环境说明
开发环境
| 工具 | 版本 | 备注 |
|---|---|---|
| jdk | 1.8 | 强制要求 |
| mysql | 5.7.24+ | 强制要求 |
| redis | —— |
开发使用工具
| 工具 | 说明 |
|---|---|
| intellij idea | java编程语言开发的集成环境 |
| navicat | mysql数据库管理工具 |
| redisdesktopmanager | redis可视化管理工具 |
部署说明
针对于不同的技术人群,我们提供了多种部署方式:
- 简易版部署:使用docker只需要一行命令即可完成‘nlp自然语言处理引擎’系统的部署
- 全服务本地化部署:针对于前端、java后端、python后端全部实现本地化部署
简易版部署
针对于小白用户,为了避免安装各种开发环境的苦恼,我们给出了简易版部署教程,只需要用户安装好docker,执行一行命令即可部署我们的‘nlp自然语言处理引擎’系统
docker安装
在docker官网也有针对各个操作系统的详细安装步骤:https://www.docker.com/get-started/
-
对于windows用户
在docker官网点击download for windows下载安装包进行安装,具体的安装教程可以参考互联网资料

-
对于ubuntu用户
在命令行输入apt install -y docker.io
-
对于centos用户
yum install -y docker
-
对于macos用户
brew install --cask --appdir=/applications docker
安装完在命令行输入 docker -v 可以返回docker版本号相关信息即为安装成功
docker拉取镜像并运行
在命令行输入下面一行命令即可完成镜像的拉取以及运行。拉取镜像大概需要花费5-10分钟,容器启动大概1-3分钟。
docker run -itd --name nlp_stonedt -p 8866:8866 registry.cn-beijing.aliyuncs.com/stonedt_nlp/nlp_stonedt:1.0.9
验证是否成功运行
-
使用docker ps 命令查看容器运行状况 如果是healthy 即为 部署成功

-
如果失败 请使用docker logs 容器id或名称 -f 查看容器日志(例如 docker logs nlp_stonedt -f)然后提交相关截图联系我们
访问系统
打开浏览器,输入网址 http://ip地址:8866 即可进入系统 默认用户名:user 默认密码:123456
全服务本地化部署
启动python程序
python部署需要准备至少12gb运行内存
