go语言的并发模型是csp(通信顺序进程),提倡通过通信来进行内存共享,而不是通过共享内存来实现通信。
控制并发有三种经典的方式,使用 channel 通知实现并发控制、使用 sync 包中的 waitgroup 实现并发控制、使用 context 上下文实现并发控制。
一、使用 channel 通知实现并发控制
1、无缓冲通道
无缓冲通道,又叫做阻塞通道。发送方 (goroutine) 和接收方 (gouroutine) 必须是同步的,同时准备好,如果没有同时准备好的话,一方就会一直阻塞住,直到另一方准备好为止。
使用无缓冲通道进行通信,将发送和接收的 goroutine 同步化,因此,无缓冲通道也被称为同步通道。
ch := make(chan int) // 创建无缓冲通道
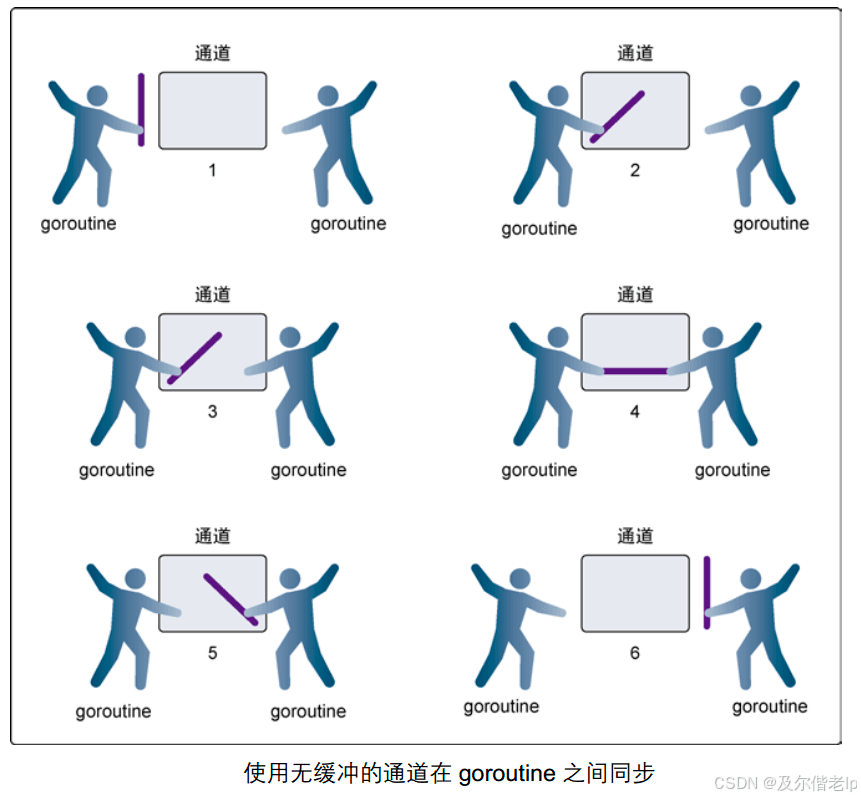
使用无缓冲通道实现并发控制:
package main
import "fmt"
func recv(c chan int) {
fmt.println("开始接收")
ret := <-c
fmt.println("接收成功", ret)
}
func main() {
ch := make(chan int)
go recv(ch) // 启用 goroutine 从通道接收值
ch <- 10
fmt.println("发送成功")
}
当子协程从无缓冲 channel 里接收值时,没有发送方,子协程阻塞等待,直到主协程往无缓冲 channel 里发送值,子协程开始执行,然后主协程开始执行。
2、有缓冲通道
只要通道的容量大于0,那么该通道就是有缓冲通道,通道的容量表示通道中能最多存放元素的数量。发送方在缓冲区满的时候阻塞,接收方不阻塞;接收方在缓冲区为空的时候阻塞,发送方不阻塞。
ch := make(chan int, 10) // 创建一个缓冲区为10的有缓冲通道 fmt.println(len(ch)) // 通过len函数获取当前通道内元素数量 fmt.println(cap(ch)) // 通过cap函数获取通道的容量
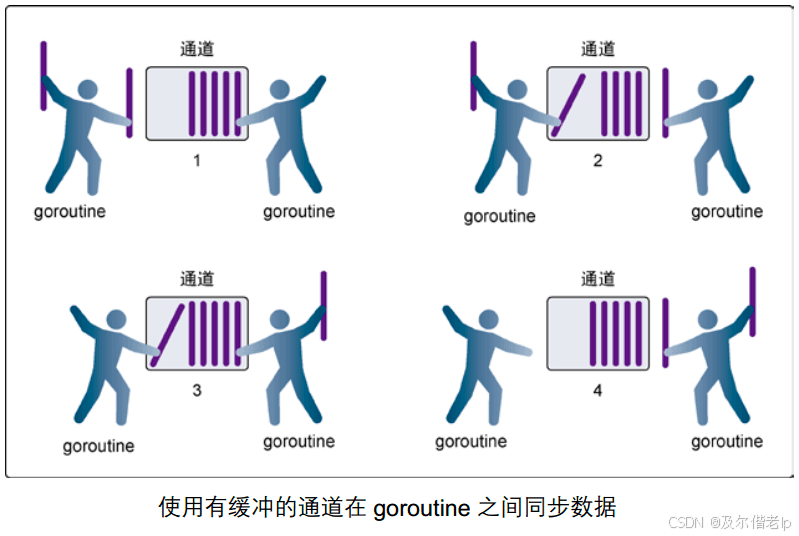
使用缓冲区为 1 的通道实现并发控制:
package main
import (
"fmt"
"time"
)
func recv(c chan int) {
fmt.println("开始接收")
ret := <-c
