1.解压hadoop
解压到任意盘,路径不要带中文路径
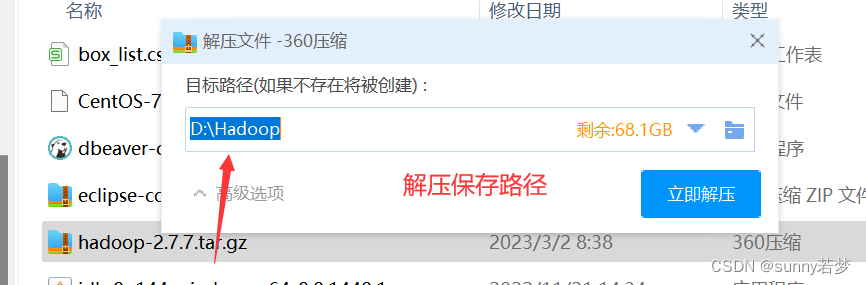
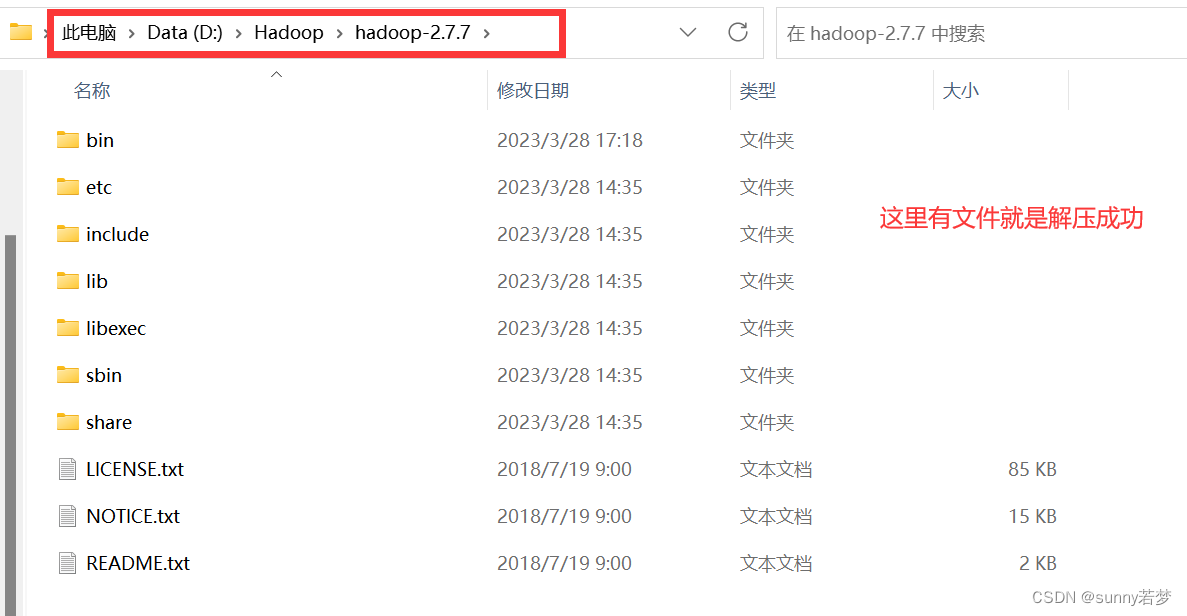
进入保存后的bin目录,查看,是否解压成功
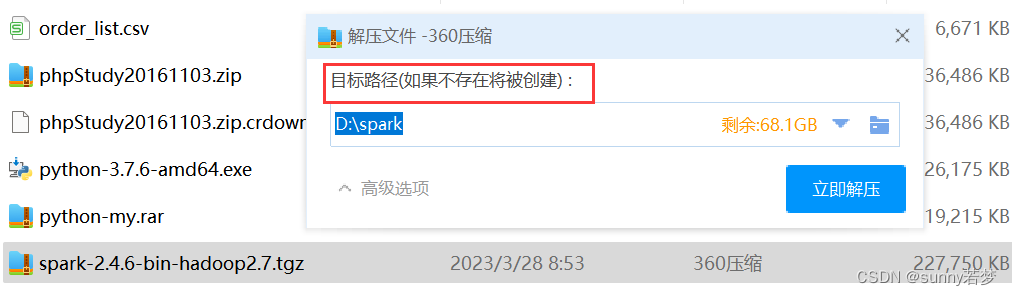
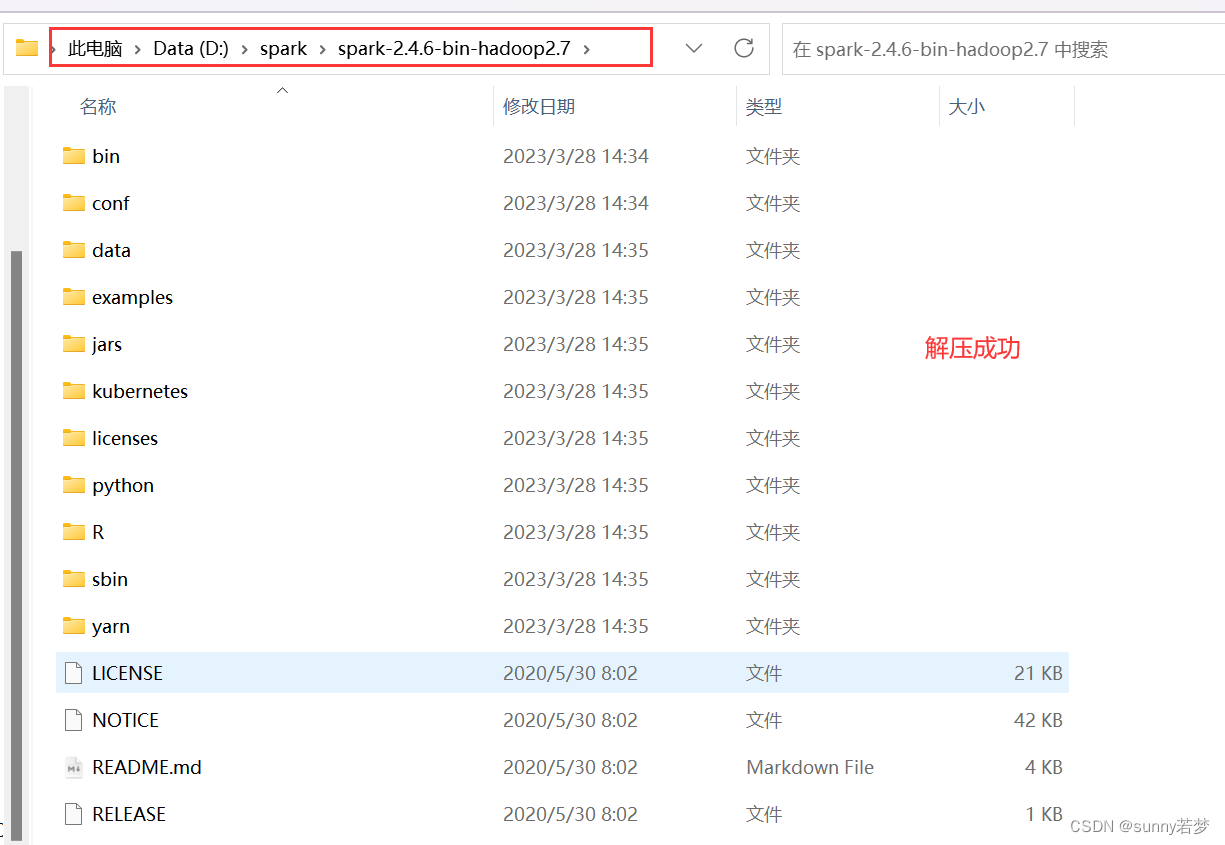
2.解压spark
