文章较长,附目录,此次安装是在vm虚拟环境下进行。文章第一节主要是介绍hbase,只需安装配置的朋友可以直接跳到文章第二节。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。
注:本次案例是在基于hadoop配置完成的情况下搭建的,需要的朋友可以查看我的这篇文章学习搭建
hadoop集群搭建 https://blog.csdn.net/qq_49513817/article/details/136525399?spm=1001.2014.3001.5501
https://blog.csdn.net/qq_49513817/article/details/136525399?spm=1001.2014.3001.5501
目录
一、hbase
什么是hbase
hbase官网介绍
apache hbase™ is the hadoop database, a distributed, scalable, big data store.
use apache hbase™ when you need random, realtime read/write access to your big data. this project's goal is the hosting of very large tables -- billions of rows x millions of columns -- atop clusters of commodity hardware. apache hbase is an open-source, distributed, versioned, non-relational database modeled after google's bigtable: a distributed storage system for structured data by chang et al. just as bigtable leverages the distributed data storage provided by the google file system, apache hbase provides bigtable-like capabilities on top of hadoop and hdfs.
阿帕奇hbase™ 是 hadoop 数据库,是一种分布式、可扩展的大数据存储。当您需要对大数据进行随机、实时的读/写访问时,请使用 apache hbase™。 这个项目的目标是在商用硬件集群上托管非常大的表 - 数十亿行,x数百万列。 apache hbase 是一个开源的、分布式的、版本控制的、非关系型数据库,以 chang 等人的 google bigtable: a distributed storage system for structured data 为模型。 正如 bigtable 利用 google 文件系统提供的分布式数据存储一样,apache hbase 在 hadoop 和 hdfs 之上提供了类似 bigtable 的功能。
