收到一批社区用户的使用建议后,我们在 deepflow 6.4 社区版中新增了一个简洁易用的「开箱即用」 dashboard。当用户初次安装 deepflow、业务变更、扩容缩容时,随时都可以查看这个 dashboard,及时发现应用的性能和稳定性隐患,深刻感受基于 ebpf 的零侵扰可观测性带来的便捷。
01
开箱即用 dashboard
deepflow 在此之前提供的 application 系列 dashboard,主要用于观测 red(请求、错误、时延)黄金指标的历史变化、服务之间的调用关系、服务的请求日志详情。此类 grafana dashboard 的缺点是不同 panel 之间的联动分析能力较弱,需要较多的手动操作。因此社区在此基础上针对初次体验、业务变更等使用场景,提供了一个新的开箱即用 dashboard。
过滤条件区域
通过【过滤条件】过滤需要分析的服务。

- server:需要分析服务(作为服务端)
- endpoint:端点,端点的提取方式参考应用协议字段映射文档
- l7_protocol:应用协议,对应 http、rpc、sql、mq、dns 等应用协议
- signal_source:信号源,目前支持进行区分的三种信号源为 packet (cbpf)、ebpf、otel
- ebpf:使用 ebpf 零侵扰采集的函数调用数据,dashboard 默认查看的是 ebpf 信号源。如果你的操作系统内核不支持 ebpf,可手动切换到 packet 查看数据
- packet:使用 af_packet + cbpf 零侵扰采集的网卡流量数据
- otel:使用 otlp 协议集成的分布式追踪数据
端点列表区域
通过【端点列表】分析服务 api 的 red 指标。
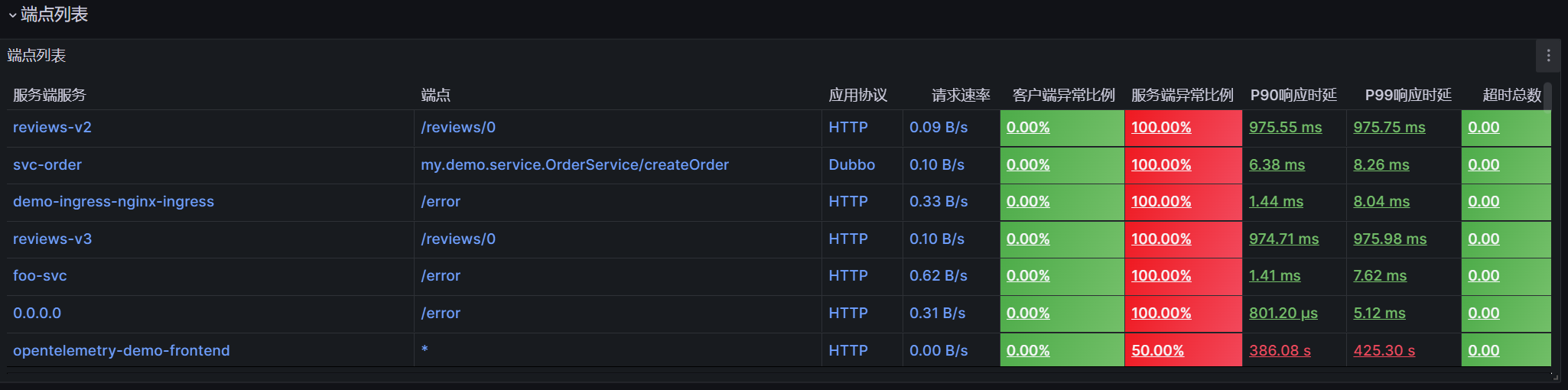
端点列表可查看服务端服务 (auto_service_1)、端点 (endpoint)、应用协议 (l7_protocol) 对应的请求速率、响应异常、响应时延指标量。表格支持的操作如下:
- 点击指标量的表头可进行排序,快速过滤出异常比例高或响应时延大的服务端点
- 点击表格某一行,将打开一个新页面,展示点击行对应的服务端服务 + 端点 + 应用协议的端点详情