到任意位置,路径不要带有中文
3. 打开pycharm
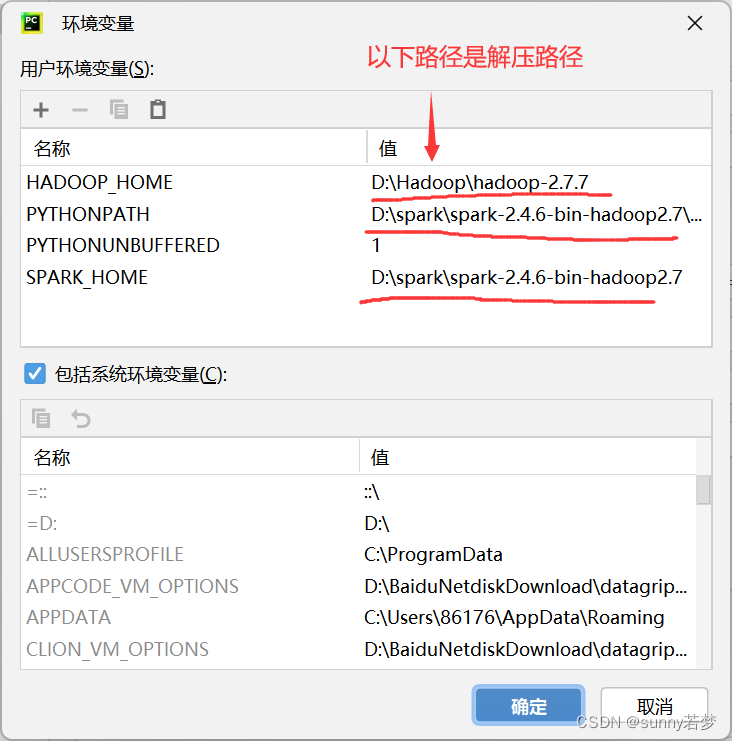
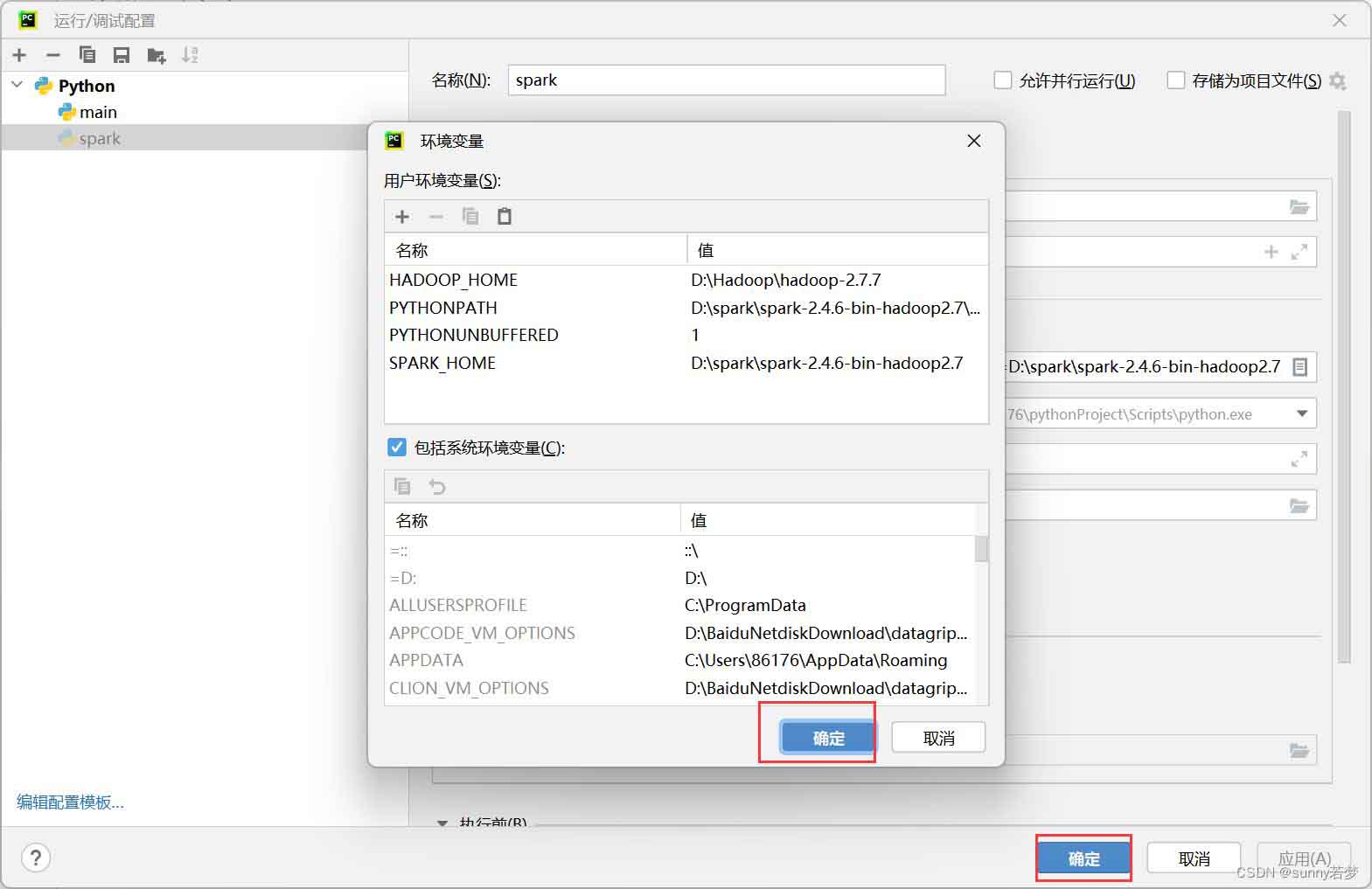
把hadoop,spark环境变量配置到pycharm中。
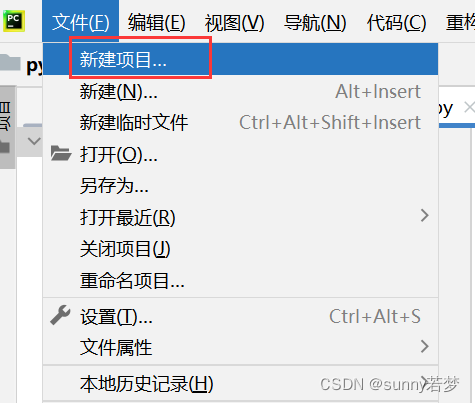
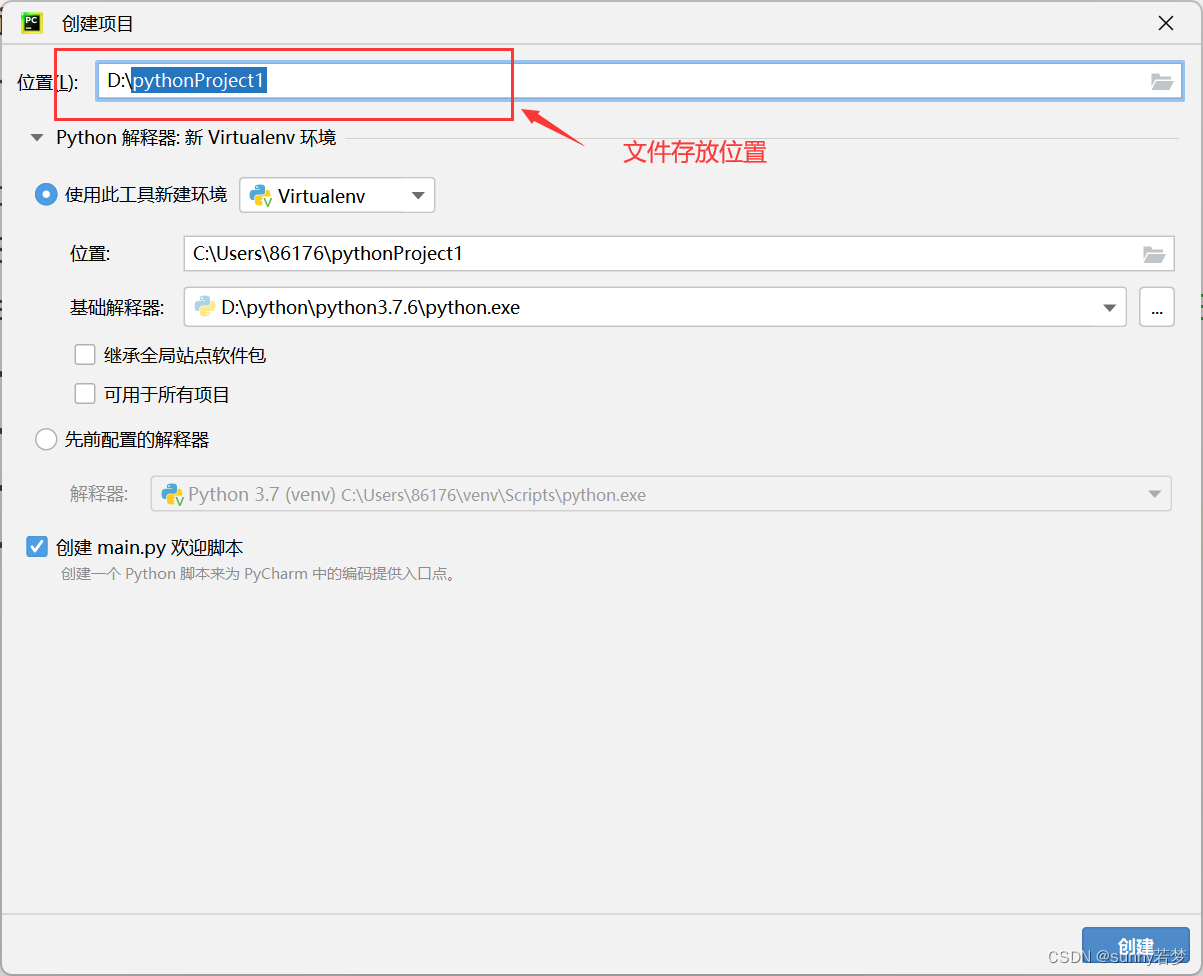