hbase的历史
hbase的历史可以追溯到2006年,当时google发布了论文《bigtable: a distributed storage system for structured data》。这篇论文描述了一个分布式、高可靠性的结构化数据存储系统bigtable,为hbase的诞生奠定了理论基础。
随后,在2007年,hbase项目作为hadoop的一个子项目开始启动。它的最初开发人员是michael stack和jim kellerman,他们基于google的bigtable论文思想,实现了hbase的原型。同年4月,hbase作为一个模块被提交到hadoop的代码库中。
在hbase的早期阶段,它主要解决了hadoop中随机读效率低下的问题,为大数据存储和处理提供了有效的解决方案。然而,由于hbase依赖于hdfs和mapreduce,因此在处理小数据时并不太适合。
随着时间的推移,hbase逐渐受到越来越多公司的关注和使用。2008年,hbase成为hadoop的子项目,这为hbase社区的发展带来了巨大的便利。到了2010年,hbase晋升为apache的顶级项目,这表明了它在开源社区中的重要性和认可度。
同年,facebook开始在其消息平台中使用hbase,这是hbase大规模商业化使用的开始。随后,越来越多的公司开始采用hbase来支持其业务,包括阿里巴巴等大型互联网公司。
如今,hbase仍然是apache社区最活跃的项目之一,并持续不断地发展和完善。它已经成为了大数据领域中的一个重要工具,被广泛应用于各种业务场景中。随着技术的不断进步和应用场景的不断拓展,hbase的未来也将更加广阔和光明。所以,hbase的学习,对一个成熟的大数据开发者来说,是十分必要的。
hbase的特点
- 面向列存储:hbase的数据是按照列族进行存储的,这种存储方式使得查询只需要少数几个字段时,能大大减少读取的数据量,从而提高查询效率。同时,这种列式存储结构也使其具有更好的扩展性和灵活性。
- 多版本数据:hbase中的每个列都可以存储多个版本的数据,每个版本的数据都有一个对应的时间戳,这使得数据的管理和恢复更加灵活和方便。
- 稀疏性:在hbase中,如果某个列的数据为空,那么它不会占用任何存储空间,这种稀疏性的特性使得hbase可以设计得非常灵活,适应各种数据需求。
- 高可靠性:hbase采用了wal(write-ahead logging)机制和replication机制,保证了数据在写入时不会因集群异常而导致数据丢失,同时在集群出现严重问题时,数据也不会发生丢失或损坏。此外,其底层的hdfs也有备份机制,进一步增强了数据的可靠性。
