非贪婪匹配 (.*?)通常情况,满足匹配规则“456(.*?)789”的内容通常不止一个,那么findall()函数会从字符串的起始位置开始寻找文本a,找到后开始寻找文本b,当找到第一
非贪婪匹配 (.*?)
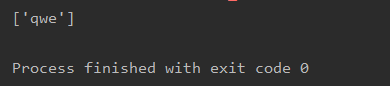
通常情况,满足匹配规则“456(.*?)789”的内容通常不止一个,那么findall()函数会从字符串的起始位置开始寻找文本a,找到后开始寻找文本b,当找到第一个文本b后,暂时停止寻找,将文本a和文本b之间的内容存入列表;然后继续寻找文本a,并重复之前的步骤,直到到达字符串的结束位置,并将所有匹配到的内容存入列表。
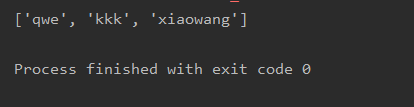
贪婪模式的话就会寻找最长的

非贪婪匹配 .*?

" 和 url后面的html代码用.*?代表,需要提取的是<a href="后的内容,用“(.*?)”代表
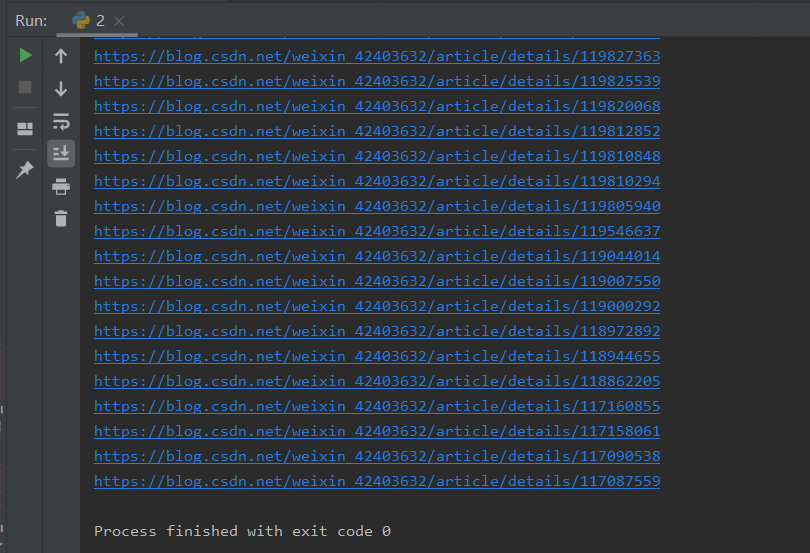
实战爬取博客专栏url
到此这篇关于轻松入门正则表达式之非贪婪匹配篇详解的文章就介绍到这了,更多相关正则表达式 非贪婪匹配内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!
相关文章:
-
-

最新最全的手机号验证正则表达式
前言一般表单页面都需要填写手机号,校验用户输入的手机号码是否正确,就要用到正则表达式,用正则表达式来匹配手机号段,如在运营商号段内,则号码正确。因此,需要知道运...
[阅读全文]
-

正则表达式拆分url实例代码
背景做web开发的同学,经常会有从url中获取二级域名或者主域名或者参数等等需求,需要扎实的正则功底。本文提供一个全面的url拆分案例,需要哪个部分用哪个部分。...
[阅读全文]
-
-
-
版权声明:本文内容由互联网用户贡献,该文观点仅代表作者本人。本站仅提供信息存储服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 2386932994@qq.com 举报,一经查实将立刻删除。


发表评论