1、创建安装目录
mkdir /data/redis/ -p && cd /data/redis
2、创建docker-compose.yml文件
version: '3'
services:
redis:
image: registry.cn-hangzhou.aliyuncs.com/xiaopangpang/redis:7.0.5
container_name: redis
restart: always
environment:
tz: asia/shanghai
lang: en_us.utf-8
ports:
- "6379:6379"
volumes:
- "./redis/data:/data"
- "./redis/config/redis.conf:/etc/redis/redis.conf"
command: redis-server /etc/redis/redis.conf --requirepass 123456 --appendonly yes
3、创建redis.conf配置文件
# redis configuration file example.
#
# note that in order to read the configuration file, redis must be
# started with the file path as first argument:
#
# ./redis-server /path/to/redis.conf
# note on units: when memory size is needed, it is possible to specify
# it in the usual form of 1k 5gb 4m and so forth:
#
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
#
# units are case insensitive so 1gb 1gb 1gb are all the same.
################################## includes ###################################
# include one or more other config files here. this is useful if you
# have a standard template that goes to all redis servers but also need
# to customize a few per-server settings. include files can include
# other files, so use this wisely.
#
# note that option "include" won't be rewritten by command "config rewrite"
# from admin or redis sentinel. since redis always uses the last processed
# line as value of a configuration directive, you'd better put includes
# at the beginning of this file to avoid overwriting config change at runtime.
#
# if instead you are interested in using includes to override configuration
# options, it is better to use include as the last line.
#
# included paths may contain wildcards. all files matching the wildcards will
# be included in alphabetical order.
# note that if an include path contains a wildcards but no files match it when
# the server is started, the include statement will be ignored and no error will
# be emitted. it is safe, therefore, to include wildcard files from empty
# directories.
#
# include /path/to/local.conf
# include /path/to/other.conf
# include /path/to/fragments/*.conf
#
################################## modules #####################################
# load modules at startup. if the server is not able to load modules
# it will abort. it is possible to use multiple loadmodule directives.
#
# loadmodule /path/to/my_module.so
# loadmodule /path/to/other_module.so
################################## network #####################################
# by default, if no "bind" configuration directive is specified, redis listens
# for connections from all available network interfaces on the host machine.
# it is possible to listen to just one or multiple selected interfaces using
# the "bind" configuration directive, followed by one or more ip addresses.
# each address can be prefixed by "-", which means that redis will not fail to
# start if the address is not available. being not available only refers to
# addresses that does not correspond to any network interface. addresses that
# are already in use will always fail, and unsupported protocols will always be
# silently skipped.
#
# examples:
#
# bind 192.168.1.100 10.0.0.1 # listens on two specific ipv4 addresses
# bind 127.0.0.1 ::1 # listens on loopback ipv4 and ipv6
# bind * -::* # like the default, all available interfaces
#
# ~~~ warning ~~~ if the computer running redis is directly exposed to the
# internet, binding to all the interfaces is dangerous and will expose the
# instance to everybody on the internet. so by default we uncomment the
# following bind directive, that will force redis to listen only on the
# ipv4 and ipv6 (if available) loopback interface addresses (this means redis
# will only be able to accept client connections from the same host that it is
# running on).
#
# if you are sure you want your instance to listen to all the interfaces
# comment out the following line.
#
# you will also need to set a password unless you explicitly disable protected
# mode.
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# 注释允许外部访问redis
# bind 127.0.0.1 -::1
# by default, outgoing connections (from replica to master, from sentinel to
# instances, cluster bus, etc.) are not bound to a specific local address. in
# most cases, this means the operating system will handle that based on routing
# and the interface through which the connection goes out.
#
# using bind-source-addr it is possible to configure a specific address to bind
# to, which may also affect how the connection gets routed.
#
# example:
#
# bind-source-addr 10.0.0.1
# protected mode is a layer of security protection, in order to avoid that
# redis instances left open on the internet are accessed and exploited.
#
# when protected mode is on and the default user has no password, the server
# only accepts local connections from the ipv4 address (127.0.0.1), ipv6 address
# (::1) or unix domain sockets.
#
# by default protected mode is enabled. you should disable it only if
# you are sure you want clients from other hosts to connect to redis
# even if no authentication is configured.
protected-mode yes
# redis uses default hardened security configuration directives to reduce the
# attack surface on innocent users. therefore, several sensitive configuration
# directives are immutable, and some potentially-dangerous commands are blocked.
#
# configuration directives that control files that redis writes to (e.g., 'dir'
# and 'dbfilename') and that aren't usually modified during runtime
# are protected by making them immutable.
#
# commands that can increase the attack surface of redis and that aren't usually
# called by users are blocked by default.
#
# these can be exposed to either all connections or just local ones by setting
# each of the configs listed below to either of these values:
#
# no - block for any connection (remain immutable)
# yes - allow for any connection (no protection)
# local - allow only for local connections. ones originating from the
# ipv4 address (127.0.0.1), ipv6 address (::1) or unix domain sockets.
#
# enable-protected-configs no
# enable-debug-command no
# enable-module-command no
# accept connections on the specified port, default is 6379 (iana #815344).
# if port 0 is specified redis will not listen on a tcp socket.
port 6379
# tcp listen() backlog.
#
# in high requests-per-second environments you need a high backlog in order
# to avoid slow clients connection issues. note that the linux kernel
# will silently truncate it to the value of /proc/sys/net/core/somaxconn so
# make sure to raise both the value of somaxconn and tcp_max_syn_backlog
# in order to get the desired effect.
tcp-backlog 511
# unix socket.
#
# specify the path for the unix socket that will be used to listen for
# incoming connections. there is no default, so redis will not listen
# on a unix socket when not specified.
#
# unixsocket /run/redis.sock
# unixsocketperm 700
# close the connection after a client is idle for n seconds (0 to disable)
timeout 0
# tcp keepalive.
#
# if non-zero, use so_keepalive to send tcp acks to clients in absence
# of communication. this is useful for two reasons:
#
# 1) detect dead peers.
# 2) force network equipment in the middle to consider the connection to be
# alive.
#
# on linux, the specified value (in seconds) is the period used to send acks.
# note that to close the connection the double of the time is needed.
# on other kernels the period depends on the kernel configuration.
#
# a reasonable value for this option is 300 seconds, which is the new
# redis default starting with redis 3.2.1.
tcp-keepalive 300
# apply os-specific mechanism to mark the listening socket with the specified
# id, to support advanced routing and filtering capabilities.
#
# on linux, the id represents a connection mark.
# on freebsd, the id represents a socket cookie id.
# on openbsd, the id represents a route table id.
#
# the default value is 0, which implies no marking is required.
# socket-mark-id 0
################################# tls/ssl #####################################
# by default, tls/ssl is disabled. to enable it, the "tls-port" configuration
# directive can be used to define tls-listening ports. to enable tls on the
# default port, use:
#
# port 0
# tls-port 6379
# configure a x.509 certificate and private key to use for authenticating the
# server to connected clients, masters or cluster peers. these files should be
# pem formatted.
#
# tls-cert-file redis.crt
# tls-key-file redis.key
#
# if the key file is encrypted using a passphrase, it can be included here
# as well.
#
# tls-key-file-pass secret
# normally redis uses the same certificate for both server functions (accepting
# connections) and client functions (replicating from a master, establishing
# cluster bus connections, etc.).
#
# sometimes certificates are issued with attributes that designate them as
# client-only or server-only certificates. in that case it may be desired to use
# different certificates for incoming (server) and outgoing (client)
# connections. to do that, use the following directives:
#
# tls-client-cert-file client.crt
# tls-client-key-file client.key
#
# if the key file is encrypted using a passphrase, it can be included here
# as well.
#
# tls-client-key-file-pass secret
# configure a dh parameters file to enable diffie-hellman (dh) key exchange,
# required by older versions of openssl (<3.0). newer versions do not require
# this configuration and recommend against it.
#
# tls-dh-params-file redis.dh
# configure a ca certificate(s) bundle or directory to authenticate tls/ssl
# clients and peers. redis requires an explicit configuration of at least one
# of these, and will not implicitly use the system wide configuration.
#
# tls-ca-cert-file ca.crt
# tls-ca-cert-dir /etc/ssl/certs
# by default, clients (including replica servers) on a tls port are required
# to authenticate using valid client side certificates.
#
# if "no" is specified, client certificates are not required and not accepted.
# if "optional" is specified, client certificates are accepted and must be
# valid if provided, but are not required.
#
# tls-auth-clients no
# tls-auth-clients optional
# by default, a redis replica does not attempt to establish a tls connection
# with its master.
#
# use the following directive to enable tls on replication links.
#
# tls-replication yes
# by default, the redis cluster bus uses a plain tcp connection. to enable
# tls for the bus protocol, use the following directive:
#
# tls-cluster yes
# by default, only tlsv1.2 and tlsv1.3 are enabled and it is highly recommended
# that older formally deprecated versions are kept disabled to reduce the attack surface.
# you can explicitly specify tls versions to support.
# allowed values are case insensitive and include "tlsv1", "tlsv1.1", "tlsv1.2",
# "tlsv1.3" (openssl >= 1.1.1) or any combination.
# to enable only tlsv1.2 and tlsv1.3, use:
#
# tls-protocols "tlsv1.2 tlsv1.3"
# configure allowed ciphers. see the ciphers(1ssl) manpage for more information
# about the syntax of this string.
#
# note: this configuration applies only to <= tlsv1.2.
#
# tls-ciphers default:!medium
# configure allowed tlsv1.3 ciphersuites. see the ciphers(1ssl) manpage for more
# information about the syntax of this string, and specifically for tlsv1.3
# ciphersuites.
#
# tls-ciphersuites tls_chacha20_poly1305_sha256
# when choosing a cipher, use the server's preference instead of the client
# preference. by default, the server follows the client's preference.
#
# tls-prefer-server-ciphers yes
# by default, tls session caching is enabled to allow faster and less expensive
# reconnections by clients that support it. use the following directive to disable
# caching.
#
# tls-session-caching no
# change the default number of tls sessions cached. a zero value sets the cache
# to unlimited size. the default size is 20480.
#
# tls-session-cache-size 5000
# change the default timeout of cached tls sessions. the default timeout is 300
# seconds.
#
# tls-session-cache-timeout 60
################################# general #####################################
# by default redis does not run as a daemon. use 'yes' if you need it.
# note that redis will write a pid file in /var/run/redis.pid when daemonized.
# when redis is supervised by upstart or systemd, this parameter has no impact.
daemonize no
# if you run redis from upstart or systemd, redis can interact with your
# supervision tree. options:
# supervised no - no supervision interaction
# supervised upstart - signal upstart by putting redis into sigstop mode
# requires "expect stop" in your upstart job config
# supervised systemd - signal systemd by writing ready=1 to $notify_socket
# on startup, and updating redis status on a regular
# basis.
# supervised auto - detect upstart or systemd method based on
# upstart_job or notify_socket environment variables
# note: these supervision methods only signal "process is ready."
# they do not enable continuous pings back to your supervisor.
#
# the default is "no". to run under upstart/systemd, you can simply uncomment
# the line below:
#
# supervised auto
# if a pid file is specified, redis writes it where specified at startup
# and removes it at exit.
#
# when the server runs non daemonized, no pid file is created if none is
# specified in the configuration. when the server is daemonized, the pid file
# is used even if not specified, defaulting to "/var/run/redis.pid".
#
# creating a pid file is best effort: if redis is not able to create it
# nothing bad happens, the server will start and run normally.
#
# note that on modern linux systems "/run/redis.pid" is more conforming
# and should be used instead.
pidfile /var/run/redis_6379.pid
# specify the server verbosity level.
# this can be one of:
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably)
# warning (only very important / critical messages are logged)
loglevel notice
# specify the log file name. also the empty string can be used to force
# redis to log on the standard output. note that if you use standard
# output for logging but daemonize, logs will be sent to /dev/null
logfile ""
# to enable logging to the system logger, just set 'syslog-enabled' to yes,
# and optionally update the other syslog parameters to suit your needs.
# syslog-enabled no
# specify the syslog identity.
# syslog-ident redis
# specify the syslog facility. must be user or between local0-local7.
# syslog-facility local0
# to disable the built in crash log, which will possibly produce cleaner core
# dumps when they are needed, uncomment the following:
#
# crash-log-enabled no
# to disable the fast memory check that's run as part of the crash log, which
# will possibly let redis terminate sooner, uncomment the following:
#
# crash-memcheck-enabled no
# set the number of databases. the default database is db 0, you can select
# a different one on a per-connection basis using select <dbid> where
# dbid is a number between 0 and 'databases'-1
databases 16
# by default redis shows an ascii art logo only when started to log to the
# standard output and if the standard output is a tty and syslog logging is
# disabled. basically this means that normally a logo is displayed only in
# interactive sessions.
#
# however it is possible to force the pre-4.0 behavior and always show a
# ascii art logo in startup logs by setting the following option to yes.
always-show-logo no
# by default, redis modifies the process title (as seen in 'top' and 'ps') to
# provide some runtime information. it is possible to disable this and leave
# the process name as executed by setting the following to no.
set-proc-title yes
# when changing the process title, redis uses the following template to construct
# the modified title.
#
# template variables are specified in curly brackets. the following variables are
# supported:
#
# {title} name of process as executed if parent, or type of child process.
# {listen-addr} bind address or '*' followed by tcp or tls port listening on, or
# unix socket if only that's available.
# {server-mode} special mode, i.e. "[sentinel]" or "[cluster]".
# {port} tcp port listening on, or 0.
# {tls-port} tls port listening on, or 0.
# {unixsocket} unix domain socket listening on, or "".
# {config-file} name of configuration file used.
#
proc-title-template "{title} {listen-addr} {server-mode}"