- 高性能:hbase底层使用了lsm(log-structured merge-tree)数据结构,且rowkey有序排列,这些设计使得hbase具有非常高的写入性能。同时,它也支持高并发的读写请求,满足了大规模数据处理的需求。
- 灵活的数据模型:hbase的数据模型是基于列族的,每个列族可以包含多个列,这种模型可以灵活地适应不同的数据结构和查询需求。
- 分布式存储与扩展性:hbase是构建在hadoop分布式文件系统(hdfs)之上的,因此它具有很好的分布式存储和扩展性。当数据量增大时,可以通过增加节点来动态扩展存储容量和处理能力。
- 强一致性:hbase保证数据的强一致性,即数据写入后会立即更新所有节点的副本数据,确保读取到的数据是最新的。
hbase的工作原理
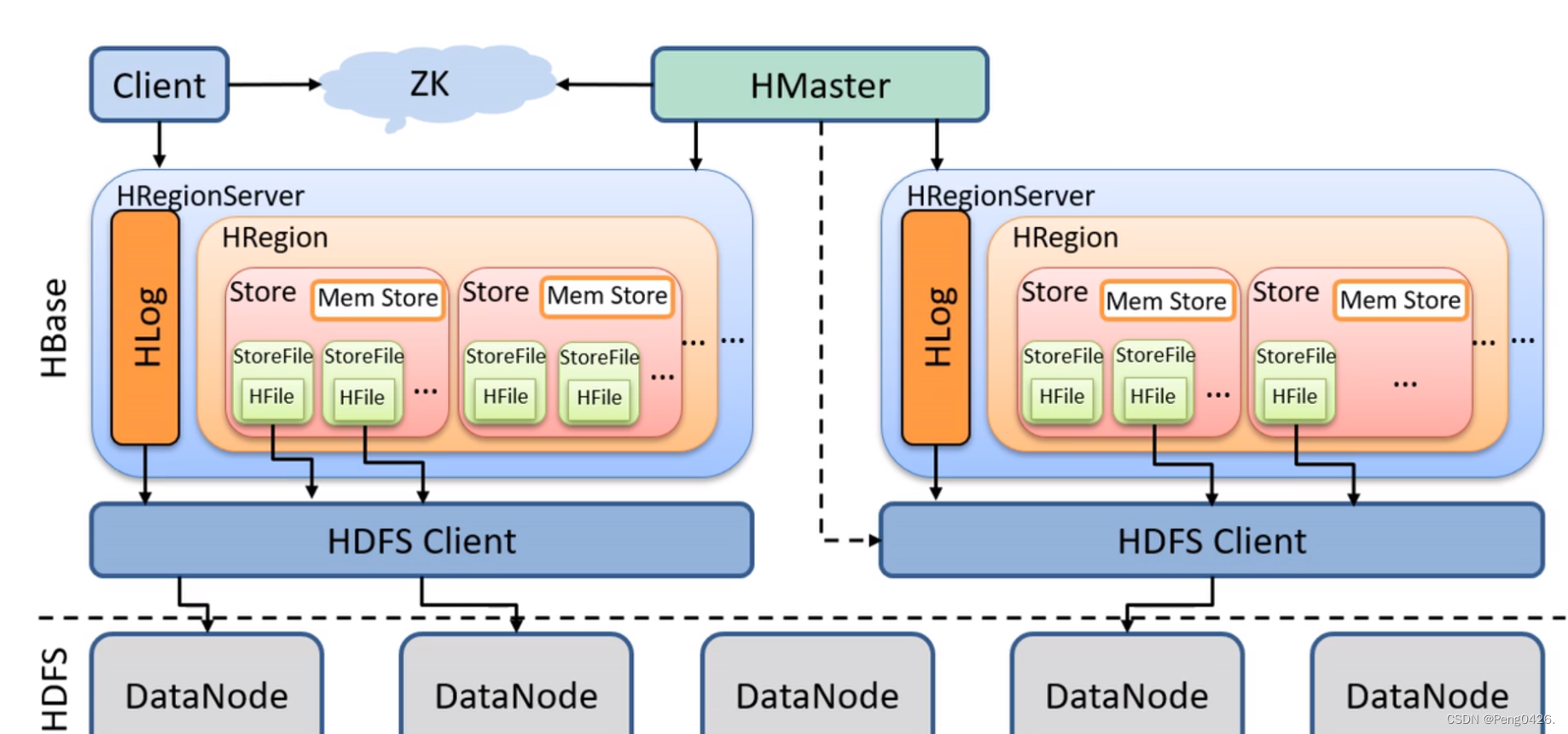
hbase工作流程图
- 客户端向hbase发起请求:
- 当客户端需要向hbase中写入数据时,它会首先与zookeeper进行通信。zookeeper是hbase集群的协调者,负责维护集群的元数据信息和提供分布式协调服务。
- 客户端通过zookeeper获取到meta-region-server节点的信息,进而找到对应的hbase元数据表(hbase:meta)的位置。
- 获取元数据并定位数据位置:
- 客户端根据读请求的namespace:table/rowkey信息,从hbase:meta表中查询到目标数据位于哪个region server中的哪个region中。
- 同时,客户端会将查询到的region信息和meta表的位置信息缓存在本地的meta cache中,以便下次访问时能够直接获取,提高访问效率。
- 与目标region server通信:
- 客户端与目标region server建立通信连接,发送数据读写请求。
- 数据读写操作:
- 对于写操作,region server将数据首先写入其内存中的memstore。当memstore中的数据达到一定大小时,会将其刷写到磁盘上的storefile(hfile)中。此外,为了确保数据的可靠性,写操作还会先将数据写入wal(write-ahead log),以防止数据丢失。
- 对于读操作,region server会首先在memstore中查找数据,如果找不到,则会在storefile中进行查找。同时,hbase还提供了缓存机制(如block cache),用于缓存经常访问的数据块,以加快数据读取速度。
- 数据合并与返回:
- 如果在多个位置(如memstore和多个storefile)找到了同一条数据的不同版本或类型,hbase会将这些数据进行合并。
- 合并后的最终结果会返回给客户端。
