
python搭建文件下载服务
在web开发中,文件下载服务是一个常见且基础的功能。python的http.server模块提供了一个简单而强大的方式来搭建http服务器,进而实现文件下载服务。本文将结合实际案例,详细介绍如何使用python的http.server模块来搭建文件下载服务。
一、概述
python的http.server模块是python标准库的一部分,它提供了一个基本的http服务器类和请求处理器。通过这个模块,我们可以轻松地搭建一个http服务器,用于处理客户端的http请求,包括文件下载请求。
1.1 准备工作
在开始之前,请确保你的计算机上已安装python环境。python 3.x版本已经内置了http.server模块,因此你不需要额外安装任何库。
1.2 场景描述
假设我们有一个需求:需要搭建一个http服务器,用于提供特定目录下的文件下载服务。客户端通过访问服务器上的特定url,即可下载服务器上的文件。
二、搭建http服务器
2.1 基础服务器搭建
首先,我们将使用http.server模块搭建一个基础的http服务器。
2.1.1 示例代码
import http.server
import socketserver
# 设置端口号
port = 8000
# 创建一个tcp服务器
with socketserver.tcpserver(("", port), http.server.simplehttprequesthandler) as httpd:
print("serving at port", port)
# 启动服务器,使其一直运行
httpd.serve_forever()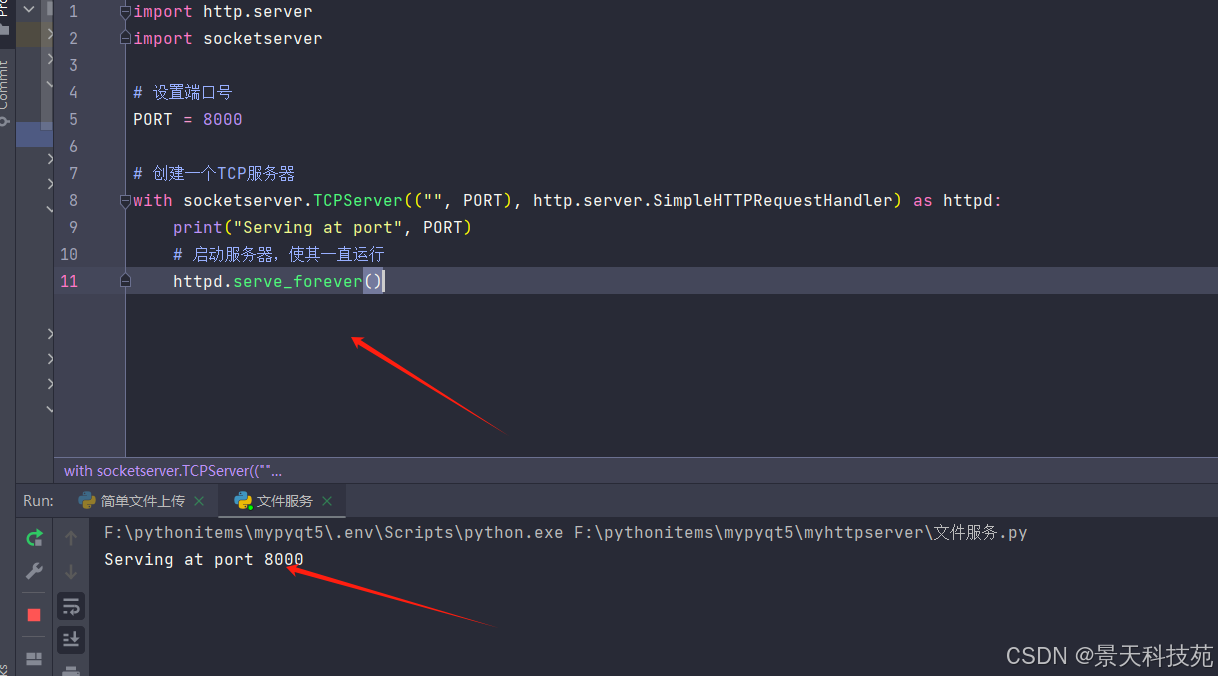
在上述代码中,我们导入了http.server和socketserver模块,并设置了服务器监听的端口号为8000。然后,我们创建了一个tcpserver实例,并将http.server.simplehttprequesthandler作为请求处理器传入。最后,我们调用serve_forever()方法启动服务器,使其持续运行。
2.1.2 运行服务器
将上述代码保存为一个.py文件,例如server.py。然后,在命令行中导航到该文件所在的目录,并执行以下命令:
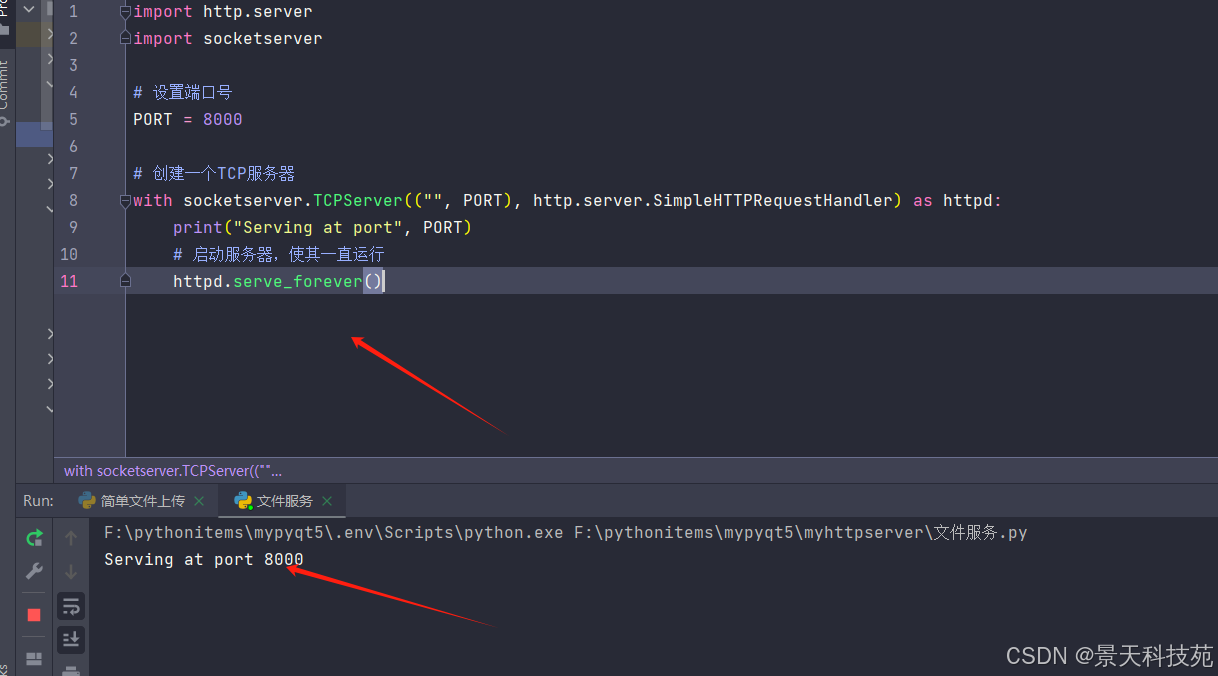
python server.py
执行后,你将在控制台看到“serving at port 8000”的提示,表示服务器已成功启动。
2.2 自定义文件目录
默认情况下,simplehttprequesthandler会处理服务器当前工作目录下的文件。然而,我们可能希望服务器处理特定目录下的文件。为了实现这一需求,我们可以创建一个继承自simplehttprequesthandler的类,并重写translate_path方法。
2.2.1 示例代码
import http.server
import socketserver
import os
# 定义服务器端口
port = 8080
# 定义文件目录
directory = "/path/to/your/directory"
# 创建一个处理请求的类
class myhandler(http.server.simplehttprequesthandler):
def translate_path(self, path):
# 确保返回的路径在指定的目录内
path = os.path.normpath(os.path.join(directory, path.lstrip('/')))
return path
# 创建服务器
with socketserver.tcpserver(("", port), myhandler) as httpd:
print(f"serving at port {port}")
# 启动服务器,使其一直运行
httpd.serve_forever()在上述代码中,我们定义了directory变量来指定文件所在的目录,并创建了一个myhandler类,该类继承自simplehttprequesthandler并重写了translate_path方法。在translate_path方法中,我们通过os.path.join和os.path.normpath函数将请求的路径与directory变量拼接起来,并确保返回的路径在指定的目录内。