一. 部署方式
针对于新手、或有一定基础、或有一定经验,我们准备了三种部署方式:
-
docker镜像(适合新手)
-
dockerfile(有一定基础)
-
conda(有一定经验)
下方conda准备工作和docker准备工作只需要做其一就可以了。
二. conda准备工作
conda是一个用于管理python环境和软件包的开源工具。下面是使用conda进行部署的步骤:
1:安装conda
如果您尚未安装conda,请按照以下步骤安装:
- 访问 anaconda官方网站 下载适用于您操作系统的anaconda安装程序。
- 运行安装程序,并按照提示进行安装。
2:创建环境
-
打开终端
-
创建一个新的conda环境:
conda create --name myenv python=3.9 其中,`myenv`是您想要给环境取的名字,`python=3.9`指定了使用python 3.9版本。 例如 conda create --name nlp_text python=3.9
-
在终端执行下面命令进入虚拟环境激活环境:
conda activate myenv
3:更换镜像源
考虑到网络原因,这里建议用户将镜像源切换成国内源。复制下面的命令在conda虚拟环境里运行即可
- 添加conda清华源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --set show_channel_urls yes
- 添加python源
pip config set global.index-url https://mirror.baidu.com/pypi/simple/
三. 功能分类
考虑到功能分类、资源占用和用户需求的多样性,我们将 python 端拆分为多个项目。根据您的需求,您可以下载相应的 python 代码并安装其所需的依赖包。
根据当前计划,我们将 python 项目分为以下几类:
- 文本处理服务(nlptextservice.py)
- 音视频文件处理服务
- 图像处理服务
文本处理服务功能包括:
- 情感分析
- 招标抽取
- 合同抽取
- 法律文书信息抽取
- 简历抽取
- 观点抽取
- 自定义文本抽取
- 时间抽取
- 关系抽取
- 实体抽取
- 机构识别
- 主题抽取
- 相似度查找
- 文本纠错
- 词性标注
四. python部署
1:文本处理服务(nlptextservice.py)
-
conda部署
-
拉取代码:此服务的代码的位置在:free-nlp-api/python/code/nlptextservice.py
-
进入conda虚拟环境:conda activate myenv
-
安装paddlepaddle 基础依赖
