围的查...
Go语言如何在Web服务中实现优雅关机
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 79
在构建 web 服务时,我们往往会遇到一个棘手的问题:当我们想要停止服务时,如何确保正在处理的请求能够顺利完成,而不是突然中断? 这种技术被...
Go集成swagger实现在线接口文档的教程指南
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 82
安装swaggogo install github.com/swaggo/swag/cmd/swag@latest编写swagimport ...
基于Golang+Vue编写一个手机远程控制电脑的懒人工具
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 92
前言躺在床上投屏到电脑的时候, 调节音量和一些简单的操作还需要起身操作, 觉得麻烦, 就开发了这么一个小工具。思路go语言负责后端,负责模拟...
Go语言如何使用 Viper 来管理配置
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 81
在现代软件开发中,良好的配置管理可以极大地提升应用的灵活性和可维护性。在 go 语言中,viper 是一个功能强大且广泛使用的配置管理库,它...
Golang并发编程中Context包的使用与并发控制
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 79
一、简介在并发编程中,任务管理和资源控制是非常重要的,而golang 的context包为我们提供了一种优雅的方式来传递取消信号和超时控制。...
Go语言基本类型转换的实现示例
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 78
在go语言编程中,类型转换是一个常见的操作,它允许我们在不同的数据类型之间转换值。go语言提供了几种方式来进行类型转换,以满足不同的编程需求...
Go语言中未知异常捕获的多种场景与实用技巧
2024-11-25 15:13 | 分类:前端脚本 | 评论:0 次 | 浏览: 89
一、前言在go语言编程中,异常处理是确保程序健壮性的关键环节。与一些其他编程语言不同,go没有传统的try - catch结构化异常处理机制...