一、场景分析
我们平常爬地图 poi 数据的时候,会得到大量的中文地址信息,比如【厦门大学附属中山医院】这个时候,就需要做中文分词,以便进一步分析。
二、中文分词库试用
1、jieba(结巴分词)
pip install jieba
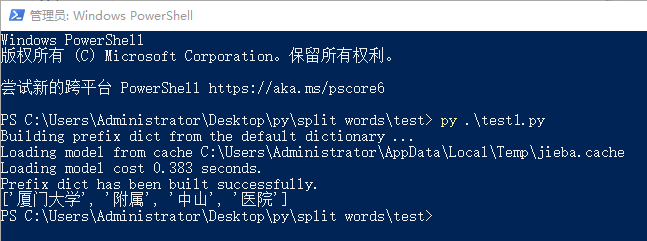
test1.py 代码如下:
import jieba text = "厦门大学附属中山医院" words = jieba.cut(text) print( list(words) )
运行
py test1.py
2、snownlp
pip install snownlp
test2.py 代码如下:
from snownlp import snownlp text = "厦门大学附属中山医院" s = snownlp(text) words = s.words print(words)
运行
py test2.py

3、thulac(清华大学自然语言处理与社会人文计算实验室开发的中文词法分析工具包)
pip install thulac
test3.py 代码如下:
import thulac thu = thulac.thulac() text = "厦门大学附属中山医院" result = thu.cut(text) print(result)
运行
py test3.py

三、总结
通过试用,发现三款分词库都能准确的把词条进行分词。
thulac 分词结果,因为加入了 词性标注,结果比较复杂。
jieba 的结果最简单,也最接近自然语言。
四、实战案例
从一个 txt 读入一批中文词条,进行分词,然后把分词结果写入 excel 文件中。
test.py 代码如下:
import jieba
from openpyxl import workbook
# 创建一个新的工作簿
wb = workbook()
# 选择默认的活动工作表
ws = wb.active
# 向工作表中写入表头
ws['a1'] = '分词'
# 读取文件
input_path = r"c:\users\administrator\desktop\py\split words\demo\address.txt"
with open(input_path, 'r', encoding='utf-8') as input_file:
for line in input_file:
word = line.strip()
print("---------"+word)
words = jieba.cut( word )
ll = list(words)
for item in ll:
print(item.strip())
temp_list = []
temp_list.append( item.strip() )
ws.append(temp_list)
input_file.close()
# 保存工作簿
wb.save('output.xlsx')address.txt 如下:
厦门大学思明校区
厦门大学附属中山医院
厦门南洋职业学院
集美大学
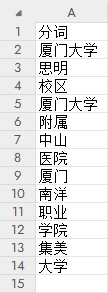
运行
py test.py

output.xlsx 如下:
到此这篇关于python中文分词工具使用详解的文章就介绍到这了,更多相关python中文分词内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论