conda install paddlepaddle==2.5.1 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/paddle/
- 安装依赖
pip install paddlenlp==2.5.2 synonyms==3.18.0 paddlehub==2.1.0 aiofiles==22.1.0 fastapi uvicorn pycorrector==0.4.8 jiagu
-
下载模型
对于大部分的功能,在运行python程序的时候会自动从互联网进行下载,但是对于某些服务我们提供了我们自己训练的模型,对结果的精度以及效果都有很大的提升,需要用户手动下载模型放在和python代码同路径(free-nlp-api/pythoncode)下(当然也可以放到别的路径,需要在代码里修改模型路径地址) uie模型下载地址 https://118.184.157.251:8866/uie_modle.tar.gz (备用https://file.654432.xyz/uie_modle.tar.gz) 下载完模型进行解压即可。 如果直链下载失败,可以使用123云盘保存到自己云盘进行下载,下载地址:https://www.123pan.com/s/aec8jv-l99i.html
-
运行程序
进入本项目本地路径free-nlp-api/pythoncode,执行下面命令完成后台运行
nohup python nlptextservice.py &
-
-
dockerfile部署
-
拉取文本处理dockerfile:此文件的位置在:free-nlp-api/python/dockerfile/nlptextservice
-
或者直接wget下载 :wget https://gitee.com/stonedtx/free-nlp-api/raw/master/python/dockerfile/nlptextservice
-
将nlptextservice改名成dockerfile
-
构建镜像
在dockerfile目录下 运行 docker build -t nlp_text:1.0.0 .
-
构建容器并运行
docker run -itd --name nlp_text:1.0.0
-
-
docker部署
-
拉取docker镜像并运行
docker run -itd -p 8801:8801 --name nlp_text registry.cn-beijing.aliyuncs.com/stonedt_nlp/nlp_text:1.0.2
-
查看容器是否正在运行 在命令行输入以下命令 如果出现了名为nlp_text的容器即为正常
docker ps
-
