 2024软件测试面试刷题,这个小程序(永久刷题),靠它快速找到工作了!(刷题app的天花板)
2024软件测试面试刷题,这个小程序(永久刷题),靠它快速找到工作了!(刷题app的天花板)
selenium 遇见伪元素该如何处理?
问题发生
在很多前端页面中,大家会见到很多::before、::after 元素,比如【百度流量研究院】:
比如【百度疫情大数据平台】:
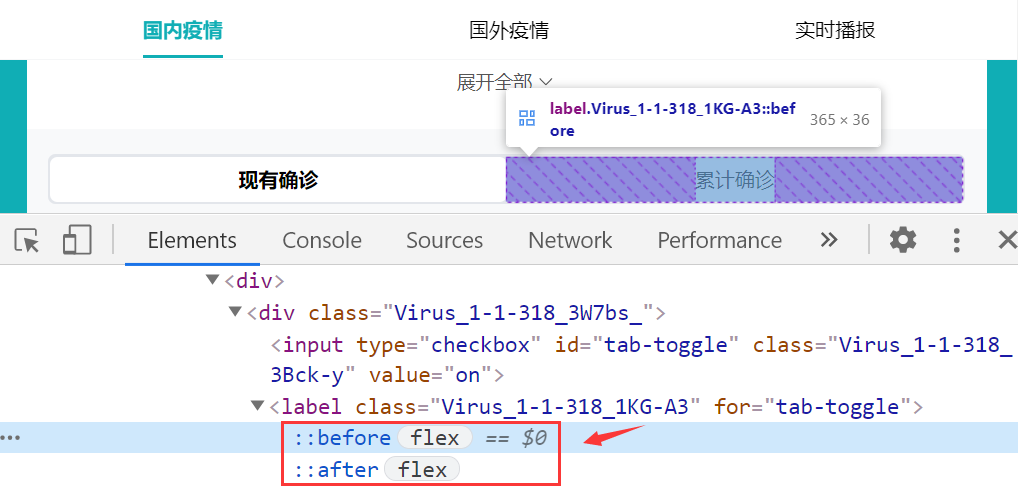
以【百度疫情大数据平台】为例,“累计确诊”文本并没有显示在 html 源代码中,如果通过常规的 xpath 元素定位方式是没办法的,因为“累计确诊”文本并不存在当前页面 dom 树中。
如何处理?
我们要弄清楚的是该元素的特殊之处,文本究竟存放在哪?
其实很简单,通过 chrome 的 f12,我们将 style 选项展示出来:
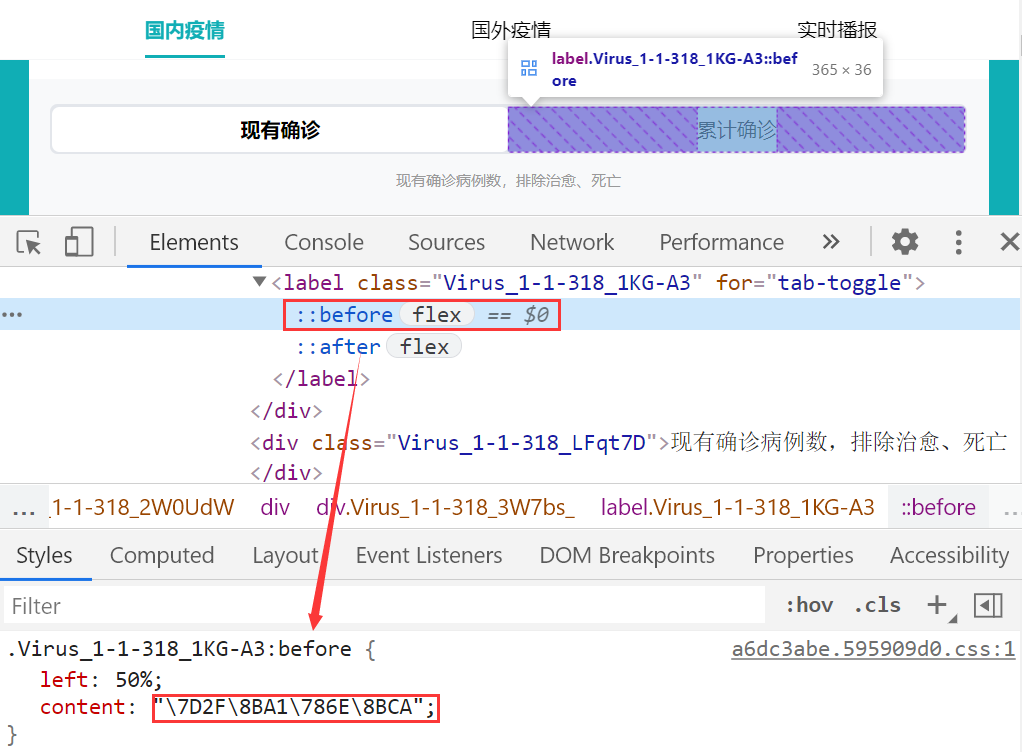
可以看到元素的文本保存在 css 样式里面,通过 content 属性进行设置。
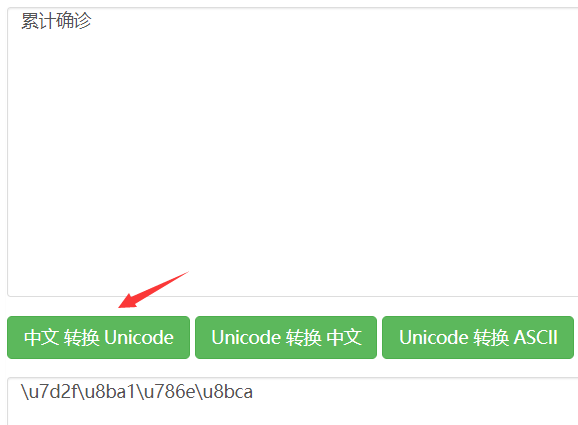
这里还有个小问题:文本根本对不上呢?
