




当 pdf 文件中包含有价值的图片,如艺术画作、设计素材、报告图表等,提取图片可以将这些图像资源进行单独保存,方便后续在不同的项目中使用,避免每次都要从 pdf 中查找。本文将介绍如何使用c#通过代码从pdf文档中提取图片,包含以下两个示例:
提取pdf图片需要用到 spire.pdf for .net 库。可以通过此链接下载产品包后手动添加引用,或者直接通过nuget安装。
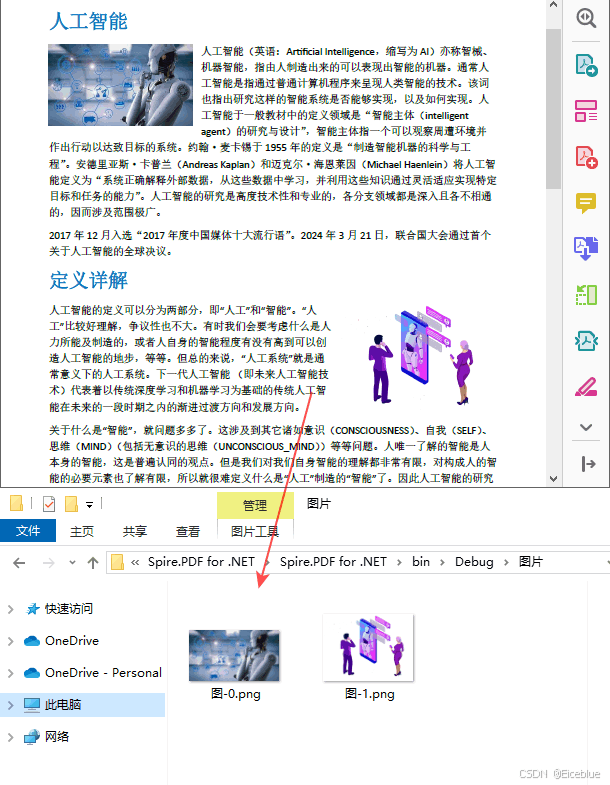
c# 提取指定 pdf 页面中的图片
pdfimagehelper 类可用于帮助用户管理 pdf 文档中的图像,要从某个指定的pdf页面中提取图片,参考以下步骤:
使用 pdfdocument 类的 loadfromfile() 方法加载 pdf 文件。
通过 pdfdocument 类的 pages[index] 属性获取指定页面。
创建 pdfimagehelper 对象,然后使用其 getimagesinfo() 方法获取页面中图像信息集合。
遍历图像信息集合,并使用 pdfimageinfo.image.save() 方法将每一张图片以png格式储存到指定文件路径。
c# 代码:
using spire.pdf;
using spire.pdf.utilities;
using system.drawing;
namespace extractimagesfromspecificpage
{
class program
{
static void main(string[] args)
{
// 加载pdf文档
pdfdocument pdf = new pdfdocument();
pdf.loadfromfile("e:\\pythonpdf\\ai.pdf");
// 获取第一页
pdfpagebase page = pdf.pages[0];
// 创建pdfimagehelper对象
pdfimagehelper imagehelper = new pdfimagehelper();
// 获取页面上的图片信息
pdfimageinfo[] imageinfos = imagehelper.getimagesinfo(page);
// 遍历图片信息
for (int i = 0; i < imageinfos.length; i++)
{
// 获取某个指定图片信息
pdfimageinfo imageinfo = imageinfos[i];
// 获取指定图片
image image = imageinfo.image;
// 将图片保存为png格式
image.save("图片\\图-" + i + ".png");
}
pdf.dispose();
}
}
}
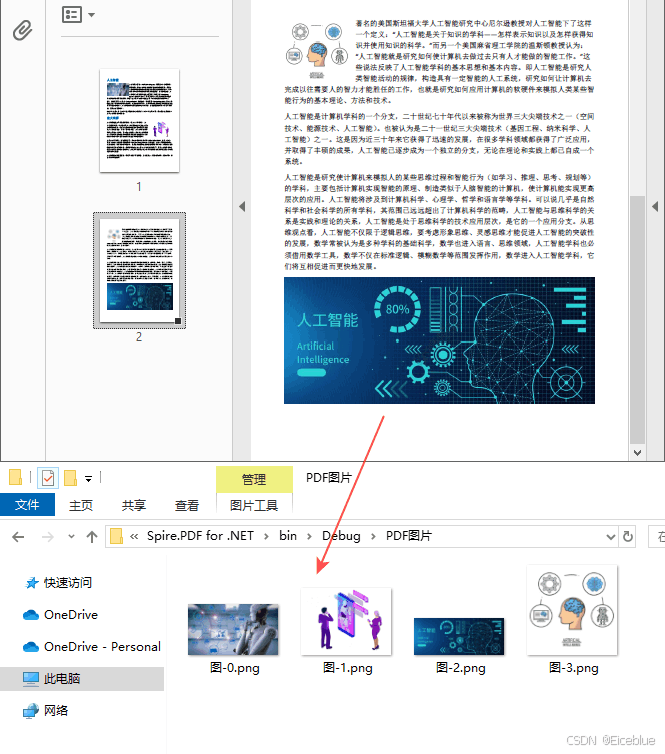
c# 提取pdf 文档中所有图片
要获取整个pdf文档中的图片,就需要遍历每一页然后再提取,具体参考以下步骤:
- 使用 pdfdocument 类的 loadfromfile() 方法加载 pdf 文件。
- 创建 pdfimagehelper 对象。
- 遍历文档中的每一个页面。
- 通过 pdfdocument 类的 pages[index] 属性获取指定页面。
- 使用 pdfimagehelper.getimagesinfo() 方法获取页面中图像信息集合。
- 遍历图像信息集合,并使用 **pdfimageinfo.image.save()**方法将每一张图片以png格式储存到指定文件路径。
c# 代码:
using spire.pdf;
using spire.pdf.utilities;
using system.drawing;
namespace extractallimages
{
class program
{
static void main(string[] args)
{
// 加载pdf文档
pdfdocument pdf = new pdfdocument();
pdf.loadfromfile("e:\\pythonpdf\\ai.pdf");
// 创建pdfimagehelper对象
pdfimagehelper imagehelper = new pdfimagehelper();
int m = 0;
// 遍历pdf页面
for (int i = 0; i < pdf.pages.count; i++)
{
// 获取指定页面
pdfpagebase page = pdf.pages[i];
// 获取页面上的图片信息
pdfimageinfo[] imageinfos = imagehelper.getimagesinfo(page);
// 遍历图片信息
for (int j = 0; j < imageinfos.length; j++)
{
// 获取某个指定图片信息
pdfimageinfo imageinfo = imageinfos[j];
// 获取指定图片
image image = imageinfo.image;
// 将图片保存为png格式
image.save("pdf图片\\图-" + m + ".png");
m++;
}
}
pdf.dispose();
}
}
}
到此这篇关于详解c#如何提取pdf文档中的图片的文章就介绍到这了,更多相关c#提取pdf图片内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!