端点详情区域
通过【端点详情】观测 api endpoint 对应的 red 指标变化趋势、api 调用详情、调用链追踪信息。
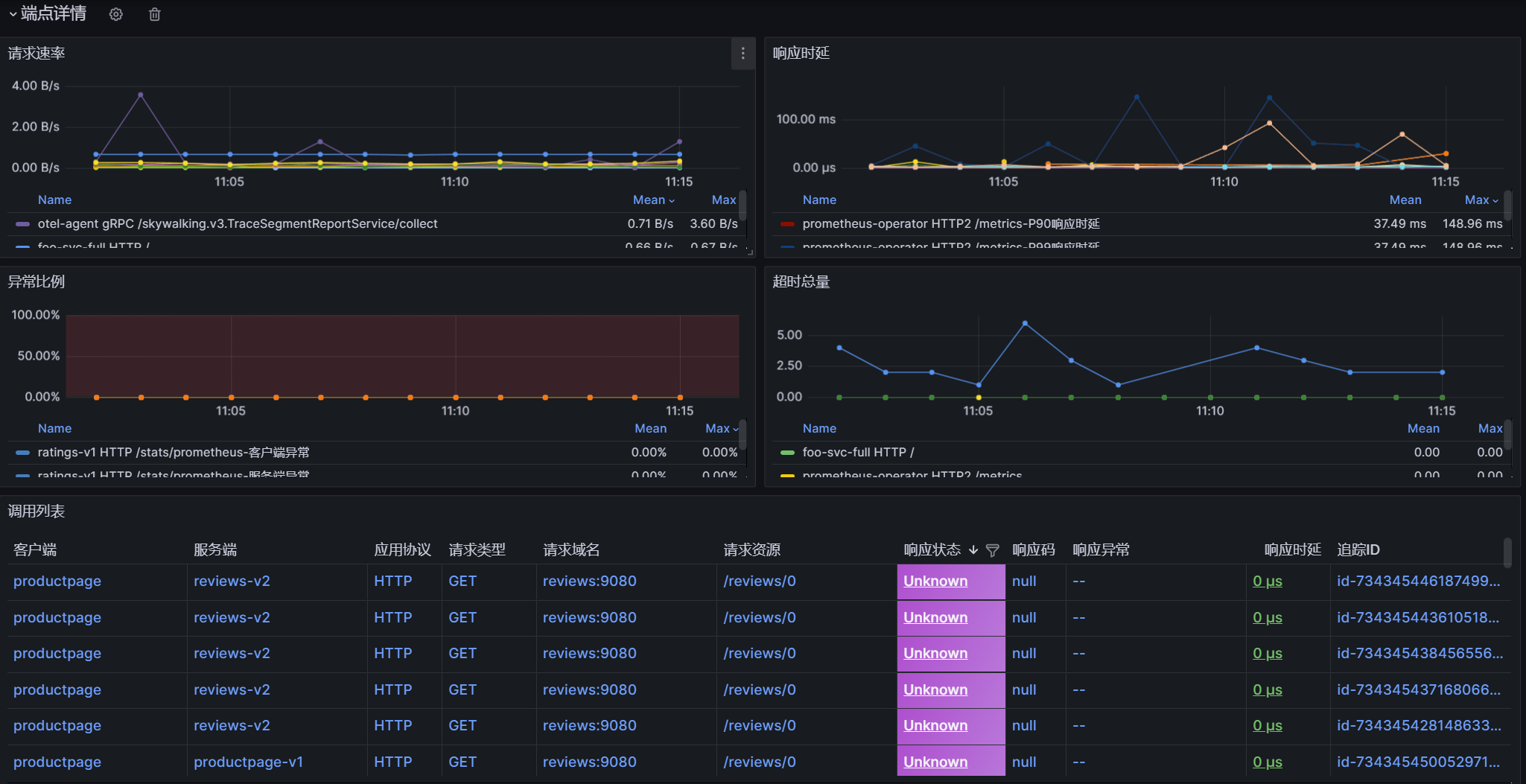
指标折线图
- 请求速率:查看 server + endpoint + l7_protcol 变量对应的请求速率变化趋势,图例由 $ 服务端服务 $ 应用协议 $ 端点组成。
- 响应时延:查看 server + endpoint + l7_protcol 变量对应的响应时延变化趋势,其中包含 p90 响应时延及 p99 响应时延两个指标量,图例由 $ 服务端服务 $ 应用协议 $ 端点-$ 指标量名称组成。
- 异常比例:查看 server + endpoint + l7_protcol 变量对应的异常比例变化趋势,其中包含客户端异常比例及服务端异常比例两个指标量,图例由 $ 服务端服务 $ 应用协议 $ 端点-$ 指标量名称组成。
- 超时总数:查看 server + endpoint + l7_protcol 变量对应的超时变化趋势,图例由 $ 服务端服务 $ 应用协议 $ 端点组成。
