1、kafka的安装
1、下载与安装kafka
kafka官网https://kafka.apache.org/downloads
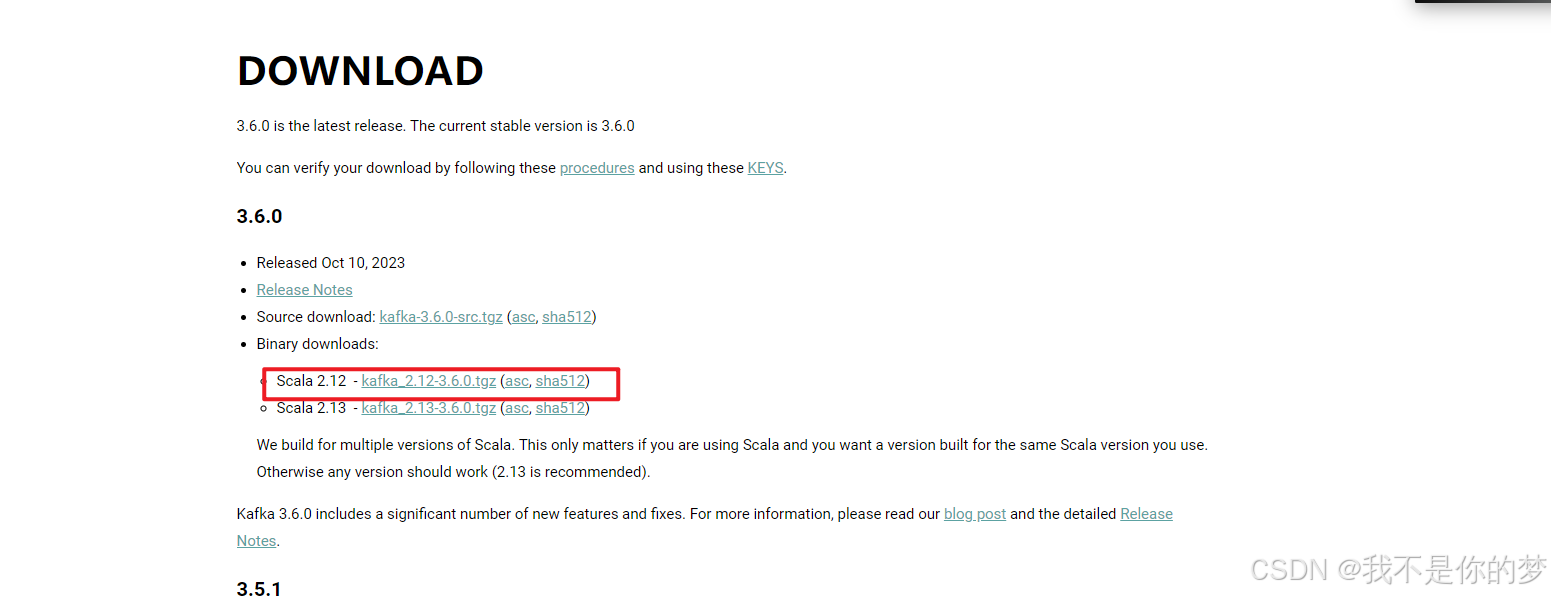
所以这里推荐的版本是 : https://archive.apache.org/dist/kafka/2.7.2/kafka_2.12-2.7.2.tgz
将下载下来的安装包直接解压到一个路径下即可完成kafka的安装,这里统一将kafka安装到/usr/local目录下
基本操作过程如下:
mkdir -p /www/kuangstudy cd /www/kuangstudy wget https://archive.apache.org/dist/kafka/2.7.2/kafka_2.12-2.7.2.tgz tar -zxvf kafka_2.12-2.7.2.tgz -c /usr/local/ mv /usr/local/kafka_2.12-2.7.2 /usr/local/kafka #新建存放日志和数据的文件夹 mkdir /usr/local/kafka/logs
这里我们将kafka安装到了/usr/local目录下。
2、配置kafka
这里将kafka安装到/usr/local目录下
因此,kafka的主配置文件为/usr/local/kafka/config/server.properties,这里以节点kafkazk1为例,重点介绍一些常用配置项的含义:
broker.id=1 listeners=plaintext://127.0.0.1:9092 num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 log.dirs=/usr/local/kafka/logs num.partitions=6 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 log.retention.hours=168 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 zookeeper.connect=localhost:2181 #不是集群,所以可以写成localhost #zookeeper.connect=127.0.0.1:2181,10.0.0.7:2181,10.0.0.8:2181 zookeeper.connection.timeout.ms=18000 group.initial.rebalance.delay.ms=0 auto.create.topics.enable=true delete.topic.enable=true
每个配置项含义如下:
broker.id:每一个broker在集群中的唯一表示,要求是正数。当该服务器的ip地址发生改变时,broker.id没有变化,则不会影响consumers的消息情况。listeners:设置kafka的监听地址与端口,可以将监听地址设置为主机名或ip地址,这里将监听地址设置为ip地址。log.dirs:这个参数用于配置kafka保存数据的位置,kafka中所有的消息都会存在这个目录下。可以通过逗号来指定多个路径, kafka会根据最少被使用的原则选择目录分配新的parition。需要注意的是,kafka在分配parition的时候选择的规则不是按照磁盘的空间大小来定的,而是根据分配的 parition的个数多小而定。num.partitions:这个参数用于设置新创建的topic有多少个分区,可以根据消费者实际情况配置,配置过小会影响消费性能。这里配置6个。log.retention.hours:这个参数用于配置kafka中消息保存的时间,还支持log.retention.minutes和 log.retention.ms配置项。这三个参数都会控制删除过期数据的时间,推荐使用log.retention.ms。如果多个同时设置,那么会选择最小的那个。log.segment.bytes:配置partition中每个segment数据文件的大小,默认是1gb,超过这个大小会自动创建一个新的segment file。
zookeeper.connect
:这个参数用于指定zookeeper所在的地址,它存储了broker的元信息。 这个值可以通过逗号设置多个值,每个值的格式均为:hostname:port/path,每个部分的含义如下:
- hostname:表示zookeeper服务器的主机名或者ip地址,这里设置为ip地址。
- port: 表示是zookeeper服务器监听连接的端口号。
- /path:表示kafka在zookeeper上的根目录。如果不设置,会使用根目录。
auto.create.topics.enable:这个参数用于设置是否自动创建topic,如果请求一个topic时发现还没有创建, kafka会在broker上自动创建一个topic,如果需要严格的控制topic的创建,那么可以设置auto.create.topics.enable为false,禁止自动创建topic。
delete.topic.enable:在0.8.2版本之后,kafka提供了删除topic的功能,但是默认并不会直接将topic数据物理删除。如果要从物理上删除(即删除topic后,数据文件也会一同删除),就需要设置此配置项为true。
3、添加环境变量
$ vim /etc/profile export kafka_home=/usr/local/kafka export path=$path:$kafka_home/bin #生效 $ source /etc/profile
zookeeper服务的启动
cd /usr/local/kafka/bin # 占用启动 ./zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties & # 后台启动 nohup ./zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties &
4、kafka启动脚本
