2.从制造工艺来看,1980年采用4μ的n沟道mos工艺,而现在则普遍采用亚微米cmos工艺。
3.从封装工艺来看,dsp芯片的引脚数量从1980年的最多64个增加到现在的200个以上,引脚数量的增加,意味着结构灵活性的增加。
此外,dsp芯片的发展,是dsp系统的成本、体积、重量和功耗都有很大程度的下降。
三、dsp芯片的类型
\1. 根据基础特性
根据dsp芯片的工作时钟和指令类型来分类的。如果dsp芯片在某时钟频率范围内的任何频率上能正常工作,除计算速度有变化外,没有性能的下降,这类dsp芯片一般称之为静态dsp芯片。如果有两种或两种以上的dsp芯片,它们的指令集和相应的机器代码机管脚结构相互兼容,则这类dsp芯片称之为一致性的dsp芯片。
\2. 根据数据格式
数据以定点格式工作的dsp芯片称之为定点dsp芯片。以浮点格式工作的称为浮点dsp芯片。不同的浮点dsp芯片所采用的浮点格式不完全一样,有的dsp芯片采用自定义的浮点格式,有的dsp芯片则采用ieee的标准浮点格式。
\3. 根据用途
可分为通用型dsp芯片和专用型的dsp芯片。通用型dsp芯片适合普通的dsp应用,如ti公司的一系列dsp芯片。专用型dsp芯片市为特定的dsp运算而设计,更适合特殊的运算,如数字滤波,卷积和fft等。
四、dsp芯片的基本结构
dsp芯片的基本结构包括:
(1)哈佛结构;
(2)流水线操作;
(3)专用的硬件乘法器;
(4)特殊的dsp指令;
(5)快速的指令周期。
哈佛结构
哈佛结构的主要特点是将程序和数据存储在不同的存储空间中,即程序存储器和数据存储器是两个相互独立的存储器,每个存储器独立编址,独立访问。与两个存储器相对应的是系统中设置了程序总线和数据总线,从而使数据的吞吐率提高了一倍。由于程序和存储器在两个分开的空间中,因此取指和执行能完全重叠。
流水线与哈佛结构相关,dsp芯片广泛采用流水线以减少指令执行的时间,从而增强了处理器的处理能力。处理器可以并行处理二到四条指令,每条指令处于流水线的不同阶段。
专用的硬件乘法器
乘法速度越快,dsp处理器的性能越高。由于具有专用的应用乘法器,乘法可在一个指令周期内完成。
特殊的dsp指令dsp芯片是采用特殊的指令。
快速的指令周期哈佛结构、流水线操作、专用的硬件乘法器、特殊的dsp指令再加上集成电路的优化设计可使dsp芯片的指令周期在200ns以下。
tms320f28335 嵌入式dsp内部结构框图:
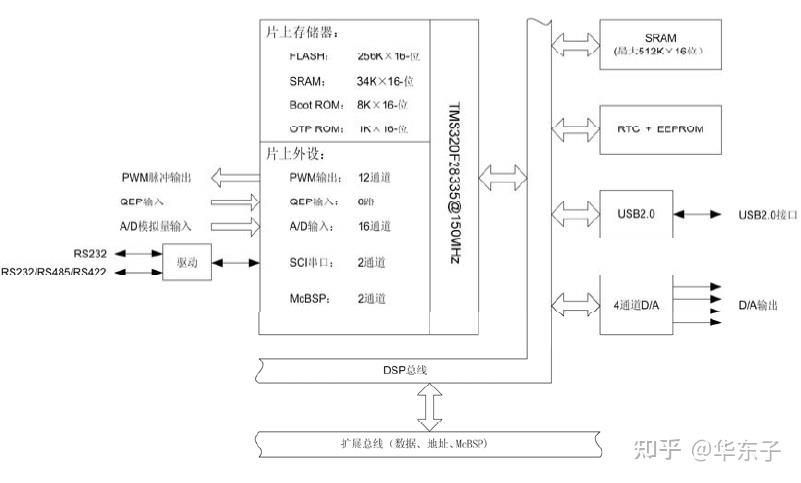
tms320f28335 嵌入式dsp 来自网上 侵删
seed-dec28335主要集成了150m系统时钟的dsp、64k x 16 位的片外sram、16 路片内12 位a/d、12 路pwm、2 路uart、1 路can、一路高速usb、片外4 通道12-位d/a 和串行eeprom+rtc 实时时钟等外设。这样使其能够应用在电机、电力等工业控制领域。
五、如何选择dsp芯片
一般来说,我们选择dsp芯片时,需要考虑如下因素:
ti系列推荐:
如果用于控制,主要是选择tms320c2000系列;
如果用于通信,主要是选择tms320c5000系列;
如果用于图像处理,那就选择6000系列。
具体指标:
1.运算速度。运算速度是芯片的一个最重要的性能指标,也是选择芯片时所需要考虑的一个主要因素。运算速度可以用以下几种性能指标来衡量:
(1) 指令周期。就是执行一条指令所需要的时间,通常以纳秒(ns)为单位。
(2) mac时间。即一次乘法加上一次加法的时间。
(3) fft执行时间。即运行一个n点fft程序所需的时间。
(4) mips。即每秒执行百万条指令。
(5) mops。即每秒执行百万次操作。
(6) mflops。即每秒执行百万次浮点操作。
(7) bops。即每秒执行十亿次操作。
2.价格。根据实际应用,确定一个价格适中的芯片。
3.硬件资源。
4.运算速度。
5.开发工具。
6.功耗。
另外还要考虑一些其它的因素,如封装的形式等等。
dsp应用系统的运算量是确定选用处理能力多大的dsp芯片的基础。确定一个dsp系统的运算量以选择dsp芯片的方法:
1. 按样点处理
就是dsp算法对每一个输入样点循环一次。比如:设计一个采用lms算法的256抽头的自适应fir滤波器,假定每个抽头的计算需要3个mac周期,则256抽头计算需要256*3=768个mac周期。如果采样频率为8khz,即样点之间的间隔为125μs的时间,dsp芯片的mac周期为200μs,则768个周期需要153.6μs的时间,显然无法实时处理,需要选用速度更快的芯片。
2. 按帧处理
有些数字信号处理算法不是每个输入样点循环一次,而是每隔一定的时间间隔(通常称为帧)循环一次。所以选择dsp芯片应该比较一帧内dsp芯片的处理能力和dsp算法的运算量。假设dsp芯片的指令周期为p(ns),一帧的时间为⊿τ(ns),则该dsp芯片在一帧内所提供的最大运算量为⊿τ/ p 条指令。