- 数据持久化与恢复:
- 为了防止数据丢失,hbase会将wal中的数据异步地写入hdfs(hadoop distributed file system)中进行持久化存储。当数据成功写入hdfs后,wal中的相应记录会被清除
- region:hbase表中的数据按照行键的字典顺序进行排序,并切分为多个region。最初只有一个region,但随着数据量的增加,region会进行分裂,形成更多的region。每个region是hbase表分布式存储和负载均衡的基本单元,可能分布在多个hregionserver上。
- store:每个region由多个store组成,store的数量由表的列族数量决定。一个列族对应一个store,这样设计是因为列族中的数据往往具有相似的特性,便于进行压缩和节省存储空间。
- memstore与storefile:每个store包含一个memstore和零个或多个storefile。memstore用于保存内存中的数据,当数据达到一定大小时,会刷写到磁盘上的storefile中。storefile是hbase中数据的物理存储形式,它以hfile格式存储在hdfs上。
- wal:hbase的写入操作采用写前日志的机制,即先将数据写入wal,然后再写入memstore。这确保了数据的可靠性和恢复能力。
- get操作:根据行键进行精确的数据读取。
- scan操作:可以扫描指定范围内的数据,提供灵活的数据查询能力。
二、hbase的下载与配置
1.hbase的下载
在下载之前要注意,hbase与hbase的版本必须要对应,不然可能出现功能异常或者功能不全的现象,下面是版本对应图。
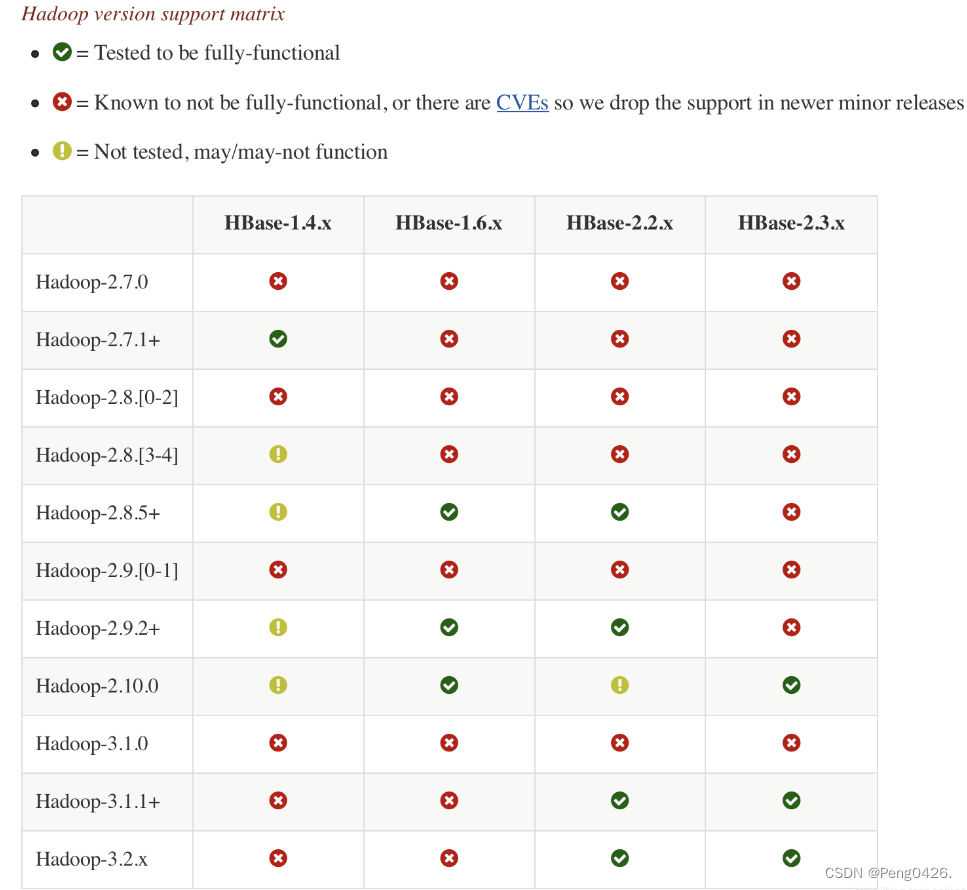
hbase与hadoop版本对应图
hbase官网下载地址https://hbase.apache.org/downloads.html
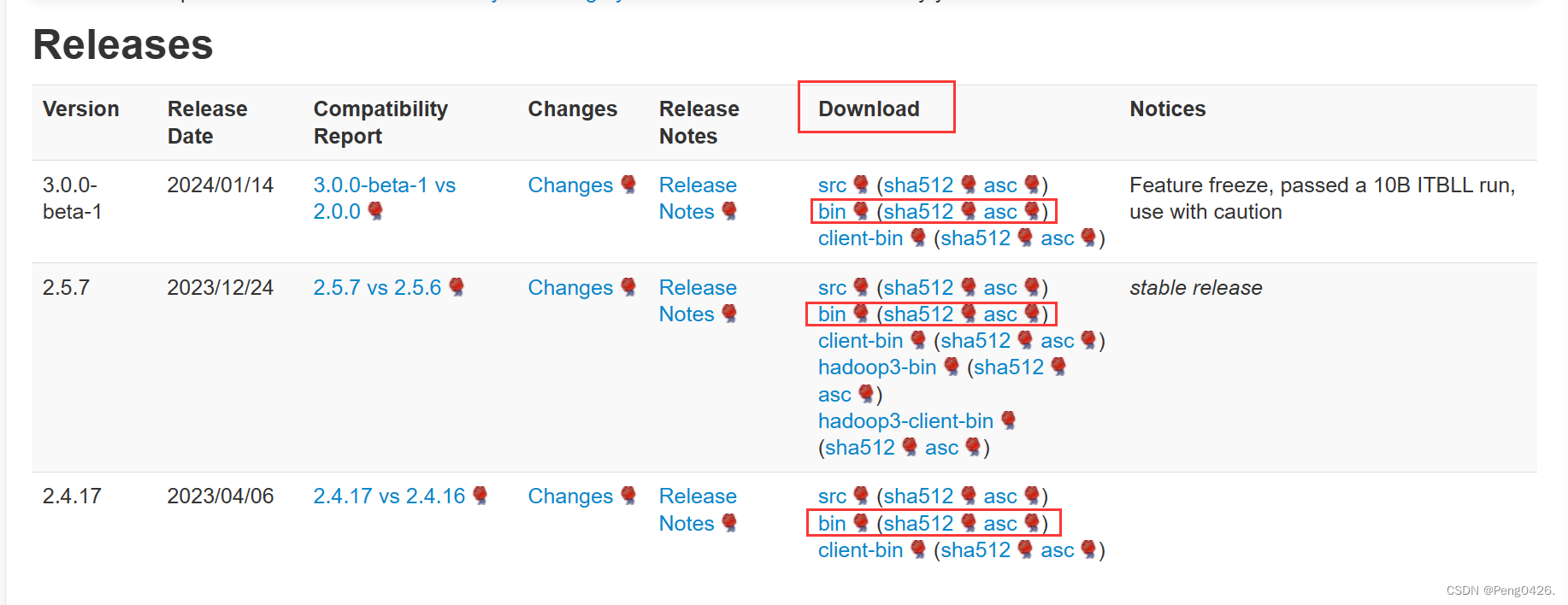
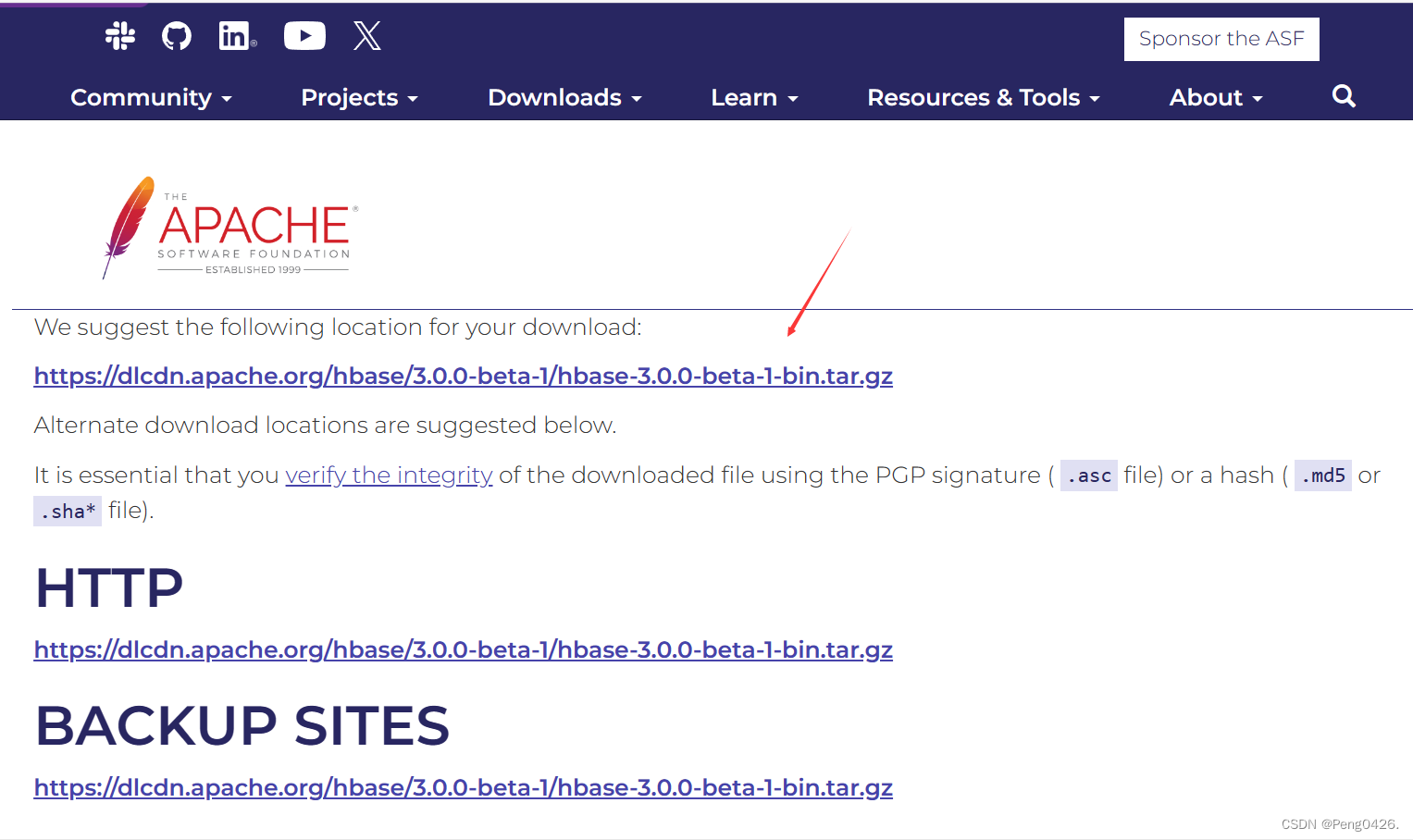
hbase下载
选择自己需要的版本跟着图片下载即可
2.hbase的配置
我使用的主机、从机名称分别为bigdata01,bigdata02,bigdata03,hadoop配置版本与上篇文章一致,hbase版本为1.2.6,解压到opt下,如有主机、从机名称,ip,版本,路径与我不一致的,更改成自己的即可。
#在bigdata01下:
tar zxvf /root/downloads/hbase-1.2.6-bin.tar.gz -c/opt/
vim /etc/profile
export hbase_home=/opt/hbase-1.2.6
export path=$path:$hbase_home/bin