################################ snapshotting ################################
# save the db to disk.
#
# save <seconds> <changes> [<seconds> <changes> ...]
#
# redis will save the db if the given number of seconds elapsed and it
# surpassed the given number of write operations against the db.
#
# snapshotting can be completely disabled with a single empty string argument
# as in following example:
#
# save ""
#
# unless specified otherwise, by default redis will save the db:
# * after 3600 seconds (an hour) if at least 1 change was performed
# * after 300 seconds (5 minutes) if at least 100 changes were performed
# * after 60 seconds if at least 10000 changes were performed
#
# you can set these explicitly by uncommenting the following line.
#
# save 3600 1 300 100 60 10000
# by default redis will stop accepting writes if rdb snapshots are enabled
# (at least one save point) and the latest background save failed.
# this will make the user aware (in a hard way) that data is not persisting
# on disk properly, otherwise chances are that no one will notice and some
# disaster will happen.
#
# if the background saving process will start working again redis will
# automatically allow writes again.
#
# however if you have setup your proper monitoring of the redis server
# and persistence, you may want to disable this feature so that redis will
# continue to work as usual even if there are problems with disk,
# permissions, and so forth.
stop-writes-on-bgsave-error yes
# compress string objects using lzf when dump .rdb databases?
# by default compression is enabled as it's almost always a win.
# if you want to save some cpu in the saving child set it to 'no' but
# the dataset will likely be bigger if you have compressible values or keys.
rdbcompression yes
# since version 5 of rdb a crc64 checksum is placed at the end of the file.
# this makes the format more resistant to corruption but there is a performance
# hit to pay (around 10%) when saving and loading rdb files, so you can disable it
# for maximum performances.
#
# rdb files created with checksum disabled have a checksum of zero that will
# tell the loading code to skip the check.
rdbchecksum yes
# enables or disables full sanitization checks for ziplist and listpack etc when
# loading an rdb or restore payload. this reduces the chances of a assertion or
# crash later on while processing commands.
# options:
# no - never perform full sanitization
# yes - always perform full sanitization
# clients - perform full sanitization only for user connections.
# excludes: rdb files, restore commands received from the master
# connection, and client connections which have the
# skip-sanitize-payload acl flag.
# the default should be 'clients' but since it currently affects cluster
# resharding via migrate, it is temporarily set to 'no' by default.
#
# sanitize-dump-payload no
# the filename where to dump the db
dbfilename dump.rdb
# remove rdb files used by replication in instances without persistence
# enabled. by default this option is disabled, however there are environments
# where for regulations or other security concerns, rdb files persisted on
# disk by masters in order to feed replicas, or stored on disk by replicas
# in order to load them for the initial synchronization, should be deleted
# asap. note that this option only works in instances that have both aof
# and rdb persistence disabled, otherwise is completely ignored.
#
# an alternative (and sometimes better) way to obtain the same effect is
# to use diskless replication on both master and replicas instances. however
# in the case of replicas, diskless is not always an option.
rdb-del-sync-files no
# the working directory.
#
# the db will be written inside this directory, with the filename specified
# above using the 'dbfilename' configuration directive.
#
# the append only file will also be created inside this directory.
#
# note that you must specify a directory here, not a file name.
dir ./
################################# replication #################################
# master-replica replication. use replicaof to make a redis instance a copy of
# another redis server. a few things to understand asap about redis replication.
#
# +------------------+ +---------------+
# | master | ---> | replica |
# | (receive writes) | | (exact copy) |
# +------------------+ +---------------+
#
# 1) redis replication is asynchronous, but you can configure a master to
# stop accepting writes if it appears to be not connected with at least
# a given number of replicas.
# 2) redis replicas are able to perform a partial resynchronization with the
# master if the replication link is lost for a relatively small amount of
# time. you may want to configure the replication backlog size (see the next
# sections of this file) with a sensible value depending on your needs.
# 3) replication is automatic and does not need user intervention. after a
# network partition replicas automatically try to reconnect to masters
# and resynchronize with them.
#
# replicaof <masterip> <masterport>
# if the master is password protected (using the "requirepass" configuration
# directive below) it is possible to tell the replica to authenticate before
# starting the replication synchronization process, otherwise the master will
# refuse the replica request.
#
# masterauth <master-password>
#
# however this is not enough if you are using redis acls (for redis version
# 6 or greater), and the default user is not capable of running the psync
# command and/or other commands needed for replication. in this case it's
# better to configure a special user to use with replication, and specify the
# masteruser configuration as such:
#
# masteruser <username>
#
# when masteruser is specified, the replica will authenticate against its
# master using the new auth form: auth <username> <password>.
# when a replica loses its connection with the master, or when the replication
# is still in progress, the replica can act in two different ways:
#
# 1) if replica-serve-stale-data is set to 'yes' (the default) the replica will
# still reply to client requests, possibly with out of date data, or the
# data set may just be empty if this is the first synchronization.
#
# 2) if replica-serve-stale-data is set to 'no' the replica will reply with error
# "masterdown link with master is down and replica-serve-stale-data is set to 'no'"
# to all data access commands, excluding commands such as:
# info, replicaof, auth, shutdown, replconf, role, config, subscribe,
# unsubscribe, psubscribe, punsubscribe, publish, pubsub, command, post,
# host and latency.
#
replica-serve-stale-data yes
# you can configure a replica instance to accept writes or not. writing against
# a replica instance may be useful to store some ephemeral data (because data
# written on a replica will be easily deleted after resync with the master) but
# may also cause problems if clients are writing to it because of a
# misconfiguration.
#
# since redis 2.6 by default replicas are read-only.
#
# note: read only replicas are not designed to be exposed to untrusted clients
# on the internet. it's just a protection layer against misuse of the instance.
# still a read only replica exports by default all the administrative commands
# such as config, debug, and so forth. to a limited extent you can improve
# security of read only replicas using 'rename-command' to shadow all the
# administrative / dangerous commands.
replica-read-only yes
# replication sync strategy: disk or socket.
#
# new replicas and reconnecting replicas that are not able to continue the
# replication process just receiving differences, need to do what is called a
# "full synchronization". an rdb file is transmitted from the master to the
# replicas.
#
# the transmission can happen in two different ways:
#
# 1) disk-backed: the redis master creates a new process that writes the rdb
# file on disk. later the file is transferred by the parent
# process to the replicas incrementally.
# 2) diskless: the redis master creates a new process that directly writes the
# rdb file to replica sockets, without touching the disk at all.
#
# with disk-backed replication, while the rdb file is generated, more replicas
# can be queued and served with the rdb file as soon as the current child
# producing the rdb file finishes its work. with diskless replication instead
# once the transfer starts, new replicas arriving will be queued and a new
# transfer will start when the current one terminates.
#
# when diskless replication is used, the master waits a configurable amount of
# time (in seconds) before starting the transfer in the hope that multiple
# replicas will arrive and the transfer can be parallelized.
#
# with slow disks and fast (large bandwidth) networks, diskless replication
# works better.
repl-diskless-sync yes
# when diskless replication is enabled, it is possible to configure the delay
# the server waits in order to spawn the child that transfers the rdb via socket
# to the replicas.
#
# this is important since once the transfer starts, it is not possible to serve
# new replicas arriving, that will be queued for the next rdb transfer, so the
# server waits a delay in order to let more replicas arrive.
#
# the delay is specified in seconds, and by default is 5 seconds. to disable
# it entirely just set it to 0 seconds and the transfer will start asap.
repl-diskless-sync-delay 5
# when diskless replication is enabled with a delay, it is possible to let
# the replication start before the maximum delay is reached if the maximum
# number of replicas expected have connected. default of 0 means that the
# maximum is not defined and redis will wait the full delay.
repl-diskless-sync-max-replicas 0
# -----------------------------------------------------------------------------
# warning: rdb diskless load is experimental. since in this setup the replica
# does not immediately store an rdb on disk, it may cause data loss during
# failovers. rdb diskless load + redis modules not handling i/o reads may also
# cause redis to abort in case of i/o errors during the initial synchronization
# stage with the master. use only if you know what you are doing.
# -----------------------------------------------------------------------------
#
# replica can load the rdb it reads from the replication link directly from the
# socket, or store the rdb to a file and read that file after it was completely
# received from the master.
#
# in many cases the disk is slower than the network, and storing and loading
# the rdb file may increase replication time (and even increase the master's
# copy on write memory and replica buffers).
# however, parsing the rdb file directly from the socket may mean that we have
# to flush the contents of the current database before the full rdb was
# received. for this reason we have the following options:
#
# "disabled" - don't use diskless load (store the rdb file to the disk first)
# "on-empty-db" - use diskless load only when it is completely safe.
# "swapdb" - keep current db contents in ram while parsing the data directly
# from the socket. replicas in this mode can keep serving current
# data set while replication is in progress, except for cases where
# they can't recognize master as having a data set from same
# replication history.
# note that this requires sufficient memory, if you don't have it,
# you risk an oom kill.
repl-diskless-load disabled
# master send pings to its replicas in a predefined interval. it's possible to
# change this interval with the repl_ping_replica_period option. the default
# value is 10 seconds.
#
# repl-ping-replica-period 10
# the following option sets the replication timeout for:
#
# 1) bulk transfer i/o during sync, from the point of view of replica.
# 2) master timeout from the point of view of replicas (data, pings).
# 3) replica timeout from the point of view of masters (replconf ack pings).
#
# it is important to make sure that this value is greater than the value
# specified for repl-ping-replica-period otherwise a timeout will be detected
# every time there is low traffic between the master and the replica. the default
# value is 60 seconds.
#
# repl-timeout 60
# disable tcp_nodelay on the replica socket after sync?
#
# if you select "yes" redis will use a smaller number of tcp packets and
# less bandwidth to send data to replicas. but this can add a delay for
# the data to appear on the replica side, up to 40 milliseconds with
# linux kernels using a default configuration.
#
# if you select "no" the delay for data to appear on the replica side will
# be reduced but more bandwidth will be used for replication.
#
# by default we optimize for low latency, but in very high traffic conditions
# or when the master and replicas are many hops away, turning this to "yes" may
# be a good idea.
repl-disable-tcp-nodelay no
# set the replication backlog size. the backlog is a buffer that accumulates
# replica data when replicas are disconnected for some time, so that when a
# replica wants to reconnect again, often a full resync is not needed, but a
# partial resync is enough, just passing the portion of data the replica
# missed while disconnected.
#
# the bigger the replication backlog, the longer the replica can endure the
# disconnect and later be able to perform a partial resynchronization.
#
# the backlog is only allocated if there is at least one replica connected.
#
# repl-backlog-size 1mb
# after a master has no connected replicas for some time, the backlog will be
# freed. the following option configures the amount of seconds that need to
# elapse, starting from the time the last replica disconnected, for the backlog
# buffer to be freed.
#
# note that replicas never free the backlog for timeout, since they may be
# promoted to masters later, and should be able to correctly "partially
# resynchronize" with other replicas: hence they should always accumulate backlog.
#
# a value of 0 means to never release the backlog.
#
# repl-backlog-ttl 3600
# the replica priority is an integer number published by redis in the info
# output. it is used by redis sentinel in order to select a replica to promote
# into a master if the master is no longer working correctly.
#
# a replica with a low priority number is considered better for promotion, so
# for instance if there are three replicas with priority 10, 100, 25 sentinel
# will pick the one with priority 10, that is the lowest.
#
# however a special priority of 0 marks the replica as not able to perform the
# role of master, so a replica with priority of 0 will never be selected by
# redis sentinel for promotion.
#
# by default the priority is 100.
replica-priority 100