fmt.println("接收成功", ret)
}
func main() {
ch := make(chan int, 1)
ch <- 10
go recv(ch) // 启用 goroutine 从通道接收值
time.sleep(time.second)
fmt.println("发送成功")
}
当主协程往缓冲区为1的 channel 里发送值时,不阻塞,子协程启动,从无缓冲 channel 里接收值,主协程睡眠1秒,等待子协程执行完,主协程在执行。
二、使用 sync 包中的 waitgroup 实现并发控制
1、sync.waitgroup
在 sync 包中提供了 waitgroup ,它会等待它收集的所有 goroutine 任务全部完成。
在主协程中调用 add() 添加需要执行 goroutine 的数量,在每一个 goroutine 执行完成后调用 done() ,表示这个 goroutine 已经完成,主协程调用 wait() 阻塞等待所有 goroutine 执行完成,当所有的 goroutine 都执行完成后,主协程返回。
实现原理:sync.waitgroup 内部维护着一个计数器,计数器的值可以增加和减少,当我们启动 n 个并发任务时,将计数器增加 n,每个任务通过调用done方法将计数器减1,通过调用wait()来等待并发任务执行完,当计数器的值为 0 时,表示所有并发任务都已经完成。
sync.waitgroup有以下三种方法:
- add(n int) : 计数器 + n
- done() : 计数器 - 1
- wait() : 阻塞,直到计数器变为0
package main
import (
"fmt"
"sync"
)
var wg sync.waitgroup
func hello() {
defer wg.done()
fmt.println("hello goroutine!")
}
func main() {
wg.add(3)
go hello() // 启动3个goroutine去执行hello函数
go hello()
go hello()
fmt.println("main goroutine done!")
wg.wait()
}

扩展:
在golang官网中,有这么一句话:
a waitgroup must not be copied after first use.
意思是,在 waitgroup 第一次使用后,不能被拷贝。
为什么呢???