3.1新建项目
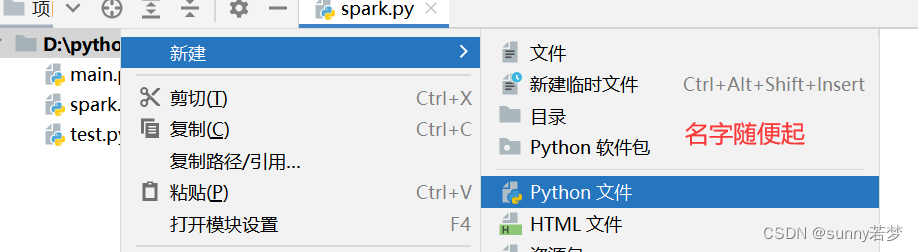
3.2在项目中创建一个python文件
3.3把hadoop_home
python_home,pythonpath添加到pycharm中.
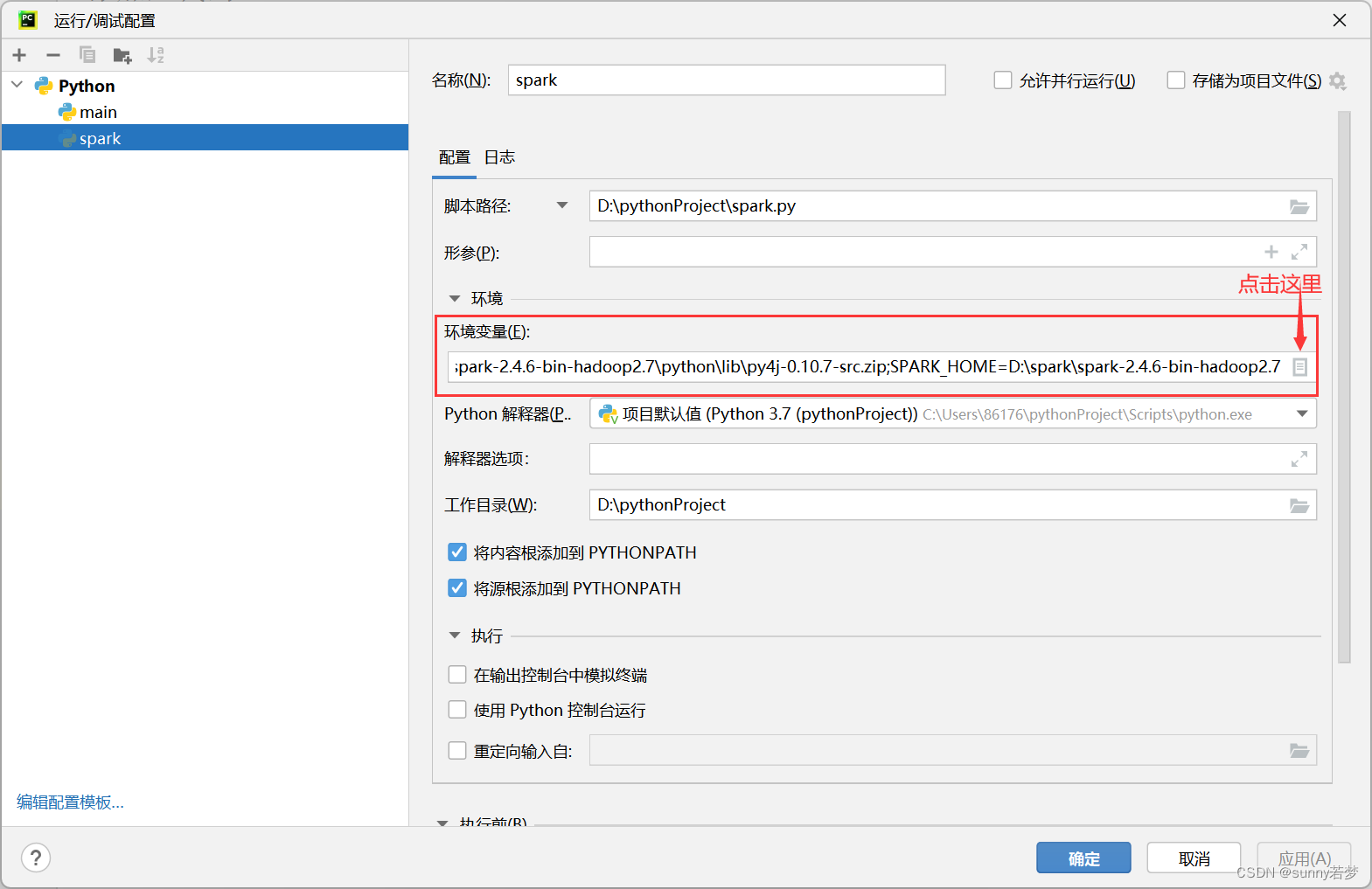

- 1.hadoop_home
- 2.spark_home
- 3.pythonpath
注意!!!