六、dsp系统
三大特色:强大数据处理能力、数字信号处理的实时性和高运行速度,最值得称道。一般具有如下的一些主要特点:
(1) 在一个指令周期内可完成一次乘法和一次加法。
(2) 程序和数据空间分开,可以同时访问指令和数据。
(3) 片内具有快速ram,通常可通过独立的数据总线在两块中同时访问。
(4) 具有低开销或无开销循环及跳转的硬件支持。
(5) 快速的中断处理和硬件i/o支持。
(6) 具有在单周期内操作的多个硬件地址产生器。
(7) 可以并行执行多个操作。
(8) 支持流水线操作,使取指、译码和执行等操作可以重叠执行。
与通用微处理器相比,dsp芯片的其他通用功能相对较弱些。
数字信号处理系统是以数字信号处理为基础,因此具有数字处理的全部特点:
(1) 接口方便。dsp系统与其它以现代数字技术为基础的系统或设备都是相互兼容,这样的系统接口以实现某种功能要比模拟系统与这些系统接口要容易的多。
(2) 编程方便。dsp系统种的可编程dsp芯片可使设计人员在开发过程中灵活方便地对软件进行修改和升级。
(3) 稳定性好。dsp系统以数字处理为基础,受环境温度以及噪声的影响较小,可靠性高。
(4) 精度高。16位数字系统可以达到的精度。
(5) 可重复性好。模拟系统的性能受元器件参数性能变化比较大,而数字系统基本上不受影响,因此数字系统便于测试,调试和大规模生产。
(6) 集成方便。dsp系统中的数字部件有高度的规范性,便于大规模集成。
目前广泛应用的是tms320f28335芯片系列。
dsp芯片实例tms320c542:
tms320c542属于ti公司c5000系列。c5000系列具有以下特点:
·改进的哈佛结构,包含一条程序总线,三条数据总线和四条地址总线
·高度并行的cpu和针对应用优化的硬件
·针对算法和高级语言优化的指令集
·先进的ic技术使其既高性能又低功耗。
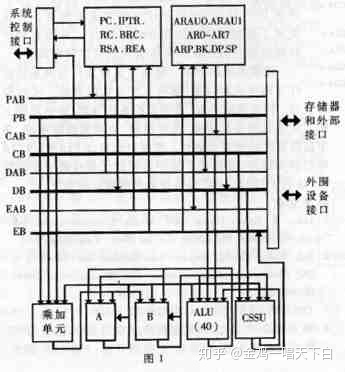
c5000系列dsp微处理器内部结构功能框图,如图1所示。包括:40bit算数逻辑单元(alu);2个40bit累加器a和b;17×17bit乘加单元、40bitmac ,可作64级fir运算而不必考虑溢出;计算、选择、存储单元(ccsu),特别适合viterbi等算法;40bit桶型移位寄存器;片上双存取ram,每机器周期可存取两次;片上单存取ram,可同时访问两块片上存储区;片上外围接口,包括串口、定时器、pll、hpi接口等。
tms320c542自身特点如下:
·25ns单周期定点指令执行时间,5v供电
·10k words16bit 片上双存取ram
·64k words程序,64k words数据,64k words i/o存储空间
·2k words hpi接口,可通过此接口方便地与主设备进行信息交换,主设备也可通过此接口下载dsp程序
·一个自动缓冲的串口和一个tdm串口,且都可用作标准同步串口
此外,c5000系列dsp可使用jtag接口进行调试,可完全控制dsp上的所有资源,使用方便可靠。
学习指导
一本非常好用的dsp教材:手把手教你学dsp。
这本书以tms320x281x的开发为主线,介绍与dsp开发相关的知识:dsp开发环境的搭建、新工程的建立、ccs6.0的使用、cmd文件的编写、硬件电路的设计、存储器的映像、三级中断系统以及tms320x281x各个外设模块的功能和使用。
每部分内容都有应用实例,并手把手地讲解例程的编写过程。所有代码都标注有详细的中文注释,为读者快速熟悉并掌握dsp的开发方法和技巧提供了方便。
基于ccs6.0,生活化语言,浅显易懂,深入浅出,非常适合新手学习。
出版社: 北京航空航天大学出版社 出版时间:2019-02-01
第1章如何开始dsp的学习和开发
第2章tms320x2812的结构、资源及性能
第3章tms320x281x的硬件设计
第4章创建一个新工程
第5章ccs的常用操作
第6章使用c语言操作dsp的寄存器
第7章存储器的结构、映像及cmd文件的编写
第8章x281x的时钟和系统控制
第9章通用输入/输出多路复用器gpio
第10章cpu定时器
第11章x2812的中断系统
第12章事件管理器ev
第13章模/数转换器adc
第14章串行通信接口sci
第15章串行外设接口spi
第16章增强型控制器局域网通信接口ecan
第17章基于hdspsuper2812的开发实例
b站上 手把手教你学dsp视频教程dsp281x
参考
- ^如有侵犯您的权益,请联系作者删除。
已剪辑自: https://dongka.github.io/2018/11/17/cpu/arm体系架构的发展/
arm体系架构的发展
本文将从以下几点去展开介绍arm体系架构的发展:
- 指令集架构
- arm公司的发展历史以及授权模式
- arm的体系架构
arm公司的发展历史
arm的发展历程在此文章讲的非常详细,故不再赘述一文带你了解arm的发展历程
