文章目录
stable diffusion模型或checkpoint模型是预先训练的稳定扩散权重,用于生成特定风格的图像。
模型生成什么样的图像取决于训练图像。如果训练数据中不存在猫,则模型将无法生成猫的图像。同样,如果您只用猫图像训练模型,它只会生成猫。
我们将介绍哪些模型、一些流行的模型以及如何安装、使用和合并它们。
微调模型
什么是微调?
微调是机器学习中的常用技术。它需要一个在宽数据集上训练的模型,并在窄数据集上进行更多训练。
经过微调的模型往往会生成与训练中使用的图像相似的图像。例如,anything v3模型是使用动漫图像进行训练的。因此,它默认生成动漫风格的图像。
人们为什么要制作stable diffusion模型?
stable diffusion基础模型很棒,但并不擅长所有事情。例如,它会在提示中生成带有关键字“anime”的动漫风格图像。然而,生成动漫子类型的图像可能很困难。您可以使用针对该子类型的图像进行微调的自定义模型,而不是修改提示。
下面的图像是使用相同的提示和设置但使用不同的模型生成的。
- realistic vision:逼真的照片风格。
- anything v3:动漫风格。
- dreamshaper:写实绘画风格。

使用模型是实现某种风格的简单方法。
模型是如何创建的?
自定义的checkpoint模型是通过 (1) 额外训练和 (2) dreambooth 制作的。它们都以stable diffusion v1.5或xl等基本模型开始 。
额外的训练是通过使用您感兴趣的附加数据集训练基本模型来实现的。例如,您可以使用老式汽车的附加数据集训练 stable diffusion v1.5,以使汽车的美感偏向老式子类型。
dreambooth由 google 开发,是一种将自定义主题注入文本到图像模型的技术。它仅适用于 3-5 个自定义图像。您可以给自己拍几张照片,然后使用 dreambooth 将自己放入模型中。使用 dreambooth 训练的模型需要特殊的关键字来调节模型。
checkpoint模型并不是唯一的模型类型。我们还有textual inversion(也称为embedding)、lora、lycoris 和 hypernetwork 。我们将在本文中重点讨论checkpoint模型。
流行的stable diffusion模型
有数千个经过微调的stable diffusion模型。这个数字每天都在增加。以下是可用于一般用途的模型列表。
stable diffusion v1.4

v1.4 模型由 stability ai 于 2022 年 8 月发布,是第一个公开可用的stable diffusion模型。
它是一种通用模型,能够生产各种款式。
自 v1.5 版本发布以来,大多数人都已转向该版本。
stable diffusion v1.5

型号页
链接地址
v1.5 由 stability ai 合作伙伴 runway ml 于 2022 年 10 月发布。该模型基于 v1.2 进行了进一步训练。
模型页面没有提及改进是什么。与 v1.4 相比,它产生的结果略有不同,但尚不清楚它们是否更好。
与 v1.4 一样,您可以将 v1.5 视为通用模型。根据我的经验,v1.5 作为初始模型是一个不错的选择,并且可以与 v1.4 互换使用。
realistic vision

realistic vision v2适合生成任何真实的东西,无论是人、物体还是场景。
dreamshaper

dreamshaper模型针对介于照片写实和计算机图形之间的肖像插画风格进行了微调。它很容易使用,如果你喜欢这种风格,你就会喜欢它。
sdxl型号
sdxl 模型是著名的 v1.5 和被遗忘的 v2 模型的升级版。
使用 sdxl 模型的好处是
- 更高的原始分辨率 – 1024 像素,v1.5 为 512 像素
- 更高的图像质量(与 v1.5 基础型号相比)
- 能够生成清晰的文本
- 很容易生成较暗的图像
anything v3

anything v3是一种经过训练可生成高质量动漫风格图像的特殊用途模型。您可以在文本提示中使用danbooru 标签(例如 1girl、白发)。
它对于塑造名人的风格很有用,然后可以与说明性元素无缝融合。
一个缺点(至少对我来说)是它产生的女性体型不成比例。我喜欢用 f222 来调低它的效果。
最佳stable diffusion模型
有数千种可用的stable diffusion模型。其中许多是专用模型,旨在生成特定风格。你应该从哪里开始?除了我刚才提到的那些之外,这里还有一些我经常回顾的最佳模型。
deliberate v2

deliberate v2是另一个必备模型(很多!),可以渲染逼真的插图。结果可能出奇的好。每当您有良好的提示时,请切换到此模型,看看您会得到什么!
f222

f222最初是为了生成裸体而训练的,但人们发现它有助于生成具有正确身体部位关系的美丽女性肖像。与您可能想象的相反,它非常擅长生成美观的服装。
f222适合拍摄人像。它很容易产生裸体。在提示中包含“连衣裙”和“牛仔裤”等衣柜术语。
chilloutmix

