elasticsearch 系列文章
2、elasticsearch7.6.1基本介绍、2种部署方式及验证、head插件安装、分词器安装及验证
3、elasticsearch7.6.1信息搜索示例(索引操作、数据操作-添加、删除、导入等、数据搜索及分页)
4、elasticsearch7.6.1 java api操作es(crud、两种分页方式、高亮显示)和elasticsearch sql详细示例
5、elasticsearch7.6.1 filebeat介绍及收集kafka日志到es示例
6、elasticsearch7.6.1、logstash、kibana介绍及综合示例(elk、grok插件)
7、elasticsearch7.6.1收集nginx日志及监测指标示例
8、elasticsearch7.6.1收集mysql慢查询日志及监控
9、elasticsearch7.6.1 es与hdfs相互转存数据-es-hadoop
文章目录
本文简单的介绍了es-hadoop组件功能使用,即通过es-hadoop实现相互数据写入示例。
本文依赖es环境、hadoop环境好用。
本文分为三部分,即es-hadoop介绍、es数据写入hadoop和hadoop数据写入es。
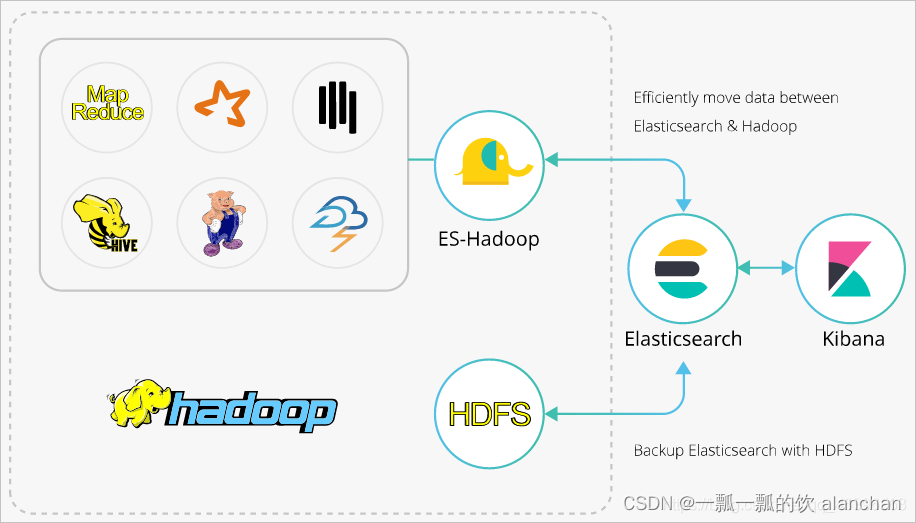
一、es-hadoop介绍
es-hadoop是elasticsearch推出的专门用于对接hadoop生态的工具,可以让数据在elasticsearch和hadoop之间双向移动,无缝衔接elasticsearch与hadoop服务,充分使用elasticsearch的快速搜索及hadoop批处理能力,实现交互式数据处理。
本文介绍如何通过es-hadoop实现hadoop的hive服务读写elasticsearch数据。
hadoop生态的优势是处理大规模数据集,但是其缺点也很明显,就是当用于交互式分析时,查询时延会比较长。而elasticsearch擅长于交互式分析,对于很多查询类型,特别是对于ad-hoc查询(即席查询),可以达到秒级。es-hadoop的推出提供了一种组合两者优势的可能性。使用es-hadoop,您只需要对代码进行很小的改动,即可快速处理存储在elasticsearch中的数据,并且能够享受到elasticsearch带来的加速效果。
es-hadoop的原理是将elasticsearch作为mr、spark或hive等数据处理引擎的数据源,在计算存储分离的架构中扮演存储的角色。这和 mr、spark或hive的数据源并无差异,但相对于这些数据源,elasticsearch具有更快的数据选择过滤能力。这种能力正是分析引擎最为关键的能力之一。
二、es写入hdfs
假设es中已经存储具体索引数据,下面仅仅是将es的数据读取并存入hdfs中。

1、txt文件格式写入
1)、pom.xml
<dependency>
<groupid>org.elasticsearch</groupid>
<artifactid>elasticsearch-hadoop</artifactid>
<version>7.6.1</version>
</dependency>
<dependency>
<groupid>org.elasticsearch.client</groupid>
<artifactid>transport</artifactid>
<version>7.6.1</version>
</dependency>
<dependency>
<groupid>org.apache.hadoop</groupid>
<artifactid>hadoop-common</artifactid>
<version>3.1.4</version>
</dependency>
<dependency>
<groupid>org.apache.hadoop</groupid>
<artifactid>hadoop-client</artifactid>
<version>3.1.4</version>
</dependency>
<dependency>
<groupid>org.apache.hadoop</groupid>
<artifactid>hadoop-hdfs</artifactid>
<version>3.1.4</version>
</dependency>
<dependency>
<groupid>jdk.tools</groupid>
<artifactid>jdk.tools</artifactid>
<version>1.8</version>
<scope>system</scope>
<systempath>${java_home}/lib/tools.jar</systempath>
</dependency>
<dependency>
<groupid>org.apache.hadoop</groupid>
<artifactid>hadoop-mapreduce-client-core</artifactid>
<version>3.1.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-httpclient/commons-httpclient -->
<dependency>
<groupid>commons-httpclient</groupid>
<artifactid>commons-httpclient</artifactid>
<version>3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.google.code.gson/gson -->
<dependency>
<groupid>com.google.code.gson</groupid>
<artifactid>gson</artifactid>
<version>2.10.1</version>
</dependency>