# the propagation error behavior controls how redis will behave when it is
# unable to handle a command being processed in the replication stream from a master
# or processed while reading from an aof file. errors that occur during propagation
# are unexpected, and can cause data inconsistency. however, there are edge cases
# in earlier versions of redis where it was possible for the server to replicate or persist
# commands that would fail on future versions. for this reason the default behavior
# is to ignore such errors and continue processing commands.
#
# if an application wants to ensure there is no data divergence, this configuration
# should be set to 'panic' instead. the value can also be set to 'panic-on-replicas'
# to only panic when a replica encounters an error on the replication stream. one of
# these two panic values will become the default value in the future once there are
# sufficient safety mechanisms in place to prevent false positive crashes.
#
# propagation-error-behavior ignore
# replica ignore disk write errors controls the behavior of a replica when it is
# unable to persist a write command received from its master to disk. by default,
# this configuration is set to 'no' and will crash the replica in this condition.
# it is not recommended to change this default, however in order to be compatible
# with older versions of redis this config can be toggled to 'yes' which will just
# log a warning and execute the write command it got from the master.
#
# replica-ignore-disk-write-errors no
# -----------------------------------------------------------------------------
# by default, redis sentinel includes all replicas in its reports. a replica
# can be excluded from redis sentinel's announcements. an unannounced replica
# will be ignored by the 'sentinel replicas <master>' command and won't be
# exposed to redis sentinel's clients.
#
# this option does not change the behavior of replica-priority. even with
# replica-announced set to 'no', the replica can be promoted to master. to
# prevent this behavior, set replica-priority to 0.
#
# replica-announced yes
# it is possible for a master to stop accepting writes if there are less than
# n replicas connected, having a lag less or equal than m seconds.
#
# the n replicas need to be in "online" state.
#
# the lag in seconds, that must be <= the specified value, is calculated from
# the last ping received from the replica, that is usually sent every second.
#
# this option does not guarantee that n replicas will accept the write, but
# will limit the window of exposure for lost writes in case not enough replicas
# are available, to the specified number of seconds.
#
# for example to require at least 3 replicas with a lag <= 10 seconds use:
#
# min-replicas-to-write 3
# min-replicas-max-lag 10
#
# setting one or the other to 0 disables the feature.
#
# by default min-replicas-to-write is set to 0 (feature disabled) and
# min-replicas-max-lag is set to 10.
# a redis master is able to list the address and port of the attached
# replicas in different ways. for example the "info replication" section
# offers this information, which is used, among other tools, by
# redis sentinel in order to discover replica instances.
# another place where this info is available is in the output of the
# "role" command of a master.
#
# the listed ip address and port normally reported by a replica is
# obtained in the following way:
#
# ip: the address is auto detected by checking the peer address
# of the socket used by the replica to connect with the master.
#
# port: the port is communicated by the replica during the replication
# handshake, and is normally the port that the replica is using to
# listen for connections.
#
# however when port forwarding or network address translation (nat) is
# used, the replica may actually be reachable via different ip and port
# pairs. the following two options can be used by a replica in order to
# report to its master a specific set of ip and port, so that both info
# and role will report those values.
#
# there is no need to use both the options if you need to override just
# the port or the ip address.
#
# replica-announce-ip 5.5.5.5
# replica-announce-port 1234
############################### keys tracking #################################
# redis implements server assisted support for client side caching of values.
# this is implemented using an invalidation table that remembers, using
# a radix key indexed by key name, what clients have which keys. in turn
# this is used in order to send invalidation messages to clients. please
# check this page to understand more about the feature:
#
# https://redis.io/topics/client-side-caching
#
# when tracking is enabled for a client, all the read only queries are assumed
# to be cached: this will force redis to store information in the invalidation
# table. when keys are modified, such information is flushed away, and
# invalidation messages are sent to the clients. however if the workload is
# heavily dominated by reads, redis could use more and more memory in order
# to track the keys fetched by many clients.
#
# for this reason it is possible to configure a maximum fill value for the
# invalidation table. by default it is set to 1m of keys, and once this limit
# is reached, redis will start to evict keys in the invalidation table
# even if they were not modified, just to reclaim memory: this will in turn
# force the clients to invalidate the cached values. basically the table
# maximum size is a trade off between the memory you want to spend server
# side to track information about who cached what, and the ability of clients
# to retain cached objects in memory.
#
# if you set the value to 0, it means there are no limits, and redis will
# retain as many keys as needed in the invalidation table.
# in the "stats" info section, you can find information about the number of
# keys in the invalidation table at every given moment.
#
# note: when key tracking is used in broadcasting mode, no memory is used
# in the server side so this setting is useless.
#
# tracking-table-max-keys 1000000
################################## security ###################################
# warning: since redis is pretty fast, an outside user can try up to
# 1 million passwords per second against a modern box. this means that you
# should use very strong passwords, otherwise they will be very easy to break.
# note that because the password is really a shared secret between the client
# and the server, and should not be memorized by any human, the password
# can be easily a long string from /dev/urandom or whatever, so by using a
# long and unguessable password no brute force attack will be possible.
# redis acl users are defined in the following format:
#
# user <username> ... acl rules ...
#
# for example:
#
# user worker +@list +@connection ~jobs:* on >ffa9203c493aa99
#
# the special username "default" is used for new connections. if this user
# has the "nopass" rule, then new connections will be immediately authenticated
# as the "default" user without the need of any password provided via the
# auth command. otherwise if the "default" user is not flagged with "nopass"
# the connections will start in not authenticated state, and will require
# auth (or the hello command auth option) in order to be authenticated and
# start to work.
#
# the acl rules that describe what a user can do are the following:
#
# on enable the user: it is possible to authenticate as this user.
# off disable the user: it's no longer possible to authenticate
# with this user, however the already authenticated connections
# will still work.
# skip-sanitize-payload restore dump-payload sanitization is skipped.
# sanitize-payload restore dump-payload is sanitized (default).
# +<command> allow the execution of that command.
# may be used with `|` for allowing subcommands (e.g "+config|get")
# -<command> disallow the execution of that command.
# may be used with `|` for blocking subcommands (e.g "-config|set")
# +@<category> allow the execution of all the commands in such category
# with valid categories are like @admin, @set, @sortedset, ...
# and so forth, see the full list in the server.c file where
# the redis command table is described and defined.
# the special category @all means all the commands, but currently
# present in the server, and that will be loaded in the future
# via modules.
# +<command>|first-arg allow a specific first argument of an otherwise
# disabled command. it is only supported on commands with
# no sub-commands, and is not allowed as negative form
# like -select|1, only additive starting with "+". this
# feature is deprecated and may be removed in the future.
# allcommands alias for +@all. note that it implies the ability to execute
# all the future commands loaded via the modules system.
# nocommands alias for -@all.
# ~<pattern> add a pattern of keys that can be mentioned as part of
# commands. for instance ~* allows all the keys. the pattern
# is a glob-style pattern like the one of keys.
# it is possible to specify multiple patterns.
# %r~<pattern> add key read pattern that specifies which keys can be read
# from.
# %w~<pattern> add key write pattern that specifies which keys can be
# written to.
# allkeys alias for ~*
# resetkeys flush the list of allowed keys patterns.
# &<pattern> add a glob-style pattern of pub/sub channels that can be
# accessed by the user. it is possible to specify multiple channel
# patterns.
# allchannels alias for &*
# resetchannels flush the list of allowed channel patterns.
# ><password> add this password to the list of valid password for the user.
# for example >mypass will add "mypass" to the list.
# this directive clears the "nopass" flag (see later).
# <<password> remove this password from the list of valid passwords.
# nopass all the set passwords of the user are removed, and the user
# is flagged as requiring no password: it means that every
# password will work against this user. if this directive is
# used for the default user, every new connection will be
# immediately authenticated with the default user without
# any explicit auth command required. note that the "resetpass"
# directive will clear this condition.
# resetpass flush the list of allowed passwords. moreover removes the
# "nopass" status. after "resetpass" the user has no associated
# passwords and there is no way to authenticate without adding
# some password (or setting it as "nopass" later).
# reset performs the following actions: resetpass, resetkeys, off,
# -@all. the user returns to the same state it has immediately
# after its creation.
# (<options>) create a new selector with the options specified within the
# parentheses and attach it to the user. each option should be
# space separated. the first character must be ( and the last
# character must be ).
# clearselectors remove all of the currently attached selectors.
# note this does not change the "root" user permissions,
# which are the permissions directly applied onto the
# user (outside the parentheses).
#
# acl rules can be specified in any order: for instance you can start with
# passwords, then flags, or key patterns. however note that the additive
# and subtractive rules will change meaning depending on the ordering.
# for instance see the following example:
#
# user alice on +@all -debug ~* >somepassword
#
# this will allow "alice" to use all the commands with the exception of the
# debug command, since +@all added all the commands to the set of the commands
# alice can use, and later debug was removed. however if we invert the order
# of two acl rules the result will be different:
#
# user alice on -debug +@all ~* >somepassword
#
# now debug was removed when alice had yet no commands in the set of allowed
# commands, later all the commands are added, so the user will be able to
# execute everything.
#
# basically acl rules are processed left-to-right.
#
# the following is a list of command categories and their meanings:
# * keyspace - writing or reading from keys, databases, or their metadata
# in a type agnostic way. includes del, restore, dump, rename, exists, dbsize,
# keys, expire, ttl, flushall, etc. commands that may modify the keyspace,
# key or metadata will also have `write` category. commands that only read
# the keyspace, key or metadata will have the `read` category.
# * read - reading from keys (values or metadata). note that commands that don't
# interact with keys, will not have either `read` or `write`.
# * write - writing to keys (values or metadata)
# * admin - administrative commands. normal applications will never need to use
# these. includes replicaof, config, debug, save, monitor, acl, shutdown, etc.
# * dangerous - potentially dangerous (each should be considered with care for
# various reasons). this includes flushall, migrate, restore, sort, keys,
# client, debug, info, config, save, replicaof, etc.
# * connection - commands affecting the connection or other connections.
# this includes auth, select, command, client, echo, ping, etc.
# * blocking - potentially blocking the connection until released by another
# command.
# * fast - fast o(1) commands. may loop on the number of arguments, but not the
# number of elements in the key.
# * slow - all commands that are not fast.
# * pubsub - publish / subscribe related
# * transaction - watch / multi / exec related commands.
# * scripting - scripting related.
# * set - data type: sets related.
# * sortedset - data type: zsets related.
# * list - data type: lists related.
# * hash - data type: hashes related.
# * string - data type: strings related.
# * bitmap - data type: bitmaps related.
# * hyperloglog - data type: hyperloglog related.
# * geo - data type: geo related.
# * stream - data type: streams related.
#
# for more information about acl configuration please refer to
# the redis web site at https://redis.io/topics/acl
# acl log
#
# the acl log tracks failed commands and authentication events associated
# with acls. the acl log is useful to troubleshoot failed commands blocked
# by acls. the acl log is stored in memory. you can reclaim memory with
# acl log reset. define the maximum entry length of the acl log below.
acllog-max-len 128
# using an external acl file
#
# instead of configuring users here in this file, it is possible to use
# a stand-alone file just listing users. the two methods cannot be mixed:
# if you configure users here and at the same time you activate the external
# acl file, the server will refuse to start.
#
# the format of the external acl user file is exactly the same as the
# format that is used inside redis.conf to describe users.
#
# aclfile /etc/redis/users.acl
# important note: starting with redis 6 "requirepass" is just a compatibility
# layer on top of the new acl system. the option effect will be just setting
# the password for the default user. clients will still authenticate using
# auth <password> as usually, or more explicitly with auth default <password>
# if they follow the new protocol: both will work.
#
# the requirepass is not compatible with aclfile option and the acl load
# command, these will cause requirepass to be ignored.
#
# requirepass foobared
# new users are initialized with restrictive permissions by default, via the
# equivalent of this acl rule 'off resetkeys -@all'. starting with redis 6.2, it
# is possible to manage access to pub/sub channels with acl rules as well. the
# default pub/sub channels permission if new users is controlled by the
# acl-pubsub-default configuration directive, which accepts one of these values:
#
# allchannels: grants access to all pub/sub channels
# resetchannels: revokes access to all pub/sub channels
#
# from redis 7.0, acl-pubsub-default defaults to 'resetchannels' permission.
#
# acl-pubsub-default resetchannels
# command renaming (deprecated).
#
# ------------------------------------------------------------------------
# warning: avoid using this option if possible. instead use acls to remove
# commands from the default user, and put them only in some admin user you
# create for administrative purposes.
# ------------------------------------------------------------------------
#
# it is possible to change the name of dangerous commands in a shared
# environment. for instance the config command may be renamed into something
# hard to guess so that it will still be available for internal-use tools
# but not available for general clients.
#
# example:
#
# rename-command config b840fc02d524045429941cc15f59e41cb7be6c52
#
# it is also possible to completely kill a command by renaming it into
# an empty string:
#
# rename-command config ""
#
# please note that changing the name of commands that are logged into the
# aof file or transmitted to replicas may cause problems.
################################### clients ####################################
# set the max number of connected clients at the same time. by default
# this limit is set to 10000 clients, however if the redis server is not
# able to configure the process file limit to allow for the specified limit
# the max number of allowed clients is set to the current file limit
# minus 32 (as redis reserves a few file descriptors for internal uses).
#
# once the limit is reached redis will close all the new connections sending
# an error 'max number of clients reached'.
#
# important: when redis cluster is used, the max number of connections is also
# shared with the cluster bus: every node in the cluster will use two
# connections, one incoming and another outgoing. it is important to size the
# limit accordingly in case of very large clusters.
#
# maxclients 10000
############################## memory management ################################
