




一、引言
在高并发场景下,redis 以极致的内存操作速度成为缓存与nosql领域的首选。但随着业务发展,大key(bigkey) 问题逐渐显现,带来内存风险、性能瓶颈、集群失衡等隐患。系统性治理大key,是redis高可用运维的基础能力。
二、什么是bigkey?为什么是隐患?
2.1 定义
bigkey:指单个key的value体量巨大,如string类型大于10mb,list/set/hash/zset等容器元素数超过数万,或内存占用显著超标。
2.2 主要危害
| 影响点 | 具体表现 | 背后原理 |
|---|---|---|
| 内存风险 | oom、写入阻塞、重要key被淘汰 | redis主线程,内存分配/释放同步 |
| 集群失衡 | 单节点负载高、迁移难 | hash slot粒度,难细分拆迁 |
| 带宽抢占 | 读/同步大key时带宽激增,影响其他请求 | 大数据包、网络阻塞 |
| 主从同步阻塞 | del/expire等操作导致主线程卡顿,主从同步中断 | 释放大对象为阻塞操作 |
| 内存碎片/thp问题 | 大对象频繁释放,导致内存碎片和性能抖动 | jemalloc分配器、thp机制 |
三、bigkey识别原理与流程
3.1 识别原则
- 低侵入:用scan惰性遍历,避免阻塞业务。
- 类型分离:分别统计各类型key的长度/元素数量。
- 双维度分析:关注元素数与实际内存占用。
- 可配置扫描节奏:通过参数平衡扫描速度和业务影响。
3.2 流程图
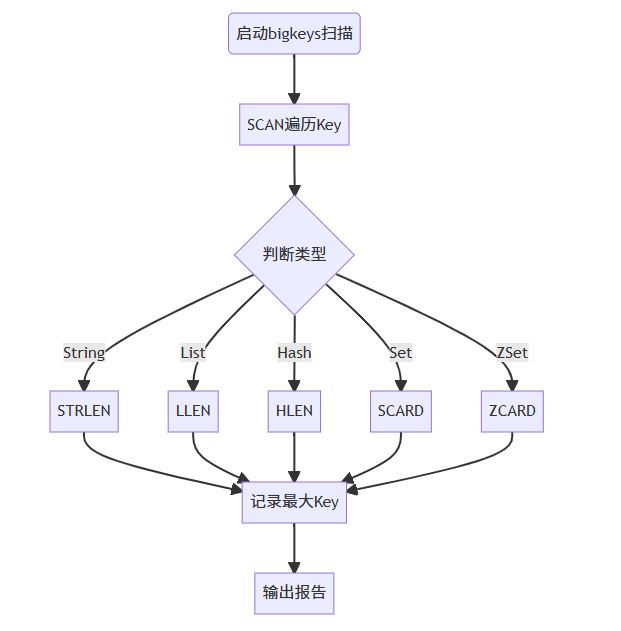
3.3 典型实现(redis-cli bigkeys)
核心流程伪代码:
while (1) {
keys = scan(cursor)
for (key in keys) {
type = type(key)
switch(type) {
case "string": size = strlen(key); break;
case "list": size = llen(key); break;
...
}
记录最大key及分布
}
if (cursor == 0) break;
usleep(间隔)
}
重点命令:
- scan:游标遍历,低阻塞
- strlen/llen/hlen/scard/zcard:类型专属长度命令
四、bigkey治理与优化策略
4.1 总体思路
- 预防优先:业务侧杜绝写入大key
- 合理拆分:大对象分片存储,按业务特征拆分
- 异步删除:unlink/lazyfree避免主线程阻塞
- 定期清理:定时维护容器长度
- 自动监控:扫描+报警体系
4.2 具体措施
1. 预防性控制
- 业务分片:大数据分块分key存储,如
bigkey:part:<n> - 容器分桶:hash/list等按业务id或时间窗口分桶
2. 安全删除大key
- unlink命令(异步释放,主线程快速返回)
redis> unlink bigkey
- lazyfree机制(配置项:
lazyfree-lazy-user-del yes)
3. 定期清理与自动化监控
- 容器类型定期扫描+删除
cursor = 0
while true:
cursor, fields = redis.hscan("myhash", cursor, count=1000)
for field in fields:
if should_delete(field):
redis.hdel("myhash", field)
if cursor == 0:
break
- 定时bigkeys扫描+阈值报警
4. 特殊场景专项治理
- list消息队列积压:设置
expire、定期ltrim等
五、业务实战案例
- 订单hash大key阻塞:订单明细异常积压,del操作阻塞主线程
- 解决策略:定期hscan+hdel无效字段,迁移unlink删除,升级redis开启lazyfree
六、与其他技术栈集成及高阶应用
- 中间件分片:如codis/自研proxy,避免单节点存大key
- 与消息队列结合:大对象分片后异步聚合
- 自动化治理平台:定期扫描、自动报警、智能分片
七、底层实现与源码剖析
7.1 del与unlink对比
| 命令 | 释放方式 | 主线程阻塞 | 适用场景 |
|---|---|---|---|
| del | 同步释放 | 是 | 小对象 |
| unlink | 异步后台释放 | 否 | 大对象 |
核心源码片段:
// del
int dbsyncdelete(redisdb *db, robj *key) {
// dict删除,decrrefcount同步释放
}
// unlink
int dbasyncdelete(redisdb *db, robj *key) {
// dict删除,指针加入后台线程
biocreatebackgroundjob(bio_lazy_free, ...);
}
7.2 内存管理与碎片
- jemalloc:大对象频繁分配/释放易碎片化
- thp问题:透明大页加剧性能抖动
- 建议:禁用thp、定期重启、升级jemalloc
八、调试与优化技巧
- 慢日志:关注set/del等操作耗时,排查大key
- 低冲击扫描:合理调整-i参数,避开高峰
- 内存分析工具:memory usage、memory doctor等
- 自动报警:prometheus+grafana集成
九、总结
- 识别靠scan,预防靠设计
- 治理靠拆分,优化靠异步
- 监控靠自动化,源码知根本
bigkey治理是redis稳定运行的“防火墙”。只有深入理解主线程模型、内存机制和命令实现,结合业务特点结构化预防与优化,才能支撑redis系统的可持续演进。
以上就是redis大key(bigkey)问题识别与解决全解析的详细内容,更多关于redis大key问题识别与解决的资料请关注代码网其它相关文章!