
目录
一、引言
pipeline(管道)是huggingface transformers库中一种极简方式使用大模型推理的抽象,将所有大模型分为语音(audio)、计算机视觉(computer vision)、自然语言处理(nlp)、多模态(multimodal)等4大类,28小类任务(tasks)。共计覆盖32万个模型
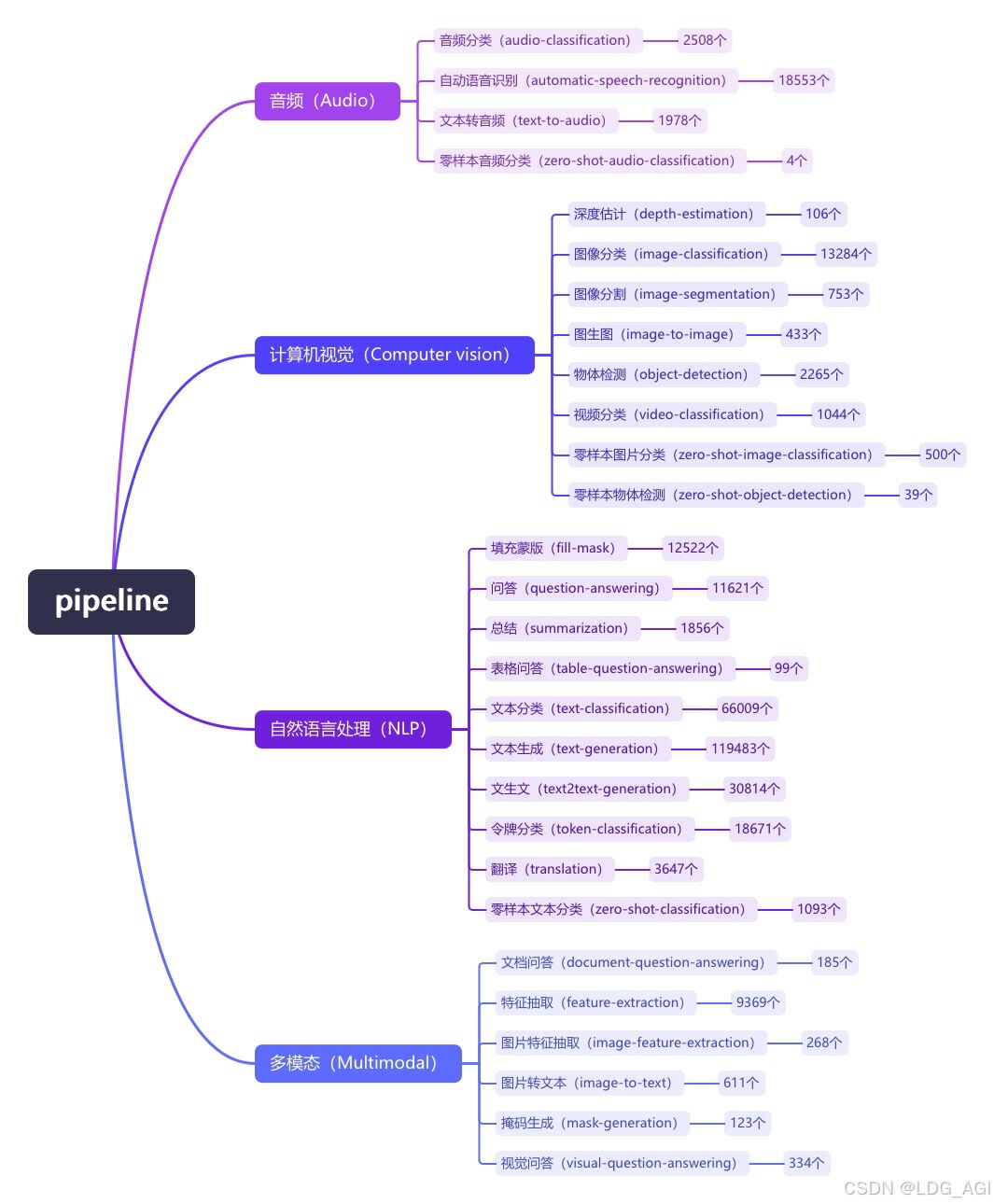
本文对pipeline进行整体介绍,之后本专栏以每个task为主题,分别介绍各种task使用方法。
二、pipeline库
2.1 概述
管道是一种使用模型进行推理的简单而好用的方法。这些管道是从库中抽象出大部分复杂代码的对象,提供了专用于多项任务的简单 api,包括命名实体识别、掩码语言建模、情感分析、特征提取和问答。在使用上,主要有2种方法
2.2 使用task实例化pipeline对象
2.2.1 基于task实例化“自动语音识别”
自动语音识别的task为automatic-speech-recognition:
import os
os.environ["hf_endpoint"] = "https://hf-mirror.com"
os.environ["cuda_visible_devices"] = "2"
from transformers import pipeline
speech_file = "./output_video_enhanced.mp3"
pipe = pipeline(task="automatic-speech-recognition")
result = pipe(speech_file)
print(result)2.2.2 task列表
task共计28类,按首字母排序,列表如下,直接替换2.2.1代码中的pipeline的task即可应用:
2.2.3 task默认模型
针对每一个task,pipeline默认配置了模型,可以通过pipeline源代码查看:
supported_tasks = {
"audio-classification": {
"impl": audioclassificationpipeline,
"tf": (),
"pt": (automodelforaudioclassification,) if is_torch_available() else (),
"default": {"model": {"pt": ("superb/wav2vec2-base-superb-ks", "372e048")}},
"type": "audio",
},
"automatic-speech-recognition": {
"impl": automaticspeechrecognitionpipeline,
"tf": (),
"pt": (automodelforctc, automodelforspeechseq2seq) if is_torch_available() else (),
"default": {"model": {"pt": ("facebook/wav2vec2-base-960h", "55bb623")}},
"type": "multimodal",
},
"text-to-audio": {
"impl": texttoaudiopipeline,
"tf": (),
"pt": (automodelfortexttowaveform, automodelfortexttospectrogram) if is_torch_available() else (),
"default": {"model": {"pt": ("suno/bark-small", "645cfba")}},
"type": "text",
},
"feature-extraction": {
"impl": featureextractionpipeline,
"tf": (tfautomodel,) if is_tf_available() else (),
"pt": (automodel,) if is_torch_available() else (),
"default": {
"model": {
"pt": ("distilbert/distilbert-base-cased", "935ac13"),
"tf": ("distilbert/distilbert-base-cased", "935ac13"),
}
},
"type": "multimodal",
},
"text-classification": {
"impl": textclassificationpipeline,
"tf": (tfautomodelforsequenceclassification,) if is_tf_available() else (),
"pt": (automodelforsequenceclassification,) if is_torch_available() else (),
"default": {
"model": {
"pt": ("distilbert/distilbert-base-uncased-finetuned-sst-2-english", "af0f99b"),
"tf": ("distilbert/distilbert-base-uncased-finetuned-sst-2-english", "af0f99b"),
},
},
"type": "text",
},
"token-classification": {
"impl": tokenclassificationpipeline,
"tf": (tfautomodelfortokenclassification,) if is_tf_available() else (),
"pt": (automodelfortokenclassification,) if is_torch_available() else (),
"default": {
"model": {