# set a memory usage limit to the specified amount of bytes.
# when the memory limit is reached redis will try to remove keys
# according to the eviction policy selected (see maxmemory-policy).
#
# if redis can't remove keys according to the policy, or if the policy is
# set to 'noeviction', redis will start to reply with errors to commands
# that would use more memory, like set, lpush, and so on, and will continue
# to reply to read-only commands like get.
#
# this option is usually useful when using redis as an lru or lfu cache, or to
# set a hard memory limit for an instance (using the 'noeviction' policy).
#
# warning: if you have replicas attached to an instance with maxmemory on,
# the size of the output buffers needed to feed the replicas are subtracted
# from the used memory count, so that network problems / resyncs will
# not trigger a loop where keys are evicted, and in turn the output
# buffer of replicas is full with dels of keys evicted triggering the deletion
# of more keys, and so forth until the database is completely emptied.
#
# in short... if you have replicas attached it is suggested that you set a lower
# limit for maxmemory so that there is some free ram on the system for replica
# output buffers (but this is not needed if the policy is 'noeviction').
#
# maxmemory <bytes>
# maxmemory policy: how redis will select what to remove when maxmemory
# is reached. you can select one from the following behaviors:
#
# volatile-lru -> evict using approximated lru, only keys with an expire set.
# allkeys-lru -> evict any key using approximated lru.
# volatile-lfu -> evict using approximated lfu, only keys with an expire set.
# allkeys-lfu -> evict any key using approximated lfu.
# volatile-random -> remove a random key having an expire set.
# allkeys-random -> remove a random key, any key.
# volatile-ttl -> remove the key with the nearest expire time (minor ttl)
# noeviction -> don't evict anything, just return an error on write operations.
#
# lru means least recently used
# lfu means least frequently used
#
# both lru, lfu and volatile-ttl are implemented using approximated
# randomized algorithms.
#
# note: with any of the above policies, when there are no suitable keys for
# eviction, redis will return an error on write operations that require
# more memory. these are usually commands that create new keys, add data or
# modify existing keys. a few examples are: set, incr, hset, lpush, sunionstore,
# sort (due to the store argument), and exec (if the transaction includes any
# command that requires memory).
#
# the default is:
#
# maxmemory-policy noeviction
# lru, lfu and minimal ttl algorithms are not precise algorithms but approximated
# algorithms (in order to save memory), so you can tune it for speed or
# accuracy. by default redis will check five keys and pick the one that was
# used least recently, you can change the sample size using the following
# configuration directive.
#
# the default of 5 produces good enough results. 10 approximates very closely
# true lru but costs more cpu. 3 is faster but not very accurate.
#
# maxmemory-samples 5
# eviction processing is designed to function well with the default setting.
# if there is an unusually large amount of write traffic, this value may need to
# be increased. decreasing this value may reduce latency at the risk of
# eviction processing effectiveness
# 0 = minimum latency, 10 = default, 100 = process without regard to latency
#
# maxmemory-eviction-tenacity 10
# starting from redis 5, by default a replica will ignore its maxmemory setting
# (unless it is promoted to master after a failover or manually). it means
# that the eviction of keys will be just handled by the master, sending the
# del commands to the replica as keys evict in the master side.
#
# this behavior ensures that masters and replicas stay consistent, and is usually
# what you want, however if your replica is writable, or you want the replica
# to have a different memory setting, and you are sure all the writes performed
# to the replica are idempotent, then you may change this default (but be sure
# to understand what you are doing).
#
# note that since the replica by default does not evict, it may end using more
# memory than the one set via maxmemory (there are certain buffers that may
# be larger on the replica, or data structures may sometimes take more memory
# and so forth). so make sure you monitor your replicas and make sure they
# have enough memory to never hit a real out-of-memory condition before the
# master hits the configured maxmemory setting.
#
# replica-ignore-maxmemory yes
# redis reclaims expired keys in two ways: upon access when those keys are
# found to be expired, and also in background, in what is called the
# "active expire key". the key space is slowly and interactively scanned
# looking for expired keys to reclaim, so that it is possible to free memory
# of keys that are expired and will never be accessed again in a short time.
#
# the default effort of the expire cycle will try to avoid having more than
# ten percent of expired keys still in memory, and will try to avoid consuming
# more than 25% of total memory and to add latency to the system. however
# it is possible to increase the expire "effort" that is normally set to
# "1", to a greater value, up to the value "10". at its maximum value the
# system will use more cpu, longer cycles (and technically may introduce
# more latency), and will tolerate less already expired keys still present
# in the system. it's a tradeoff between memory, cpu and latency.
#
# active-expire-effort 1
############################# lazy freeing ####################################
# redis has two primitives to delete keys. one is called del and is a blocking
# deletion of the object. it means that the server stops processing new commands
# in order to reclaim all the memory associated with an object in a synchronous
# way. if the key deleted is associated with a small object, the time needed
# in order to execute the del command is very small and comparable to most other
# o(1) or o(log_n) commands in redis. however if the key is associated with an
# aggregated value containing millions of elements, the server can block for
# a long time (even seconds) in order to complete the operation.
#
# for the above reasons redis also offers non blocking deletion primitives
# such as unlink (non blocking del) and the async option of flushall and
# flushdb commands, in order to reclaim memory in background. those commands
# are executed in constant time. another thread will incrementally free the
# object in the background as fast as possible.
#
# del, unlink and async option of flushall and flushdb are user-controlled.
# it's up to the design of the application to understand when it is a good
# idea to use one or the other. however the redis server sometimes has to
# delete keys or flush the whole database as a side effect of other operations.
# specifically redis deletes objects independently of a user call in the
# following scenarios:
#
# 1) on eviction, because of the maxmemory and maxmemory policy configurations,
# in order to make room for new data, without going over the specified
# memory limit.
# 2) because of expire: when a key with an associated time to live (see the
# expire command) must be deleted from memory.
# 3) because of a side effect of a command that stores data on a key that may
# already exist. for example the rename command may delete the old key
# content when it is replaced with another one. similarly sunionstore
# or sort with store option may delete existing keys. the set command
# itself removes any old content of the specified key in order to replace
# it with the specified string.
# 4) during replication, when a replica performs a full resynchronization with
# its master, the content of the whole database is removed in order to
# load the rdb file just transferred.
#
# in all the above cases the default is to delete objects in a blocking way,
# like if del was called. however you can configure each case specifically
# in order to instead release memory in a non-blocking way like if unlink
# was called, using the following configuration directives.
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
replica-lazy-flush no
# it is also possible, for the case when to replace the user code del calls
# with unlink calls is not easy, to modify the default behavior of the del
# command to act exactly like unlink, using the following configuration
# directive:
lazyfree-lazy-user-del no
# flushdb, flushall, script flush and function flush support both asynchronous and synchronous
# deletion, which can be controlled by passing the [sync|async] flags into the
# commands. when neither flag is passed, this directive will be used to determine
# if the data should be deleted asynchronously.
lazyfree-lazy-user-flush no
################################ threaded i/o #################################