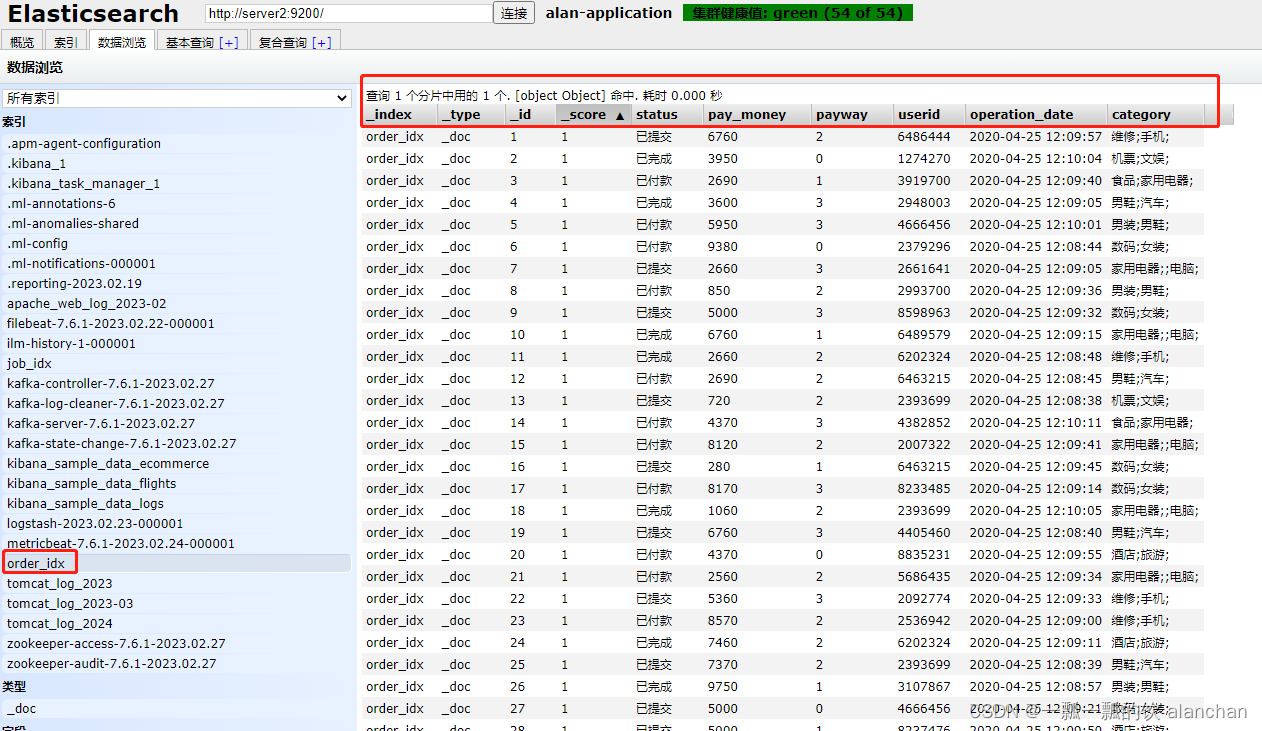
2)、示例1:order_idx
将es中的order_idx索引数据存储至hdfs中,其中hdfs是ha。hdfs中是以txt形式存储的,其中数据用逗号隔离
- 其数据结构
key 5000,value {status=已付款, pay_money=3820.0, payway=3, userid=4405460,operation_date=2020-04-25 12:09:51, category=维修;手机;}
- 实现
import java.io.ioexception;
import java.util.iterator;
import java.util.map;
import org.apache.hadoop.conf.configuration;
import org.apache.hadoop.conf.configured;
import org.apache.hadoop.fs.path;
import org.apache.hadoop.io.nullwritable;
import org.apache.hadoop.io.text;
import org.apache.hadoop.mapreduce.job;
import org.apache.hadoop.mapreduce.mapper;
import org.apache.hadoop.mapreduce.lib.output.fileoutputformat;
import org.apache.hadoop.util.tool;
import org.apache.hadoop.util.toolrunner;
import org.elasticsearch.hadoop.mr.esinputformat;
import org.elasticsearch.hadoop.mr.linkedmapwritable;
import lombok.data;
import lombok.extern.slf4j.slf4j;
@slf4j
public class estohdfs extends configured implements tool {
private static string out = "/es-hadoop/test";
public static void main(string[] args) throws exception {
configuration conf = new configuration();
int status = toolrunner.run(conf, new estohdfs(), args);
system.exit(status);
}
static class estohdfsmapper extends mapper<text, linkedmapwritable, nullwritable, text> {
text outvalue = new text();
protected void map(text key, linkedmapwritable value, context context) throws ioexception, interruptedexception {
// log.info("key {} , value {}", key.tostring(), value);
order order = new order();
// order.setid(integer.parseint(key.tostring()));
iterator it = value.entryset().iterator();
order.setid(key.tostring());
string name = null;
string data = null;
while (it.hasnext()) {
map.entry entry = (map.entry) it.next();
name = entry.getkey().tostring();
data = entry.getvalue().tostring();
switch (name) {
case "userid":
order.setuserid(integer.parseint(data));
break;
case "operation_date":
order.setoperation_date(data);
break;
case "category":
order.setcategory(data);
break;
case "pay_money":
order.setpay_money(double.parsedouble(data));
break;
case "status":
order.setstatus(data);
break;
case "payway":
order.setpayway(data);
break;
}
}
//log.info("order={}", order);
outvalue.set(order.tostring());
context.write(nullwritable.get(), outvalue);
}
}
@data
static class order {
// key 5000 value {status=已付款, pay_money=3820.0, payway=3, userid=4405460, operation_date=2020-04-25 12:09:51, category=维修;手机;}
private string id;
private int userid;
private string operation_date;
private string category;
private double pay_money;
private string status;
private string payway;