"pt": ("dbmdz/bert-large-cased-finetuned-conll03-english", "f2482bf"),
"tf": ("dbmdz/bert-large-cased-finetuned-conll03-english", "f2482bf"),
},
},
"type": "text",
},
"question-answering": {
"impl": questionansweringpipeline,
"tf": (tfautomodelforquestionanswering,) if is_tf_available() else (),
"pt": (automodelforquestionanswering,) if is_torch_available() else (),
"default": {
"model": {
"pt": ("distilbert/distilbert-base-cased-distilled-squad", "626af31"),
"tf": ("distilbert/distilbert-base-cased-distilled-squad", "626af31"),
},
},
"type": "text",
},
"table-question-answering": {
"impl": tablequestionansweringpipeline,
"pt": (automodelfortablequestionanswering,) if is_torch_available() else (),
"tf": (tfautomodelfortablequestionanswering,) if is_tf_available() else (),
"default": {
"model": {
"pt": ("google/tapas-base-finetuned-wtq", "69ceee2"),
"tf": ("google/tapas-base-finetuned-wtq", "69ceee2"),
},
},
"type": "text",
},
"visual-question-answering": {
"impl": visualquestionansweringpipeline,
"pt": (automodelforvisualquestionanswering,) if is_torch_available() else (),
"tf": (),
"default": {
"model": {"pt": ("dandelin/vilt-b32-finetuned-vqa", "4355f59")},
},
"type": "multimodal",
},
"document-question-answering": {
"impl": documentquestionansweringpipeline,
"pt": (automodelfordocumentquestionanswering,) if is_torch_available() else (),
"tf": (),
"default": {
"model": {"pt": ("impira/layoutlm-document-qa", "52e01b3")},
},
"type": "multimodal",
},
"fill-mask": {
"impl": fillmaskpipeline,
"tf": (tfautomodelformaskedlm,) if is_tf_available() else (),
"pt": (automodelformaskedlm,) if is_torch_available() else (),
"default": {
"model": {
"pt": ("distilbert/distilroberta-base", "ec58a5b"),
"tf": ("distilbert/distilroberta-base", "ec58a5b"),
}
},
"type": "text",
},
"summarization": {
"impl": summarizationpipeline,
"tf": (tfautomodelforseq2seqlm,) if is_tf_available() else (),
"pt": (automodelforseq2seqlm,) if is_torch_available() else (),
"default": {
"model": {"pt": ("sshleifer/distilbart-cnn-12-6", "a4f8f3e"), "tf": ("google-t5/t5-small", "d769bba")}
},
"type": "text",
},
# this task is a special case as it's parametrized by src, tgt languages.
"translation": {
"impl": translationpipeline,
"tf": (tfautomodelforseq2seqlm,) if is_tf_available() else (),
"pt": (automodelforseq2seqlm,) if is_torch_available() else (),
"default": {
("en", "fr"): {"model": {"pt": ("google-t5/t5-base", "686f1db"), "tf": ("google-t5/t5-base", "686f1db")}},
("en", "de"): {"model": {"pt": ("google-t5/t5-base", "686f1db"), "tf": ("google-t5/t5-base", "686f1db")}},
("en", "ro"): {"model": {"pt": ("google-t5/t5-base", "686f1db"), "tf": ("google-t5/t5-base", "686f1db")}},