pythonpath路径要添加到d:\spark\spark-2.4.6-bin-hadoop2.7\python\lib\py4j-0.10.7-src.zip下
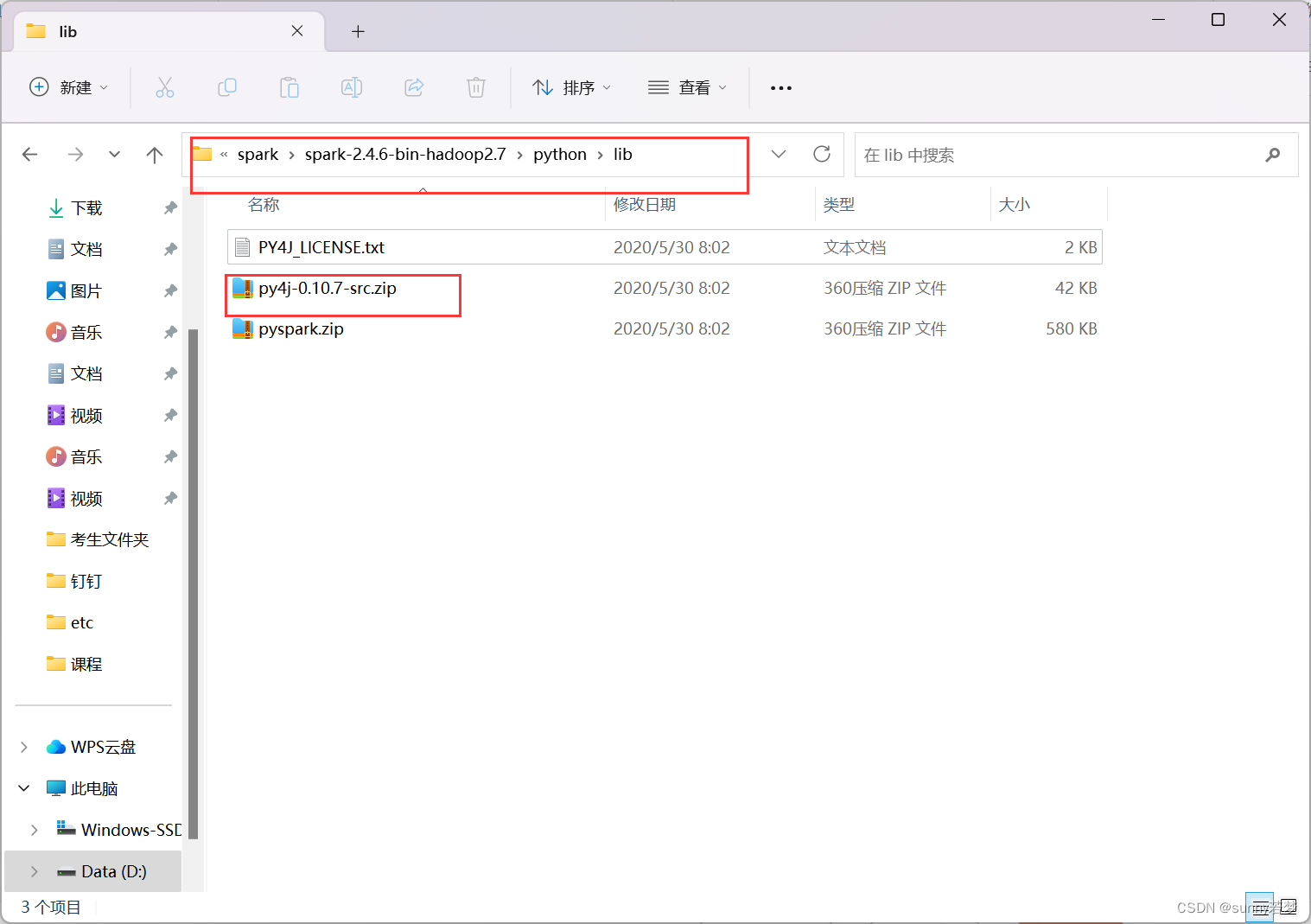
3.4 检查是否有以下软件包
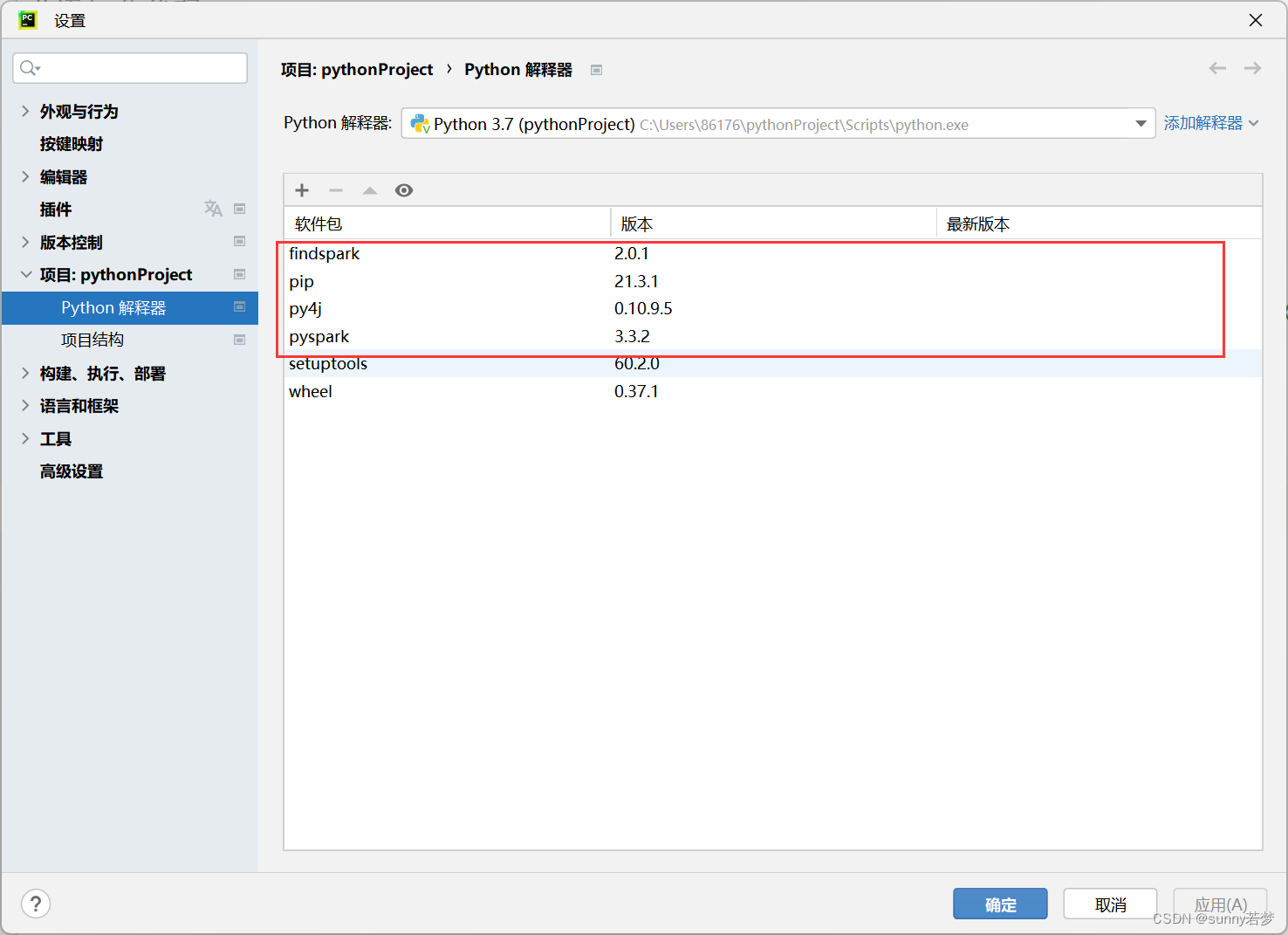
3.4.1 如果没有请按照以下教程下载,后期需要
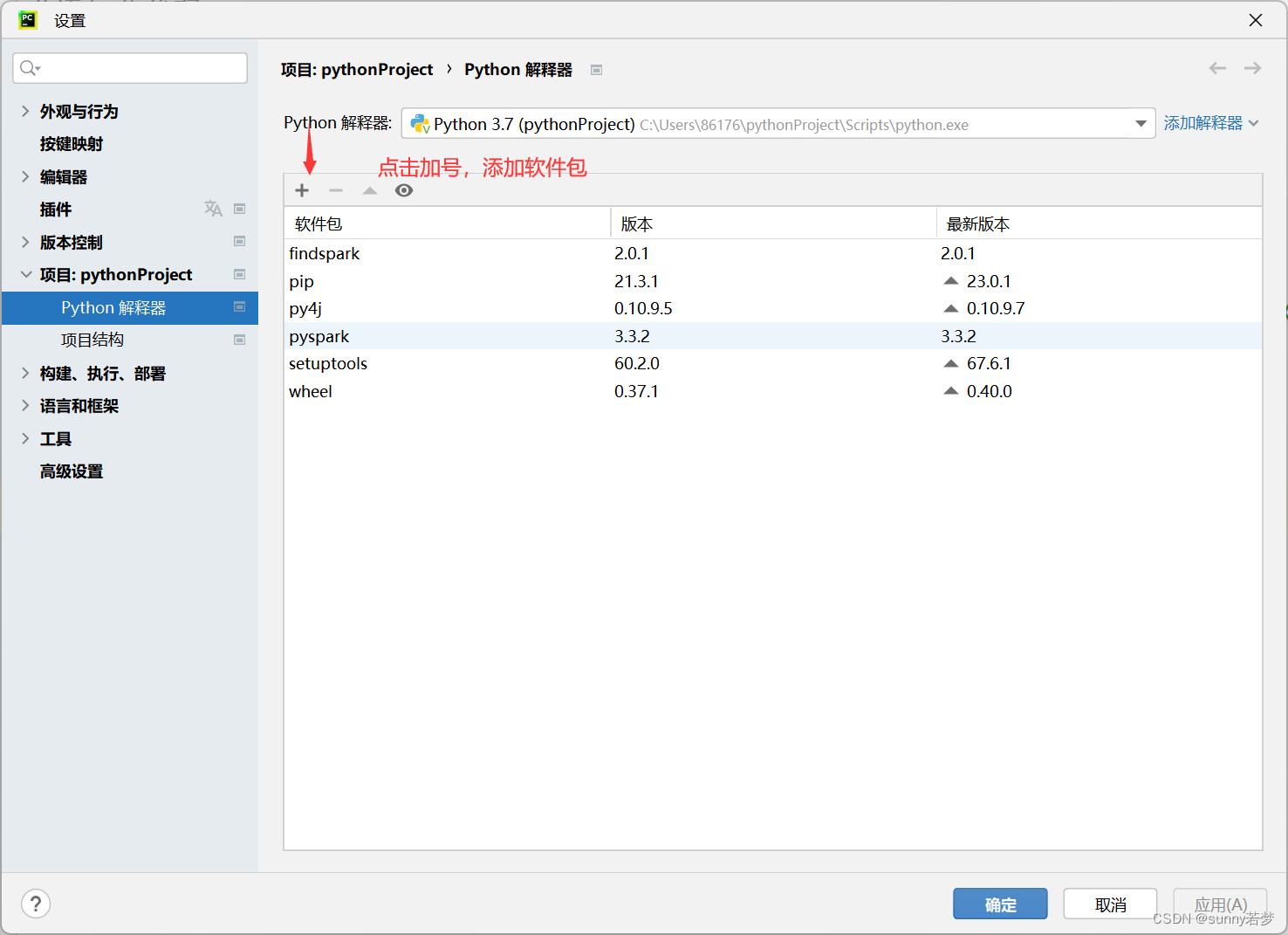