public string tostring() {
return new stringbuilder(id).append(",").append(userid).append(",").append(operation_date).append(",").append(category).append(",").append(pay_money).append(",")
.append(status).append(",").append(payway).tostring();
}
}
@override
public int run(string[] args) throws exception {
configuration conf = getconf();
conf.set("fs.defaultfs", "hdfs://hadoophacluster");
conf.set("dfs.nameservices", "hadoophacluster");
conf.set("dfs.ha.namenodes.hadoophacluster", "nn1,nn2");
conf.set("dfs.namenode.rpc-address.hadoophacluster.nn1", "server1:8020");
conf.set("dfs.namenode.rpc-address.hadoophacluster.nn2", "server2:8020");
conf.set("dfs.client.failover.proxy.provider.hadoophacluster", "org.apache.hadoop.hdfs.server.namenode.ha.configuredfailoverproxyprovider");
system.setproperty("hadoop_user_name", "alanchan");
conf.setboolean("mapred.map.tasks.speculative.execution", false);
conf.setboolean("mapred.reduce.tasks.speculative.execution", false);
conf.set("es.nodes", "server1:9200,server2:9200,server3:9200");
// elaticsearch 索引名称
conf.set("es.resource", "order_idx");
// 查询索引中的所有数据,也可以加条件
conf.set("es.query", "{ \"query\": {\"match_all\": { }}}");
job job = job.getinstance(conf, estohdfs.class.getname());
// 设置作业驱动类
job.setjarbyclass(estohdfs.class);
// 设置es的输入类型
job.setinputformatclass(esinputformat.class);
job.setmapperclass(estohdfsmapper.class);
job.setmapoutputkeyclass(nullwritable.class);
job.setmapoutputvalueclass(text.class);
fileoutputformat.setoutputpath(job, new path(out));
job.setnumreducetasks(0);
return job.waitforcompletion(true) ? 0 : 1;
}
}
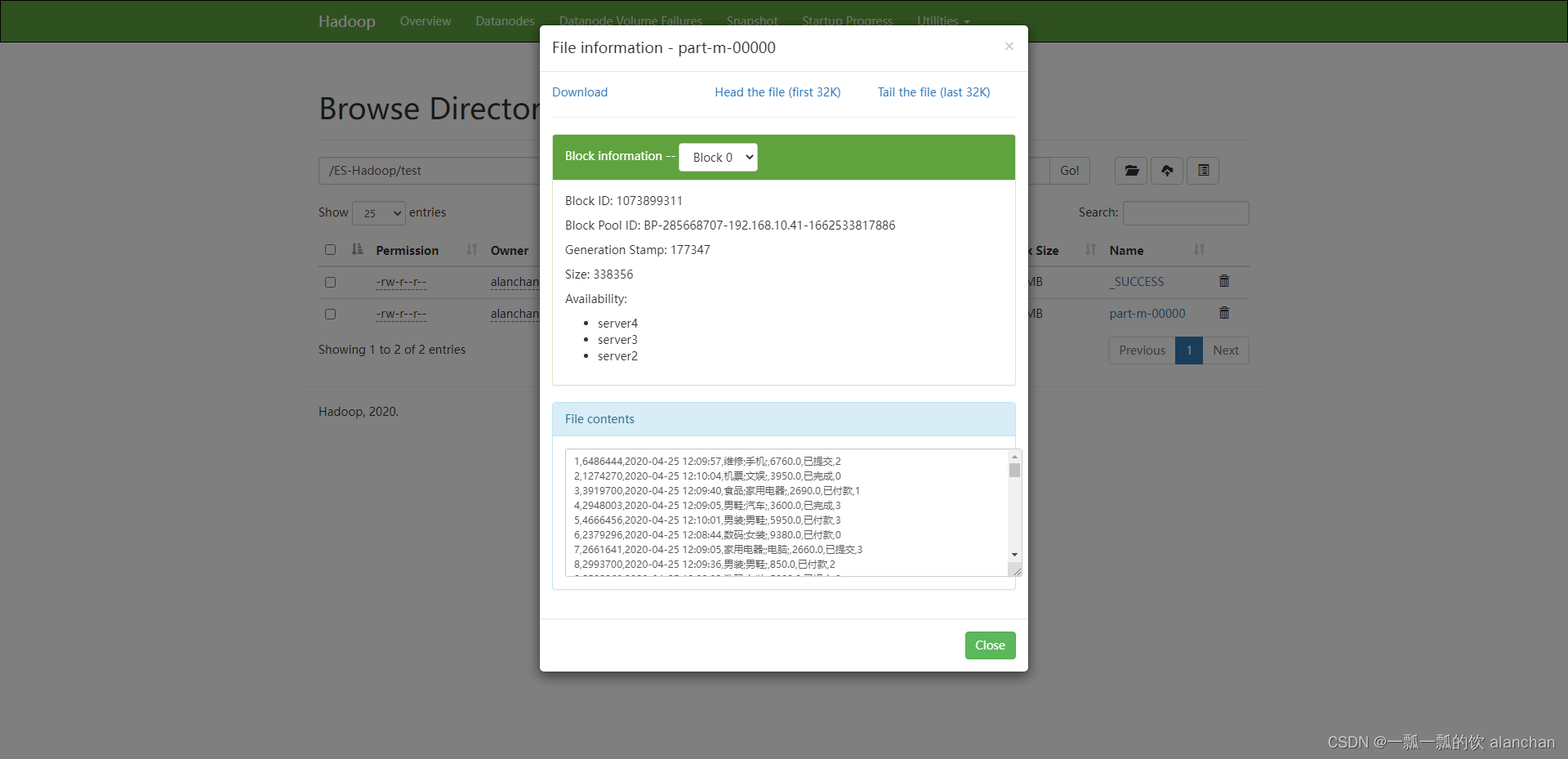
- 验证
结果如下图
3)、示例2:tomcat_log_2023-03
将es中的tomcat_log_2023-03索引数据存储至hdfs中,其中hdfs是ha。hdfs中是以txt形式存储的,其中数据用逗号隔离
- 其数据结构
key uzm_44ybh2rq2w9r5vqk , value {message=2023-03-15 13:30:00.001 [schedulerjoballtask_worker-1] info c.o.d.s.t.quartztask.executealltasklist-{37} - 生成消息记录任务停止执行结束*******, tags=[_dateparsefailure], class=c.o.d.s.t.quartztask.executealltasklist-{37}, level=info, date=2023-03-15 13:30:00.001, thread=schedulerjoballtask_worker-1, fields={source=catalina}, @timestamp=2023-03-15t05:30:06.812z, log={file={path=/opt/apache-tomcat-9.0.43/logs/catalina.out}, offset=76165371}, info=- 生成消息记录任务停止执行结束*******}
- 实现
import java.io.ioexception;
import java.util.iterator;
import java.util.map;
import org.apache.hadoop.conf.configuration;
import org.apache.hadoop.conf.configured;
import org.apache.hadoop.fs.path;
import org.apache.hadoop.io.nullwritable;
import org.apache.hadoop.io.text;
import org.apache.hadoop.mapreduce.job;
import org.apache.hadoop.mapreduce.mapper;