通过下面的例子我们浅浅分析一下。
package main
import (
"fmt"
"sync"
)
func main() {
wg := sync.waitgroup{}
for i := 0; i < 5; i++ {
wg.add(1)
go func(wg sync.waitgroup, i int) {
fmt.println(i)
wg.done()
}(wg, i)
}
wg.wait()
}
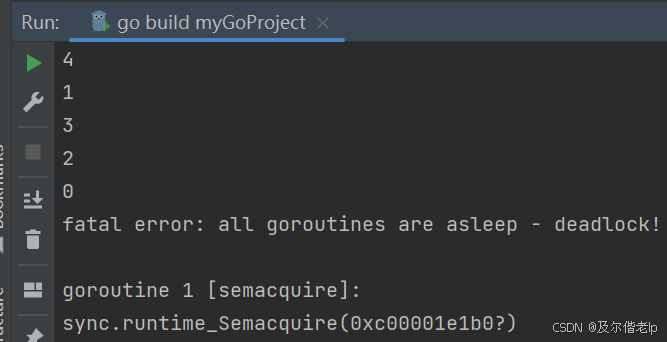
提示所有的 goroutine 都已经睡眠了,出现了死锁。这是因为 wg 值拷贝传递到了子 goroutine 中,导致只有 add 操作,done 操作是在 wg 的副本执行的, wg 的作用域为子协程,而不是全局,因此主协程就死锁了。
改正方法:
- 指针,将匿名函数中 wg 的传入类型改为 *sync.waitgroup 。
func main() {
wg := sync.waitgroup{}
for i := 0; i < 5; i++ {
wg.add(1)
go func(wg *sync.waitgroup, i int) {
fmt.println(i)
wg.done()
}(&wg, i)
}
wg.wait()
}
- 闭包,将匿名函数中的 wg 的传入参数去掉,在匿名函数中可以直接使用外面的 wg 变量。
func main() {
wg := sync.waitgroup{}
for i := 0; i < 5; i++ {
wg.add(1)
go func(i int) {
fmt.println(i)
wg.done()
}(i)
}
wg.wait()
}
2、sync.once
很多场景下,我们需要确保某些操作在高并发时只执行一次,例如只加载一次配置文件。go语言中的sync包提供了一个针对只执行一次场景的解决方案 sync.once。
sync.once只有一个do方法,do(f func()) 。
实现原理:sync.once 内部包含一个互斥锁和一个布尔值,互斥锁保证布尔值和数据的安全,而布尔值用来记录初始化是否完成,这样设计就能保证初始化操作的时候是并发安全的,并且初始化操作也不会执行多次。
样例如下:延迟一个开销很大的初始化操作到真正用到它的时候再执行。
package main
import (
"image"
"sync"
)
var icons map[string]image.image
var loadiconsonce sync.once
func loadicons() {
// 加载图片
icons = map[string]image.image{}
}
// icon 是并发安全的
func icon(name string) image.image {
loadiconsonce.do(loadicons)
return icons[name]
}
三、使用 context 上下文实现并发控制
1、简介
在一些简单场景下使用 channel 和 waitgroup 已经足够了,但是当面临一些复杂多变的网络并发场景下 channel 和 waitgroup 显得有些力不从心了。在并发程序中,由于超时、取消操作或者一些异常情况,往往需要进行抢占操作或者中断后续操作。
举个例子:在 go http包的server中,每一个请求在都有一个对应的 goroutine 去处理。请求处理函数通常会启动额外的 goroutine 用来访问后端服务,比如数据库和rpc服务,用来处理一个请求的 goroutine 通常需要访问一些与请求特定的数据,比如终端用户的身份认证信息、验证相关的token、请求的截止时间。 当一个请求被取消或超时时,所有用来处理该请求的 goroutine 都应该迅速中断退出,然后系统才能释放这些 goroutine 占用的资源。
所以我们需要一种可以跟踪 goroutine 的方案,才可以达到控制他们的目的,这就是go语言为我们提供的 context,称之为上下文非常贴切,它就是 goroutine 的上下文。它包括一个程序的运行环境、现场和快照等。每个程序要运行时,都需要知道当前程序的运行状态,通常go 将这些封装在一个 context 里,再将它传给要执行的 goroutine 。context 包主要是用来处理多个 goroutine 之间共享数据,及多个 goroutine 的管理。
context常用的使用场景:
- 一个请求对应多个goroutine之间的数据交互
- 超时控制
- 上下文控制
2、context 包
context 包的核心是 struct context,接口声明如下:
type context interface {
// 返回context的超时时间(超时返回场景)
deadline() (deadline time.time, ok bool)
// 在context超时或取消时(即结束了)返回一个关闭的channel,取消信号
// 如果当前context超时或取消时,done方法会返回一个channel,然后其他地方就可以通过判断done方法是否有返回(channel),如果有则说明context已结束
// 故其可以作为广播通知其他相关方本context已结束,请做相关处理。
done() <-chan struct{}
// 返回context取消的原因
err() error
// 返回context相关数据
value(key any) any
}
context 对象是线程安全的(底层数据结构加了互斥锁),你可以把一个 context 对象传递给任意个数的 gorotuine,对它执行取消操作时,所有 goroutine 都会接收到取消信号。
一个 context 不能拥有 cancel 方法,同时我们也只能 done channel 接收数据。原因是:接收取消信号的函数和发送信号的函数通常不是一个。一个典型的场景是:父操作为子操作操作启动 goroutine,子操作也就不能取消父操作。
3、继承 context