# redis is mostly single threaded, however there are certain threaded
# operations such as unlink, slow i/o accesses and other things that are
# performed on side threads.
#
# now it is also possible to handle redis clients socket reads and writes
# in different i/o threads. since especially writing is so slow, normally
# redis users use pipelining in order to speed up the redis performances per
# core, and spawn multiple instances in order to scale more. using i/o
# threads it is possible to easily speedup two times redis without resorting
# to pipelining nor sharding of the instance.
#
# by default threading is disabled, we suggest enabling it only in machines
# that have at least 4 or more cores, leaving at least one spare core.
# using more than 8 threads is unlikely to help much. we also recommend using
# threaded i/o only if you actually have performance problems, with redis
# instances being able to use a quite big percentage of cpu time, otherwise
# there is no point in using this feature.
#
# so for instance if you have a four cores boxes, try to use 2 or 3 i/o
# threads, if you have a 8 cores, try to use 6 threads. in order to
# enable i/o threads use the following configuration directive:
#
# io-threads 4
#
# setting io-threads to 1 will just use the main thread as usual.
# when i/o threads are enabled, we only use threads for writes, that is
# to thread the write(2) syscall and transfer the client buffers to the
# socket. however it is also possible to enable threading of reads and
# protocol parsing using the following configuration directive, by setting
# it to yes:
#
# io-threads-do-reads no
#
# usually threading reads doesn't help much.
#
# note 1: this configuration directive cannot be changed at runtime via
# config set. also, this feature currently does not work when ssl is
# enabled.
#
# note 2: if you want to test the redis speedup using redis-benchmark, make
# sure you also run the benchmark itself in threaded mode, using the
# --threads option to match the number of redis threads, otherwise you'll not
# be able to notice the improvements.
############################ kernel oom control ##############################
# on linux, it is possible to hint the kernel oom killer on what processes
# should be killed first when out of memory.
#
# enabling this feature makes redis actively control the oom_score_adj value
# for all its processes, depending on their role. the default scores will
# attempt to have background child processes killed before all others, and
# replicas killed before masters.
#
# redis supports these options:
#
# no: don't make changes to oom-score-adj (default).
# yes: alias to "relative" see below.
# absolute: values in oom-score-adj-values are written as is to the kernel.
# relative: values are used relative to the initial value of oom_score_adj when
# the server starts and are then clamped to a range of -1000 to 1000.
# because typically the initial value is 0, they will often match the
# absolute values.
oom-score-adj no
# when oom-score-adj is used, this directive controls the specific values used
# for master, replica and background child processes. values range -2000 to
# 2000 (higher means more likely to be killed).
#
# unprivileged processes (not root, and without cap_sys_resource capabilities)
# can freely increase their value, but not decrease it below its initial
# settings. this means that setting oom-score-adj to "relative" and setting the
# oom-score-adj-values to positive values will always succeed.
oom-score-adj-values 0 200 800
#################### kernel transparent hugepage control ######################
# usually the kernel transparent huge pages control is set to "madvise" or
# or "never" by default (/sys/kernel/mm/transparent_hugepage/enabled), in which
# case this config has no effect. on systems in which it is set to "always",
# redis will attempt to disable it specifically for the redis process in order
# to avoid latency problems specifically with fork(2) and cow.
# if for some reason you prefer to keep it enabled, you can set this config to
# "no" and the kernel global to "always".
disable-thp yes
############################## append only mode ###############################
# by default redis asynchronously dumps the dataset on disk. this mode is
# good enough in many applications, but an issue with the redis process or
# a power outage may result into a few minutes of writes lost (depending on
# the configured save points).
#
# the append only file is an alternative persistence mode that provides
# much better durability. for instance using the default data fsync policy
# (see later in the config file) redis can lose just one second of writes in a
# dramatic event like a server power outage, or a single write if something
# wrong with the redis process itself happens, but the operating system is
# still running correctly.
#
# aof and rdb persistence can be enabled at the same time without problems.
# if the aof is enabled on startup redis will load the aof, that is the file
# with the better durability guarantees.
#
# please check https://redis.io/topics/persistence for more information.
appendonly no
# the base name of the append only file.
#
# redis 7 and newer use a set of append-only files to persist the dataset
# and changes applied to it. there are two basic types of files in use:
#
# - base files, which are a snapshot representing the complete state of the
# dataset at the time the file was created. base files can be either in
# the form of rdb (binary serialized) or aof (textual commands).
# - incremental files, which contain additional commands that were applied
# to the dataset following the previous file.
#
# in addition, manifest files are used to track the files and the order in
# which they were created and should be applied.
#
# append-only file names are created by redis following a specific pattern.
# the file name's prefix is based on the 'appendfilename' configuration
# parameter, followed by additional information about the sequence and type.
#
# for example, if appendfilename is set to appendonly.aof, the following file
# names could be derived:
#
# - appendonly.aof.1.base.rdb as a base file.
# - appendonly.aof.1.incr.aof, appendonly.aof.2.incr.aof as incremental files.
# - appendonly.aof.manifest as a manifest file.
appendfilename "appendonly.aof"
# for convenience, redis stores all persistent append-only files in a dedicated
# directory. the name of the directory is determined by the appenddirname
# configuration parameter.
appenddirname "appendonlydir"
# the fsync() call tells the operating system to actually write data on disk
# instead of waiting for more data in the output buffer. some os will really flush
# data on disk, some other os will just try to do it asap.
#
# redis supports three different modes:
#
# no: don't fsync, just let the os flush the data when it wants. faster.
# always: fsync after every write to the append only log. slow, safest.
# everysec: fsync only one time every second. compromise.
#
# the default is "everysec", as that's usually the right compromise between
# speed and data safety. it's up to you to understand if you can relax this to
# "no" that will let the operating system flush the output buffer when
# it wants, for better performances (but if you can live with the idea of
# some data loss consider the default persistence mode that's snapshotting),
# or on the contrary, use "always" that's very slow but a bit safer than
# everysec.
#
# more details please check the following article:
# http://antirez.com/post/redis-persistence-demystified.html
#
# if unsure, use "everysec".
# appendfsync always
appendfsync everysec
# appendfsync no
# when the aof fsync policy is set to always or everysec, and a background
# saving process (a background save or aof log background rewriting) is
# performing a lot of i/o against the disk, in some linux configurations
# redis may block too long on the fsync() call. note that there is no fix for
# this currently, as even performing fsync in a different thread will block
# our synchronous write(2) call.
#
# in order to mitigate this problem it's possible to use the following option
# that will prevent fsync() from being called in the main process while a
# bgsave or bgrewriteaof is in progress.
#
# this means that while another child is saving, the durability of redis is
# the same as "appendfsync no". in practical terms, this means that it is
# possible to lose up to 30 seconds of log in the worst scenario (with the
# default linux settings).
#
# if you have latency problems turn this to "yes". otherwise leave it as
# "no" that is the safest pick from the point of view of durability.
no-appendfsync-on-rewrite no
# automatic rewrite of the append only file.
# redis is able to automatically rewrite the log file implicitly calling
# bgrewriteaof when the aof log size grows by the specified percentage.
#
# this is how it works: redis remembers the size of the aof file after the
# latest rewrite (if no rewrite has happened since the restart, the size of
# the aof at startup is used).
#
# this base size is compared to the current size. if the current size is
# bigger than the specified percentage, the rewrite is triggered. also
# you need to specify a minimal size for the aof file to be rewritten, this
# is useful to avoid rewriting the aof file even if the percentage increase
# is reached but it is still pretty small.
#
# specify a percentage of zero in order to disable the automatic aof
# rewrite feature.
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# an aof file may be found to be truncated at the end during the redis
