




数据透视表是 excel 最强大的数据分析工具之一,能快速实现海量数据的动态汇总、多维分析与交互式展示。用户能在不同角度上查看和比较数据,深入研究数据之间的关系和模式。 但是 excel 同其他 office 软件一样,想要高效办公就得付出大量时间和精力去学习高阶使用,而人工处理也在面对大量数据时显得力不从心。
幸运的是,利用好 python 等编程语言,我们就可以使用几行浅显易懂的代码实现全自动处理数据,并生成所需 excel 文件。而 python 的 spire.xls 库就是这样一个绝佳的工具。 本文将介绍如何使用 python 在 excel 中应用数据透视表。
前期准备
为了实现纯代码操控 excel 文档,本文中需要用到 spire.xls for python 库,我们可以用以下两种方法安装。
- 手动下载产品包后再从本地路径安装。
- 通过命令行直接使用以下 pip 命令安装:
pip install spire.xls
python 在 excel 中创建透视表
从最简单的部分开始——要在 excel 中创建透视表,请按照以下步骤操作:
- 使用 workbook.loadfromfile() 方法加载一个现有的 excel 文档
- 通过 workbook.worksheets[index] 属性获取指定的工作表
- 使用 worksheet.range 属性指定透视表的单元格数据范围
- 使用 workbook.pivotcaches.add() 方法创建 pivotcache 对象
- 使用 worksheet.pivottables.add() 方法根据 pivotcache 创建透视表
- 添加行字段
- 添加值字段
- 使用 pivottable.pivotbuiltinstyles 设置内置样式到透视表
- 使用 workbook.savetofile() 方法保存结果文档
- 使用 workbook.dispose() 方法释放文档对象[i]
from spire.xls import *
from spire.xls.common import *
# 创建一个 workbook 对象
workbook = workbook()
# 加载原 excel 文档
workbook.loadfromfile("microsoft excel 工作表.xlsx")
# 获取第一个工作表
sheet = workbook.worksheets[0]
# 指定透视表的数据范围
cellrange = sheet.range["a2:d28"]
# 添加 cellrange 到 pivotcaches
pivotcache = workbook.pivotcaches.add(cellrange)
# 通过pivotcaches添加透视表并设置位置
pivottable = sheet.pivottables.add("pivot table", sheet.range["h4"],
pivotcache)
# 设置透视表的行字段
regionfield = pivottable.pivotfields["书店名称"]
regionfield.axis = axistypes.row
pivottable.options.rowheadercaption = "书店名称"
productfield = pivottable.pivotfields["书籍名称"]
productfield.axis = axistypes.row
# 添加值字段
pivottable.datafields.add(pivottable.pivotfields["销售数量(本)"], "总计销售数量(本)",
subtotaltypes.sum)
# 设置透视表的样式
pivottable.builtinstyle = pivotbuiltinstyles.pivotstylemedium11
# 设置透视表相应列的列宽
h = sheet.range["h4"]
sheet.setcolumnwidth(h.column, 18)
sheet.setcolumnwidth(h.column + 1, 20)
# 保存文件
workbook.savetofile("结果.xlsx", excelversion.version2016)
# 释放对象
workbook.dispose()结果预览:
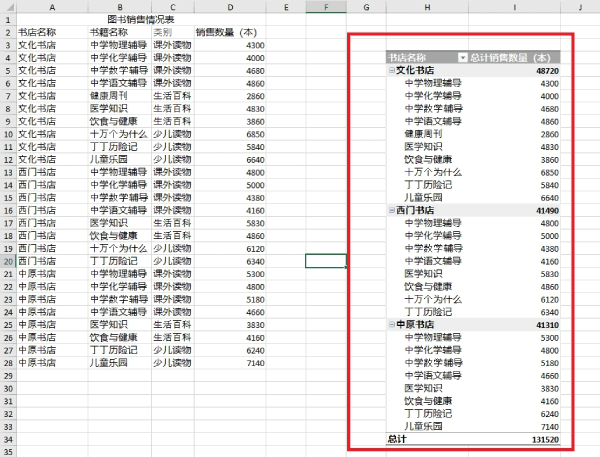
(python 在 excel 中创建数据透视表)
python 按列值对透视表进行排序
使用 spire.xls,让我们在 python 中得以通过列值对透视表进行排序。首先,通过 pivottable.pivotfields["fieldname"] 属性访问特定字段,然后使用 pivotfield.sorttype 属性设置其排序类型。