$ vim /usr/lib/systemd/system/kafka.service [unit] description=apache kafka server (broker) after=network.target zookeeper.service [service] type=simple user=root group=root execstart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties execstop=/usr/local/kafka/bin/kafka-server-stop.sh restart=on-failure [install] wantedby=multi-user.target
systemctl daemon-reload
5、启动kafka
在启动kafka集群前,需要确保zookeeper集群已经正常启动。接着,依次在kafka各个节点上执行如下命令即可:
$ cd /usr/local/kafka $ nohup bin/kafka-server-start.sh config/server.properties & # 或者 $ systemctl start kafka $ jps 21840 kafka 15593 jps 15789 quorumpeermain
这里将kafka放到后台运行,启动后,会在启动kafka的当前目录下生成一个nohup.out文件,可通过此文件查看kafka的启动和运行状态。通过jps指令,可以看到有个kafka标识,这是kafka进程成功启动的标志。
6、测试kafka基本命令操作
kefka提供了多个命令用于查看、创建、修改、删除topic信息,也可以通过命令测试如何生产消息、消费消息等,这些命令位于kafka安装目录的bin目录下,这里是/usr/local/kafka/bin。
登录任意一台kafka集群节点,切换到此目录下,即可进行命令操作。
下面列举kafka的一些常用命令的使用方法。
(1)显示topic列表
#kafka-topics.sh --zookeeper 127.0.0.1:2181,10.0.0.7:2181,10.0.0.8:2181 --list $ kafka-topics.sh --zookeeper 127.0.0.1:2181 --list topic123
(2)创建一个topic,并指定topic属性(副本数、分区数等)
#kafka-topics.sh --create --zookeeper 127.0.0.1:2181,10.0.0.7:2181,10.0.0.8:2181 --replication-factor 1 --partitions 3 --topic topic123 $ kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 3 --topic topic123 created topic topic123. #--replication-factor表示指定副本的个数
(3)查看某个topic的状态
#kafka-topics.sh --describe --zookeeper 127.0.0.1:2181,10.0.0.7:2181,10.0.0.8:2181 --topic topic123 $ kafka-topics.sh --describe --zookeeper 127.0.0.1:2181 --topic topic123 topic: topic123 partitioncount: 3 replicationfactor: 1 configs: topic: topic123 partition: 0 leader: 1 replicas: 1 isr: 1 topic: topic123 partition: 1 leader: 1 replicas: 1 isr: 1 topic: topic123 partition: 2 leader: 1 replicas: 1 isr: 1
(4)生产消息 阻塞状态
#kafka-console-producer.sh --broker-list 127.0.0.1:9092,10.0.0.7:9092,10.0.0.8:9092 --topic topic123 $ kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic topic123
(5)消费消息 阻塞状态
#kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092,10.0.0.7:9092,10.0.0.8:9092 --topic topic123 $ kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic topic123 #从头开始消费消息 #kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic topic123 --from-beginning $ kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092,10.0.0.7:9092,10.0.0.8:9092 --topic topic123 --from-beginning
(6)删除topic
#kafka-topics.sh --delete --zookeeper 127.0.0.1:2181,10.0.0.7:2181,10.0.0.8:2181 --topic topic123 $ kafka-topics.sh --delete --zookeeper 127.0.0.1:2181 --topic topic_
2、go整合kafka实现消息发送和订阅
2.1 消息生产代码示例
package main
import (
"fmt"
"github.com/ibm/sarama"
)
func main() {
// 配置生产者信息
conf := sarama.newconfig()
conf.producer.requiredacks = sarama.waitforall // 生产者等待所有分区副本成功提交消息
conf.producer.return.successes = true // 成功消息写入返回
client, err := sarama.newsyncproducer([]string{"47.115.230.36:9092"}, conf)
if nil != err {
fmt.println("create kafka sync producer failed", err)
return
}
