redis中跳表的实现原理
跳表: 主要通过多重链表实现,最底层包含所有元素,上层都是底层元素的跳跃索引,每一层的元素是从下一层中随机选择的,通常使用概率算法来决定一个元素是否出现在上一层。
每个节点包含一个值和指向下一层节点的指针
- 插入时,首先从最高层开始查找插入位置,然后随机决定新节点的层数,最后在相应的层中插入节点并更新指针。
- 删除时,同样从最高层开始查找要删除的节点,并在各层中更新指针,以保持跳表的结构。
- 查找时,从最高层开始,逐层向下,直到找到目标元素或确定元素不存在。查找效率高,时间复杂度为 o(logn)
原理
跳表,一句话概括:就是一个多层索引的链表,每一层索引的元素在最底层的链表中可以找到( 这一点和 b+树是一样的 )
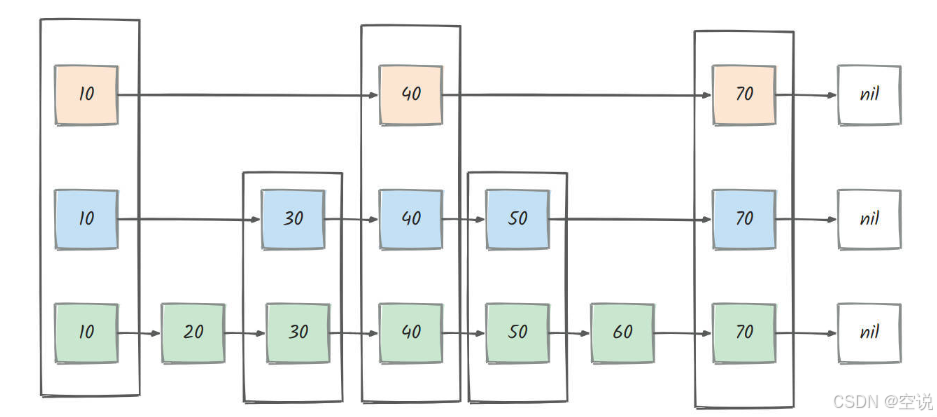
如下图所示:
这就是一个简单的跳表实现了,每个颜色代表一层,绿色的就是链表的最底层了
接下来我们通过查询和添加元素来了解其功能流程:
1) 查询元素: 这里我们与传统的链表进行对比,来了解跳表查询的高效。
- 假设我们要查找 50 这个元素,如果通过传统链表的话( 看最底层绿色的查询路线 ),需要查找 4次,查找的时间复杂度为0(n)
- 但如果使用跳表的话,其只需要从最上面的 10 开始,首先跳到 40 ,发现目标元素比 40 大,然后对比后一个元素比 70 小。于是就前往下一层进行查找,然后 40 的下一个 50 刚好符合目标,就直接返回就可以了,类似 b+树二分查找
- 这个过程的跳转次数是3次,即10->40(顶层)->40(第二层)->50(第二层),跳表的平均时间查询复杂度是 0(logn),最差的时间复杂度是o(n)
2) 插入元素: 我们插入一条 score 为 48 的数据
- 先需要定位到第一个比 score 大的数据。如图所示,一下子就可以定位到 50 了,这里和查询的过程( 上文所示 )是一样的。
- 在定位到对应节点之后,将在节点所有应该存在的层级上进行插入操作,这里就是40-50之间的所有层
补充插入的随机层级
- 一个节点有多少层,redis 是采用随机的概率函数来决定的。
- 在代码中,跳表每一个节点能否新加一层( 即前面如何从下往上构建出跳表 )的概率是 25 %