调用列表
查看 server + endpoint + l7_protcol 变量对应的调用详情列表,可查看客户端服务、响应码、响应异常描述等等信息。表格支持的操作如下:
- 点击响应状态表头漏斗 icon,支持根据响应状态过滤数据
- 点击响应时延表头,支持按指标量进行排序
- 点击表格中的某一行,可对当前调用进行追踪,结果可在调用链追踪对应的火焰图中查看
调用链追踪
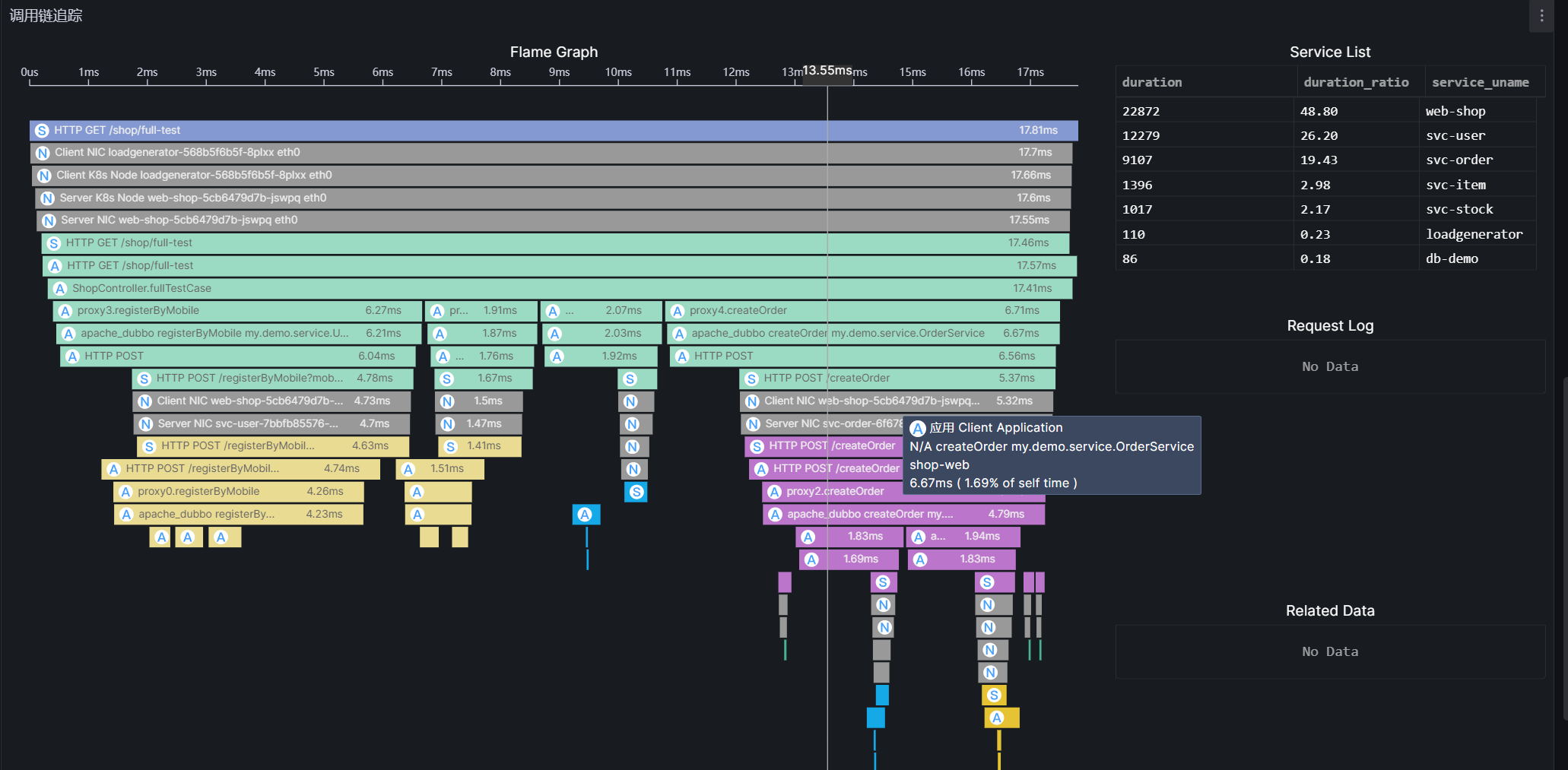
当点击「调用列表」中的一行时,调用链追踪区域即可以火焰图形式展示链路,对于火焰图的使用可参考 deepflow 帮助文档中的调用链追踪说明。
02
dashboard 用法举例
以下使用一个 demo 演示如何利用开箱即用 dashboard 在分钟级排查应用问题。
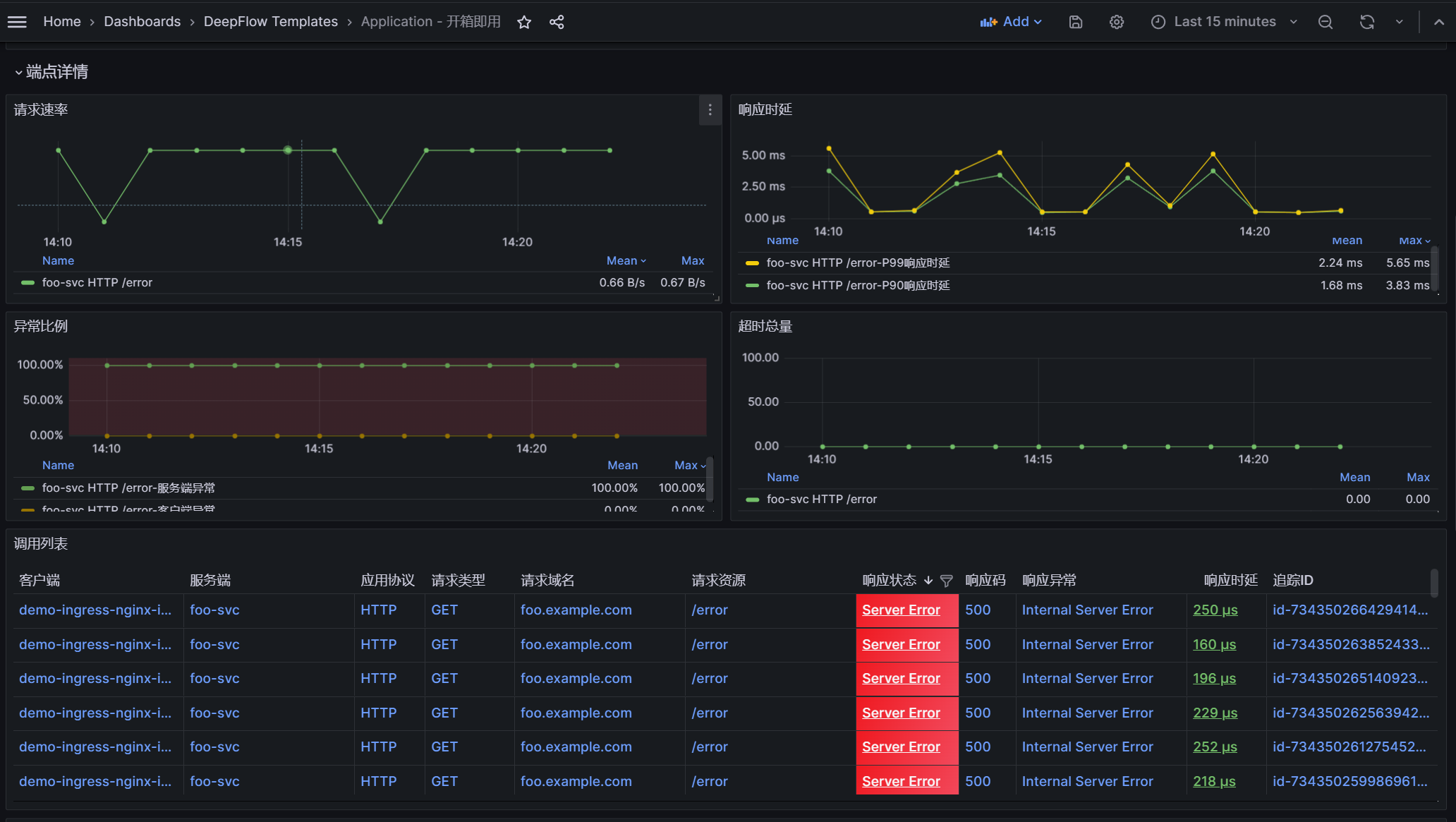
step 1:过滤 foo-svc 服务,通过端点列表发现 /error 接口服务端异常比例高达 100%。