import org.apache.hadoop.mapreduce.lib.output.fileoutputformat;
import org.apache.hadoop.util.tool;
import org.apache.hadoop.util.toolrunner;
import org.elasticsearch.hadoop.mr.esinputformat;
import org.elasticsearch.hadoop.mr.linkedmapwritable;
import lombok.data;
import lombok.extern.slf4j.slf4j;
@slf4j
public class estohdfs2 extends configured implements tool {
private static string out = "/es-hadoop/tomcatlog";
static class estohdfs2mapper extends mapper<text, linkedmapwritable, nullwritable, text> {
text outvalue = new text();
protected void map(text key, linkedmapwritable value, context context) throws ioexception, interruptedexception {
// log.info("key {} , value {}", key.tostring(), value);
tomcatlog tlog = new tomcatlog();
iterator it = value.entryset().iterator();
string name = null;
string data = null;
while (it.hasnext()) {
map.entry entry = (map.entry) it.next();
name = entry.getkey().tostring();
data = entry.getvalue().tostring();
switch (name) {
case "date":
tlog.setdate(data.replace('/', '-'));
break;
case "thread":
tlog.setthread(data);
break;
case "level":
tlog.setloglevel(data);
break;
case "class":
tlog.setclazz(data);
break;
case "info":
tlog.setlogmsg(data);
break;
}
}
outvalue.set(tlog.tostring());
context.write(nullwritable.get(), outvalue);
}
}
@data
static class tomcatlog {
private string date;
private string thread;
private string loglevel;
private string clazz;
private string logmsg;
public string tostring() {
return new stringbuilder(date).append(",").append(thread).append(",").append(loglevel).append(",").append(clazz).append(",").append(logmsg).tostring();
}
}
public static void main(string[] args) throws exception {
configuration conf = new configuration();
int status = toolrunner.run(conf, new estohdfs2(), args);
system.exit(status);
}
@override
public int run(string[] args) throws exception {
configuration conf = getconf();
conf.set("fs.defaultfs", "hdfs://hadoophacluster");
conf.set("dfs.nameservices", "hadoophacluster");
conf.set("dfs.ha.namenodes.hadoophacluster", "nn1,nn2");
conf.set("dfs.namenode.rpc-address.hadoophacluster.nn1", "server1:8020");
conf.set("dfs.namenode.rpc-address.hadoophacluster.nn2", "server2:8020");
conf.set("dfs.client.failover.proxy.provider.hadoophacluster", "org.apache.hadoop.hdfs.server.namenode.ha.configuredfailoverproxyprovider");
system.setproperty("hadoop_user_name", "alanchan");
conf.setboolean("mapred.map.tasks.speculative.execution", false);
conf.setboolean("mapred.reduce.tasks.speculative.execution", false);
conf.set("es.nodes", "server1:9200,server2:9200,server3:9200");
// elaticsearch 索引名称