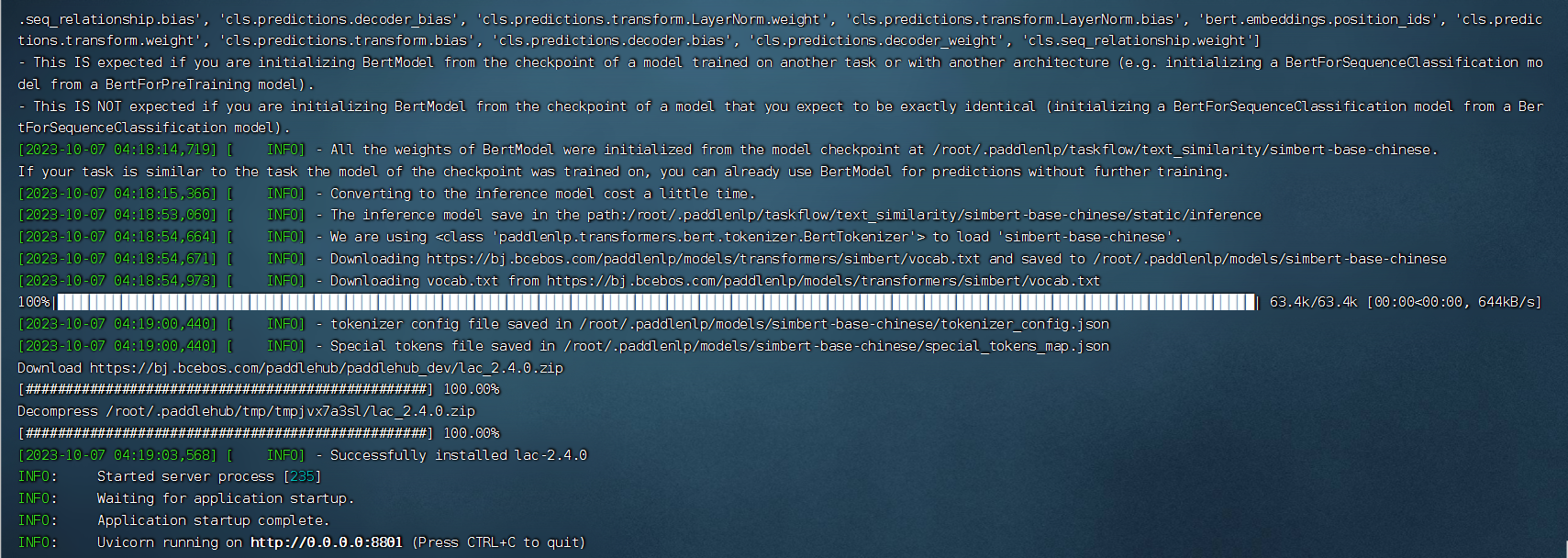
查看服务是否运行成功 在命令行输入以下命令,如果出现和下面图片类似的结果即为部署成功
docker logs nlp_text -f
-
修改简易版镜像地址
如果用户不想折腾其他的环境去部署前后端程序,可以使用我们提供的简易版docker镜像,只需要将python接口地址改成自己的就可以了。
-
进入容器
docker exec -it nlp_stonedt /bin/bash
-
修改python接口地址
进入路径/opt/free-nlp-api/config 输入vim application.properties 将网址修改成我们本地部署的python服务机器的ip地址
-
重启java项目
杀掉进程
kill $(ps aux | grep '[j]ava -jar /opt/free-nlp-api/nlp.jar' | awk '{print $2}')重启进程
nohup java -jar /opt/free-nlp-api/nlp.jar &
环境安装
安装java环境
jdk8 oracle官方下载地址:https://www.oracle.com/java/technologies/downloads/#java8
window安装jdk8 参见: https://www.cnblogs.com/zhangzhixing/p/12953187.html
linux安装jdk8 参见: https://www.jianshu.com/p/75f0f34b599d
安装mysql
mysql5.7安装方式可以参见:https://www.runoob.com/mysql/mysql-install.html
安装redis
- 安装
源码及apt安装
http://www.imxmx.com/item/1/211097.html
- 配置
关于redis的配置这篇文章说的很详细
https://www.cnblogs.com/ysocean/p/9074787.html
启动后端程序
对于有开发经验 建议使用编译器运行调试和jar包部署运行 对于小白用户 建议docker部署
配置文件
-
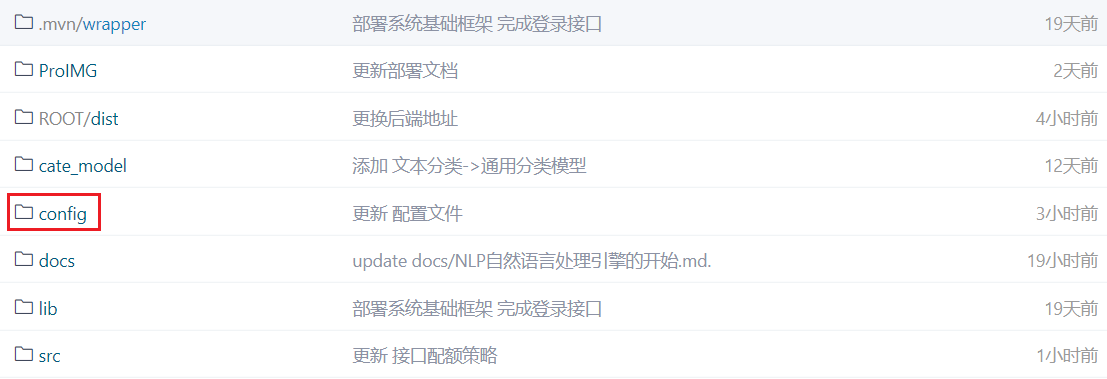
配置文件路径
配置文件的路径在项目根路径的config文件夹下
-
配置文件说明
application.properties为python服务端接口配置
application.yml为java后端配置,里面包含了java后端启动端口、mysql数据库配置信息、redis配置信息等,用户只需要关注mysql、redis配置即可,修改说明在此文件有详细的注释可以参考
编译器运行调试
