xai今日发布新一代大语言模型grok-3及其精简版grok-3 mini。
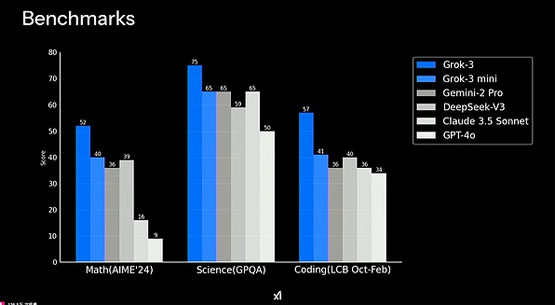
最新基准测试显示,grok-3在与deepseek的直接对比中展现出显著优势。
在数学能力测试(aime'24)中,grok-3获得52分,明显超过deepseek-v3的39分。
科学知识评估(gpqa)方面,grok-3以75分的成绩领先,而deepseek-v3为65分。
在编程能力测试(lcb oct-feb)中,grok-3同样以57分超过deepseek-v3的36分。
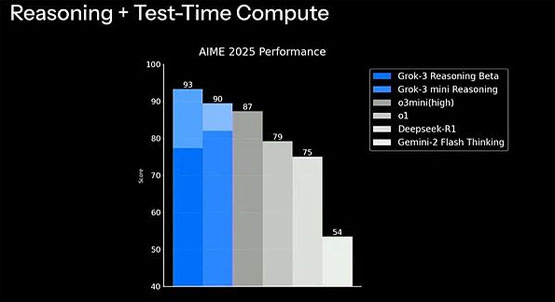
最新公布的aime 2025性能测试中,grok-3 reasoning beta版本在推理和计算时间复合评分上取得93分的优异成绩,其精简版本grok-3 mini也达到了90分。
相比之下,deepseek-r1的得分为75分,而gemini-2 flash thinking仅为54分。
这一结果进一步凸显了grok-3在复杂数学推理和计算效率方面的突出优势。
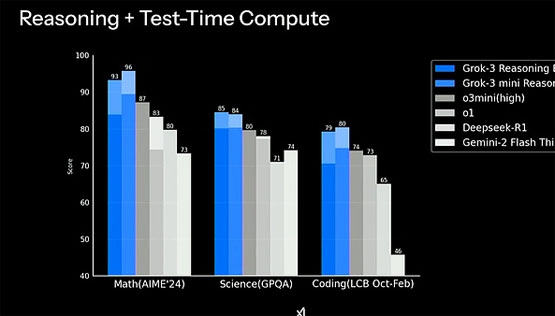
特别值得注意的是,deepseek近期发布的deepseek-r1在其他推理能力测试中也未能赶超grok-3。
在数学推理中,grok-3获得93分,deepseek-r1为73分;科学推理中,grok-3得分85分,deepseek-r1为74分;编程推理中,grok-3达到79分,而deepseek-r1为65分。
在lmsys聊天机器人竞技场评估中,grok-3的得分约为1400分,不仅超过了deepseek系列,也领先于其他主流大模型,包括gpt-4、claude等。
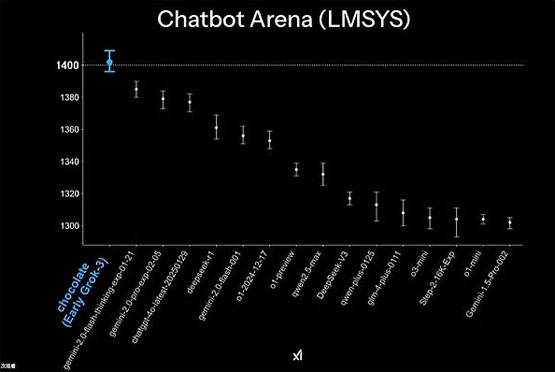
这些数据表明,尽管deepseek在过去几个月展现出强劲的发展势头,但grok-3的整体性能仍然保持领先地位。
特别是在数学推理和计算效率方面的优势更为明显,这不仅体现了xai在模型研发上的技术实力,也显示出ai领域竞争的白热化程度。
以上就是一文了解马斯克发布grok3大模型 多项测试超越deepseek 展现强劲竞争力的详细内容,更多关于grok-3在与deepseek的直接对比中展现出显著优势的资料请关注代码网其它相关文章!






发表评论