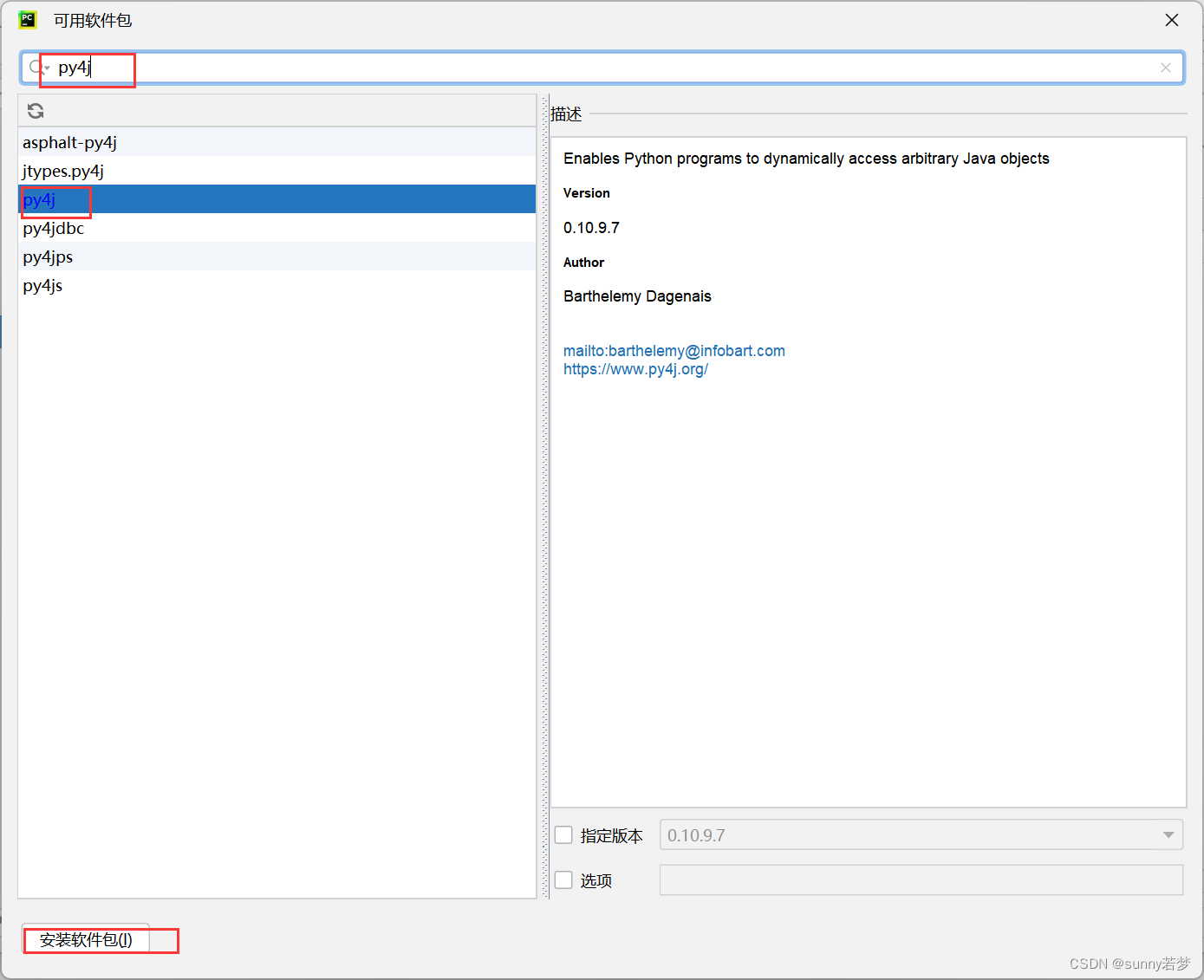
3.4.2安装py4j
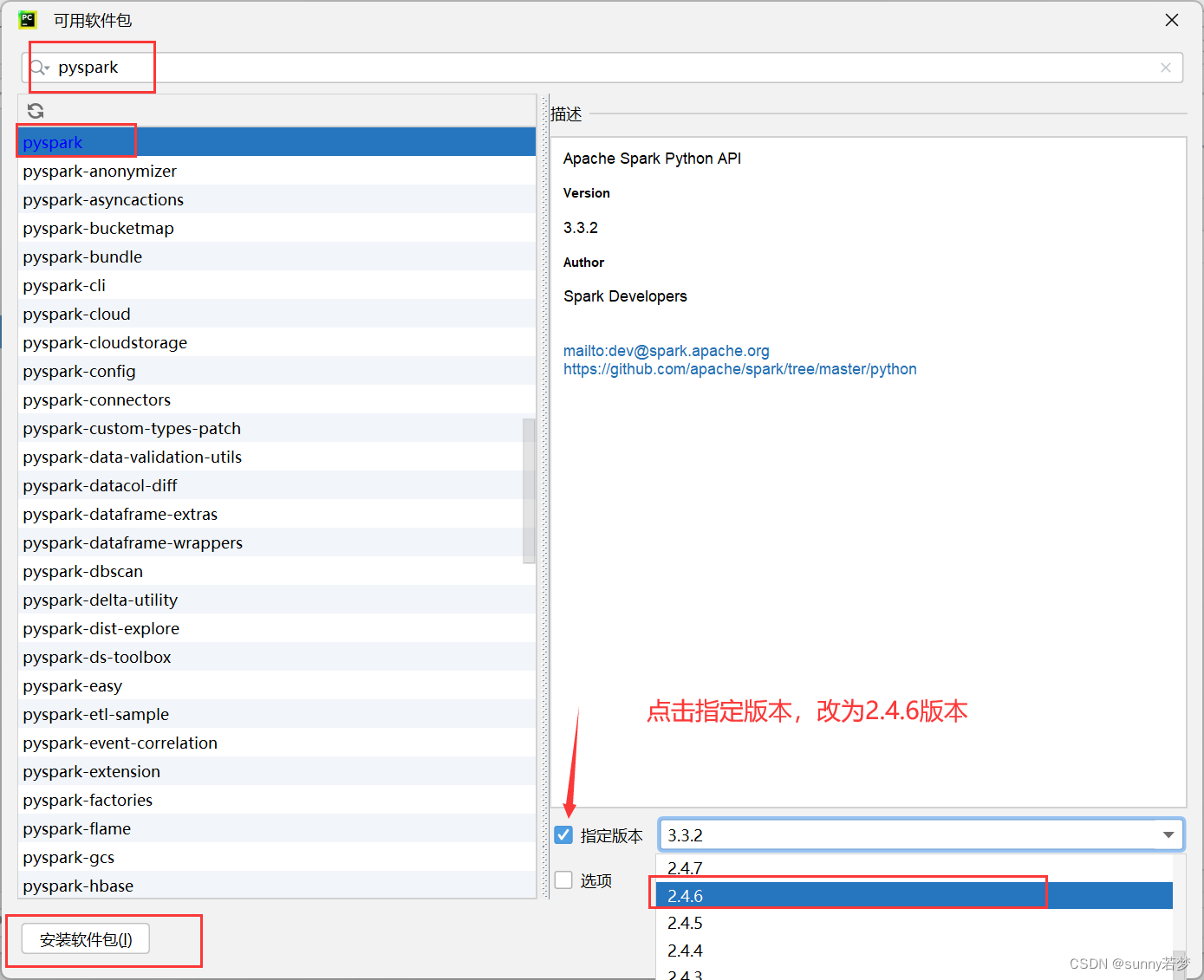
3.4.3安装pyspark推荐2.4.6版本
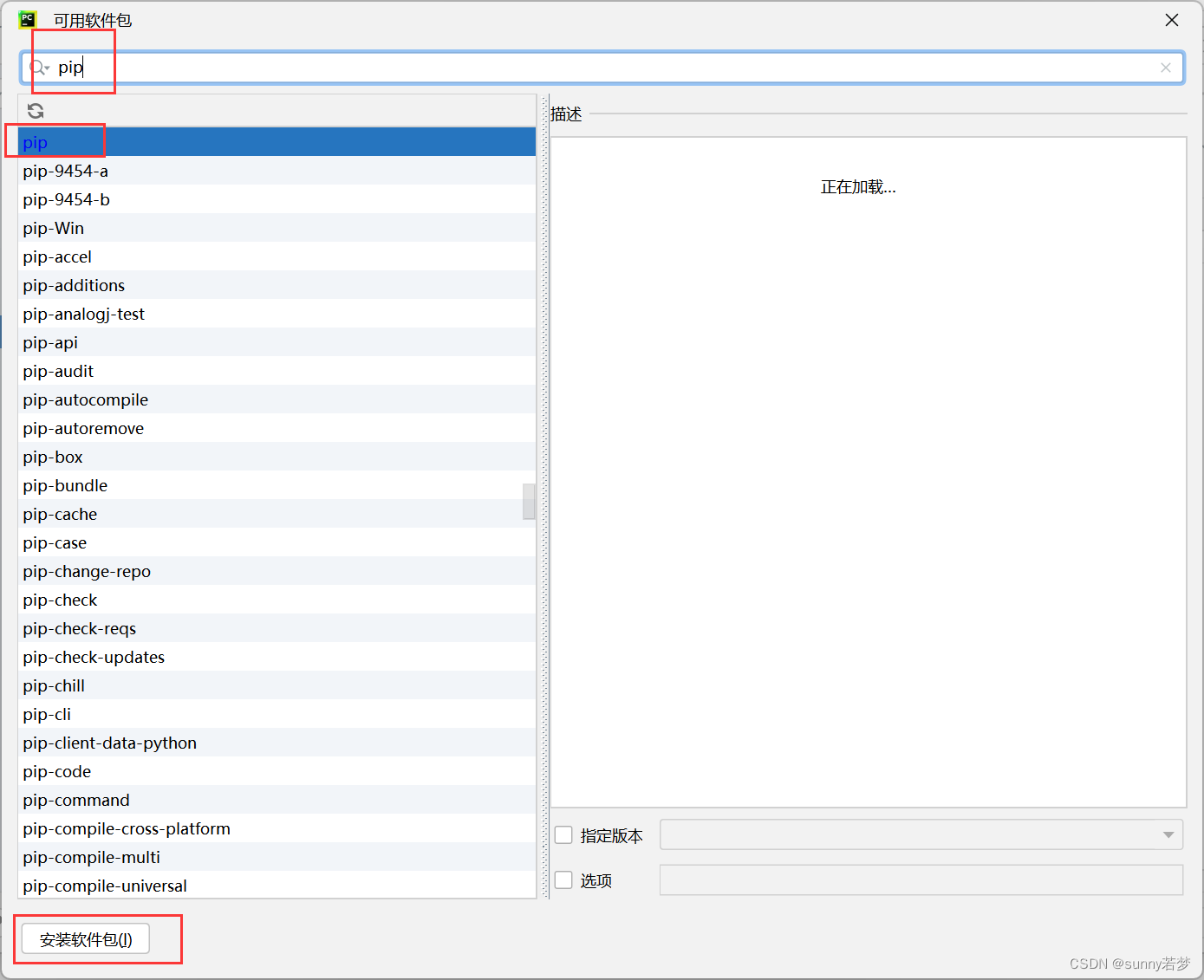
3.4.4安装pip
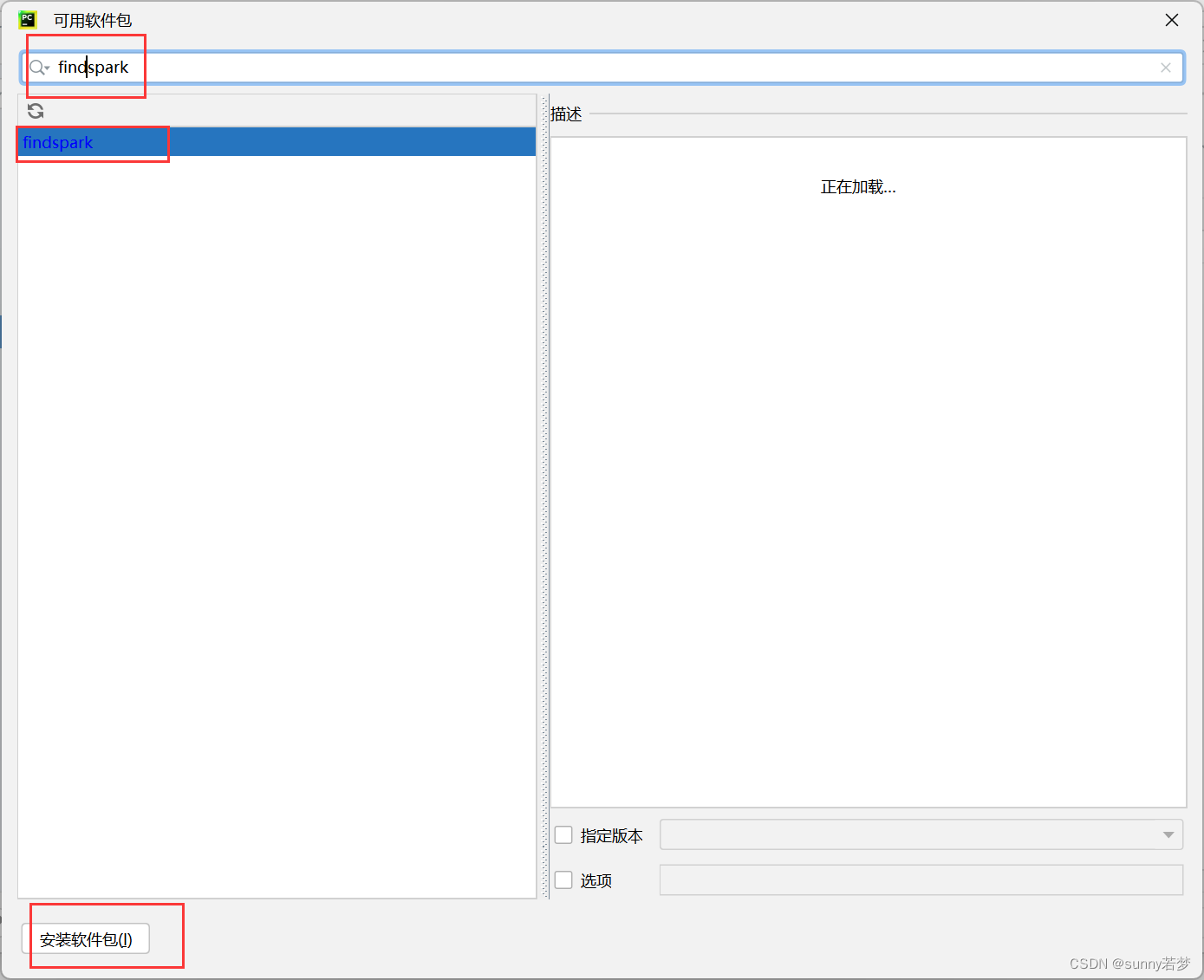
3.5安装findspark