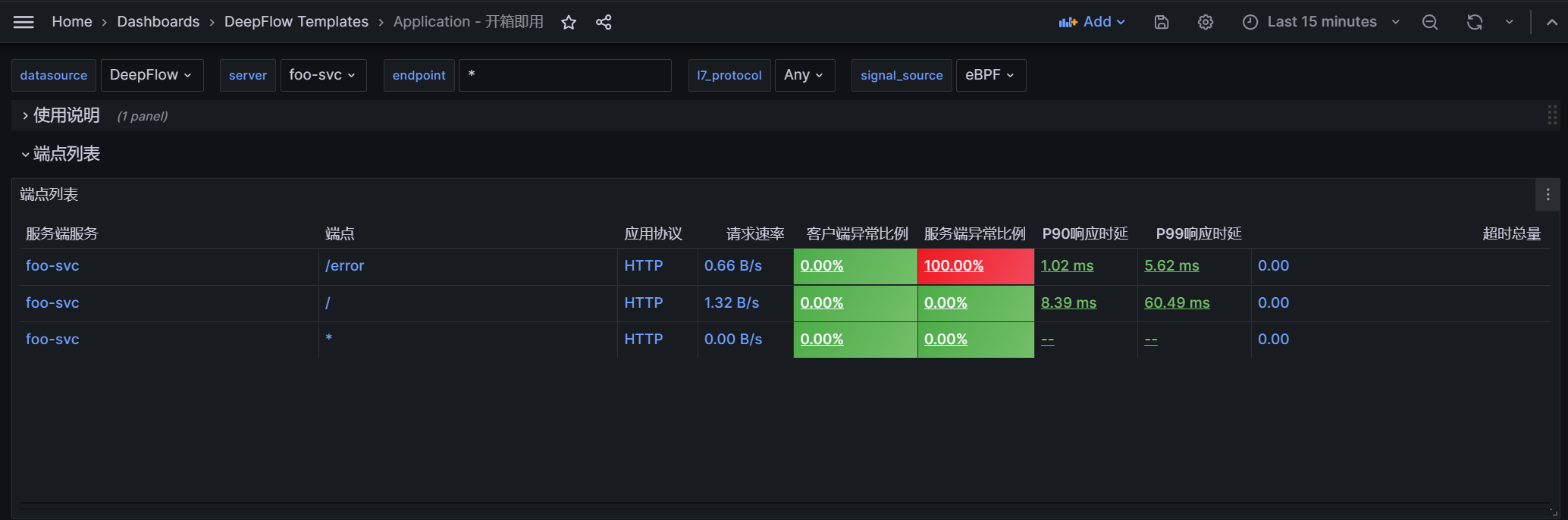
step 2:点击端点列表 /error 行,通过新 tab 查看端点详情,通过异常比例曲线发现一直存在异常,通过调用列表发现都是 demo-ingress-nginx-ingress 访问 foo.example.com/error 链接时,foo-svc 返回了 500 异常。
step 3:点击调用列表中 500 异常的行,对异常调用发起追踪,通过调用链追踪火焰图可知整个调用由 loadgenerator-ng 服务通过 curl 发起的调用,调用经过了 demo-ingress-nginx-ingress,然后转发到了 foo-svc,最后 foo-svc 的 java 进程返回了 500 异常。
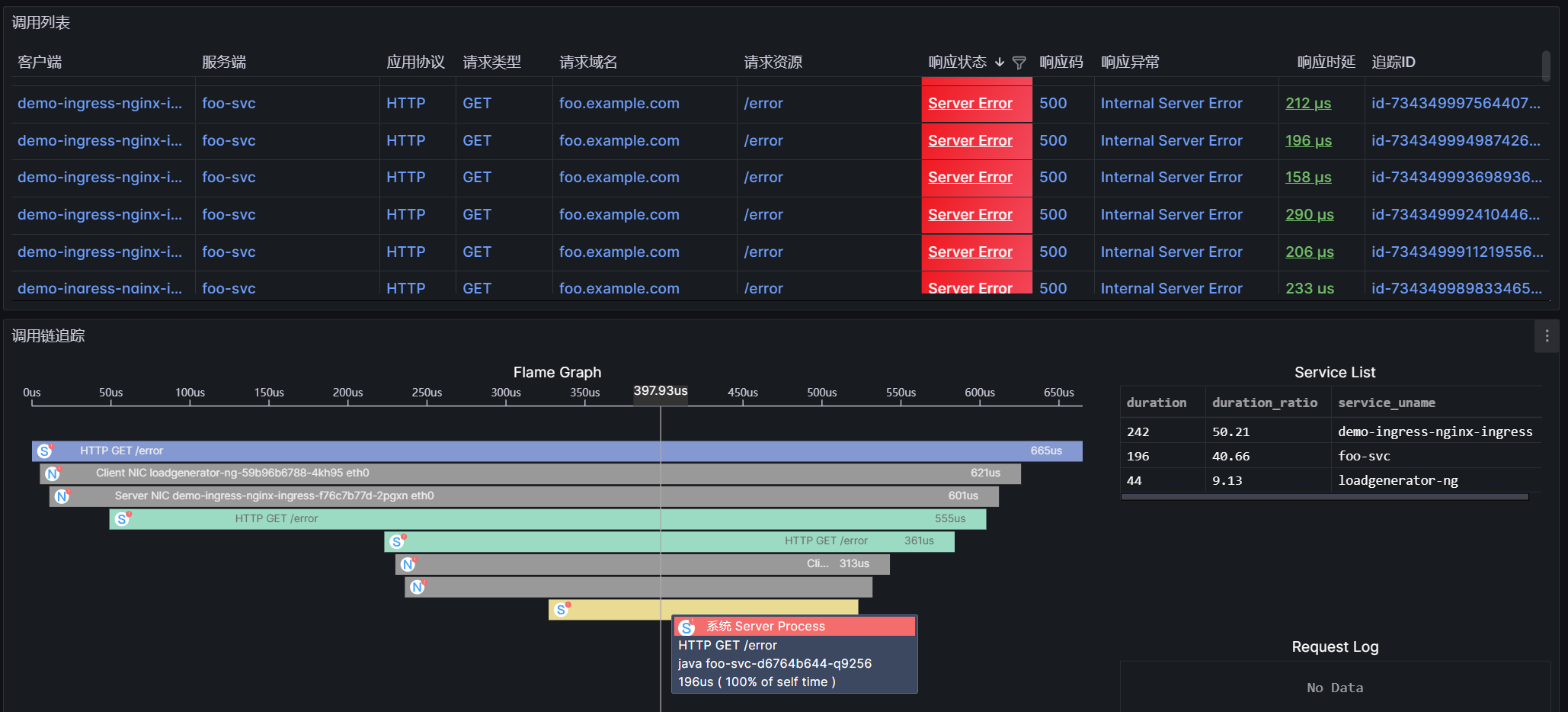
至此,我们仅查看一个 dashboard、只需两三步操作,即完成了一次故障定界。这些能力都是你在一键安装完 deepflow 的五分钟后就能立即获取的,真·开箱即用的应用可观测性。