},
"type": "text",
},
"text2text-generation": {
"impl": text2textgenerationpipeline,
"tf": (tfautomodelforseq2seqlm,) if is_tf_available() else (),
"pt": (automodelforseq2seqlm,) if is_torch_available() else (),
"default": {"model": {"pt": ("google-t5/t5-base", "686f1db"), "tf": ("google-t5/t5-base", "686f1db")}},
"type": "text",
},
"text-generation": {
"impl": textgenerationpipeline,
"tf": (tfautomodelforcausallm,) if is_tf_available() else (),
"pt": (automodelforcausallm,) if is_torch_available() else (),
"default": {"model": {"pt": ("openai-community/gpt2", "6c0e608"), "tf": ("openai-community/gpt2", "6c0e608")}},
"type": "text",
},
"zero-shot-classification": {
"impl": zeroshotclassificationpipeline,
"tf": (tfautomodelforsequenceclassification,) if is_tf_available() else (),
"pt": (automodelforsequenceclassification,) if is_torch_available() else (),
"default": {
"model": {
"pt": ("facebook/bart-large-mnli", "c626438"),
"tf": ("facebookai/roberta-large-mnli", "130fb28"),
},
"config": {
"pt": ("facebook/bart-large-mnli", "c626438"),
"tf": ("facebookai/roberta-large-mnli", "130fb28"),
},
},
"type": "text",
},
"zero-shot-image-classification": {
"impl": zeroshotimageclassificationpipeline,
"tf": (tfautomodelforzeroshotimageclassification,) if is_tf_available() else (),
"pt": (automodelforzeroshotimageclassification,) if is_torch_available() else (),
"default": {
"model": {
"pt": ("openai/clip-vit-base-patch32", "f4881ba"),
"tf": ("openai/clip-vit-base-patch32", "f4881ba"),
}
},
"type": "multimodal",
},
"zero-shot-audio-classification": {
"impl": zeroshotaudioclassificationpipeline,
"tf": (),
"pt": (automodel,) if is_torch_available() else (),
"default": {
"model": {
"pt": ("laion/clap-htsat-fused", "973b6e5"),
}
},
"type": "multimodal",
},
"image-classification": {
"impl": imageclassificationpipeline,
"tf": (tfautomodelforimageclassification,) if is_tf_available() else (),
"pt": (automodelforimageclassification,) if is_torch_available() else (),
"default": {
"model": {
"pt": ("google/vit-base-patch16-224", "5dca96d"),
"tf": ("google/vit-base-patch16-224", "5dca96d"),
}
},
"type": "image",
},
"image-feature-extraction": {
"impl": imagefeatureextractionpipeline,
"tf": (tfautomodel,) if is_tf_available() else (),
"pt": (automodel,) if is_torch_available() else (),
"default": {
"model": {
"pt": ("google/vit-base-patch16-224", "3f49326"),
"tf": ("google/vit-base-patch16-224", "3f49326"),
}
},
"type": "image",
},
"image-segmentation": {
"impl": imagesegmentationpipeline,
"tf": (),
"pt": (automodelforimagesegmentation, automodelforsemanticsegmentation) if is_torch_available() else (),