arm授权模式
在传统pc领域,半导体有两种路子可以走,一种是intel这种,从头到尾一条龙,架构和芯片设计,生产一律不靠任何人; 这样做需要极其雄厚,全方位的实力做保障,得有钱,有人,有技术,在半导体技术日益复杂的今天,能这么做屈指可数;好处就是利润率比较高,想卖多少钱就多少;当然技术上得做到领先甚至于垄断的地位优势才比较明显;
另外一种则无工厂模式(fabless),nvidia,amd,这类企业都是自己设计芯片,制造交给代工厂,比如台积电,联电,globalfoundries,三星电子。好处很明显,负担轻,但是在半导体这种工艺在功耗与性能中扮演重要角色的行业,你设计出来的是否能设计出来,怎么设计出来,很大程度看代工厂的能耐;幸好这些代工厂也十分给力,不断的逼近物理极限;使得amd最近也能慢慢的赶上挤牙膏的intel;
arm就不一样了,它不制造,不销售芯片,只是自己设计ip,包括指令集,微处理器,gpu,总线,然后谁要的话就买arm的授权;授权模式分为此三种:
处理器授权
arm设计好一颗cpu或者gpu,armv7架构对应的ip为cortex-a5/a7/a9/a12/a15/a17这几个核心架构,对应armv8-a就有cortext-a35/a53/a57/a72/a73;armv8.2a指令集:cortext-a55/a75;然后授权卖给伙伴,买下它们后,只能按照图纸实现,能发挥的不多,如何实现就比较随便,如配置哪些模块,几个核心,多少缓存,多高频率,什么工艺,谁来代工等等;
如果想优化,但是技术有限,那么可以买arm的处理器优化包/物理ip包授权(pop)
如果只是想更快速搞出产品,那么更干脆了,arm已经帮你制定好代工厂处理器类型和工艺了;
代表商家有联发科,展讯,联芯,全志,瑞芯微,炬力等;这些设计公司获得的是软核或者这点硬核授权,通过购买的cpu核,与gpu核,以及通过一定的流程,集成出soc;
购买处理器授权的本质上就大同小异了,可以做出差异化的只能在一些ip上做出差异化;
架构/指令授权
这种授权方式价格比较贵,为防止碎片化的情况出现还有可能处于技术上的保护,arm禁止对指令集进行修改或者添加,但其他公司是否确切遵守了,这个就不得而知了;总之这种授权需要具有非常强的技术实力,也不过15家,如我们熟知的高通,苹果,三星,华为等公司;
除了版税,那些购买了arm ip授权的,还需要为每一个芯片支付版税;
在这里有些问题就应该提出来思考了,为什么都是arm的指令集,苹果的芯片却可以吊打现在的android厂商的芯片呢?评价cpu性能指标在以下几个方面:
一:指令集宽度(issue)6
二:乱序指令执行缓冲区(recorder buffer)(192)
三:内存加载延迟(load latency):4
四:分支预测错误代价(misprediction penalty):16(一般介于14~19)
不得不说,苹果很早就开始布局cpu的设计之路,具有极强的芯片设计能力,在厂家都是基于arm的公版进行设计,苹果就已经通过购买arm指令集,然后进行自己的cpu设计,在14年的时候a7处理器,作为第一个arm 64位cpu商用,而且将指令集宽度位6,作为对比arm目前的指令集为3;由于封闭式的开发,不像高通,需要考虑各个厂家的需求和成本,苹果有更高的溢价能力,可以用面积去换取性能与功耗,并根据自己的系统去做定制化;
指令集架构(isa)
cpu执行计算任务时都需要遵从一定的规范,程序在被执行时都需要先翻译成cpu可以理解的语言。这种规范就是指令集**(isa,intruction set architecrure);**
例如以下的机器码:1110 0001 1010 0000 0010 0000 0000 0001
比如有个cpu定位1110 0001就是add指令,1010 0000对应的是存储数据的寄存器r2;0010 0000对应的寄存器r0;
0000 0001对应是寄存器r1,故意思可以是add r2 r0 r1,将r0,r1的值加起来放到r2;指令集就是定义一套约定俗成的cpu运行规则,对于编程人员,面对的汇编指令;而对于cpu来说,就是怎么去理解这段二进制码,不同的cpu对这段二进制代码不同,故就有了不同的指令集架构;
指令集一般分为两种:精简指令集(risc:reduced instruction set computer)和复杂指令集(cisc:complex instrution set computer),以洗衣机洗衣服为例,risc架构为,加水->漂洗->风干;而复杂指令集则可以发出洗衣服的指令,从而让洗衣机自动帮忙做这一整套的流程;cisc可以通过一条复杂的指令来完成许多事情,性能在处理复杂的任务时,会比risc更为高效;但随之而来的是面积和功耗的提升;基于2/8理论,程序大部分时间(80%)都是在做重复而简单的事情;所以risc架构就应运而生,更为精简的指令,将任务更多的放在了编译器这块,通过复杂的指令转化成简单指令的组合,在一定程度上增加了代码量,但使其大部分场合能比cisc取得更小的面积和功耗;