# startup process, when the aof data gets loaded back into memory.
# this may happen when the system where redis is running
# crashes, especially when an ext4 filesystem is mounted without the
# data=ordered option (however this can't happen when redis itself
# crashes or aborts but the operating system still works correctly).
#
# redis can either exit with an error when this happens, or load as much
# data as possible (the default now) and start if the aof file is found
# to be truncated at the end. the following option controls this behavior.
#
# if aof-load-truncated is set to yes, a truncated aof file is loaded and
# the redis server starts emitting a log to inform the user of the event.
# otherwise if the option is set to no, the server aborts with an error
# and refuses to start. when the option is set to no, the user requires
# to fix the aof file using the "redis-check-aof" utility before to restart
# the server.
#
# note that if the aof file will be found to be corrupted in the middle
# the server will still exit with an error. this option only applies when
# redis will try to read more data from the aof file but not enough bytes
# will be found.
aof-load-truncated yes
# redis can create append-only base files in either rdb or aof formats. using
# the rdb format is always faster and more efficient, and disabling it is only
# supported for backward compatibility purposes.
aof-use-rdb-preamble yes
# redis supports recording timestamp annotations in the aof to support restoring
# the data from a specific point-in-time. however, using this capability changes
# the aof format in a way that may not be compatible with existing aof parsers.
aof-timestamp-enabled no
################################ shutdown #####################################
# maximum time to wait for replicas when shutting down, in seconds.
#
# during shut down, a grace period allows any lagging replicas to catch up with
# the latest replication offset before the master exists. this period can
# prevent data loss, especially for deployments without configured disk backups.
#
# the 'shutdown-timeout' value is the grace period's duration in seconds. it is
# only applicable when the instance has replicas. to disable the feature, set
# the value to 0.
#
# shutdown-timeout 10
# when redis receives a sigint or sigterm, shutdown is initiated and by default
# an rdb snapshot is written to disk in a blocking operation if save points are configured.
# the options used on signaled shutdown can include the following values:
# default: saves rdb snapshot only if save points are configured.
# waits for lagging replicas to catch up.
# save: forces a db saving operation even if no save points are configured.
# nosave: prevents db saving operation even if one or more save points are configured.
# now: skips waiting for lagging replicas.
# force: ignores any errors that would normally prevent the server from exiting.
#
# any combination of values is allowed as long as "save" and "nosave" are not set simultaneously.
# example: "nosave force now"
#
# shutdown-on-sigint default
# shutdown-on-sigterm default
################ non-deterministic long blocking commands #####################
# maximum time in milliseconds for eval scripts, functions and in some cases
# modules' commands before redis can start processing or rejecting other clients.
#
# if the maximum execution time is reached redis will start to reply to most
# commands with a busy error.
#
# in this state redis will only allow a handful of commands to be executed.
# for instance, script kill, function kill, shutdown nosave and possibly some
# module specific 'allow-busy' commands.
#
# script kill and function kill will only be able to stop a script that did not
# yet call any write commands, so shutdown nosave may be the only way to stop
# the server in the case a write command was already issued by the script when
# the user doesn't want to wait for the natural termination of the script.
#
# the default is 5 seconds. it is possible to set it to 0 or a negative value
# to disable this mechanism (uninterrupted execution). note that in the past
# this config had a different name, which is now an alias, so both of these do
# the same:
# lua-time-limit 5000
# busy-reply-threshold 5000
################################ redis cluster ###############################
# normal redis instances can't be part of a redis cluster; only nodes that are
# started as cluster nodes can. in order to start a redis instance as a
# cluster node enable the cluster support uncommenting the following:
#
# cluster-enabled yes
# every cluster node has a cluster configuration file. this file is not
# intended to be edited by hand. it is created and updated by redis nodes.
# every redis cluster node requires a different cluster configuration file.
# make sure that instances running in the same system do not have
# overlapping cluster configuration file names.
#
# cluster-config-file nodes-6379.conf
# cluster node timeout is the amount of milliseconds a node must be unreachable
# for it to be considered in failure state.
# most other internal time limits are a multiple of the node timeout.
#
# cluster-node-timeout 15000
# the cluster port is the port that the cluster bus will listen for inbound connections on. when set
# to the default value, 0, it will be bound to the command port + 10000. setting this value requires
# you to specify the cluster bus port when executing cluster meet.
# cluster-port 0
# a replica of a failing master will avoid to start a failover if its data
# looks too old.
#
# there is no simple way for a replica to actually have an exact measure of
# its "data age", so the following two checks are performed:
#
# 1) if there are multiple replicas able to failover, they exchange messages
# in order to try to give an advantage to the replica with the best
# replication offset (more data from the master processed).
# replicas will try to get their rank by offset, and apply to the start
# of the failover a delay proportional to their rank.
#
# 2) every single replica computes the time of the last interaction with
# its master. this can be the last ping or command received (if the master
# is still in the "connected" state), or the time that elapsed since the
# disconnection with the master (if the replication link is currently down).
# if the last interaction is too old, the replica will not try to failover
# at all.
#
# the point "2" can be tuned by user. specifically a replica will not perform
# the failover if, since the last interaction with the master, the time
# elapsed is greater than:
#
# (node-timeout * cluster-replica-validity-factor) + repl-ping-replica-period
#
# so for example if node-timeout is 30 seconds, and the cluster-replica-validity-factor
# is 10, and assuming a default repl-ping-replica-period of 10 seconds, the
# replica will not try to failover if it was not able to talk with the master
# for longer than 310 seconds.
#
# a large cluster-replica-validity-factor may allow replicas with too old data to failover
# a master, while a too small value may prevent the cluster from being able to
# elect a replica at all.
#
# for maximum availability, it is possible to set the cluster-replica-validity-factor
# to a value of 0, which means, that replicas will always try to failover the
# master regardless of the last time they interacted with the master.
# (however they'll always try to apply a delay proportional to their
# offset rank).
#
# zero is the only value able to guarantee that when all the partitions heal
# the cluster will always be able to continue.
#
# cluster-replica-validity-factor 10
# cluster replicas are able to migrate to orphaned masters, that are masters
# that are left without working replicas. this improves the cluster ability
# to resist to failures as otherwise an orphaned master can't be failed over
# in case of failure if it has no working replicas.
#
# replicas migrate to orphaned masters only if there are still at least a
# given number of other working replicas for their old master. this number
# is the "migration barrier". a migration barrier of 1 means that a replica
# will migrate only if there is at least 1 other working replica for its master
# and so forth. it usually reflects the number of replicas you want for every
# master in your cluster.
#
# default is 1 (replicas migrate only if their masters remain with at least
# one replica). to disable migration just set it to a very large value or
# set cluster-allow-replica-migration to 'no'.
# a value of 0 can be set but is useful only for debugging and dangerous
# in production.
#
# cluster-migration-barrier 1
# turning off this option allows to use less automatic cluster configuration.
# it both disables migration to orphaned masters and migration from masters
# that became empty.
#
# default is 'yes' (allow automatic migrations).
#
# cluster-allow-replica-migration yes
# by default redis cluster nodes stop accepting queries if they detect there
# is at least a hash slot uncovered (no available node is serving it).
# this way if the cluster is partially down (for example a range of hash slots
# are no longer covered) all the cluster becomes, eventually, unavailable.
# it automatically returns available as soon as all the slots are covered again.
#
# however sometimes you want the subset of the cluster which is working,
# to continue to accept queries for the part of the key space that is still
# covered. in order to do so, just set the cluster-require-full-coverage
# option to no.
#
# cluster-require-full-coverage yes
# this option, when set to yes, prevents replicas from trying to failover its
# master during master failures. however the replica can still perform a
# manual failover, if forced to do so.
#
# this is useful in different scenarios, especially in the case of multiple
# data center operations, where we want one side to never be promoted if not
# in the case of a total dc failure.
#
# cluster-replica-no-failover no
# this option, when set to yes, allows nodes to serve read traffic while the
# cluster is in a down state, as long as it believes it owns the slots.
#
# this is useful for two cases. the first case is for when an application
# doesn't require consistency of data during node failures or network partitions.
# one example of this is a cache, where as long as the node has the data it
# should be able to serve it.
#
# the second use case is for configurations that don't meet the recommended
# three shards but want to enable cluster mode and scale later. a
# master outage in a 1 or 2 shard configuration causes a read/write outage to the
# entire cluster without this option set, with it set there is only a write outage.
# without a quorum of masters, slot ownership will not change automatically.
#
# cluster-allow-reads-when-down no
# this option, when set to yes, allows nodes to serve pubsub shard traffic while
# the cluster is in a down state, as long as it believes it owns the slots.
#
# this is useful if the application would like to use the pubsub feature even when
# the cluster global stable state is not ok. if the application wants to make sure only
# one shard is serving a given channel, this feature should be kept as yes.
#
# cluster-allow-pubsubshard-when-down yes
# cluster link send buffer limit is the limit on the memory usage of an individual
# cluster bus link's send buffer in bytes. cluster links would be freed if they exceed
# this limit. this is to primarily prevent send buffers from growing unbounded on links
# toward slow peers (e.g. pubsub messages being piled up).
# this limit is disabled by default. enable this limit when 'mem_cluster_links' info field
# and/or 'send-buffer-allocated' entries in the 'cluster links` command output continuously increase.
# minimum limit of 1gb is recommended so that cluster link buffer can fit in at least a single
# pubsub message by default. (client-query-buffer-limit default value is 1gb)
#
# cluster-link-sendbuf-limit 0
# clusters can configure their announced hostname using this config. this is a common use case for
# applications that need to use tls server name indication (sni) or dealing with dns based
# routing. by default this value is only shown as additional metadata in the cluster slots
# command, but can be changed using 'cluster-preferred-endpoint-type' config. this value is
# communicated along the clusterbus to all nodes, setting it to an empty string will remove
# the hostname and also propagate the removal.
#
# cluster-announce-hostname ""
# clusters can advertise how clients should connect to them using either their ip address,
# a user defined hostname, or by declaring they have no endpoint. which endpoint is
# shown as the preferred endpoint is set by using the cluster-preferred-endpoint-type
# config with values 'ip', 'hostname', or 'unknown-endpoint'. this value controls how
# the endpoint returned for moved/asking requests as well as the first field of cluster slots.
# if the preferred endpoint type is set to hostname, but no announced hostname is set, a '?'
# will be returned instead.
#
# when a cluster advertises itself as having an unknown endpoint, it's indicating that
# the server doesn't know how clients can reach the cluster. this can happen in certain
# networking situations where there are multiple possible routes to the node, and the
# server doesn't know which one the client took. in this case, the server is expecting
# the client to reach out on the same endpoint it used for making the last request, but use
# the port provided in the response.
#
# cluster-preferred-endpoint-type ip
# in order to setup your cluster make sure to read the documentation
# available at https://redis.io web site.
########################## cluster docker/nat support ########################
