一、引言
在统计分析中,f ff分布是一种非常重要的连续概率分布,广泛应用于方差分析、回归分析的显著性检验等场景。为了方便查阅和使用f分布的临界值,我们可以使用python编写一个脚本来生成f分布表,并将其导出到excel文件中。本文将详细介绍如何完成这一任务。
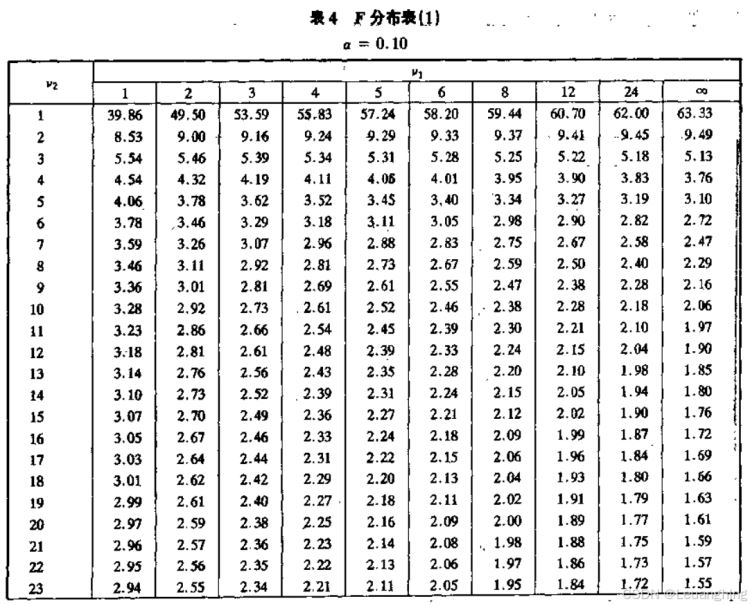
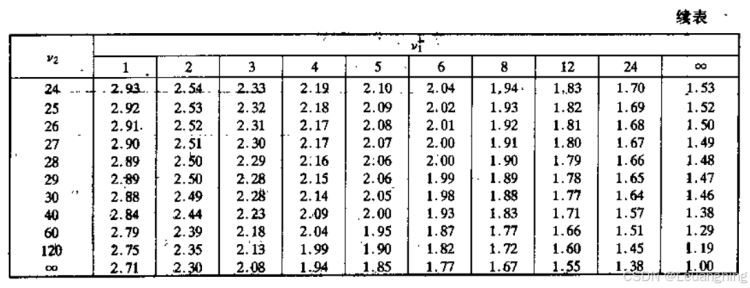
二、准备工作
首先,我们需要确保python环境已经安装了必要的库。本文所使用的库包括pandas用于数据处理和scipy.stats中的f函数用于计算f分布的临界值。此外,os库(虽然本文示例中未直接使用,但提供了保存文件到特定目录的方法)也是python标准库的一部分,无需额外安装。
你可以使用以下命令来安装pandas库(如果尚未安装):
pip install pandas
scipy库通常与numpy一起安装,但你也可以单独安装它:
pip install scipy
三、代码实现
以下是完整的python脚本,用于生成f ff分布表并导出到excel文件:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @time : 2023-11-13 18:00
# @author : leuanghing chen
# @blog : https://blog.csdn.net/weixin_46153372?spm=1010.2135.3001.5421
# @file : f分布表.py
# @software : pycharm
import pandas as pd
from scipy.stats import f
import os
# 置信度列表
confidence_levels = [0.1, 0.05, 0.01]
# 自由度范围
n_1_range = range(1, 31)
n_2_range = range(1, 31)
# 为每个置信度生成一个f分布表
for alpha in confidence_levels:
# 创建一个空的dataframe来存储结果
index = pd.multiindex.from_product([n_1_range, n_2_range], names=['n_1', 'n_2'])
f_table = pd.dataframe(index=index, columns=[f'f_critical'])
# 填充f分布表
for (n1, n2), row in f_table.iterrows():
f_critical = f.ppf(1 - alpha, n1, n2)
f_table.loc[(n1, n2), 'f_critical'] = f_critical
# 注意:原代码中文件生成部分缩进错误,已修正如下
file_name = f'f_distribution_table_alpha_{alpha:.2f}.xlsx'
f_table.to_excel(file_name)
print(f"f分布表(alpha={alpha:.2f})已成功生成并保存到{file_name}")
# (可选)确保输出目录存在并保存文件到该目录的注释代码(已修正缩进并添加说明)
# 如果需要将文件保存到特定目录,可以取消以下代码的注释,并修改'output_dir'为你的目标目录
# os.makedirs('output_dir', exist_ok=true)
# file_path = os.path.join('output_dir', file_name) # 注意:这里的file_name是在循环中定义的,因此不能在这里直接使用
# 由于file_path需要在循环内部使用,因此上述两行代码应放入循环内部,但在本例中我们直接保存到当前目录
四、运行结果
运行上述脚本后,你将在当前目录下看到三个excel文件,分别对应于置信度0.1、0.05和0.01的f ff分布表。文件名分别为f_distribution_table_alpha_0.10.xlsx、f_distribution_table_alpha_0.05.xlsx和f_distribution_table_alpha_0.01.xlsx。
以置信度0.1,即f_distribution_table_alpha_0.10.xlsx例,整理后如下图所示:
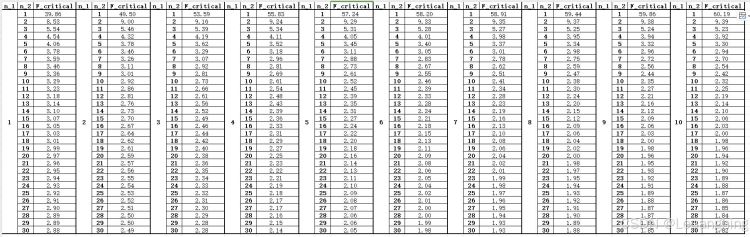
五、总结
通过本文的介绍,我们学会了如何使用python生成f分布表,并将其导出到excel文件中。这对于统计分析工作来说是一个非常实用的技能。
以上就是使用python生成f分布表并导出为excel文件的代码实现的详细内容,更多关于python生成f分布表并导出为excel的资料请关注代码网其它相关文章!





发表评论