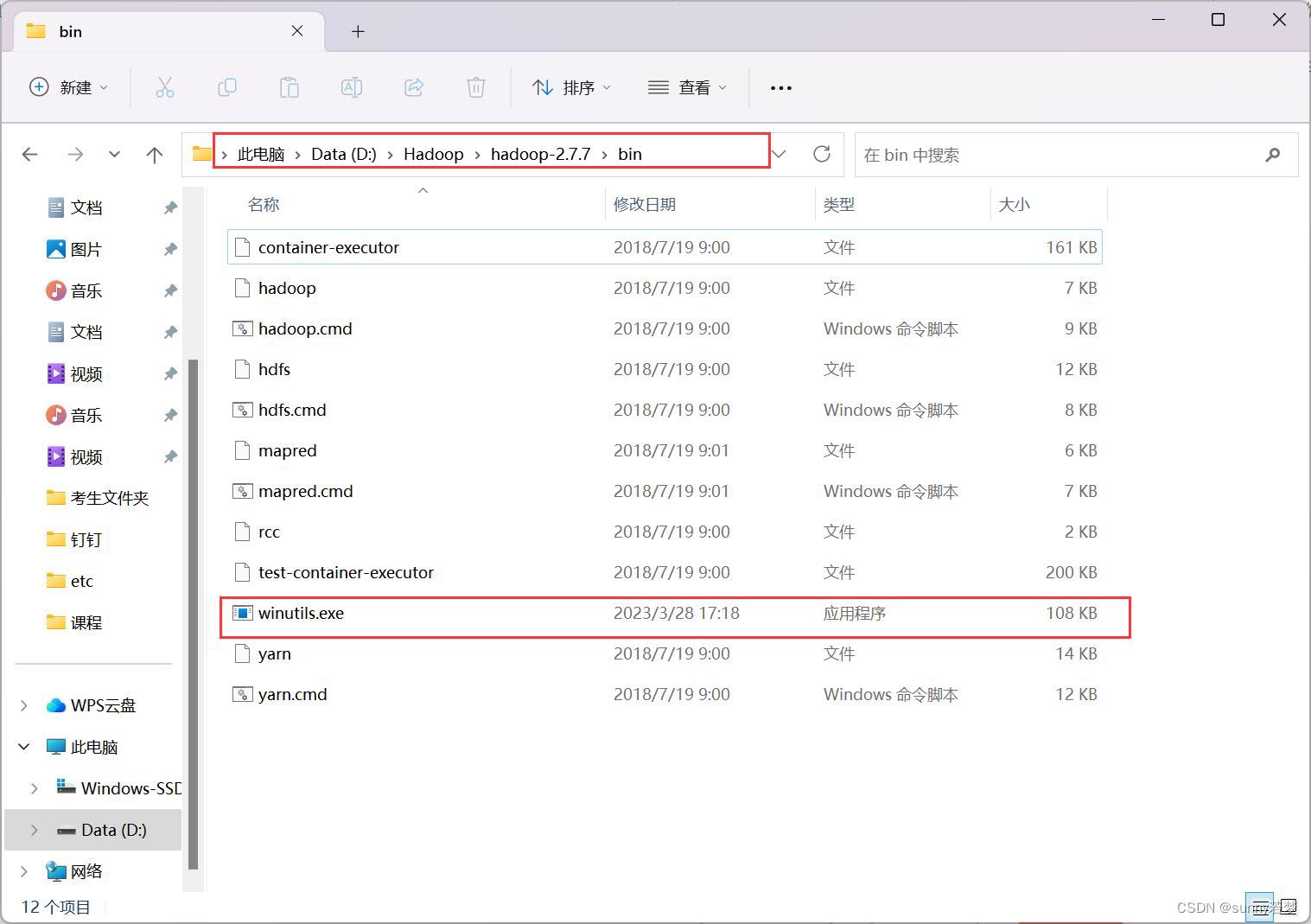
4.把winutils.exe插件
放到hadoop解压后的/bin目录下面
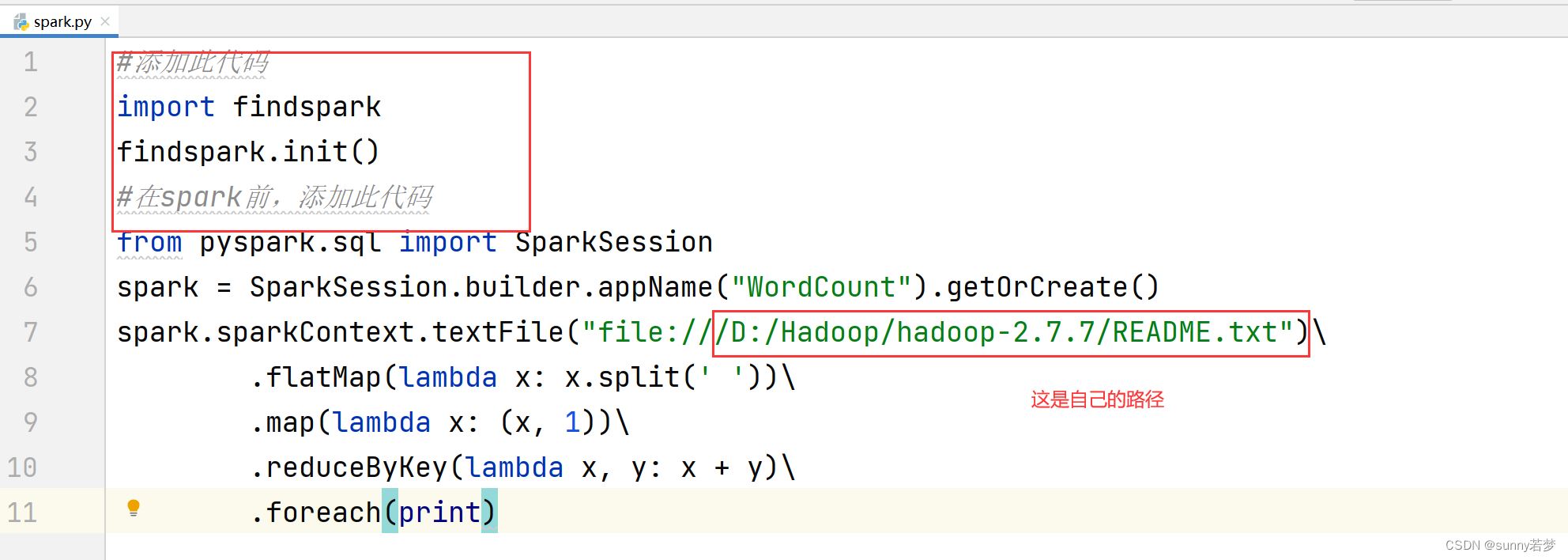
5.把以下代码
复制到4.2步骤中,新建的python文件中
#添加此代码
import findspark
findspark.init()
#在spark前,添加此代码
from pyspark.sql import sparksession
spark = sparksession.builder.appname("wordcount").getorcreate()
spark.sparkcontext.textfile("file:///d:/hadoop/hadoop-2.7.7/readme.txt")\
.flatmap(lambda x: x.split(' '))\
.map(lambda x: (x, 1))\
.reducebykey(lambda x, y: x + y)\
.foreach(print)
必须要有这句话在spark前面!!!