source /etc/profile
vim /opt/hbase-1.2.6/conf/hbase-env.sh
export java_home=/opt/jdk1.8.0_171(27行)
export hbase_manages_zk=false(128)此行下面添加:
# configure permsize. only needed in jdk7. you can safely remove it for jdk8+
export hbase_master_opts="$hbase_master_opts -xx:permsize=128m -xx:maxpermsize=128m -xx:reservedcodecachesize=256m"
export hbase_regionserver_opts="$hbase_regionserver_opts -xx:permsize=128m -xx:maxpermsize=128m -xx:reservedcodecachesize=256m"
vim /opt/hbase-1.2.6/conf/hbase-site.xml
<property>
<name>hbase.rootdir</name> <!-- hbase存放数据目录 ,默认值${hbase.tmp.dir}/hbase-->
<!-- 端口要和hadoop的fs.defaultfs端口一致-->
<!--ns1为hdfs-site.xml中dfs.nameservices的值。或与hadoop的fs.defaultfs一致-->
<value>hdfs://ns1/data/hbase_db</value>
</property>
<property>
<name>hbase.cluster.distributed</name> <!-- 是否分布式部署 -->
<value>true</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name> <!-- list of zookooper -->
<value>bigdata01,bigdata02,bigdata03</value>
</property>
<property>
<name>hbase.zookeeper.property.datadir</name> <!--zookooper配置、日志等的存储位置 -->
<value>/opt/zookeeper-3.4.12</value>
</property>
<property>
<name>hbase.zookeeper.property.clientport</name>
<value>2181</value>
</property>
vim /opt/hbase-1.2.6/conf/regionservers