采用精简指令集的微处理,常见为arm,mips,power architecture(包括powerpc,powerxcell),sparc,risc-v等而采用cisc则为x86和amd
至于arm为代表risc架构与以x86为代表的cisc之间的优劣比较还有是否存在替代一说,笔者认为,不会,而且从目前的发展来看,已经出现了你中有我,我中有你的局面;
更进一步的探讨可以看下知乎上关于精简指令集与负杂指令集的讨论,我也很赞同其中一个答主的观点,这已经不是个技术问题了,而是一个商业的问题
总结完risc和cisc之间的关系,再讲讲基于risc阵营里面的arm和最近比较火热的risc-v,arm大家都熟悉,而risc-v又是个什么东西呢?
risc-v是加州大学伯克利分校的开源指令集,由计算机架构的宗师级任务david patterson领衔打造,通过将核心指令集以及
关键ip开源,意图改变半导体生态;详细的可以看这篇文档;名家专栏丨一文看懂risc-v
总结如下:risc-v具有以下优点:1.可模块化配置的指令集。 2.支持可扩展的指令集 3.一套指令集支持所有架构,基本指令集仅40余条指令,以此为共用基础,加上其他常用模块子集指令总指令集也仅几十条 4.硬件设计和编译器非常简单
笔者认为,risc-v目前作为一个像linux看齐的硬件开源组织,linux之所以能健康长足发展,在于社区成千上万的内核爱好者的不断贡献,使得linux能够蓬勃发展;而硬件则不同,在这动辄上百万的流片费的无数摆在硬件设计者面前的坎,是否会有公司或者团体愿意将自己用血与泪验证的ip,贡献到社区,如果没有做到这一点,即将面临由于厂家扩展指令不同的碎片化问题解决,还有risc-v后面的长足发展,将付之空谈;这样risc-v架构只能作为几个大厂找到的低廉的替代arm方案的选择,而无法真正做到普惠;
arm的体系架构
时间 架构 主要更新
| 1985 | armv1 | 只有26位的寻值空间,没有用于商业产品 |
| 1986 | armv2 | 首颗量产的arm处理器,包括32位乘法指令和协处理器指令 |
| 1990 | armv3 | 具有片上高速缓存,mmu和写缓冲,寻址空间增大到32位 |
| 1993 | armv4 | arm7,arm8,arm9和strong arm采用这种架构。增加了16 thumb指令集 |
| 1998 | armv5 | arm7(ej),arm9(e),arm10(e)和xscale采用这种了该架构,改进了arm/thumb状态之间的切换效率,此外还引入dsp指令和支持java |
| 2001 | armv6 | arm11,强化了图形处理性能,通过追加有效进行多媒体处理的simd将语音及图像的处理功能大大提高。此外arm在这个系列中引入混合16位/32位的thumb-2指令集 |
| 2004 | armv7 | cortex-m3/4/7,cortex-r4/5/6/7,cortex-a8/9都是基于该架构,该架构包括neon技术扩展,可将dsp和媒体处理吞吐量高达400%,并提供改进的浮点支持以满足下一代3d图形和游戏以及传统嵌入式控制应用的需要 |
| 2007 | armv6-m | 专门为低成本,高性能的设备而设计,cortex-m0/1即采用该架构 |
| 2011 | armv8 | cortex-a32/35/53/57/72/73采用此架构,第一款支持64位的处理器架构 |
arm架构发展图:
arm体系的cpu工作模式:
1.用户模式(usr):正常的程序执行状态
2.快速中断模式(fiq):用于支持高速数据传输或者通道处理
3.中断模式(irq):用于普通中断处理
4.管理模式(svc):操作系统使用的保护模式
5.系统模式(sys):运行具有特权的操作系统的任务;
6.数据访问终止模式(abt):数据或指令与预取终止时进入该模式
7.未定义指令终止模式(und):未定义的指令执行时进入该模式;
linux如何从用户态进入内核态
分为两种:主动式和被动式、
1.主动式:就是linux用户在(arm在用户模式下)工作,通过发起用户态程序发起命令请求,arm响应进入特权模式进而linux切入内核态,就是系统调用;系统调用可被堪称一个内核与用户空间程序交互的接口;把用户进程的请求传达 给内核,待内核把请求处理完毕后再将处理结果送回给用户空间;
系统调用的主要用途:
一:控制硬件-系统调用往往作为硬件资源和用户空间的抽象接口,比如读写文件用到的write/read调用
二:设置系统状态或读取内核数据;
2.被动式:就是linux在用户态(arm在用户模式)工作,没有主动发起请求,而被动地进入内核态,包括硬件中断和程序异常;
参考资料:
一样是arm架构,为何苹果处理器效能就是压下其他人
浅析arm的异常,中断和arm工作模式的联系
如何零基础入门fpga?这篇文章让你吃透!