03
对研发效能提升的意义
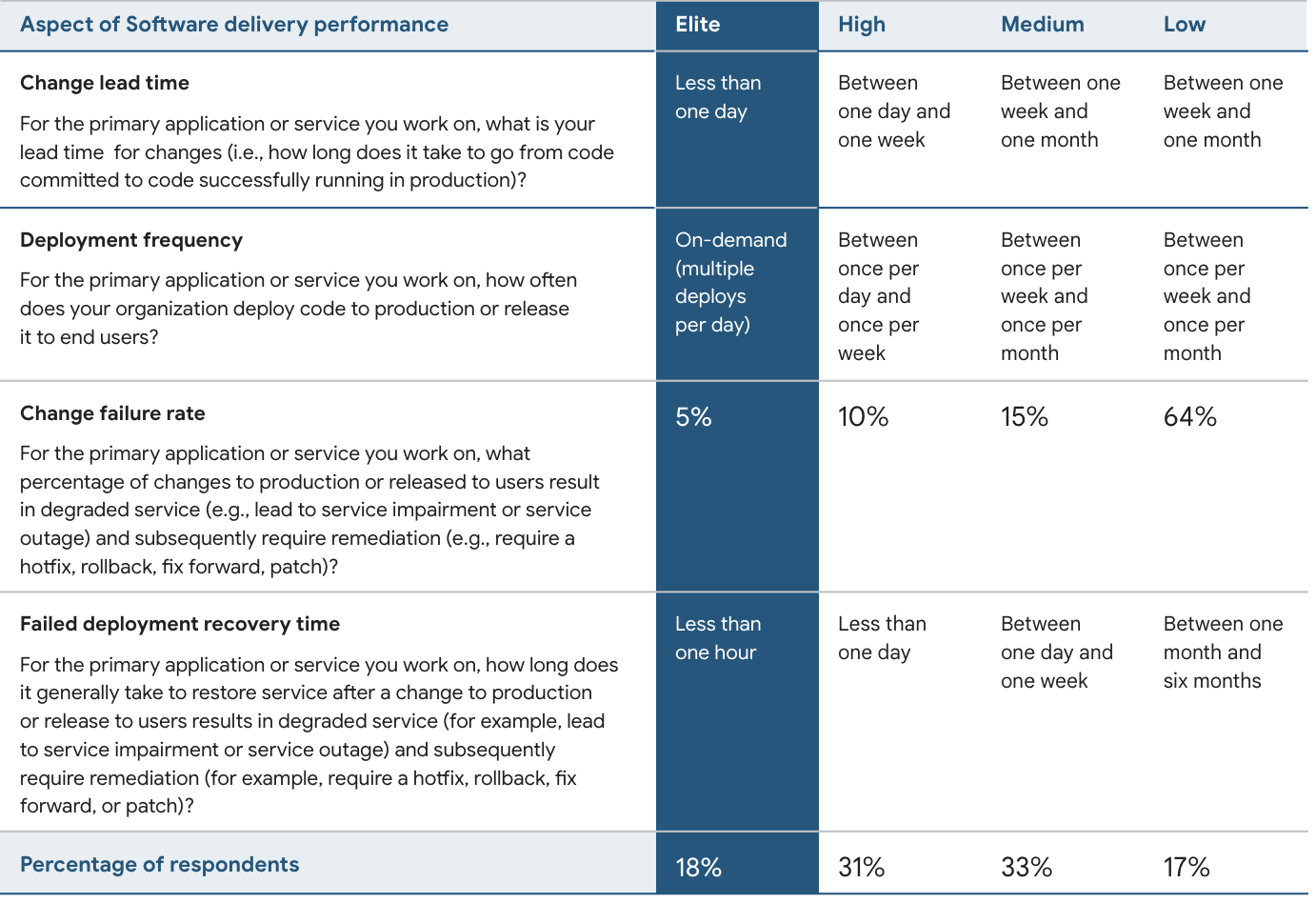
研发效能及 devops 领域最具影响力的调查机构 dora(devops research and assessments)为 devops 成熟度设定了四个指标,其中前两个最重要的指标分别为 **change lead time(代码从提交到上线的时间)**和 deployment frequency(发布频率)。在 dora 2023 年的报告中,devops 精英级(elite)对这两项指标的要求分别为 **less than one day(小于一天)**和 on-demand(随时)。
为了提升这两个指标,可累坏了研发兄弟们:每次想要做 api 变更、代码删减之前都如临大敌,痛苦的向各方确认业务依赖,生怕有所遗漏;每次发布过程中的 on-call 也会时常碰到调用链不全、指标不够的痛苦。为了解决这些问题,以往你会被迫使用 apm,但迎来的现实却是插桩永远覆盖不全、agent 和 sdk 永远要升级,升级又要 on-call。久而久之你会进入被迫使用 apm 和讨厌 apm 的死循环。