chilloutmix 是一个用于生成照片质量的亚洲女性的特殊模型。它就像 f222 的亚洲版本。与korean embedding ulzzang-6500-v1 一起使用来生成像 k-pop 这样的女孩。
与 f222 一样,它有时会生成裸体。在提示中抑制“dress”和“jeans”等衣柜术语,在否定提示中抑制“nude”。
protogen v2.2 (anime)

protogen v2.2 非常经典。它生成具有良好品味的插图和动漫风格图像。
ghostmix
ghostmix采用 90 年代经典动漫《攻壳机动队》风格进行训练。您会发现它对于生成机器人和机器人很有用。
waifu-diffusion

waifu diffusion 是一种日本动漫风格。
inkpunk diffusion

inkpunk diffusion 是一个经过 dreambooth 训练的模型,具有非常独特的插画风格。
使用关键字:nvinkpunk
寻找更多型号
civitai是下载模型的首选地点。
huggingface是另一个很好的来源,尽管该界面不是为stable diffusion模型设计的。
stable diffusion v2 模型

stable diffusion v2 是两个官方的 stable diffusion 模型。v2模型的主要变化是
- 除了 512×512 像素外,还提供 768×768 像素的更高分辨率版本。
- 您无法再生成露骨内容,因为色情材料已从培训中删除。
您可能会假设每个人都已从 v1.5 开始使用 v2 模型。然而,stable diffusion 社区发现2.0模型中的图像看起来更糟。人们也很难使用名人和艺术家名字等强大的关键词。
如何安装和使用模型
这些说明适用于 v1 和 sdxl 型号。
要在 automatic1111 gui 中安装模型,请下载checkpoint模型文件并将其放置在以下文件夹中
按左上角checkpoint下拉框旁边的重新加载按钮。
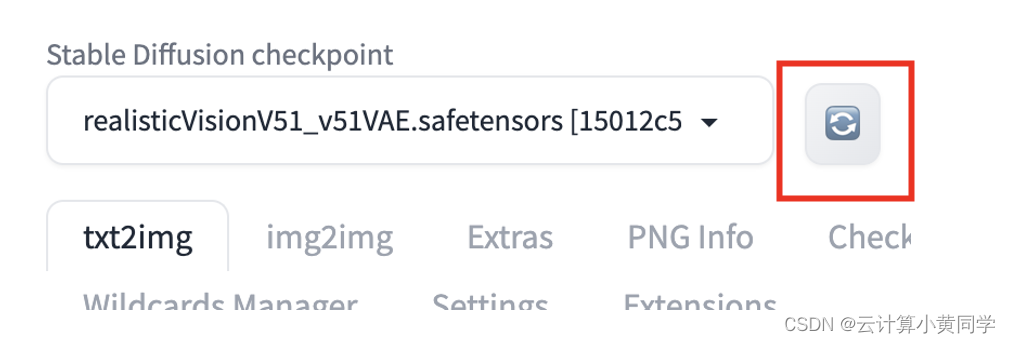
您应该会看到刚刚放入的checkpoint文件可供选择。选择新的checkpoint文件以使用该模型。
clip skip
某些型号建议使用不同的“clip skip”设置。您应该遵循此设置以获得预期的样式。