bigdata01
bigdata02
bigdata03
vim /opt/hbase-1.2.6/conf/backup-masters
bigdata02
scp /opt/hadoopha/etc/hadoop/hdfs-site.xml /opt/hbase-1.2.6/conf/
scp -r /etc/profile @bigdata02:/etc/
scp -r /etc/profile @bigdata03:/etc/
scp -r /opt/hbase-1.2.6 root@bigdata02:/opt/
scp -r /opt/hbase-1.2.6 root@bigdata03:/opt/
两节点下
source /etc/profile
#依次启动zkserver.sh start(检查防火墙)
systemctl stop firewalld
01下:
start-dfs.sh
start-yarn.sh
start-hbase.sh
jps
03下:
mr-jobhistory-daemon.sh start historyserver
jps
bigdata01和bigdata02节点上增加了 hmaster、hregionserver
bigdata03节点上只增加了 hregionserver 即配置成功
#浏览器打开查看
http://192.168.67.128:16010
http://192.168.67.128:16030
#根据实际ip地址查看
三、hbase的用法
hbase的shell命令
| 启动shell | hbase shell |
| 查看hbase运行状态 | status |
| 查看版本 | version |
| 获得帮助 | help |
| 退出shell | exit |
| 创建表 | create 表名,列族名, 列族名 |
| 显示所有数据表 | list |
| 查看表的结构 | describe '表名' |
| 修改表结构(先将表设为不可用) | disable '表名' |
| 设表为启用状态 | enable '表名' |
| 删除表 | 先disable '表名‘ 后drop'表名' |
| 读出数据(全表扫描) | scan'表名' |
| 查询表有多少行 | count'表名' |
| 将整表清空 | truncate'表名' |
| 插入数据 | put '表名', '行键值', '列族:列名', '插入的数据' |
| 查询数据 | get '表名', '数据' |
运行hbase shell脚本
可以把操作命令写入到文件中,如testhbasedata.sh,再在linux shell命令下执行:
$ hbase shell testhbasedata.sh