deepflow 基于 ebpf 的零侵扰可观测性有望改变这一现状,显然我们的社区用户也发现了这点。但受限于 grafana 的关联分析能力,新上手的用户容易迷失在我们内置的大量 dashboard 之内。在过去几个月,我们收到了好几个社区用户的使用建议,于是便有了这个非常简洁的「开箱即用」 dashboard,让你在一键安装 deepflow 的五分钟之后,打开这个 dashboard 就能以上帝视角查看应用性能和稳定性隐患,也能让你在以后的每次变更之前轻松确认业务依赖,同样能让你在灰度升级过程中快速观测新版本的健康状况。而获得这些能力不需要修改任何一行代码,也不需要重启任何一个进程。
这个 dashboard 已经在腾讯蓝鲸、中国移动磐基等社区用户处有了很不错的实践,从 deepflow 首次安装时的 day 0 初体验,到每一次业务的上新、扩容、缩容,已经在 devops 的各个流程环节开始帮助开发兄弟们消除性能和稳定性上的隐患,避免了未来可能触发的故障,我们将会在后续文章中介绍他们的使用案例。
现在就开始尝试 ebpf 的零侵扰可观测性,相信你会距离精英级 devops 前进一大步!另一个好消息是 deepflow 6.4 已经支持了 redhat/centos 3.10 内核上的 ebpf 能力,enjoy!
04
什么是 deepflow
deepflow 是云杉网络开发的一款可观测性产品,旨在为复杂的云基础设施及云原生应用提供深度可观测性。deepflow 基于 ebpf 实现了应用性能指标、分布式追踪、持续性能剖析等观测信号的零侵扰(zero code)采集,并结合智能标签(smartencoding)技术实现了所有观测信号的全栈(full stack)关联和高效存取。使用 deepflow,可以让云原生应用自动具有深度可观测性,从而消除开发者不断插桩的沉重负担,并为 devops/sre 团队提供从代码到基础设施的监控及诊断能力。
github 地址:https://github.com/deepflowio/deepflow
访问 deepflow demo,体验零插桩、全覆盖、全关联的可观测性。




发表评论