什么是 clip 跳过?
clip skip是一项功能,可在stable diffusion的图像生成过程中跳过 clip 文本嵌入网络中的最后一些层。clip 是 stable diffusion v1.5 模型中使用的语言模型。它将提示中的文本标记转换为嵌入。它是一个包含许多层的深度神经网络模型。clip skip 指的是要跳过最后几层。
在 automatic1111 和许多稳定扩散软件中,clip skip of 1 不会跳过任何层。clip skip of 2 跳过最后一层,依此类推。
为什么要跳过一些 clip 层?神经网络在信息通过各层时对其进行总结。越早的层,包含的信息越丰富。
跳过 clip 图层会对图像产生巨大的影响。许多动漫模型都是使用 clip skip 2 进行训练的。请参阅下面的示例,其中使用了不同的 clip skip 但具有相同的提示和种子。
在 automatic1111 中设置 clip 跳过
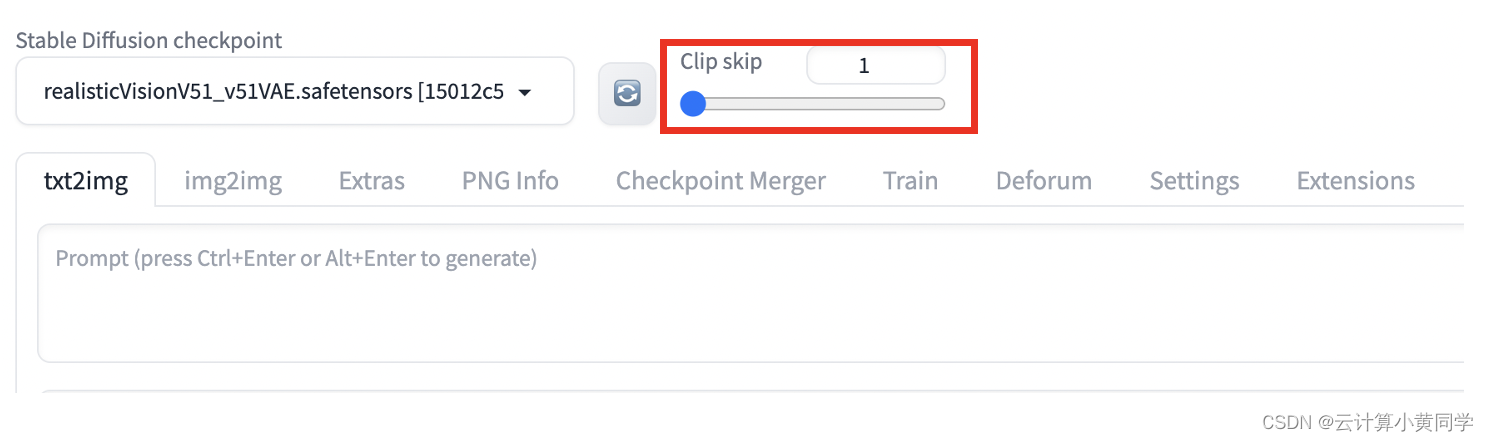
您可以在设置页面 >稳定扩散>剪辑跳过中设置剪辑跳过。调整值并单击“应用设置”。
但如果您需要定期更改 clip skip,更好的方法是将其添加到“快速设置”中。转至设置页面 >用户界面>快速设置列表。添加clip_stop_at_last_layer。单击应用设置并重新加载 ui。
剪辑跳过滑块应出现在 automatic1111 的顶部。
合并两个模型
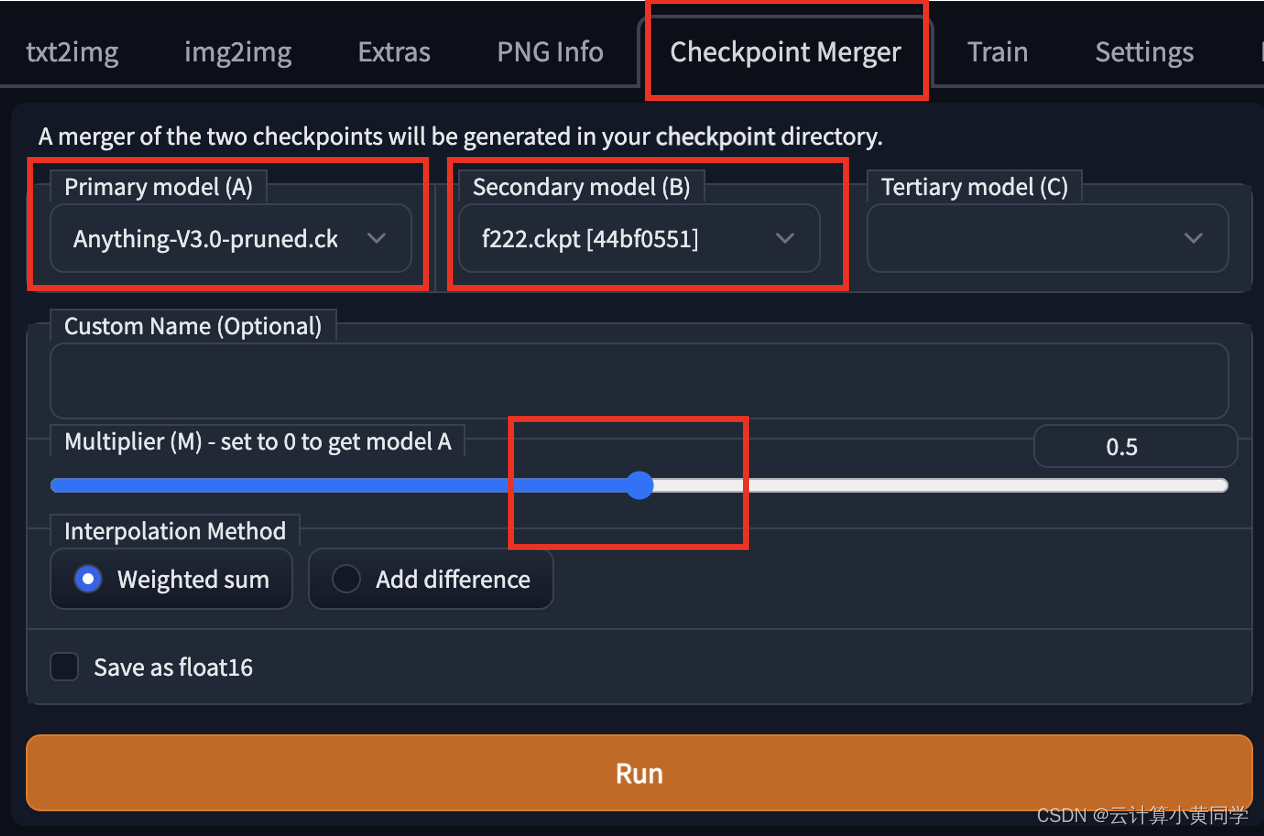
要使用 automatic1111 gui 合并两个模型,请转至checkpoint merger选项卡,然后在主模型 (a)和辅助模型 (b)中选择要合并的两个模型。
调整乘数(m)来调整两个模型的相对权重。将其设置为 0.5 会将两个具有同等重要性的模型合并。
按“运行”后,新的合并模型将可供使用。
合并模型的示例
以下是将f222和anything v3合并为相同权重 (0.5)的示例图像:
合并后的模型介于现实的 f222 和动画 anything v3 风格之间。它是生成人物插画艺术的一个非常好的模型。
stable diffusion模型文件格式
在模型下载页面上,您可能会看到多种模型文件格式。
- pruned
- full
- ema-only
- fp16
- fp32
- .pt
- .safetensor
这很令人困惑!您应该下载哪一个?
pruned vs full vs ema-only 模型