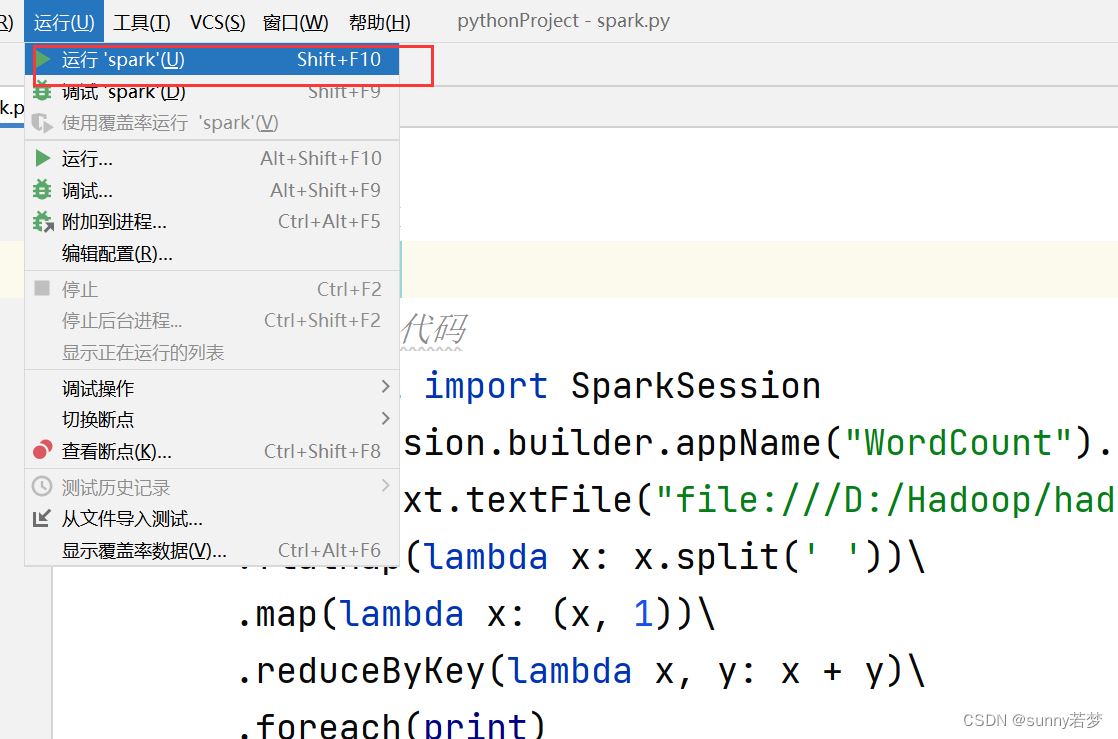
6.测试
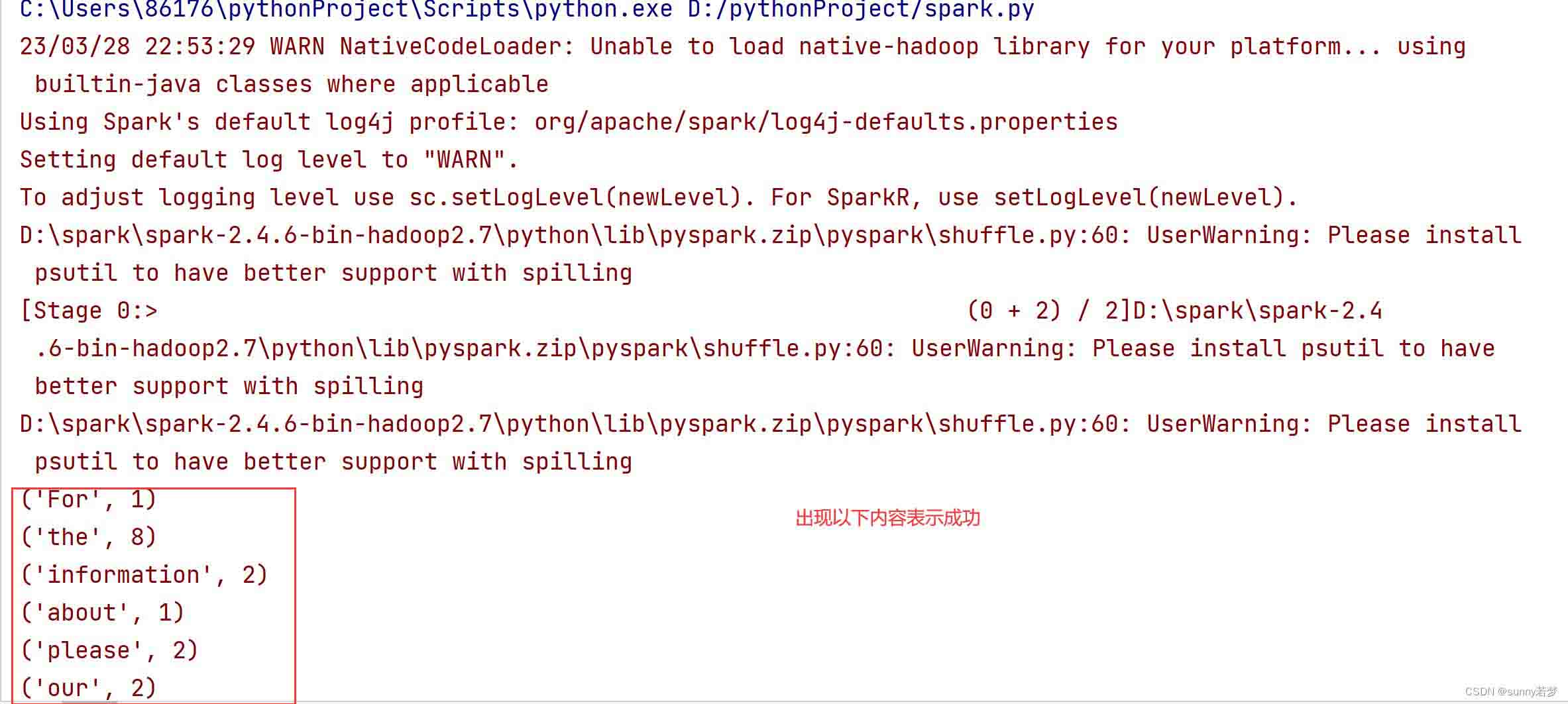
出现以上内容,表示pycharm连接spark成功。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。


发表评论