-
使用git工具或者编译器最新源代码 地址ai多模态能力平台: 免费的自然语言处理、情感分析、实体识别、图像识别与分类、ocr识别、语音识别接口,功能强大,欢迎体验。
-
使用idea或者eclipse
-
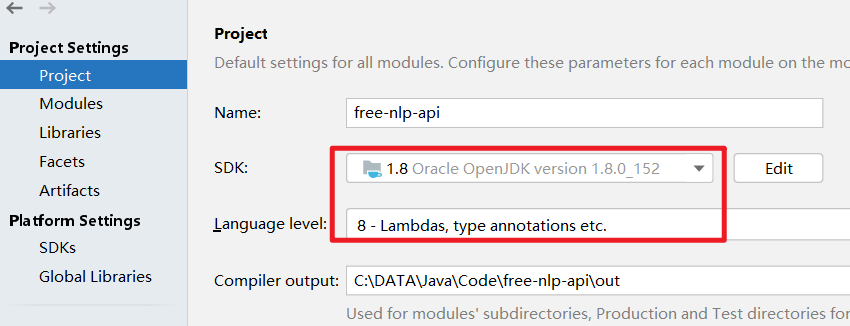
打开项目设置jdk1.8

-
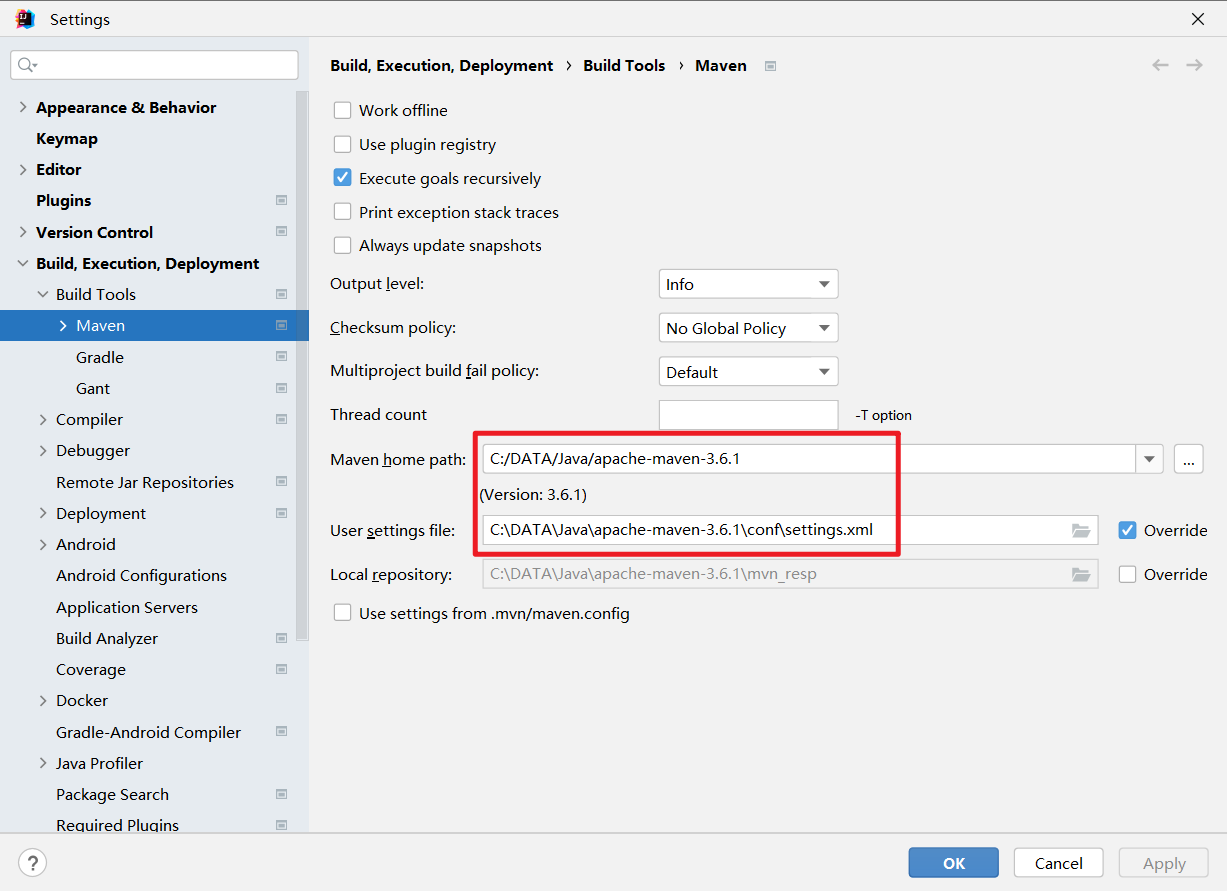
设置maven地址指向本地maven
-
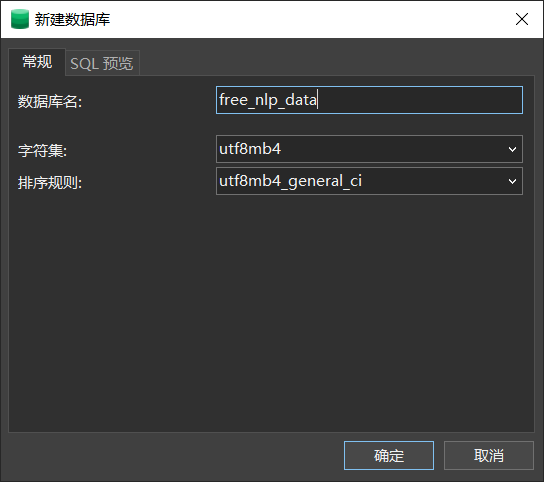
使用navicat或命令行创建数据库free_nlp_data
-
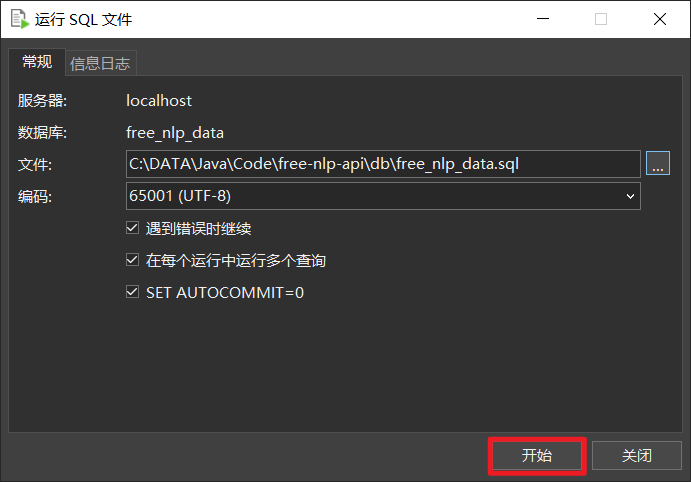
选择刚刚创建的数据库,右键选择运行sql文件进行导入数据库,sql文件的位置项目的db\v1__create.sql
-
打开项目的配置文件application.yml修改数据库和redis的地址、用户名、密码信息
# 数据源配置
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.driver
url: jdbc:mysql://127.0.0.1:3306/free_nlp_data?characterencoding=utf-8&usessl=false
username: root
password: 1234
spring:
redis:
database: 0
host: 127.0.0.1
port: 6379
max-active: 10000
max-idle: 10
max-wait: 100000
timeout: 100000
- 等待maven配置好所有的相关依赖就可以点击运行了。
jar包运行
-
下载部署文件压缩包:地址为https://118.184.157.251:8866/free-nlp-api.zip
-
解压压缩包并修改配置文件
free-nlp-api.jar文件为java程序包,config目录为配置文件目录,我们需要对配置文件进行修改
application.yml 为运行所需环境配置信息,我们将数据库信息和redis信息改成自己的。
application.properties 为调用我们部署的python端接口地址,更换ip地址为部署python服务的机器ip地址。
-
在根目录执行 java -jar free-nlp-api.jar 启动我们的nlp自然语言处理引擎
docker运行
安装docker
拉取基础docker镜像
-
拉取redis $ docker run -p 6379:6379 --name redis -d redis:7.0.12