conf.set("es.resource", "tomcat_log_2023-03");
conf.set("es.query", "{\"query\":{\"bool\":{\"must\":[{\"match_all\":{}}],\"must_not\":[],\"should\":[]}},\"from\":0,\"size\":10,\"sort\":[],\"aggs\":{}}");
job job = job.getinstance(conf, estohdfs2.class.getname());
// 设置作业驱动类
job.setjarbyclass(estohdfs2.class);
job.setinputformatclass(esinputformat.class);
job.setmapperclass(estohdfs2mapper.class);
job.setmapoutputkeyclass(nullwritable.class);
job.setmapoutputvalueclass(text.class);
fileoutputformat.setoutputpath(job, new path(out));
job.setnumreducetasks(0);
return job.waitforcompletion(true) ? 0 : 1;
}
}
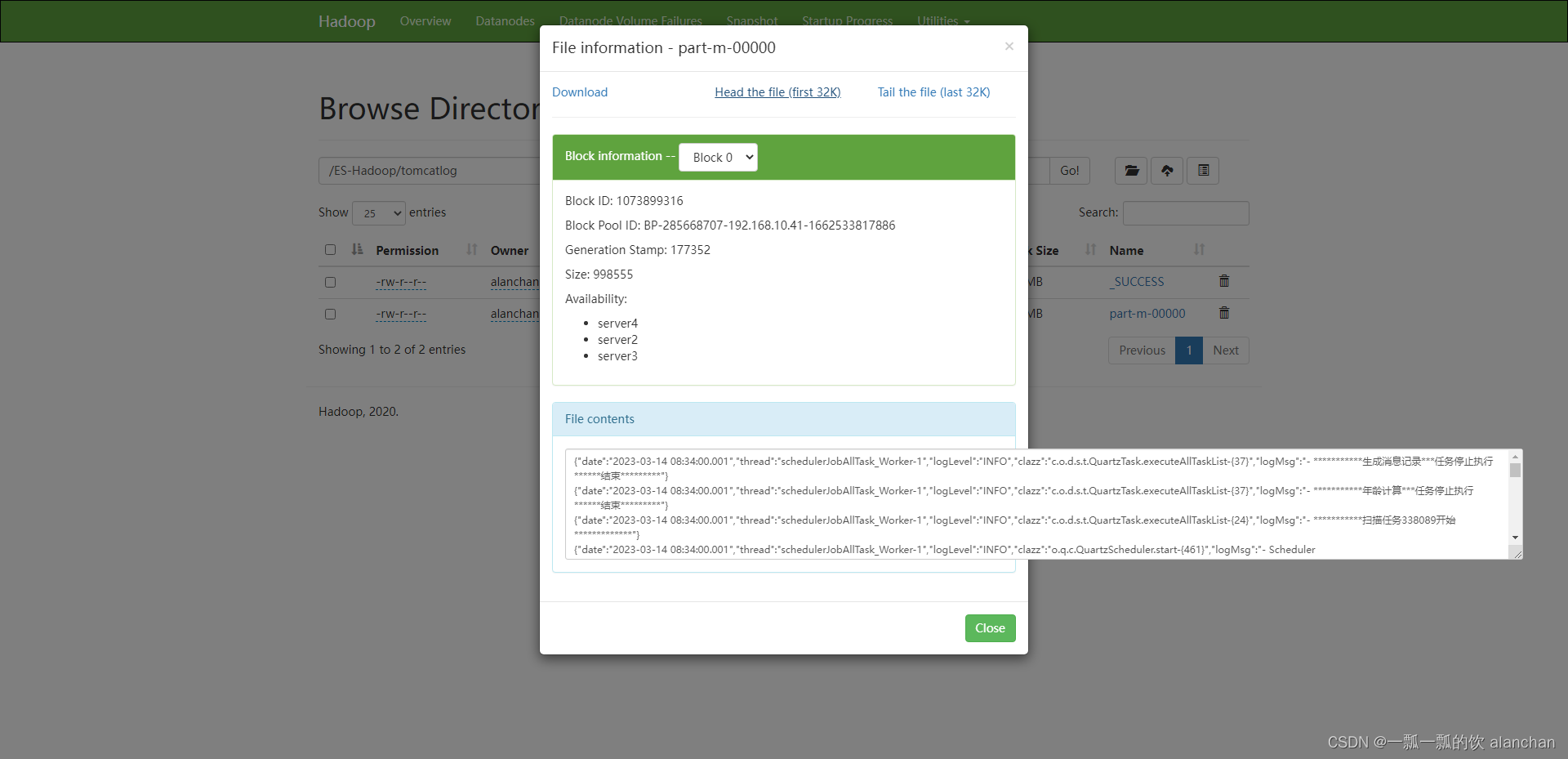
- 验证
2、json文件格式写入
将es中的tomcat_log_2023-03索引数据存储至hdfs中,其中hdfs是ha。hdfs中是以json形式存储的
- 其数据结构
key uzm_44ybh2rq2w9r5vqk , value {message=2023-03-15 13:30:00.001 [schedulerjoballtask_worker-1] info c.o.d.s.t.quartztask.executealltasklist-{37} - 生成消息记录任务停止执行结束*******, tags=[_dateparsefailure], class=c.o.d.s.t.quartztask.executealltasklist-{37}, level=info, date=2023-03-15 13:30:00.001, thread=schedulerjoballtask_worker-1, fields={source=catalina}, @timestamp=2023-03-15t05:30:06.812z, log={file={path=/opt/apache-tomcat-9.0.43/logs/catalina.out}, offset=76165371}, info=- 生成消息记录任务停止执行结束*******}
- 实现
import java.io.ioexception;
import java.util.iterator;
import java.util.map;
import org.apache.hadoop.conf.configuration;
import org.apache.hadoop.conf.configured;
import org.apache.hadoop.fs.path;
import org.apache.hadoop.io.nullwritable;
import org.apache.hadoop.io.text;
import org.apache.hadoop.mapreduce.job;
import org.apache.hadoop.mapreduce.mapper;
import org.apache.hadoop.mapreduce.lib.output.fileoutputformat;
import org.apache.hadoop.util.tool;
import org.apache.hadoop.util.toolrunner;
import org.elasticsearch.hadoop.mr.esinputformat;
import org.elasticsearch.hadoop.mr.linkedmapwritable;
import com.google.gson.gson;
import lombok.data;
public class estohdfsbyjson extends configured implements tool {
private static string out = "/es-hadoop/tomcatlog_json";
public static void main(string[] args) throws exception {
configuration conf = new configuration();
int status = toolrunner.run(conf, new estohdfsbyjson(), args);
system.exit(status);
}
@override
public int run(string[] args) throws exception {
configuration conf = getconf();
conf.set("fs.defaultfs", "hdfs://hadoophacluster");
conf.set("dfs.nameservices", "hadoophacluster");
conf.set("dfs.ha.namenodes.hadoophacluster", "nn1,nn2");
conf.set("dfs.namenode.rpc-address.hadoophacluster.nn1", "server1:8020");
conf.set("dfs.namenode.rpc-address.hadoophacluster.nn2", "server2:8020");