已剪辑自: https://www.eet-china.com/mp/a124380.html
1. 看代码,建模型
只有在脑海中建立了一个个逻辑模型,理解fpga内部逻辑结构实现的基础,才能明白为什么写verilog和写c整体思路是不一样的,才能理解顺序执行语言和并行执行语言的设计方法上的差异。在看到一段简单程序的时候应该想到是什么样的功能电路。
2. 用数学思维来简化设计逻辑
学习fpga不仅逻辑思维很重要,好的数学思维也能让你的设计化繁为简,所以啊,那些看见高数就头疼的童鞋需要重视一下这门课哦。举个简单的例子,比如有两个32bit的数据x[31:0]与y[31:0]相乘。
当然,无论altera还是xilinx都有现成的乘法器ip核可以调用,这也是最简单的方法,但是两个32bit的乘法器将耗费大量的资源。那么有没有节省资源,又不太复杂的方式来实现呢?我们可以稍做修改:
将x[31:0]拆成两部分x1[15:0]和x2[15:0],令x1[15:0]=x[31:16],x2[15:0]=x[15:0],则x1左移16位后与x2相加可以得到x;同样将y[31:0]拆成两部分y1[15:0]和y2[15:0],令 y1[15:0]=y[31:16],y2[15:0]=y[15:0],则y1左移16位后与y2相加可以得到y,则x与y的相乘可以转化为x1和x2 分别与y1和y2相乘,这样一个32bit32bit的乘法运算转换成了四个16bit16bit的乘法运算和三个32bit的加法运算。转换后的占用资源将会减少很多,有兴趣的童鞋,不妨综合一下看看,看看两者差多少。
3. 时钟与触发器的关系
“时钟是时序电路的控制者”这句话太经典了,可以说是fpga设计的圣言。fpga的设计主要是以时序电路为主,因为组合逻辑电路再怎么复杂也变不出太多花样,理解起来也不没太多困难。
但是时序电路就不同了,它的所有动作都是在时钟一拍一拍的节奏下转变触发,可以说时钟就是整个电路的控制者,控制不好,电路功能就会混乱。
打个比方,时钟就相当于人体的心脏,它每一次的跳动就是触发一个 clk,向身体的各个器官供血,维持着机体的正常运作,每一个器官体统正常工作少不了组织细胞的构成,那么触发器就可以比作基本单元组织细胞。
时序逻辑电路的时钟是控制时序逻辑电路状态转换的“发动机”,没有它时序逻辑电路就不能正常工作。
因为时序逻辑电路主要是利用触发器存储电路的状态,而触发器状态变换需要时钟的上升或下降沿,由此可见时钟在时序电路中的核心作用。
最后简单说一下体会吧,归结起来就是多实践、多思考、多问。实践出真知,看100遍别人的方案不如自己去实践一下。实践的动力一方面来自兴趣,一方面来自压力。有需求会容易形成压力,也就是说最好能在实际的项目开发中锻炼,而不是为了学习而学习。
02
为什么你会觉得fpga难学?
不熟悉fpga的内部结构
fpga为什么是可以编程的?