如testhbasedata.sh文件中写入如下内容:
put 'student','lisi','info:height','170'
put 'student','lisi','info:birthday','1991-06-20'
put 'student','lisi','info:weight','65'
put 'student','lisi','address:province','hubei'
put 'student','lisi','address:city','wuhan'
put 'student','lisi','address:university','wuhan university'
运行脚本
hbase(main):001:0> !cat testhbasedata.sh | hbase shell
拓展、hbase和cassandra的区别
hbase和cassandra都有适用于存储大量数据,并具有高可用性、高扩展性和容错性的特点,很多人分不清它们的区别,以下就是我总结出它们间的区别。
hbase和cassandra是两个不同的分布式存储系统,它们在设计、架构、功能和使用场景上存在一些显著的区别。
首先,从设计角度来看,hbase是一个开源的分布式存储系统,可以看作是google的bigtable的开源实现。而cassandra则可以看作是amazon dynamo的开源实现,并且结合了google bigtable的columnfamily的数据模型。这意味着cassandra在设计上融合了多个系统的优点,具有更强的灵活性和可靠性。
其次,从架构层面来看,hbase的内部结构更为复杂,包含了hadoop、hdfs和hbase等多个组件,每个组件都有若干个角色。相比之下,cassandra的架构更为简单,它不依赖任何已有的框架,每个节点都是对等的。这种架构使得cassandra在配置和部署上更为简单,不需要多模块协同操作。
在数据一致性方面,hbase是一个cp系统,对数据有强一致性需求。而cassandra是ap系统,它可以在牺牲一些响应时间的代价下获得和hbase一样的一致性,但通过对quorum的合适设置,可以在响应时间和数据一致性之间取得一个很好的折衷。这使得cassandra在某些需要高可用性和分区容忍性的场合更具优势。
此外,cassandra在功能灵活性上也表现出色。它支持单行查询,也可以基于列值索引选择多行,非常适合某些特定的使用场景。而hbase在辅助索引的支持上相对较弱,通常需要通过触发器等方式来实现。
最后,从存储需求来看,hbase基于hdfs设计,hdfs的设计初衷是存储超大规模文件并提供最大吞吐量和最可靠的可访问性。因此,hbase在处理超大规模文件时具有优势。而cassandra的设计初衷并不是存储大文件,尽管它也可以处理大文件,但不是最佳选择。

发表评论