- 然后最多的层数在 redis 5.0 中是 64 层,redis 7.0 中是 32层。
具体解释
跳表在创建节点时候,会生成范围为[0-1]的一个随机数,如果这个随机数小于 0.25,那么层数就增加 1 层,然后继续生成下一个随机数,这样的做法,相当于每增加一层的概率不超过 25%,层数越高,概率越低,层高最大限制是 64。(创建跳表时头结点就等于层高)
//5层跳表
10
10 50
10 20 50
10 20 30 50
10 20 30 50
//比如插入20这个结点时会生成随机数
如果>0.25,那么这一层的高度+1,然后继续生成随机数
如果还是>0.25,高度继续+1,依次类推
如果<0.25,终止,记录 该结点的最终高度定位层级后,再将每一层的链表节点进行补齐,就是在 40 与 50 之间插入一个新的链表节点48,插入过程与链表插入是一样的。
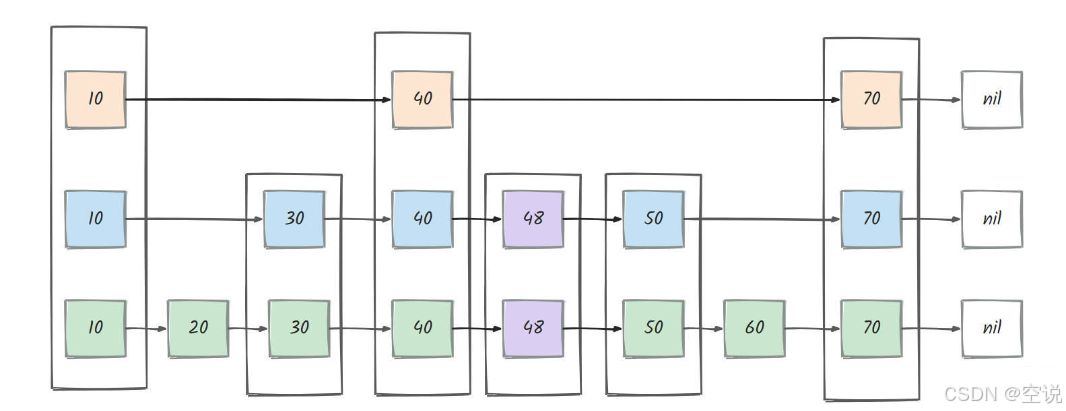
redis的跳表
就是在此基础上添加回退指针,且score能重复
为什么 redis 跳表实现多了个回退指针(前驱指针)?
回退指针主要是为了提高跳表的操作效率和灵活性,例如在进行删除操作时,需要找到要删除节点的前驱节点以便更新指针。回退指针使得这一过程更为高效,避免了从最高层开始逐层查找。
尤其是在频繁插入和删除的场景中,回退指针减少了节点之间指针的更新复杂度,提升性能。
typedef struct zskiplistnode {
//zset 对象的元素值
sds ele;
//元素权重值
double score;
//后退指针
struct zskiplistnode *backward;
//节点的level数组,保存每层上的前向指针和跨度
struct zskiplistlevel {
struct zskiplistnode *forward;
unsigned long span;
} level[];
} zskiplistnode;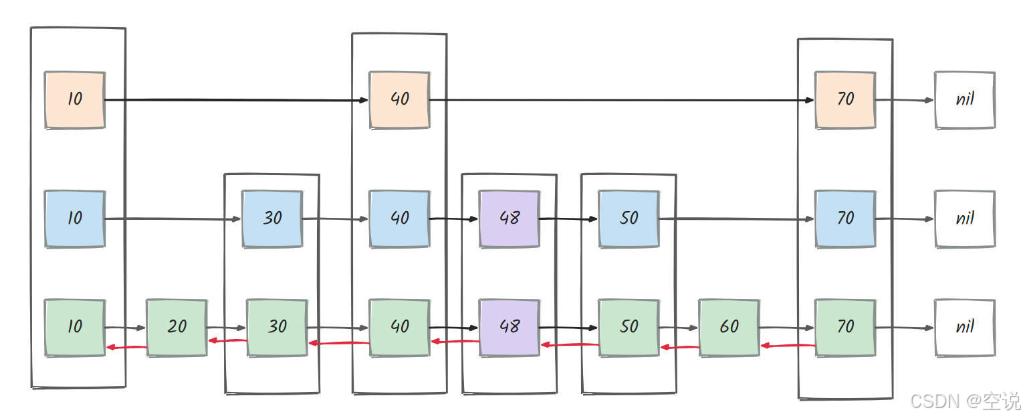
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。



发表评论