恐怕很多初学者不知道,他们也不想知道。
因为他们觉得这是无关紧要的。他们潜意识的认为可编程嘛,肯定就是像写软件一样啦。
软件编程的思想根深蒂固,看到verilog或者vhdl就像看到c语言或者其它软件编程语言一样。一条条的读,一条条的分析。
拒绝去了解为什么fpga是可以编程的,不去了解fpga的内部结构,要想学会fpga 恐怕是天方夜谭。
那么fpga为什么是可以“编程”的呢?首先来了解一下什么叫“程”。
启示 “程”只不过是一堆具有一定含义的01编码而已。
编程,其实就是编写这些01编码。只不过我们现在有了很多开发工具运算或者是其它操作。
所以软件是一条一条的,通常都不是直接编写这些01编码,而是以高级语言的形式来编写,最后由开发工具转换为这种01编码而已。
对于软件编程而言,处理器会有一个专门的译码电路逐条把这些01编码翻译为各种控制信号,然后控制其内部的电路完成一个个的读,因为软件的操作是一步一步完成的。
而fpga的可编程,本质也是依靠这些01编码实现其功能的改变,但不同的是fpga之所以可以完成不同的功能,不是依靠像软件那样将01编码翻译出来再去控制一个运算电路,fpga里面没有这些东西。
fpga内部主要三块:可编程的逻辑单元、可编程的连线和可编程的io模块。
其基本结构某种存储器(sram、 flash等)制成的4输入或6输入1输出地“真值表”加上一个d触发器构成。
任何一个4输入1输出组合逻辑电路,都有一张对应的“真值表”,同样的如果用这么一个存储器制成的4输入1输出地“真值表”,只需要修改其“真值表”内部值就可以等效出任意4输入1输出的组合逻辑,这些“真值表”内部值就是那些01编码。
如果要实现时序逻辑电路怎么办?任何的时序逻辑都可以转换为组合逻辑+d触发器来完成。但这毕竟只实现了4输入1输出的逻辑电路而已,通常逻辑电路的规模那是相当的大。
3.1 可编程连线
那怎么办呢?这个时候就需要用到可编程连线了。在这些连线上有很多用存储器控制的链接点,通过改写对应存储器的值就可以确定哪些线是连上的而哪些线是断开的。这就可以把很多可编程逻辑单元组合起来形成大型的逻辑电路。
3.2 可编程的io
任何芯片都必然有输入引脚和输出引脚。有可编程的io可以任意的定义某个非专用引脚(fpga中有专门的非用户可使用的测试、下载用引脚)为输入还是输出,还可以对io的电平标准进行设置。
总归一句话,fpga之所以可编程是因为可以通过特殊的01代码制作成一张张 “真值表”,并将这些“真值表”组合起来以实现大规模的逻辑功能。
不了解fpga内部结构,就不能明白最终代码如何变到fpga里面去的,也就无法深入的了解如何能够充分运用fpga。现在的fpga,不单单是有前面讲的那三块,还有很多专用的硬件功能单元,如何利用好这些单元实现复杂的逻辑电路设计,是从菜鸟迈向高手的路上必须要克服的障碍。而这一切,还是必须先从了解fpga内部逻辑及其工作原理做起。
3.3 错误理解hdl语言,怎么看都看不出硬件结构
hdl语言的英语全称是:hardware deion language,注意这个单词deion,而不是design。老外为什么要用deion这个词而不是design呢?因为hdl确实不是用用来设计硬件的,而仅仅是用来描述硬件的。
描述这个词精确地反映了hdl语言的本质,hdl语言不过是已知硬件电路的文本表现形式而已,只是将以后的电路用文本的形式描述出来而已。而在编写语言之前,硬件电路应该已经被设计出来了。语言只不过是将这种设计转化为文字表达形式而已。
硬件设计也是有不同的抽象层次,每一个层次都需要设计。最高的抽象层次为算法级、然后依次是体系结构级、寄存器传输级、门级、物理版图级。
使用hdl的好处在于我们已经设计好了一个寄存器传输级的电路,那么用hdl描述以后转化为文本的形式,剩下的向更低层次的转换就可以让eda工具去做了,这就大大的降低了工作量。这就是可综合的概念,也就是说在对这一抽象层次上硬件单元进行描述可以被eda工具理解并转化为底层的门级电路或其他结构的电路。
在fpga设计中,就是在将这以抽象层级的意见描述成hdl语言,就可以通过fpga开发软件转化为上一点中所述的fpga内部逻辑功能实现形式。