2.2.2 运行服务器
将上述代码保存为一个.py文件,并替换directory变量的值为你希望服务器处理的文件目录。然后,按照2.1.2节中的步骤运行服务器。
2.3 上传下载服务
有时,我们可能需要定制http响应头,以满足特定的需求。
2.3.1 示例代码
为了定制响应头,我们继续上面的例子,通过重写do_get方法来设置特定的http响应头,比如content-disposition以支持文件下载。
import os
import cgi
from http.server import httpserver, basehttprequesthandler
from urllib.parse import unquote
class simplehttprequesthandler(basehttprequesthandler):
def do_get(self):
# parse the url to get the file path
file_path = unquote(self.path.strip("/"))
if os.path.isfile(file_path):
# if the requested path is a file, serve the file as an attachment
self.send_response(200)
self.send_header('content-type', 'application/octet-stream')
# self.send_header('content-disposition', f'attachment; filename="{os.path.basename(file_path)}"')
self.end_headers()
with open(file_path, 'rb') as file:
self.wfile.write(file.read())
else:
# otherwise, show the upload form and file list
self.send_response(200)
self.send_header('content-type', 'text/html')
self.end_headers()
# list files in the current directory
file_list = os.listdir('.')
file_list_html = ''.join(f'<li><a href="/{file}" rel="external nofollow" >{file}</a></li>' for file in file_list)
self.wfile.write(f'''
<html>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
<body>
<form enctype="multipart/form-data" method="post">
<input type="file" name="file">
<input type="submit" value="upload">
</form>
<h2>files in current directory:</h2>
<ul>
{file_list_html}
</ul>
</body>
</html>
'''.encode())
def do_post(self):
try:
content_type = self.headers['content-type']
if 'multipart/form-data' in content_type:
form = cgi.fieldstorage(
fp=self.rfile,
headers=self.headers,
environ={'request_method': 'post'}
)
file_field = form['file']
