零. 待投入数据的表结构
create table db_user."person_table" ( id number not null , name varchar2(50) , age number , email varchar2(100) , created_date date )
一. insert into ... select投入数据
insert into ... select的这种方式相当于把数据加载到内存中之后再插入数据库,只适合投入小规模的数据。
1.1 普通的方式投入数据
当数据量不是很多的时候,可以使用这种方式
- 先从dual虚拟表中检索后造出指定条数的数据后,再插入到指定的表中。
- 除了主键之类的关键字段之外,其余字段写固定值即可。
insert into person_table
select
-- 因为该字段为字符串形式,所以使用to_char转换
-- to_char(100000000 + level) || 'test_id' as id,
level as id,
'name_' || rownum as name,
trunc(dbms_random.value(18, 60)) as age,
'user' || rownum || '@example.com' as email,
sysdate - dbms_random.value(0, 365) as created_date
from
dual
connect by level <= 1000000;
1.2 并行插入(parallel insert)投入数据
alter session enable parallel dml;
insert /*+ parallel(person_table, 4) */ into person_table
select level as id,
'name_' || rownum as name,
trunc(dbms_random.value(18, 60)) as age,
'user' || rownum || '@example.com' as email,
sysdate - dbms_random.value(0, 365) as created_date
from dual
connect by level <= 1000000;
二. pl/sql 循环投入数据
2.1 脚本介绍
- 灵活,支持动态生成数据,适合
中小数据量。 - 数据量大时性能较差,容易导致
上下文切换开销。
begin
for i in 1..5000000 loop
insert into person_table (id, name, age, email, created_date)
values (
i,
'name_' || i,
-- 随机年龄
trunc(dbms_random.value(18, 60)),
'user' || i || '@example.com',
-- 随机日期
sysdate - dbms_random.value(0, 365)
);
-- 每 100000 条提交一次
if mod(i, 100000) = 0 then
commit;
end if;
end loop;
commit;
end;
/
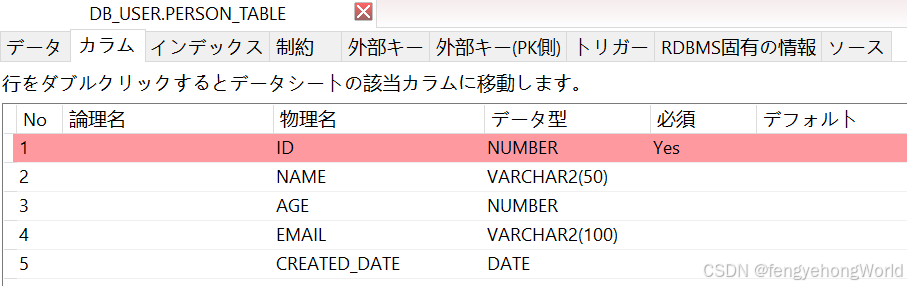
2.2 效果
投入500万条数据,耗时5分钟。
三. pl/sql forall 批量操作
3.1 脚本介绍
- 这种方式可以
减少上下文切换,性能比普通的循环插入要好。
declare
type person_array is table of person_table%rowtype;
v_data person_array := person_array();
begin
for i in 1..5000000 loop
v_data.extend;
v_data(v_data.count).id := i;
v_data(v_data.count).name := 'name_' || i;
v_data(v_data.count).age := trunc(dbms_random.value(18, 60));
v_data(v_data.count).email := 'user' || i || '@example.com';
v_data(v_data.count).created_date := sysdate - dbms_random.value(0, 365);
-- 每 100000 条批量插入一次
if mod(i, 100000) = 0 then
forall j in 1..v_data.count
insert into person_table values v_data(j);
commit;
v_data.delete; -- 清空数组
end if;
end loop;
-- 插入剩余数据
forall j in 1..v_data.count
insert into person_table values v_data(j);
commit;
end;
/
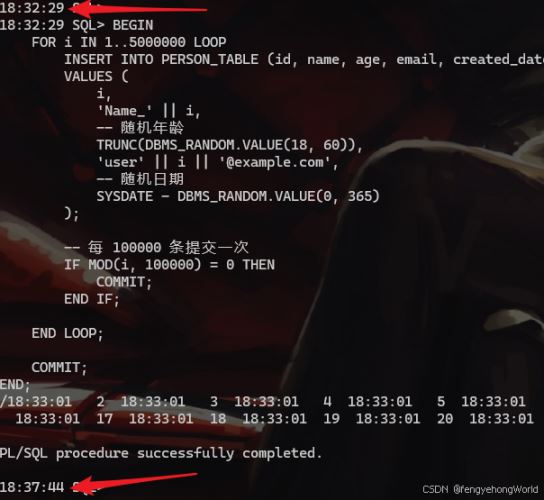
3.2 效果
投入500万条数据,耗时1分钟18秒。
四. sql*loader 工具加载外部文件
写一个powershell脚本,根据数据库的表结构来生成csv文件
- 该脚本执行后,会在桌面上生成一个csv文件。
# 文件名称
$file_name = 'person_data.csv'
# 路径
$outputfile = "$home\desktop\$file_name"
# csv 文件的总行数
$rows = 5000000
# 并行线程数
$threadcount = 4
# 每个线程生成的记录数量
$chunksize = [math]::ceiling($rows / $threadcount)
# 判断文件是否存在,存在的话就删除
if (test-path -path $outputfile) {
remove-item -path $outputfile -force
}
# 写入 csv 表头
# "`"id`",`"name`",`"age`",`"email`",`"created_date`"" | out-file -filepath $outputfile -encoding utf8 -append
# 定义脚本块
$scriptblock = {
param($startrow, $endrow, $tempfile)
# 在后台作业中定义 generate-chunk 函数
function generate-chunk {
param (
[int]$startrow,
[int]$endrow,
[string]$filepath
)
$random = [system.random]::new()