hdl也可以描述更高的抽象层级如算法级或者是体系结构级,但目前受限于eda软件的发展,eda软件还无法理解这么高的抽象层次,所以hdl描述这样抽象层级是无法被转化为较低的抽象层级的,这也就是所谓的不可综合。
所以在阅读或编写hdl语言,尤其是可综合的hdl,不应该看到的是语言本身,而是要看到语言背后所对应的硬件电路结构。
3.4 fpga本身不算什么,一切皆在fpga之外
fpga是给谁用的?很多学校是为给学微电子专业或者集成电路设计专业的学生用的,其实这不过是很多学校受资金限制,买不起专业的集成电路设计工具而用fpga工具替代而已。其实fpga是给设计电子系统的工程师使用的。
这些工程师通常是使用已有的芯片搭配在一起完成一个电子设备,如基站、机顶盒、视频监控设备等。当现有芯片无法满足系统的需求时,就需要用fpga来快速的定义一个能用的芯片。
前面说了,fpga里面无法就是一些“真值表”、触发器、各种连线以及一些硬件资源,电子系统工程师使用fpga进行设计时无非就是考虑如何将这些以后资源组合起来实现一定的逻辑功能而已,而不必像ic设计工程师那样一直要关注到最后芯片是不是能够被制造出来。
本质上和利用现有芯片组合成不同的电子系统没有区别,只是需要关注更底层的资源而已。
要想把fpga用起来还是简单的,因为无非就是那些资源,在理解了前面两点再搞个实验板,跑跑实验,做点简单的东西是可以的。
而真正要把fpga用好,那光懂点fpga知识就远远不够了。因为最终要让fpga里面的资源如何组合,实现何种功能才能满足系统的需要,那就需要懂得更多更广泛的知识。
3.5 数字逻辑知识是根本
无论是fpga的哪个方向,都离不开数字逻辑知识的支撑。fpga说白了是一种实现数字逻辑的方式而已。如果连最基本的数字逻辑的知识都有问题,学习fpga的愿望只是空中楼阁而已。数字逻辑是任何电子电气类专业的专业基础知识,也是必须要学好的一门课。
如果不能将数字逻辑知识烂熟于心,养成良好的设计习惯,学fpga到最后仍然是雾里看花水中望月,始终是一场空的。
以上几条只是我目前总结菜鸟们在学习fpga时所最容易跑偏的地方,fpga的学习其实就像学习围棋一样,学会如何在棋盘上落子很容易,成为一位高手却是难上加难。要真成为李昌镐那样的神一般的选手,除了靠刻苦专研,恐怕还确实得要一点天赋。
4.1 入门首先要掌握hdl(hdl=verilog+vhdl)
第一句话是:还没学数电的先学数电。然后你可以选择verilog或者vhdl,有c语言基础的,建议选择vhdl。因为verilog太像c了,很容易混淆,最后你会发现,你花了大量时间去区分这两种语言,而不是在学习如何使用它。当然,你思维能转得过来,也可以选verilog,毕竟在国内verilog用得比较多。
接下来,首先找本实例抄代码。
抄代码的意义在于熟悉语法规则和编译器(这里的编译器是硅编译器又叫综合器,常用的编译器有:
quartus、ise、vivado、design compiler 、synopsys的vcs、iverilog、lattice的diamond、microsemi/actel的libero、synplify pro),然后再模仿着写,最后不看书也能写出来。
编译完代码,就打开rtl图,看一下综合出来是什么样的电路。
hdl是硬件描述语言,突出硬件这一特点,所以要用数电的思维去思考hdl,而不是用c语言或者其它高级语言,如果不能理解这句话的,可以看《什么是硬件以及什么是软件》。
在这一阶段,推荐的教材是《verilog传奇》、《verilog hdl高级数字设计》或者是《用于逻辑综合的vhdl》。不看书也能写出个三段式状态机就可以进入下一阶段了。
此外,你手上必须准备verilog或者vhdl的官方文档,《verilog_ieee官方标准手册-2005_ieee_p1364》、《ieee standard vhdl language_2008》,以便遇到一些语法问题的时候能查一下。
4.2 独立完成中小规模的数字电路设计
现在,你可以设计一些数字电路了,像交通灯、电子琴、dds等等,推荐的教材是夏老《verilog 数字系统设计教程》(第三版)。在这一阶段,你要做到的是:给你一个指标要求或者时序图,你能用hdl设计电路去实现它。这里你需要一块开发板,可以选altera的cyclone iv系列,或者xilinx的spantan 6。