if file_field.filename:
# save the file
with open(os.path.join('.', file_field.filename), 'wb') as f:
f.write(file_field.file.read())
self.send_response(200)
self.send_header('content-type', 'text/html')
self.end_headers()
self.wfile.write(b'''
<html>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
<body>
<p>file uploaded successfully.</p>
<script>
settimeout(function() {
window.location.href = "/";
}, 2000);
</script>
</body>
</html>
''')
else:
self.send_response(400)
self.send_header('content-type', 'text/html')
self.end_headers()
self.wfile.write(b'''
<html>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
<body>
<p>no file uploaded.</p>
<script>
settimeout(function() {
window.location.href = "/";
}, 2000);
</script>
</body>
</html>
''')
else:
self.send_response(400)
self.send_header('content-type', 'text/html')
self.end_headers()
self.wfile.write(b'''
<html>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
<body>
<p>invalid content type.</p>
<script>
settimeout(function() {
window.location.href = "/";
}, 2000);
</script>
</body>
</html>
''')
except exception as e:
self.send_response(500)
self.send_header('content-type', 'text/html')
self.end_headers()
self.wfile.write(f'''
<html>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
<body>
<p>error occurred: {str(e)}</p>
<script>
settimeout(function() {{
window.location.href = "/";
}}, 2000);
</script>
</body>
</html>
'''.encode())
def run(server_class=httpserver, handler_class=simplehttprequesthandler, port=8000):
server_address = ('', port)
httpd = server_class(server_address, handler_class)
# uncomment the following lines if you need https support
# httpd.socket = ssl.wrap_socket(httpd.socket,
# keyfile="path/to/key.pem",
# certfile='path/to/cert.pem', server_side=true)
print(f'starting httpd server on port {port}...')