defer client.close()
msg := &sarama.producermessage{
topic: "topic123", // 指定消息主题
value: sarama.stringencoder("hello world"), // 构造消息
}
// 发送消息
_, _, err = client.sendmessage(msg)
if nil != err {
fmt.println("send message to kafka failed", err)
return
}
fmt.println("send message success")
}2.2 消息消费代码示例
package main
import (
"fmt"
"github.com/ibm/sarama"
)
/**
* @desc 生产者
* @author feige
* @date 2023-11-15
* @version 1.0
*/
func main() {
// 创建一个消费者
consumer, err := sarama.newconsumer([]string{"47.115.230.36:9092"}, nil)
if err != nil {
fmt.println("消费者kafka连接服务失败,失败的原因:", err)
return
}
// 从topic123这个主题去获取消息
partitions, err := consumer.partitions("topic123")
if err != nil {
fmt.println("主题获取失败,失败的原因:", err)
return
}
fmt.println(partitions)
// 开始遍历分区中的消息,开始进行消费
for _, partition := range partitions {
pc, err := consumer.consumepartition("topic123", int32(partition), sarama.offsetnewest)
if err != nil {
fmt.println("分区数据获取失败,失败的原因:", err)
return
}
defer pc.asyncclose()
// 开始异步获取消息
go func(sarama.partitionconsumer) {
for message := range pc.messages() {
fmt.printf("当前消费的分区是:%d,offset:%d,key:%v,消息的内容是:%v", message.partition,
message.offset, message.key, string(message.value))
fmt.println("")
}
}(pc)
}
// 阻塞让消费一直处于监听状态
select {}
}2.3 创建主题代码示例
package main
import (
"fmt"
"github.com/shopify/sarama"
)
func createtopic(addrs []string, topic string) bool {
config := sarama.newconfig()
config.version = sarama.v2_0_0_0 // 设置客户端版本
config.admin.timeout = 3 * time.second // 设置admin请求超时时间
admin, err := sarama.newclusteradmin(addrs, config)
if err!= nil {
return false
}
defer admin.close()
err = admin.createtopic(topic, &sarama.topicdetail{numpartitions: 3, replicationfactor: 2}, false)
if err == nil {
fmt.println("success create topic:", topic)
} else {
fmt.println("failed create topic:", topic)
}
return err == nil
}2.4 性能测试结果
kafka目前已经成为云计算领域中的“事件驱动”架构、微服务架构中的主要消息队列,随着越来越多的公司和组织开始采用kafka作为基础消息队列技术,越来越多的性能测试报告也陆续出来。笔者提前做了一轮性能测试,并发现它的消费性能比其它消息队列还要好,甚至更好些。下面是测试结果:
测试环境:
- 操作系统:ubuntu 16.04
- cpu:intel® xeon® gold 6148 cpu @ 2.40ghz
- 内存:128g ddr4 ecc
- kafka集群:3节点,每节点配置6个cpu、32g内存、ssd
- 测试用例:生产者每秒钟发送2万条消息,消费者每秒钟消费100条消息。
测试结果:
kafka消费者
每秒消费100条消息,平均耗时:67毫秒
每秒消费1000条消息,平均耗时:6.7毫秒
rabbitmq消费者
每秒消费100条消息,平均耗时:1038毫秒
每秒消费1000条消息,平均耗时:10.38毫秒
3、参考
github.com/shopify/sarama github.com/bsm/sarama-cluster
生产者
import (
"fmt"
"math/rand"
"os"
"strconv"
"strings"
"time"
"github.com/shopify/sarama"
"github.com/golang/glog"
)
//同步生产者
func produce() {
config := sarama.newconfig()
config.producer.requiredacks = sarama.waitforall //赋值为-1:这意味着producer在follower副本确认接收到数据后才算一次发送完成。
config.producer.partitioner = sarama.newrandompartitioner //写到随机分区中,默认设置8个分区
config.producer.return.successes = true
msg := &sarama.producermessage{}
msg.topic = `test0`
msg.value = sarama.stringencoder("hello world!")