conf.set("dfs.client.failover.proxy.provider.hadoophacluster", "org.apache.hadoop.hdfs.server.namenode.ha.configuredfailoverproxyprovider");
system.setproperty("hadoop_user_name", "alanchan");
conf.setboolean("mapred.map.tasks.speculative.execution", false);
conf.setboolean("mapred.reduce.tasks.speculative.execution", false);
conf.set("es.nodes", "server1:9200,server2:9200,server3:9200");
// elaticsearch 索引名称
conf.set("es.resource", "tomcat_log_2023-03");
conf.set("es.query", "{\"query\":{\"bool\":{\"must\":[{\"match_all\":{}}],\"must_not\":[],\"should\":[]}},\"from\":0,\"size\":10,\"sort\":[],\"aggs\":{}}");
job job = job.getinstance(conf, estohdfs2.class.getname());
// 设置作业驱动类
job.setjarbyclass(estohdfsbyjson.class);
job.setinputformatclass(esinputformat.class);
job.setmapperclass(estohdfsbyjsonmapper.class);
job.setmapoutputkeyclass(nullwritable.class);
job.setmapoutputvalueclass(text.class);
fileoutputformat.setoutputpath(job, new path(out));
job.setnumreducetasks(0);
return job.waitforcompletion(true) ? 0 : 1;
}
static class estohdfsbyjsonmapper extends mapper<text, linkedmapwritable, nullwritable, text> {
text outvalue = new text();
private gson gson = new gson();
protected void map(text key, linkedmapwritable value, context context) throws ioexception, interruptedexception {
// log.info("key {} , value {}", key.tostring(), value);
tomcatlog tlog = new tomcatlog();
// tlog.setid(key.tostring());
iterator it = value.entryset().iterator();
string name = null;
string data = null;
while (it.hasnext()) {
map.entry entry = (map.entry) it.next();
name = entry.getkey().tostring();
data = entry.getvalue().tostring();
switch (name) {
case "date":
tlog.setdate(data.replace('/', '-'));
break;
case "thread":
tlog.setthread(data);
break;
case "level":
tlog.setloglevel(data);
break;
case "class":
tlog.setclazz(data);
break;
case "info":
tlog.setlogmsg(data);
break;
}
}
outvalue.set(gson.tojson(tlog));
context.write(nullwritable.get(), outvalue);
}
}
@data
static class tomcatlog {
// private string id ;
private string date;
private string thread;
private string loglevel;
private string clazz;
private string logmsg;
}
}
- 验证
三、hdfs写入es
本示例以上述例子中存入hdfs的数据。经过测试,es只能将json的数据导入。
pom.xml参考上述例子
1、txt文件写入
先将数据转换成json后存入
import java.io.ioexception;
import org.apache.hadoop.conf.configuration;
import org.apache.hadoop.conf.configured;
import org.apache.hadoop.fs.path;
import org.apache.hadoop.io.longwritable;
import org.apache.hadoop.io.nullwritable;
import org.apache.hadoop.io.text;
import org.apache.hadoop.mapreduce.job;
import org.apache.hadoop.mapreduce.mapper;