使用命令docker ps 查看是否redis容器
-
拉取mysql $ docker run -itd --name mysql -p 3306:3306 -e mysql_root_password=1234 mysql:5.7.24
使用命令docker ps 查看是否mysql 容器
创建数据库free_nlp_data 字符集utf8mb4 排序规则utf8mb4_general_ci 在我们的开源地址gitee上找到/db项目路径的sql文件,将数据导入mysql
-
运行后端docker $ docker run -itd --name nlp_data -p 8090:8090 registry.cn-shanghai.aliyuncs.com/stonedt_nlp/nlp_data:1.0.1
使用命令docker ps 查看是否nlp_data 容器
访问http://127.0.0.1:8090/api 查看是否返回结果,如果有就说明后端部署成功
启动前端程序
- 因为本项目是前后端分离的,所以需要前后端都启动好,才能进行访问
- 前端项目在root文件夹,使用tomcat进行部署
tomcat介绍以及安装
-
下载安装tomcat8
官网:apache tomcat® - apache tomcat 8 software downloads
按照自己的操作系统下载合适的linux或者windows版本,然后进行解压,注意不要含有中文路径 解压后目录文件如下
前端部署
项目源代码拷贝
-
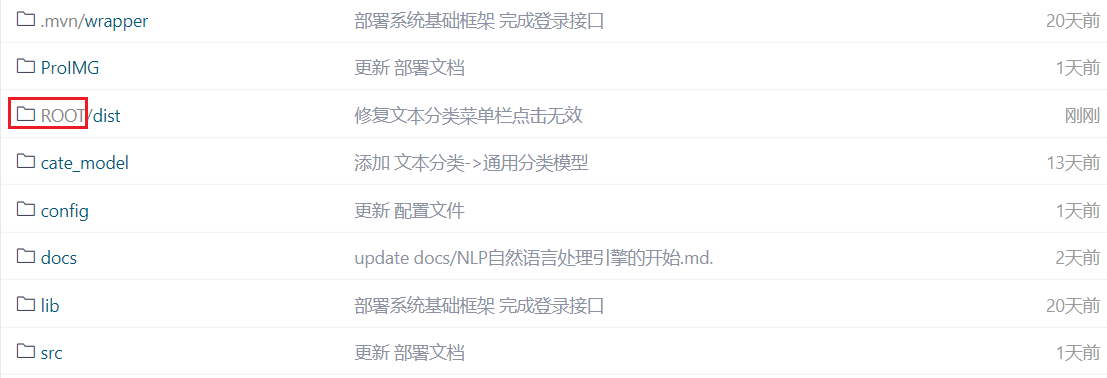
前端项目文件在项目更新目录root文件夹
-
将tomcat根目录里webapps里面的内容全部删除,将项目根目录文件夹root 拷贝到tomcat根目录下webapps下,结构如图:
后端地址修改
- 找到前端接口配置文件/dist/assets/common/public.js
- 将默认的
127.0.0.1:8866替换成 我们部署的后端地址
前端项目执行
- windows请双击tomcat根目录—>bin目录—>startup.bat
- linux用户请在tomcat根目录—>bin目录 执行./startup.sh
访问页面
访问 http://ip地址:8080/dist/assets/page/login/login.html出现登录页面即为前端部署成功
技术合作&交流
联系我们
-
微信号: javabloger
-
电话: 13913853100
-
公司官网:www.stonedt.com
-

欢迎您在下方留言,或添加微信与我们交流。
扫描微信二维码,获得技术支持 或者 申请您的系统调用配额。






发表评论