还没掌握hdl之前千万不要买开发板,因为你买回来也没用。这里你没必要每次编译通过就下载代码,咱们用modelsim仿真(此外还有questasim、nc verilog、diamond的active-hdl、vcs、debussy/verdi等仿真工具),如果仿真都不能通过那就不用下载了,肯定不行的。
在这里先掌握简单的testbench就可以了。推荐的教材是《writing testbenches functional verification of hdl models》。
4.3 掌握设计方法和设计原则
你可能发现你综合出来的电路尽管没错,但有很多警告。这个时候,你得学会同步设计原则、优化电路,是速度优先还是面积优先,时钟树应该怎样设计,怎样同步两个异频时钟等等。
推荐的教材是《fpga权威指南》、《ip核芯志-数字逻辑设计思想》、《altera fpga/cpld设计》第二版的基础篇和高级篇两本。学会加快编译速度(增量式编译、logiclock),静态时序分析(timequest),嵌入式逻辑分析仪(signaltap)就算是通关了。如果有不懂的地方可以暂时跳过,因为这部分还需要足量的实践,才能有较深刻的理解。
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、oppo等大厂,18年进入阿里一直到现在。
深知大多数go语言工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年go语言全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

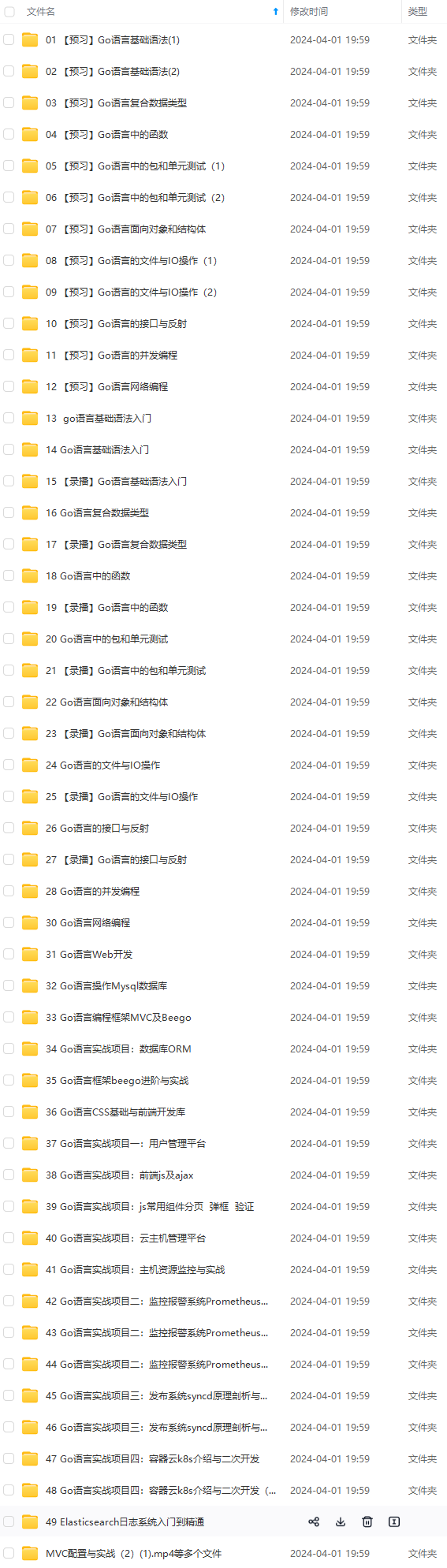
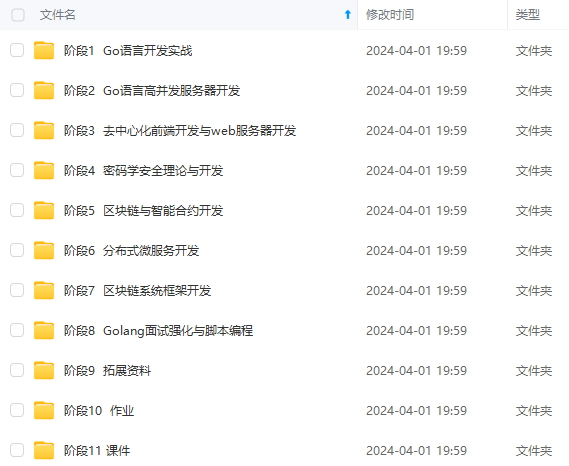
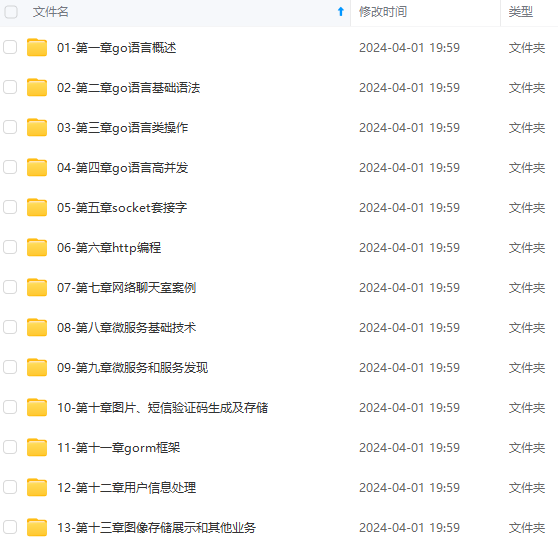
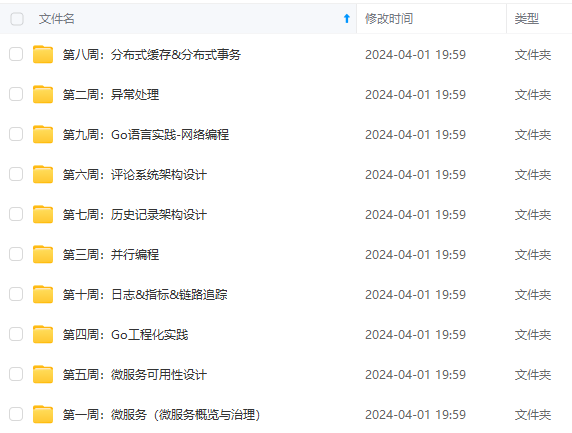
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上golang知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加v获取:vip1024b (备注go)

一个人可以走的很快,但一群人才能走的更远。不论你是正从事it行业的老鸟或是对it行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
,曾经在小公司待过,也去过华为、oppo等大厂,18年进入阿里一直到现在。**
深知大多数go语言工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年go语言全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
[外链图片转存中…(img-5yhdzkfe-1713018840298)]
[外链图片转存中…(img-s11naqnx-1713018840298)]
[外链图片转存中…(img-s80gwhxt-1713018840299)]
[外链图片转存中…(img-ilouwrux-1713018840299)]
[外链图片转存中…(img-vc7fyglr-1713018840300)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上golang知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加v获取:vip1024b (备注go)
[外链图片转存中…(img-izbkzkor-1713018840300)]
一个人可以走的很快,但一群人才能走的更远。不论你是正从事it行业的老鸟或是对it行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

发表评论