# in certain deployments, redis cluster nodes address discovery fails, because
# addresses are nat-ted or because ports are forwarded (the typical case is
# docker and other containers).
#
# in order to make redis cluster working in such environments, a static
# configuration where each node knows its public address is needed. the
# following four options are used for this scope, and are:
#
# * cluster-announce-ip
# * cluster-announce-port
# * cluster-announce-tls-port
# * cluster-announce-bus-port
#
# each instructs the node about its address, client ports (for connections
# without and with tls) and cluster message bus port. the information is then
# published in the header of the bus packets so that other nodes will be able to
# correctly map the address of the node publishing the information.
#
# if cluster-tls is set to yes and cluster-announce-tls-port is omitted or set
# to zero, then cluster-announce-port refers to the tls port. note also that
# cluster-announce-tls-port has no effect if cluster-tls is set to no.
#
# if the above options are not used, the normal redis cluster auto-detection
# will be used instead.
#
# note that when remapped, the bus port may not be at the fixed offset of
# clients port + 10000, so you can specify any port and bus-port depending
# on how they get remapped. if the bus-port is not set, a fixed offset of
# 10000 will be used as usual.
#
# example:
#
# cluster-announce-ip 10.1.1.5
# cluster-announce-tls-port 6379
# cluster-announce-port 0
# cluster-announce-bus-port 6380
################################## slow log ###################################
# the redis slow log is a system to log queries that exceeded a specified
# execution time. the execution time does not include the i/o operations
# like talking with the client, sending the reply and so forth,
# but just the time needed to actually execute the command (this is the only
# stage of command execution where the thread is blocked and can not serve
# other requests in the meantime).
#
# you can configure the slow log with two parameters: one tells redis
# what is the execution time, in microseconds, to exceed in order for the
# command to get logged, and the other parameter is the length of the
# slow log. when a new command is logged the oldest one is removed from the
# queue of logged commands.
# the following time is expressed in microseconds, so 1000000 is equivalent
# to one second. note that a negative number disables the slow log, while
# a value of zero forces the logging of every command.
slowlog-log-slower-than 10000
# there is no limit to this length. just be aware that it will consume memory.
# you can reclaim memory used by the slow log with slowlog reset.
slowlog-max-len 128
################################ latency monitor ##############################
# the redis latency monitoring subsystem samples different operations
# at runtime in order to collect data related to possible sources of
# latency of a redis instance.
#
# via the latency command this information is available to the user that can
# print graphs and obtain reports.
#
# the system only logs operations that were performed in a time equal or
# greater than the amount of milliseconds specified via the
# latency-monitor-threshold configuration directive. when its value is set
# to zero, the latency monitor is turned off.
#
# by default latency monitoring is disabled since it is mostly not needed
# if you don't have latency issues, and collecting data has a performance
# impact, that while very small, can be measured under big load. latency
# monitoring can easily be enabled at runtime using the command
# "config set latency-monitor-threshold <milliseconds>" if needed.
latency-monitor-threshold 0
################################ latency tracking ##############################
# the redis extended latency monitoring tracks the per command latencies and enables
# exporting the percentile distribution via the info latencystats command,
# and cumulative latency distributions (histograms) via the latency command.
#
# by default, the extended latency monitoring is enabled since the overhead
# of keeping track of the command latency is very small.
# latency-tracking yes
# by default the exported latency percentiles via the info latencystats command
# are the p50, p99, and p999.
# latency-tracking-info-percentiles 50 99 99.9
############################# event notification ##############################
# redis can notify pub/sub clients about events happening in the key space.
# this feature is documented at https://redis.io/topics/notifications
#
# for instance if keyspace events notification is enabled, and a client
# performs a del operation on key "foo" stored in the database 0, two
# messages will be published via pub/sub:
#
# publish __keyspace@0__:foo del
# publish __keyevent@0__:del foo
#
# it is possible to select the events that redis will notify among a set
# of classes. every class is identified by a single character:
#
# k keyspace events, published with __keyspace@<db>__ prefix.
# e keyevent events, published with __keyevent@<db>__ prefix.
# g generic commands (non-type specific) like del, expire, rename, ...
# $ string commands
# l list commands
# s set commands
# h hash commands
# z sorted set commands
# x expired events (events generated every time a key expires)
# e evicted events (events generated when a key is evicted for maxmemory)
# n new key events (note: not included in the 'a' class)
# t stream commands
# d module key type events
# m key-miss events (note: it is not included in the 'a' class)
# a alias for g$lshzxetd, so that the "ake" string means all the events
# (except key-miss events which are excluded from 'a' due to their
# unique nature).
#
# the "notify-keyspace-events" takes as argument a string that is composed
# of zero or multiple characters. the empty string means that notifications
# are disabled.
#
# example: to enable list and generic events, from the point of view of the
# event name, use:
#
# notify-keyspace-events elg
#
# example 2: to get the stream of the expired keys subscribing to channel
# name __keyevent@0__:expired use:
#
# notify-keyspace-events ex
#
# by default all notifications are disabled because most users don't need
# this feature and the feature has some overhead. note that if you don't
# specify at least one of k or e, no events will be delivered.
notify-keyspace-events ""
############################### advanced config ###############################
# hashes are encoded using a memory efficient data structure when they have a
# small number of entries, and the biggest entry does not exceed a given
# threshold. these thresholds can be configured using the following directives.
hash-max-listpack-entries 512
hash-max-listpack-value 64
# lists are also encoded in a special way to save a lot of space.
# the number of entries allowed per internal list node can be specified
# as a fixed maximum size or a maximum number of elements.
# for a fixed maximum size, use -5 through -1, meaning:
# -5: max size: 64 kb <-- not recommended for normal workloads
# -4: max size: 32 kb <-- not recommended
# -3: max size: 16 kb <-- probably not recommended
# -2: max size: 8 kb <-- good
# -1: max size: 4 kb <-- good
# positive numbers mean store up to _exactly_ that number of elements
# per list node.
# the highest performing option is usually -2 (8 kb size) or -1 (4 kb size),
# but if your use case is unique, adjust the settings as necessary.
list-max-listpack-size -2
# lists may also be compressed.
# compress depth is the number of quicklist ziplist nodes from *each* side of
# the list to *exclude* from compression. the head and tail of the list
# are always uncompressed for fast push/pop operations. settings are:
# 0: disable all list compression
# 1: depth 1 means "don't start compressing until after 1 node into the list,
# going from either the head or tail"
# so: [head]->node->node->...->node->[tail]
# [head], [tail] will always be uncompressed; inner nodes will compress.
# 2: [head]->[next]->node->node->...->node->[prev]->[tail]
# 2 here means: don't compress head or head->next or tail->prev or tail,
# but compress all nodes between them.
# 3: [head]->[next]->[next]->node->node->...->node->[prev]->[prev]->[tail]
# etc.
list-compress-depth 0
# sets have a special encoding in just one case: when a set is composed
# of just strings that happen to be integers in radix 10 in the range
# of 64 bit signed integers.
# the following configuration setting sets the limit in the size of the
# set in order to use this special memory saving encoding.
set-max-intset-entries 512
# similarly to hashes and lists, sorted sets are also specially encoded in
# order to save a lot of space. this encoding is only used when the length and
# elements of a sorted set are below the following limits:
zset-max-listpack-entries 128
zset-max-listpack-value 64
# hyperloglog sparse representation bytes limit. the limit includes the
# 16 bytes header. when an hyperloglog using the sparse representation crosses
# this limit, it is converted into the dense representation.
#
# a value greater than 16000 is totally useless, since at that point the
# dense representation is more memory efficient.
#
# the suggested value is ~ 3000 in order to have the benefits of
# the space efficient encoding without slowing down too much pfadd,
# which is o(n) with the sparse encoding. the value can be raised to
# ~ 10000 when cpu is not a concern, but space is, and the data set is
# composed of many hyperloglogs with cardinality in the 0 - 15000 range.
hll-sparse-max-bytes 3000
# streams macro node max size / items. the stream data structure is a radix
# tree of big nodes that encode multiple items inside. using this configuration
# it is possible to configure how big a single node can be in bytes, and the
# maximum number of items it may contain before switching to a new node when
# appending new stream entries. if any of the following settings are set to
# zero, the limit is ignored, so for instance it is possible to set just a
# max entries limit by setting max-bytes to 0 and max-entries to the desired
# value.
stream-node-max-bytes 4096
stream-node-max-entries 100
# active rehashing uses 1 millisecond every 100 milliseconds of cpu time in
# order to help rehashing the main redis hash table (the one mapping top-level
# keys to values). the hash table implementation redis uses (see dict.c)
# performs a lazy rehashing: the more operation you run into a hash table
# that is rehashing, the more rehashing "steps" are performed, so if the
# server is idle the rehashing is never complete and some more memory is used
# by the hash table.
#
# the default is to use this millisecond 10 times every second in order to
# actively rehash the main dictionaries, freeing memory when possible.
#
# if unsure:
# use "activerehashing no" if you have hard latency requirements and it is
# not a good thing in your environment that redis can reply from time to time
# to queries with 2 milliseconds delay.
#
# use "activerehashing yes" if you don't have such hard requirements but
# want to free memory asap when possible.
activerehashing yes
# the client output buffer limits can be used to force disconnection of clients
# that are not reading data from the server fast enough for some reason (a
# common reason is that a pub/sub client can't consume messages as fast as the
# publisher can produce them).
#
# the limit can be set differently for the three different classes of clients:
#
# normal -> normal clients including monitor clients
# replica -> replica clients
# pubsub -> clients subscribed to at least one pubsub channel or pattern
#
# the syntax of every client-output-buffer-limit directive is the following:
#
# client-output-buffer-limit <class> <hard limit> <soft limit> <soft seconds>
#
# a client is immediately disconnected once the hard limit is reached, or if
# the soft limit is reached and remains reached for the specified number of
# seconds (continuously).
# so for instance if the hard limit is 32 megabytes and the soft limit is
# 16 megabytes / 10 seconds, the client will get disconnected immediately
# if the size of the output buffers reach 32 megabytes, but will also get
# disconnected if the client reaches 16 megabytes and continuously overcomes
# the limit for 10 seconds.
#
# by default normal clients are not limited because they don't receive data
# without asking (in a push way), but just after a request, so only
# asynchronous clients may create a scenario where data is requested faster
# than it can read.
#
# instead there is a default limit for pubsub and replica clients, since
# subscribers and replicas receive data in a push fashion.
#
# note that it doesn't make sense to set the replica clients output buffer
# limit lower than the repl-backlog-size config (partial sync will succeed
# and then replica will get disconnected).
# such a configuration is ignored (the size of repl-backlog-size will be used).
# this doesn't have memory consumption implications since the replica client
# will share the backlog buffers memory.
#
# both the hard or the soft limit can be disabled by setting them to zero.
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit replica 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