一些稳定扩散 checkpoint 模型由两组权重组成:(1) 最后一个训练步骤后的权重和 (2) 最后几个训练步骤的平均权重,称为 ema(指数移动平均值)。
如果您只想使用该模型,则可以下载 ema-only 模型。这些是您使用模型时使用的权重。它们有时被称为 pruned 模型。
如果您想通过额外的训练来微调模型,则需要 full 模型(即由两组权重组成的 checkpoint 文件)。
因此,如果您想使用 pruned 模型或 ema-only 模型来生成图像,请下载它。这可以节省一些磁盘空间。相信我,您的硬盘很快就会填满!
fp16 and fp32 模型
fp代表浮点数。它是计算机存储十进制数的方式。这里的小数是模型权重。fp16 每个数字占用 16 位,称为半精度。fp32 采用 32 位,称为全精度。
深度学习模型(例如stable diffusion)的训练数据非常嘈杂。您很少需要全精度模型。额外的精度只会存储噪音!
因此,请下载 fp16 模型(如果有)。它们大约有一半大。这可以为您节省几gb!
safetensor 模型
原始的 pytorch 模型格式为.pt,这种格式的缺点是不安全。有人可以在其中打包恶意代码。当您使用该模型时,代码可以在您的机器上运行。
safetensors是 pt 模型格式的改进版本。它的作用与存储权重相同,但不会执行任何代码。
因此,请在可用时下载 safetensors 版本。如果没有,请从可信来源下载 pt 文件。
其他型号类型
四种主要类型的文件可以称为“模型”。让我们澄清一下,以便您知道人们在谈论什么。
- checkpoint 模型是真正的stable diffusion模型。它们包含生成图像所需的所有内容。不需要额外的文件。它们很大,通常为 2 – 7 gb。它们是本文的主题。
- textual inversions(也称为embeddings)是定义新关键字以生成新对象或样式的小文件。它们很小,通常为 10 – 100kb。您必须将它们与checkpoint模型一起使用。
- lora 模型是checkpoint模型的小补丁文件,用于修改样式。它们通常为 10-200mb。您必须将它们与checkpoint模型一起使用。
- hypernetworks 是添加到checkpoint模型的附加网络模块。它们通常为 5 – 300mb。您必须将它们与checkpoint模型一起使用。
概括
我介绍了stable diffusion模型、它们是如何制作的、一些常见的以及如何合并它们。当您心中有特定的风格时,使用模型可以让您的生活更轻松。


发表评论