import org.apache.hadoop.mapreduce.lib.input.fileinputformat;
import org.apache.hadoop.util.tool;
import org.apache.hadoop.util.toolrunner;
import org.elasticsearch.hadoop.mr.esoutputformat;
import com.google.gson.gson;
import lombok.data;
import lombok.extern.slf4j.slf4j;
@slf4j
public class hdfstxtdatatoes extends configured implements tool {
private static string out = "/es-hadoop/tomcatlog";
public static void main(string[] args) throws exception {
configuration conf = new configuration();
int status = toolrunner.run(conf, new hdfstxtdatatoes(), args);
system.exit(status);
}
@data
static class tomcatlog {
private string date;
private string thread;
private string loglevel;
private string clazz;
private string logmsg;
}
@override
public int run(string[] args) throws exception {
configuration conf = getconf();
conf.set("fs.defaultfs", "hdfs://hadoophacluster");
conf.set("dfs.nameservices", "hadoophacluster");
conf.set("dfs.ha.namenodes.hadoophacluster", "nn1,nn2");
conf.set("dfs.namenode.rpc-address.hadoophacluster.nn1", "server1:8020");
conf.set("dfs.namenode.rpc-address.hadoophacluster.nn2", "server2:8020");
conf.set("dfs.client.failover.proxy.provider.hadoophacluster", "org.apache.hadoop.hdfs.server.namenode.ha.configuredfailoverproxyprovider");
system.setproperty("hadoop_user_name", "alanchan");
conf.setboolean("mapred.map.tasks.speculative.execution", false);
conf.setboolean("mapred.reduce.tasks.speculative.execution", false);
conf.set("es.nodes", "server1:9200,server2:9200,server3:9200");
// elaticsearch 索引名称,可以不提前创建
conf.set("es.resource", "tomcat_log_2024");
// hadoop上的数据格式为json,可以直接导入
conf.set("es.input.json", "yes");
job job = job.getinstance(conf, hdfstxtdatatoes.class.getname());
// 设置作业驱动类
job.setjarbyclass(hdfstxtdatatoes.class);
// 设置esoutputformat
job.setoutputformatclass(esoutputformat.class);
job.setmapperclass(hdfstxtdatatoesmapper.class);
job.setmapoutputkeyclass(nullwritable.class);
job.setmapoutputvalueclass(text.class);
fileinputformat.setinputpaths(job, new path(out));
job.setnumreducetasks(0);
return job.waitforcompletion(true) ? 0 : 1;
}
static class hdfstxtdatatoesmapper extends mapper<longwritable, text, nullwritable, text> {
text outvalue = new text();
tomcatlog tlog = new tomcatlog();
gson gson = new gson();
protected void map(longwritable key, text value, context context) throws ioexception, interruptedexception {
log.info("key={},value={}", key, value);
// date:2023-03-13 17:33:00.001,
// thread:schedulerjoballtask_worker-1,
// loglevel:info,
// clazz:o.q.c.quartzscheduler.start-{461},
// logmsg:- scheduler defaultquartzscheduler_$_non_clustered started.
