
大语言模型(llm)是人工智能领域的一个突破性进展,它通过多种技术手段实现对自然语言的理解和生成。用比较通俗的话来列举一些我认为比较关键的技术手段:
通过这些技术手段,大型语言模型能够更好地理解和生成自然语言,为各种应用场景提供支持。
下面我将简单展开说明大语言模型。
1. 大语言模型(llm)概述
1.1 定义与重要性
大语言模型(llm)是指具备大量参数和复杂计算结构的深度学习模型,它们在自然语言处理(nlp)领域扮演着至关重要的角色。这些模型通过学习海量的文本数据,能够理解语言的结构、语义和上下文,进而生成符合语法和逻辑的文本。
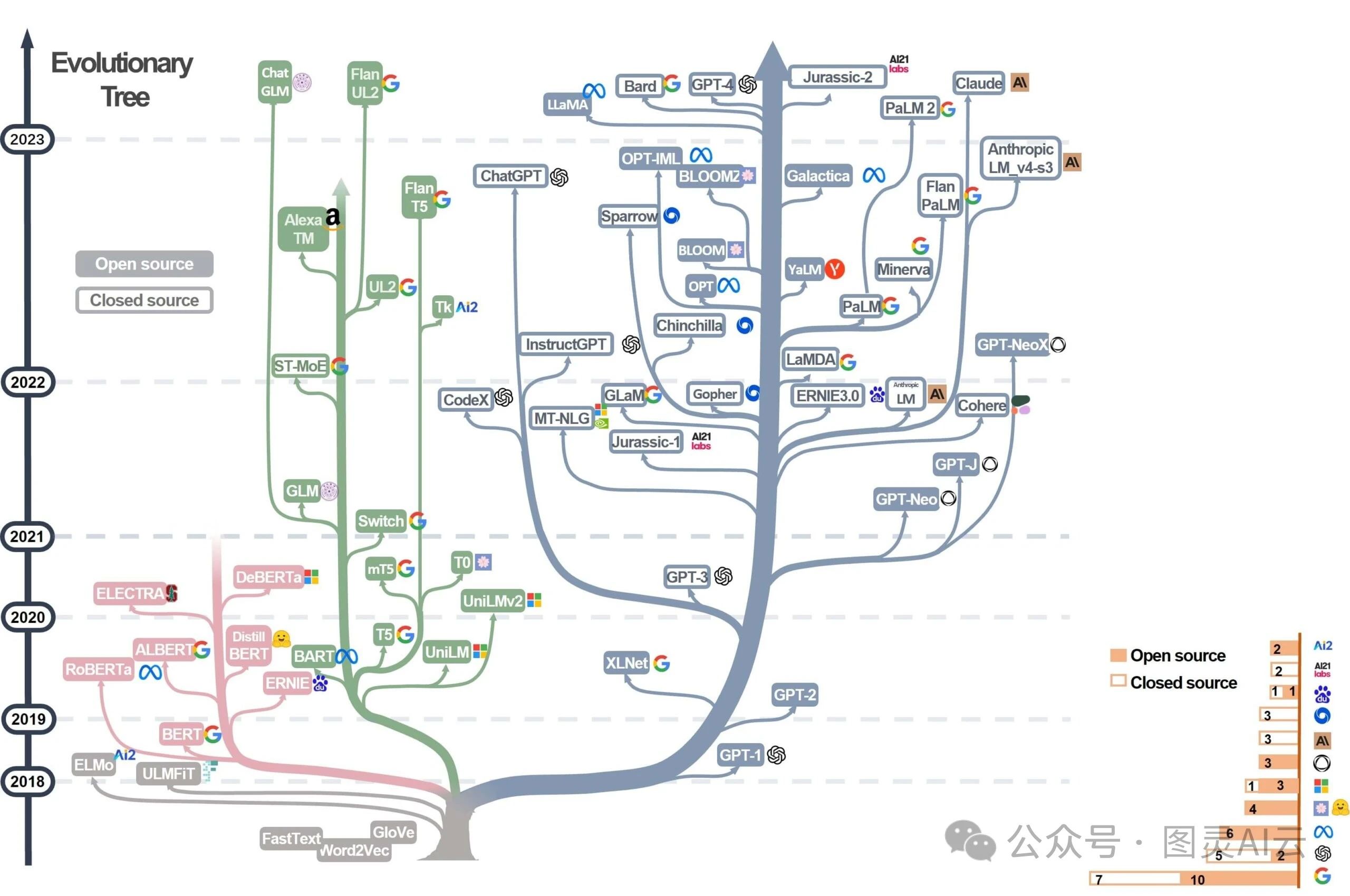
1.2 发展历程
大语言模型的发展历程标志着人工智能领域的重要进步。
2. 大语言模型(llm)的关键技术手段
2.1 模型架构
2.2 自注意力机制
2.3 位置编码
2.4 预训练技术
2.5 优化算法
2.6 计算硬件
2.7 数据处理
2.8 伦理与安全性
2. 技术架构与原理
2.1 transformer 架构
transformer 架构是大语言模型(llm)的核心技术之一,它基于自注意力机制,允许模型在处理序列数据时并行处理序列中的每个元素。这种架构最初由 vaswani 等人在 2017 年提出,并在随后的自然语言处理任务中显示出卓越的性能。
2.2 自注意力机制
自注意力机制是 transformer 架构的核心组成部分,它允许模型在生成每个输出时,对输入序列的不同部分分配不同的注意力权重。
自注意力机制的引入,使得大语言模型在处理复杂的语言结构时更加灵活和有效,极大地推动了自然语言处理领域的发展。
3. 训练过程与方法
3.1 数据集的选择与准备
大型语言模型(llm)的训练依赖于高质量且多样化的数据集。数据集的选择是确保模型能够理解和生成自然语言的关键步骤。
3.2 预训练与微调
预训练和微调是 llm 开发过程中的两个关键阶段,它们共同确保了模型在特定任务上的性能。
通过精心设计的训练过程,大型语言模型能够展现出卓越的语言理解和生成能力,为各种自然语言处理任务提供强大的支持。
4. 应用场景与案例分析
4.1 机器翻译
机器翻译作为大语言模型(llm)的重要应用之一,利用 llm 的强大语义理解能力,实现了跨语言的高效转换。llm 在机器翻译领域的应用主要体现在以下几个方面:
4.2 聊天机器人与虚拟助手
聊天机器人和虚拟助手是 llm 技术应用的另一重要领域,它们通过模拟人类对话的方式,提供交互式的服务和信息。
5. 挑战与应对策略
5.1 偏见与公平性问题
大语言模型(llm)在训练过程中可能会从数据集中学习并放大偏见,这可能导致不公平性问题。例如,如果训练数据在性别或种族方面存在偏见,模型可能会在生成文本时反映出这些偏见。
5.2 数据隐私与安全性
llm 的训练和应用涉及大量数据,其中可能包含敏感信息。保护用户隐私和数据安全是 llm 开发和部署中的重要挑战。
6. 未来发展趋势与创新方向
6.1 模型效率与可扩展性
随着大语言模型(llm)的快速发展,模型的效率和可扩展性成为了研究的重点。当前,llm 正朝着更高效的训练算法和更优化的模型结构发展。
6.2 多模态学习与整合
多模态学习是指模型能够同时处理和理解多种类型的数据,如文本、图像、声音和视频等。llm 在多模态学习方面的研究正逐渐深入,以实现更丰富的应用场景。




发表评论