# client query buffers accumulate new commands. they are limited to a fixed
# amount by default in order to avoid that a protocol desynchronization (for
# instance due to a bug in the client) will lead to unbound memory usage in
# the query buffer. however you can configure it here if you have very special
# needs, such us huge multi/exec requests or alike.
#
# client-query-buffer-limit 1gb
# in some scenarios client connections can hog up memory leading to oom
# errors or data eviction. to avoid this we can cap the accumulated memory
# used by all client connections (all pubsub and normal clients). once we
# reach that limit connections will be dropped by the server freeing up
# memory. the server will attempt to drop the connections using the most
# memory first. we call this mechanism "client eviction".
#
# client eviction is configured using the maxmemory-clients setting as follows:
# 0 - client eviction is disabled (default)
#
# a memory value can be used for the client eviction threshold,
# for example:
# maxmemory-clients 1g
#
# a percentage value (between 1% and 100%) means the client eviction threshold
# is based on a percentage of the maxmemory setting. for example to set client
# eviction at 5% of maxmemory:
# maxmemory-clients 5%
# in the redis protocol, bulk requests, that are, elements representing single
# strings, are normally limited to 512 mb. however you can change this limit
# here, but must be 1mb or greater
#
# proto-max-bulk-len 512mb
# redis calls an internal function to perform many background tasks, like
# closing connections of clients in timeout, purging expired keys that are
# never requested, and so forth.
#
# not all tasks are performed with the same frequency, but redis checks for
# tasks to perform according to the specified "hz" value.
#
# by default "hz" is set to 10. raising the value will use more cpu when
# redis is idle, but at the same time will make redis more responsive when
# there are many keys expiring at the same time, and timeouts may be
# handled with more precision.
#
# the range is between 1 and 500, however a value over 100 is usually not
# a good idea. most users should use the default of 10 and raise this up to
# 100 only in environments where very low latency is required.
hz 10
# normally it is useful to have an hz value which is proportional to the
# number of clients connected. this is useful in order, for instance, to
# avoid too many clients are processed for each background task invocation
# in order to avoid latency spikes.
#
# since the default hz value by default is conservatively set to 10, redis
# offers, and enables by default, the ability to use an adaptive hz value
# which will temporarily raise when there are many connected clients.
#
# when dynamic hz is enabled, the actual configured hz will be used
# as a baseline, but multiples of the configured hz value will be actually
# used as needed once more clients are connected. in this way an idle
# instance will use very little cpu time while a busy instance will be
# more responsive.
dynamic-hz yes
# when a child rewrites the aof file, if the following option is enabled
# the file will be fsync-ed every 4 mb of data generated. this is useful
# in order to commit the file to the disk more incrementally and avoid
# big latency spikes.
aof-rewrite-incremental-fsync yes
# when redis saves rdb file, if the following option is enabled
# the file will be fsync-ed every 4 mb of data generated. this is useful
# in order to commit the file to the disk more incrementally and avoid
# big latency spikes.
rdb-save-incremental-fsync yes
# redis lfu eviction (see maxmemory setting) can be tuned. however it is a good
# idea to start with the default settings and only change them after investigating
# how to improve the performances and how the keys lfu change over time, which
# is possible to inspect via the object freq command.
#
# there are two tunable parameters in the redis lfu implementation: the
# counter logarithm factor and the counter decay time. it is important to
# understand what the two parameters mean before changing them.
#
# the lfu counter is just 8 bits per key, it's maximum value is 255, so redis
# uses a probabilistic increment with logarithmic behavior. given the value
# of the old counter, when a key is accessed, the counter is incremented in
# this way:
#
# 1. a random number r between 0 and 1 is extracted.
# 2. a probability p is calculated as 1/(old_value*lfu_log_factor+1).
# 3. the counter is incremented only if r < p.
#
# the default lfu-log-factor is 10. this is a table of how the frequency
# counter changes with a different number of accesses with different
# logarithmic factors:
#
# +--------+------------+------------+------------+------------+------------+
# | factor | 100 hits | 1000 hits | 100k hits | 1m hits | 10m hits |
# +--------+------------+------------+------------+------------+------------+
# | 0 | 104 | 255 | 255 | 255 | 255 |
# +--------+------------+------------+------------+------------+------------+
# | 1 | 18 | 49 | 255 | 255 | 255 |
# +--------+------------+------------+------------+------------+------------+
# | 10 | 10 | 18 | 142 | 255 | 255 |
# +--------+------------+------------+------------+------------+------------+
# | 100 | 8 | 11 | 49 | 143 | 255 |
# +--------+------------+------------+------------+------------+------------+
#
# note: the above table was obtained by running the following commands:
#
# redis-benchmark -n 1000000 incr foo
# redis-cli object freq foo
#
# note 2: the counter initial value is 5 in order to give new objects a chance
# to accumulate hits.
#
# the counter decay time is the time, in minutes, that must elapse in order
# for the key counter to be divided by two (or decremented if it has a value
# less <= 10).
#
# the default value for the lfu-decay-time is 1. a special value of 0 means to
# decay the counter every time it happens to be scanned.
#
# lfu-log-factor 10
# lfu-decay-time 1
########################### active defragmentation #######################
#
# what is active defragmentation?
# -------------------------------
#
# active (online) defragmentation allows a redis server to compact the
# spaces left between small allocations and deallocations of data in memory,
# thus allowing to reclaim back memory.
#
# fragmentation is a natural process that happens with every allocator (but
# less so with jemalloc, fortunately) and certain workloads. normally a server
# restart is needed in order to lower the fragmentation, or at least to flush
# away all the data and create it again. however thanks to this feature
# implemented by oran agra for redis 4.0 this process can happen at runtime
# in a "hot" way, while the server is running.
#
# basically when the fragmentation is over a certain level (see the
# configuration options below) redis will start to create new copies of the
# values in contiguous memory regions by exploiting certain specific jemalloc
# features (in order to understand if an allocation is causing fragmentation
# and to allocate it in a better place), and at the same time, will release the
# old copies of the data. this process, repeated incrementally for all the keys
# will cause the fragmentation to drop back to normal values.
#
# important things to understand:
#
# 1. this feature is disabled by default, and only works if you compiled redis
# to use the copy of jemalloc we ship with the source code of redis.
# this is the default with linux builds.
#
# 2. you never need to enable this feature if you don't have fragmentation
# issues.
#
# 3. once you experience fragmentation, you can enable this feature when
# needed with the command "config set activedefrag yes".
#
# the configuration parameters are able to fine tune the behavior of the
# defragmentation process. if you are not sure about what they mean it is
# a good idea to leave the defaults untouched.
# active defragmentation is disabled by default
# activedefrag no
# minimum amount of fragmentation waste to start active defrag
# active-defrag-ignore-bytes 100mb
# minimum percentage of fragmentation to start active defrag
# active-defrag-threshold-lower 10
# maximum percentage of fragmentation at which we use maximum effort
# active-defrag-threshold-upper 100
# minimal effort for defrag in cpu percentage, to be used when the lower
# threshold is reached
# active-defrag-cycle-min 1
# maximal effort for defrag in cpu percentage, to be used when the upper
# threshold is reached
# active-defrag-cycle-max 25
# maximum number of set/hash/zset/list fields that will be processed from
# the main dictionary scan
# active-defrag-max-scan-fields 1000
# jemalloc background thread for purging will be enabled by default
jemalloc-bg-thread yes
# it is possible to pin different threads and processes of redis to specific
# cpus in your system, in order to maximize the performances of the server.
# this is useful both in order to pin different redis threads in different
# cpus, but also in order to make sure that multiple redis instances running
# in the same host will be pinned to different cpus.
#
# normally you can do this using the "taskset" command, however it is also
# possible to this via redis configuration directly, both in linux and freebsd.
#
# you can pin the server/io threads, bio threads, aof rewrite child process, and
# the bgsave child process. the syntax to specify the cpu list is the same as
# the taskset command:
#
# set redis server/io threads to cpu affinity 0,2,4,6:
# server_cpulist 0-7:2
#
# set bio threads to cpu affinity 1,3:
# bio_cpulist 1,3
#
# set aof rewrite child process to cpu affinity 8,9,10,11:
# aof_rewrite_cpulist 8-11
#
# set bgsave child process to cpu affinity 1,10,11
# bgsave_cpulist 1,10-11
# in some cases redis will emit warnings and even refuse to start if it detects
# that the system is in bad state, it is possible to suppress these warnings
# by setting the following config which takes a space delimited list of warnings
# to suppress
#
# ignore-warnings arm64-cow-bug
4、查看目录结构
tree /data/redis/
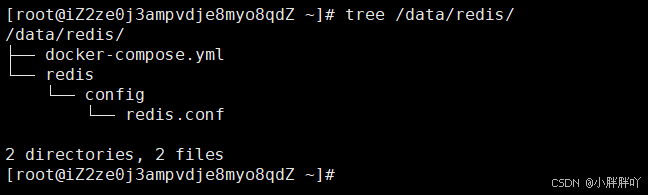
5、启动服务
docker compose up -d

6、查看服务状态

7、登录验证
docker compose exec redis /bin/bash

8、连接测试
redis-cli -a 123456

9、查看redis信息并验证
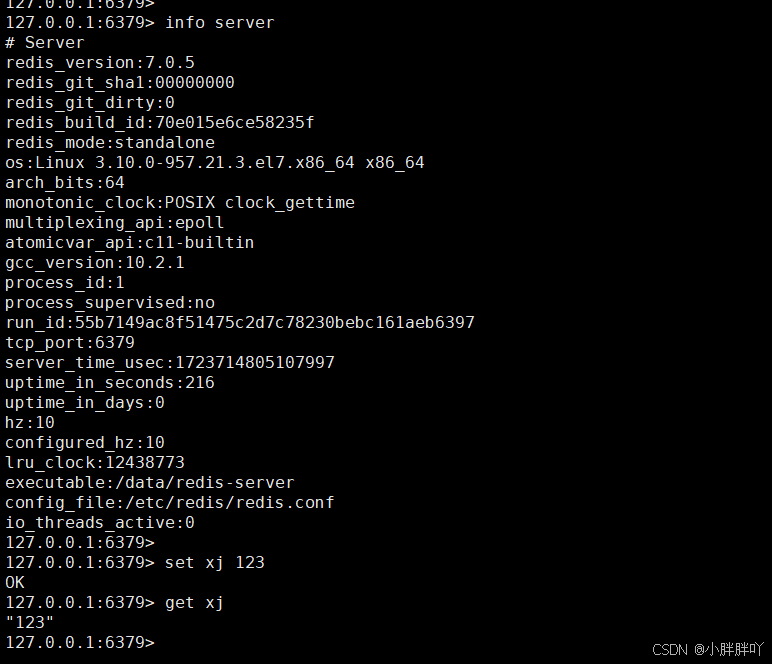
总结
到此这篇关于如何使用docker compose一键部署redis服务的文章就介绍到这了,更多相关docker compose一键部署redis服务内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!


发表评论