context 包提供了一些函数,协助用户从现有的 context 对象创建新的 context 对象。这些 context 对象形成一棵树:当一个 context 对象被取消时,继承自它的所有 context 都会被取消。
background 是所有 context 对象树的根,它不能被取消。context 包提供了三种context,分别是普通context、超时context、带值的context:
func background() context {
return backgroundctx{}
}
// 普通context,通常这样调用:
ctx, cancel := context.withcancel(context.background())
func withcancel(parent context) (ctx context, cancel cancelfunc)
// 带超时的context,超时之后会自动close对象的done,与调用cancelfunc的效果一样
// withdeadline 明确地设置一个d指定的系统时钟时间,如果超过就触发超时
// withtimeout 设置一个相对的超时时间,也就是deadline设为timeout加上当前的系统时间
// 因为两者事实上都依赖于系统时钟,所以可能存在微小的误差,所以官方不推荐把超时间隔设置得太小
// 通常这样调用:
ctx, cancel := context.withtimeout(context.background(), 5*time.second)
func withdeadline(parent context, d time.time) (context, cancelfunc)
func withtimeout(parent context, timeout time.duration) (context, cancelfunc)
// 带有值的context,没有cancelfunc,所以它只用于值的多goroutine传递和共享
// 通常这样调用:
ctx := context.withvalue(context.background(), "key", myvalue)
func withvalue(parent context, key, val interface{}) context
withcancel 和 withtimeout 函数会返回继承的 context 对象, 这些对象可以比它们的父 context 更早地取消。当请求处理函数返回时,与该请求关联的 context 会被取消。当使用多个副本发送请求时,可以使用 withcancel 取消多余的请求。 withtimeout 在设置对后端服务器请求超时时间时非常有用。withvalue 函数能够将请求作用域的数据与 context 对象建立关系。
4、context 例子
下面的例子,主要描述的是通过一个 channel 实现一个为循环次数为5的循环。
package main
import (
"context"
"fmt"
"time"
)
func childfunc(cont context.context, num *int) {
ctx, _ := context.withcancel(cont)
for {
select {
case <-ctx.done():
fmt.println("child done : ", ctx.err())
return
}
}
}
func main() {
gen := func(ctx context.context) <-chan int {
dst := make(chan int)
n := 1
go func() {
for {
select {
case <-ctx.done():
fmt.println("parent done : ", ctx.err())
return // returning not to leak the goroutine
case dst <- n:
n++
go childfunc(ctx, &n)
}
}
}()
return dst
}
ctx, cancel := context.withcancel(context.background())
for n := range gen(ctx) {
fmt.println(n)
if n >= 5 {
break
}
}
cancel()
time.sleep(5 * time.second)
}
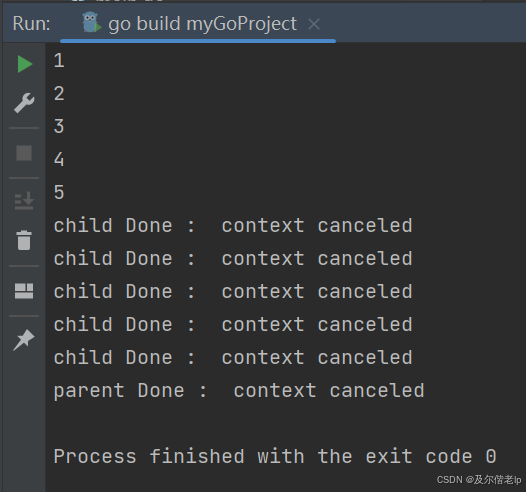
在每一个循环中产生一个goroutine,每一个goroutine中都传入context,在每个goroutine中通过传入 ctx 创建一个子context,并且通过 select 一直监控该context的运行情况,当父 context 退出的时候,代码中并没有明显调用子 context 的 cancel 函数,但是分析结果,子 context 还是被正确合理的关闭了,这是因为,所有基于这个 context 或者衍生的子 context 都会收到通知,这时就可以进行清理操作了,最终释放 goroutine,这就优雅的解决了 goroutine 启动后不可控的问题。
5、context 使用原则
- 不要把 context 放在结构体中,要以参数的方式传递。
- 以 context 作为参数的函数方法,应该把 context 作为第一个参数,放在第一位。
- 给一个函数方法传递 context 的时候,不要传递nil,如果不知道传递什么,就使用context.todo。
- context 的 value 相关方法应该传递必须的数据,不要什么数据都使用这个传递。
- context 是线程安全的,底层数据结构加了互斥锁,可以放心的在多个goroutine中传递。
到此这篇关于golang 并发控制模型的实现的文章就介绍到这了,更多相关golang 并发控制内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!


发表评论