因为这里使用了 unicode 编码,使用在线的 unicode 编码转换工具即可看到
::after 元素也是同理,这种性质的元素我们称之为伪元素:
之所以被称为伪元素,是因为他们不是真正的页面元素,html 没有对应的元素,但是其所有用法和表现行为与真正的页面元素一样,可以对其使用诸如页面元素一样的 css 样式,表面上看上去貌似是页面的某些元素来展现,实际上是 css 样式展现的行为,因此被称为伪元素。
一、伪元素的定位
由于伪元素是通过 css 样式展现的行为,所以我们可以通过 css 样式选择器来进行定位,以“百度疫情大数据为例”:
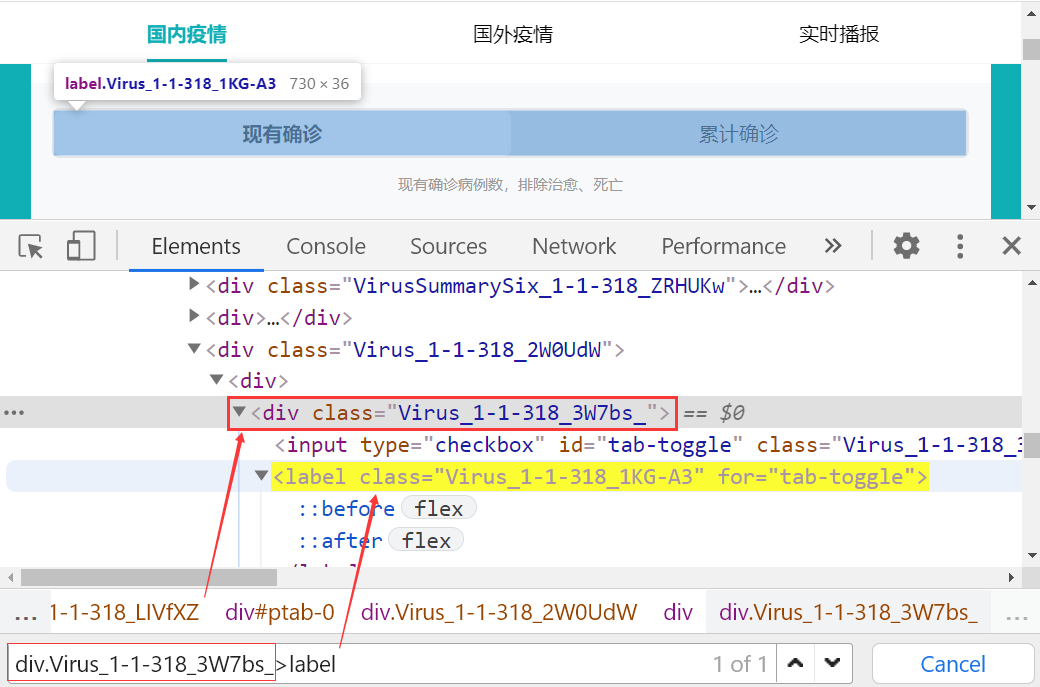
先定位伪元素的父元素:div.virus_1-1-318_3w7bs_
再定位到伪元素本身:div.virus_1-1-318_3w7bs_>label
二、伪元素文本的获取
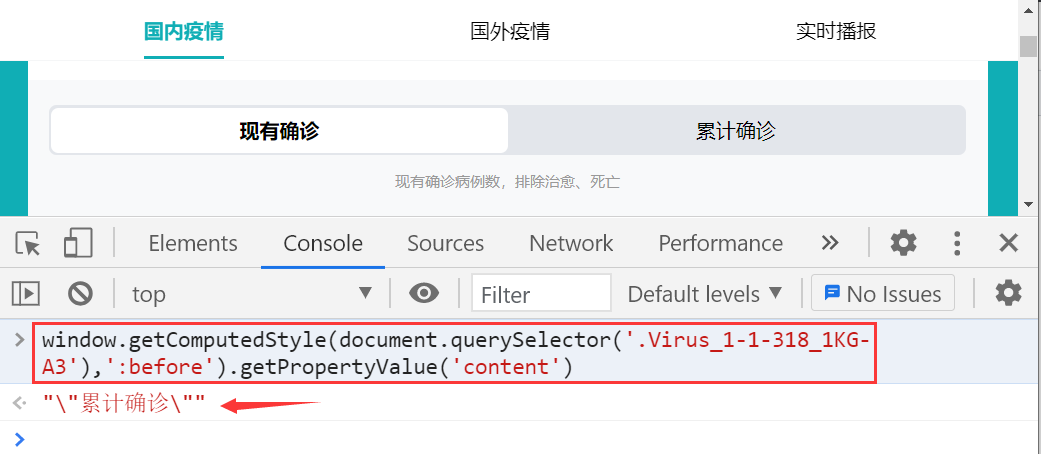
有些情况下我们需要获取到文本信息,其中伪元素的文本主要是通过 content 属性设置,我们可以通过 javascript 可以进行提取:
window.getcomputedstyle(document.queryselector('.样式'),':before').getpropertyvalue('content')
window.getcomputedstyle(document.queryselector('.样式'),':after').getpropertyvalue('content')
selenium 中调用 javascript:
javascriptexecutor jsexecutor = (javascriptexecutor) driver;
jsexecutor.executescript("window.getcomputedstyle(document.queryselector(
行动吧,在路上总比一直观望的要好,未来的你肯定会感谢现在拼搏的自己!如果想学习提升找不到资料,没人答疑解惑时,请及时加入群: 786229024,里面有各种测试开发资料和技术可以一起交流哦。
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取 【保证100%免费】
软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。



发表评论