httpd.serve_forever()
if __name__ == '__main__':
run()在上述代码中,customfilehandler类继承自之前定义的myhandler类(或直接从http.server.simplehttprequesthandler继承,如果你没有重写translate_path方法的话)。我们重写了do_get方法,以处理get请求并定制响应头。
- 首先,我们通过
translate_path方法获取请求文件的实际路径。 - 然后,我们检查该文件是否存在。
- 如果文件存在,我们使用
mimetypes.guess_type函数猜测文件的mime类型,并设置相应的content-type响应头。 - 最后,我们打开文件,并使用
copyfile方法将文件内容发送给客户端。
如果文件不存在,我们通过send_error方法返回404错误。
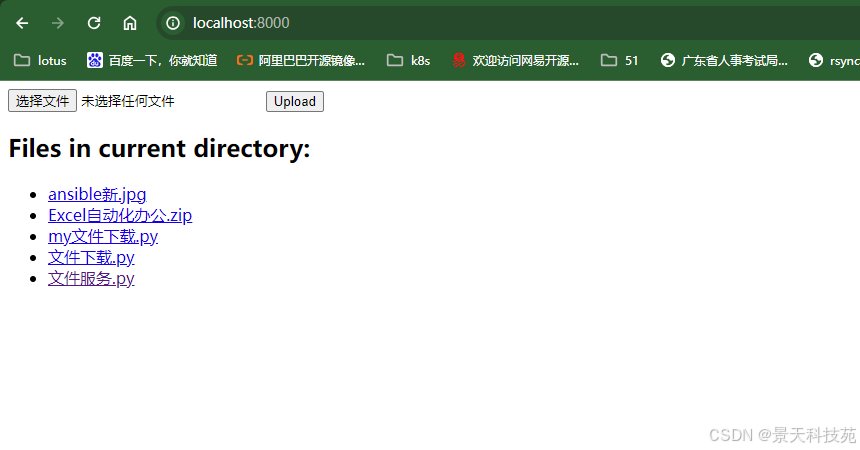
浏览器访问http://localhost:8000/
能看到下载列表
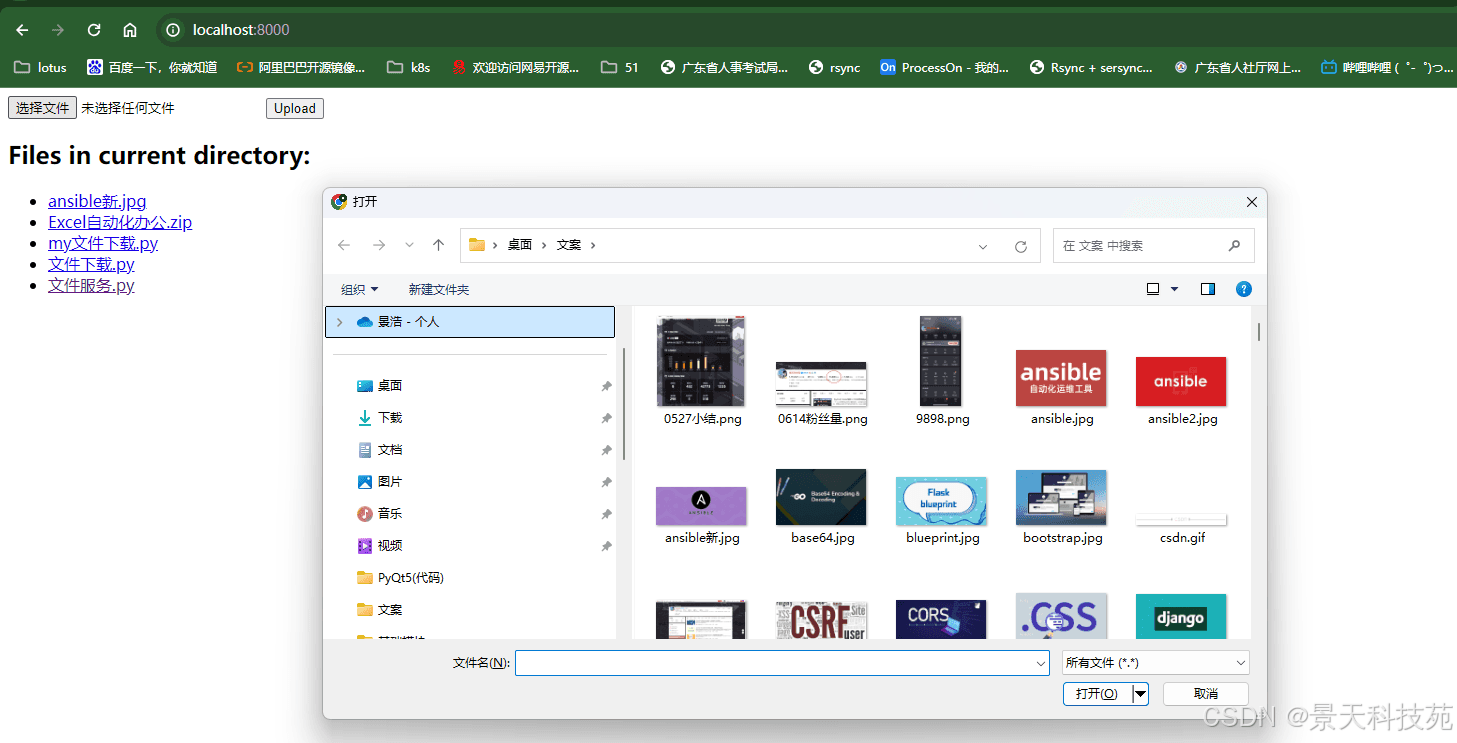
点击选择文件可以上传
2.3.2 运行服务器
将上述代码保存为一个.py文件,并替换directory变量的值为你希望服务器处理的文件目录。然后,按照之前的步骤运行服务器。
现在,当你通过浏览器访问服务器上的文件时(例如,http://localhost:8080/example.pdf),浏览器将以下载的方式处理该文件,而不是尝试在浏览器中打开它。
三、安全性考虑
虽然http.server模块提供了一个快速搭建http服务器的方法,但它在安全性方面存在一些局限性。例如,默认情况下,它会处理服务器上所有可读文件的请求,这可能会暴露敏感信息。
为了增强安全性,你可以:
- 限制服务器的访问权限,例如,使用防火墙规则来限制只有特定的ip地址或网络才能访问服务器。
- 创建一个白名单,仅允许访问白名单中指定的文件或目录。
- 使用更安全的http服务器框架,如flask或django,这些框架提供了更丰富的功能和更好的安全性支持。
四、总结
通过本教程,我们学习了如何使用python的http.server模块搭建一个基本的http服务器,并实现文件下载服务。我们介绍了如何设置服务器端口、自定义文件目录、定制http响应头以及处理get请求。最后,我们还讨论了使用http.server模块时需要注意的一些安全性问题。希望这些内容对你有所帮助!
到此这篇关于通过python中的http.server搭建文件上传下载服务功能的文章就介绍到这了,更多相关python http.server文件上传下载服务内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论