string[] lines = value.tostring().split(",");
tlog.setdate(lines[0]);
tlog.setthread(lines[1]);
tlog.setloglevel(lines[2]);
tlog.setclazz(lines[3]);
tlog.setlogmsg(lines[4]);
outvalue.set(gson.tojson(tlog));
context.write(nullwritable.get(), outvalue);
}
}
}
2、json文件写入
import java.io.ioexception;
import org.apache.hadoop.conf.configuration;
import org.apache.hadoop.conf.configured;
import org.apache.hadoop.fs.path;
import org.apache.hadoop.io.longwritable;
import org.apache.hadoop.io.nullwritable;
import org.apache.hadoop.io.text;
import org.apache.hadoop.mapreduce.job;
import org.apache.hadoop.mapreduce.mapper;
import org.apache.hadoop.mapreduce.lib.input.fileinputformat;
import org.apache.hadoop.util.tool;
import org.apache.hadoop.util.toolrunner;
import org.elasticsearch.hadoop.mr.esoutputformat;
import lombok.extern.slf4j.slf4j;
@slf4j
public class hdfsjsondatatoes extends configured implements tool {
private static string out = "/es-hadoop/tomcatlog_json";
public static void main(string[] args) throws exception {
configuration conf = new configuration();
int status = toolrunner.run(conf, new hdfsjsondatatoes(), args);
system.exit(status);
}
@override
public int run(string[] args) throws exception {
configuration conf = getconf();
conf.set("fs.defaultfs", "hdfs://hadoophacluster");
conf.set("dfs.nameservices", "hadoophacluster");
conf.set("dfs.ha.namenodes.hadoophacluster", "nn1,nn2");
conf.set("dfs.namenode.rpc-address.hadoophacluster.nn1", "server1:8020");
conf.set("dfs.namenode.rpc-address.hadoophacluster.nn2", "server2:8020");
conf.set("dfs.client.failover.proxy.provider.hadoophacluster", "org.apache.hadoop.hdfs.server.namenode.ha.configuredfailoverproxyprovider");
system.setproperty("hadoop_user_name", "alanchan");
conf.setboolean("mapred.map.tasks.speculative.execution", false);
conf.setboolean("mapred.reduce.tasks.speculative.execution", false);
conf.set("es.nodes", "server1:9200,server2:9200,server3:9200");
// elaticsearch 索引名称,可以不提前创建
conf.set("es.resource", "tomcat_log_2023");
//hadoop上的数据格式为json,可以直接导入
conf.set("es.input.json", "yes");
job job = job.getinstance(conf, hdfsjsondatatoes.class.getname());
// 设置作业驱动类
job.setjarbyclass(hdfsjsondatatoes.class);
job.setoutputformatclass(esoutputformat.class);
job.setmapperclass(hdfsjsondatatoesmapper.class);
job.setmapoutputkeyclass(nullwritable.class);
job.setmapoutputvalueclass(text.class);
fileinputformat.setinputpaths(job, new path(out));
job.setnumreducetasks(0);
return job.waitforcompletion(true) ? 0 : 1;
}
static class hdfsjsondatatoesmapper extends mapper<longwritable, text, nullwritable, text> {
protected void map(longwritable key, text value, context context) throws ioexception, interruptedexception {
log.info("key={},value={}",key,value);
context.write(nullwritable.get(), value);
}
}
}
以上,简单的介绍了es-hadoop组件功能使用,即通过es-hadoop实现相互数据写入示例。


发表评论