client, err := sarama.newsyncproducer([]string{"kafka_master:9092"}, config)
if err != nil {
fmt.println("producer close err, ", err)
return
}
defer client.close()
pid, offset, err := client.sendmessage(msg)
if err != nil {
fmt.println("send message failed, ", err)
return
}
fmt.printf("分区id:%v, offset:%v \n", pid, offset)
}
//异步生产者
func asyncproducer() {
var topics = "test0"
config := sarama.newconfig()
config.producer.return.successes = true //必须有这个选项
config.producer.timeout = 5 * time.second
p, err := sarama.newasyncproducer(strings.split("kafka_master:9092", ","), config)
defer p.close()
if err != nil {
return
}
//这个部分一定要写,不然通道会被堵塞
go func(p sarama.asyncproducer) {
errors := p.errors()
success := p.successes()
for {
select {
case err := <-errors:
if err != nil {
glog.errorln(err)
}
case <-success:
}
}
}(p)
for {
v := "async: " + strconv.itoa(rand.new(rand.newsource(time.now().unixnano())).intn(10000))
fmt.fprintln(os.stdout, v)
msg := &sarama.producermessage{
topic: topics,
value: sarama.byteencoder(v),
}
p.input() <- msg
time.sleep(time.second * 1)
}
}消费者
package consumer
import (
"fmt"
"strings"
"sync"
"time"
"github.com/shopify/sarama"
cluster "github.com/bsm/sarama-cluster"
"github.com/golang/glog"
)
//单个消费者
func consumer() {
var wg sync.waitgroup
consumer, err := sarama.newconsumer([]string{"kafka_master:9092"}, nil)
if err != nil {
fmt.println("failed to start consumer: %s", err)
return
}
partitionlist, err := consumer.partitions("test0") //获得该topic所有的分区
if err != nil {
fmt.println("failed to get the list of partition:, ", err)
return
}
for partition := range partitionlist {
pc, err := consumer.consumepartition("test0", int32(partition), sarama.offsetnewest)
if err != nil {
fmt.println("failed to start consumer for partition %d: %s\n", partition, err)
return
}
wg.add(1)
go func(sarama.partitionconsumer) { //为每个分区开一个go协程去取值
for msg := range pc.messages() { //阻塞直到有值发送过来,然后再继续等待
fmt.printf("partition:%d, offset:%d, key:%s, value:%s\n", msg.partition, msg.offset, string(msg.key), string(msg.value))
}
defer pc.asyncclose()
wg.done()
}(pc)
}
wg.wait()
}
//消费组
func consumergroup() {
groupid := "test-consumer-group"
config := cluster.newconfig()
config.group.return.notifications = true
config.consumer.offsets.commitinterval = 1 * time.second
config.consumer.offsets.initial = sarama.offsetnewest //初始从最新的offset开始
c, err := cluster.newconsumer(strings.split("kafka_master:9092", ","), groupid, strings.split("test0", ","), config)
if err != nil {
glog.errorf("failed open consumer: %v", err)
return
}
defer c.close()
go func(c *cluster.consumer) {
errors := c.errors()
noti := c.notifications()
for {
select {
case err := <-errors:
glog.errorln(err)
case <-noti:
}
}
}(c)
for msg := range c.messages() {
fmt.printf("partition:%d, offset:%d, key:%s, value:%s\n", msg.partition, msg.offset, string(msg.key), string(msg.value))
c.markoffset(msg, "") //markoffset 并不是实时写入kafka,有可能在程序crash时丢掉未提交的offset
}
}主函数
package main
import (
"strom-huang-go/go_kafka/consumer"
)
func main() {
// produce.asyncproducer()
consumer.consumer()
}到此这篇关于kafka安装部署+go整合的文章就介绍到这了,更多相关kafka安装部署内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论