$currentdate = get-date
$sb = [system.text.stringbuilder]::new()
# 循环生成csv数据
for ($i = $startrow; $i -le $endrow; $i++) {
# =========================对应数据库的各字段值=========================
$id = $i
$name = "name_$i"
$age = $random.next(18, 60)
$email = "user$i@example.com"
$createddate = $currentdate.adddays(- $random.next(0, 365)).tostring("yyyy/mm/dd hh:mm:ss")
# =========================对应数据库的各字段值=========================
# =========================一行csv=========================
$line = "`"$id`",`"$name`",`"$age`",`"$email`",`"$createddate`""
# =========================一行csv=========================
$sb.appendline($line) | out-null
}
<#
将生成的内容写入文件
-nonewline 的作用是为了防止csv文件的最后一行被追加空行
#>
$sb.tostring() | out-file -filepath $filepath -encoding utf8 -append -nonewline
}
# 调用 generate-chunk 函数,多线程生成临时csv文件
generate-chunk -startrow $startrow -endrow $endrow -filepath $tempfile
}
# csv文件合成
function merge-csv {
param (
[string]$outputfile,
[bool]$isreadalldatatomemory
)
# 获取所有分段文件,按名称排序
$partfiles = get-childitem -path "$outputfile.*.part" | sort-object name
if ($isreadalldatatomemory) {
# 将所有内容加载到内存中,然后一次性写入
$partfiles | foreach-object { get-content $_.fullname } | out-file -filepath $outputfile -encoding utf8 -force
# 删除所有分段文件
$partfiles | foreach-object { remove-item $_.fullname }
return;
}
$partfiles | foreach-object {
get-content -path $_.fullname | out-file -filepath $outputfile -encoding utf8 -append
remove-item -path $_.fullname
}
}
try {
# 定义job数组
$jobs = @()
# 组装job
1..$threadcount | foreach-object {
$startrow = ($_ - 1) * $chunksize + 1
$endrow = [math]::min($_ * $chunksize, $rows)
# 临时csv文件
$tempfile = "$outputfile.$_.part"
$jobs += start-job -scriptblock $scriptblock -argumentlist $startrow, $endrow, $tempfile
}
# 统计生成csv文件所消耗的时间
$exec_time = measure-command {
write-host "临时csv文件开始生成..."
# 执行job,等待并收集所有执行结果
$jobs | foreach-object { wait-job -job $_; receive-job -job $_; remove-job -job $_ }
# 合并所有并发生成的csv临时文件,组装成最终的总csv文件
write-host "临时csv文件生成完毕,开启合并..."
merge-csv -outputfile $outputfile -isreadalldatatomemory $false
}
write-host "csv文件生成完毕,共消耗$($exec_time.totalseconds)秒: $outputfile" -foregroundcolor red
} catch {
# 当异常发生时,清空桌面上的临时csv文件
if (test-path -path "$outputfile.*.part") {
remove-item -path "$outputfile.*.part" -force
}
write-host "脚本运行时发生异常: $_" -foregroundcolor red
write-host "详细信息: $($_.exception.message)" -foregroundcolor yellow
write-host "堆栈跟踪: $($_.exception.stacktrace)" -foregroundcolor gray
}
read-host "按 enter 键退出..."
创建控制文件control_file.ctl
load data infile 'person_data.csv' into table person_table fields terminated by ',' optionally enclosed by '"' (id, name, age, email, created_date "to_date(:created_date, 'yyyy/mm/dd hh24:mi:ss')")
使用 sql*loader 执行加载
- 性能极高,适合大规模数据插入。
- 支持多线程和并行加载。
sqlldr db_user/oracle@service_xepdb1_client control=control_file.ctl direct=true
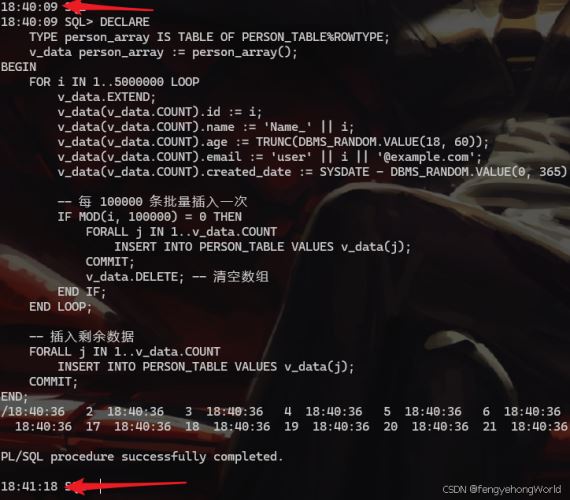
4.1 效果
投入500万条数据,耗时居然不到10秒!
到此这篇关于oracle批量投入数据方法总结的文章就介绍到这了,更多相关oracle投入数据内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论