以下是按照特定字段的值对透视表进行排序的步骤:
- 使用 workbook.loadfromfile() 方法加载含有透视表的原 excel 文档
- 通过 workbook.worksheets[index] 属性获取特定的工作表
- 通过 worksheet.pivottables[index] 属性从工作表中获取特定的透视表
- 通过 pivottable.pivotfields["fieldname"] 属性获取特定的字段
- 通过 pivotfield.sorttype 属性对该字段中的数据进行排序
- 使用 workbook.savetofile() 方法保存结果文件
- 使用 workbook.dispose() 方法释放文档对象
from spire.xls import *
from spire.xls.common import *
# 创建一个 workbook 对象
workbook = workbook()
# 加载含有透视表的原 excel 文档
workbook.loadfromfile("透视表.xlsx")
# 获取第一个工作表
sheet = workbook.worksheets[0]
# 获取第一个透视表
pivottable = sheet.pivottables[0]
# 获取要排序的字段
idfield = pivottable.pivotfields["书店名称"]
# 按升序排列
idfield.sorttype = pivotfieldsorttype.ascending
# 保存文件
workbook.savetofile("结果.xlsx", excelversion.version2016)
# 释放对象
workbook.dispose()结果预览:
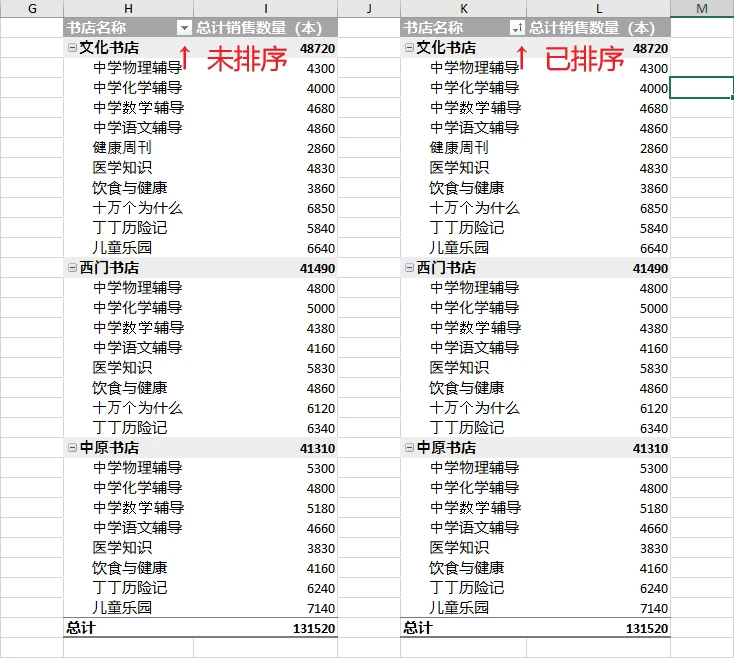
(python 按列值对数据透视表排序)
python 展开或折叠透视表中的行
若是想在 python 中展开或折叠数据透视表中的行,可以使用 pivotfield.hideitemdetail(string itemvalue, bool ishiddendetail) 方法来实现。
将第二个参数设置为 true 为折叠效果;反之,设置为 false 为展开效果。
详细步骤如下:
- 使用 workbook.loadfromfile() 方法加载含有透视表的原 excel 文档
- 通过 workbook.worksheets[index] 属性获取特定的工作表
- 通过 worksheet.pivottables[index] 属性从工作表中获取特定的透视表
- 通过 pivottable.pivotfields["fieldname"] 属性获取特定的字段
- 通过 pivotfield.hideitemdetail(string itemvalue, bool ishiddendetail) 方法针对具体项折叠或展开
- 使用 workbook.savetofile() 方法保存结果文件
- 使用 workbook.dispose() 方法释放文档对象
from spire.xls import *
from spire.xls.common import *
# 创建一个 workbook 对象
workbook = workbook()
# 加载含有透视表的原 excel 文档
workbook.loadfromfile("透视表.xlsx")
# 获取第一个工作表
sheet = workbook.worksheets[0]
# 获取第一个透视表
pivottable = sheet.pivottables[0]
# 获取特定字段
idfield = pivottable.pivotfields["书店名称"]
# 设置展开或折叠
idfield.hideitemdetail("文化书店", true)
idfield.hideitemdetail("西门书店", false)
idfield.hideitemdetail("中原书店", false)
# 保存文件
workbook.savetofile("结果.xlsx", excelversion.version2016)
# 释放对象
workbook.dispose()结果预览:
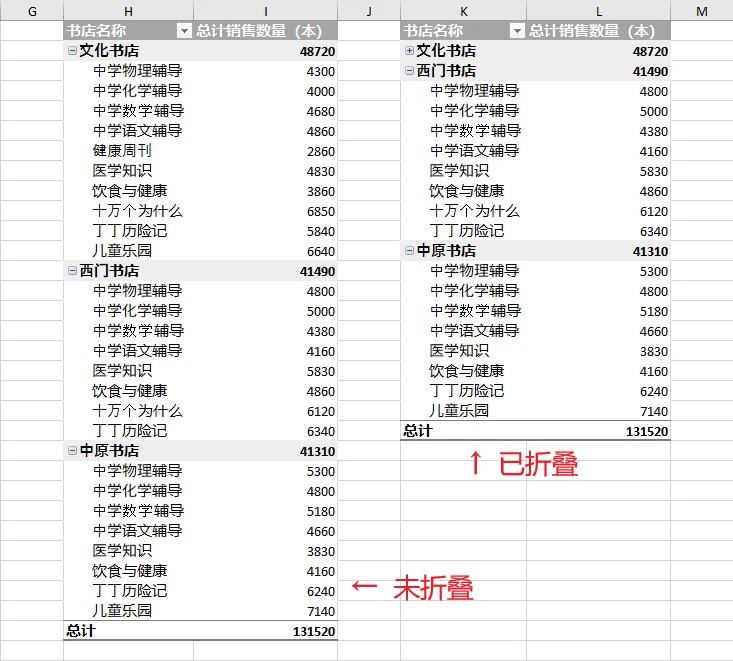
(python 展开或折叠数据透视表)
小结
在本教程中,我们了解了 python 创建透视表、python 按列值对透视表进行排序和 python 展开或折叠透视表中的行的方法。
到此这篇关于浅析python如何在excel中应用数据透视表的文章就介绍到这了,更多相关python excel数据透视表内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!