"default": {"model": {"pt": ("facebook/detr-resnet-50-panoptic", "fc15262")}},
"type": "multimodal",
},
"image-to-text": {
"impl": imagetotextpipeline,
"tf": (tfautomodelforvision2seq,) if is_tf_available() else (),
"pt": (automodelforvision2seq,) if is_torch_available() else (),
"default": {
"model": {
"pt": ("ydshieh/vit-gpt2-coco-en", "65636df"),
"tf": ("ydshieh/vit-gpt2-coco-en", "65636df"),
}
},
"type": "multimodal",
},
"object-detection": {
"impl": objectdetectionpipeline,
"tf": (),
"pt": (automodelforobjectdetection,) if is_torch_available() else (),
"default": {"model": {"pt": ("facebook/detr-resnet-50", "2729413")}},
"type": "multimodal",
},
"zero-shot-object-detection": {
"impl": zeroshotobjectdetectionpipeline,
"tf": (),
"pt": (automodelforzeroshotobjectdetection,) if is_torch_available() else (),
"default": {"model": {"pt": ("google/owlvit-base-patch32", "17740e1")}},
"type": "multimodal",
},
"depth-estimation": {
"impl": depthestimationpipeline,
"tf": (),
"pt": (automodelfordepthestimation,) if is_torch_available() else (),
"default": {"model": {"pt": ("intel/dpt-large", "e93beec")}},
"type": "image",
},
"video-classification": {
"impl": videoclassificationpipeline,
"tf": (),
"pt": (automodelforvideoclassification,) if is_torch_available() else (),
"default": {"model": {"pt": ("mcg-nju/videomae-base-finetuned-kinetics", "4800870")}},
"type": "video",
},
"mask-generation": {
"impl": maskgenerationpipeline,
"tf": (),
"pt": (automodelformaskgeneration,) if is_torch_available() else (),
"default": {"model": {"pt": ("facebook/sam-vit-huge", "997b15")}},
"type": "multimodal",
},
"image-to-image": {
"impl": imagetoimagepipeline,
"tf": (),
"pt": (automodelforimagetoimage,) if is_torch_available() else (),
"default": {"model": {"pt": ("caidas/swin2sr-classical-sr-x2-64", "4aaedcb")}},
"type": "image",
},
}2.3 使用model实例化pipeline对象
2.3.1 基于model实例化“自动语音识别”
如果不想使用task中默认的模型,可以指定huggingface中的模型:
import os
os.environ["hf_endpoint"] = "https://hf-mirror.com"
os.environ["cuda_visible_devices"] = "2"
from transformers import pipeline
speech_file = "./output_video_enhanced.mp3"
#transcriber = pipeline(task="automatic-speech-recognition", model="openai/whisper-medium")
pipe = pipeline(model="openai/whisper-medium")
result = pipe(speech_file)
print(result)2.3.2 查看model与task的对应关系
可以登录https://huggingface.co/tasks查看

三、总结
本文为transformers之pipeline专栏的第0篇,后面会以每个task为一篇,共计讲述28+个tasks的用法,通过28个tasks的pipeline使用学习,可以掌握语音、计算机视觉、自然语言处理、多模态乃至强化学习等30w+个huggingface上的开源大模型。让你成为大模型领域的专家!
期待您的3连+关注,如何还有时间,欢迎阅读我的其他文章:
《ai—工程篇》
ai智能体研发之路-工程篇(一):docker助力ai智能体开发提效
ai智能体研发之路-工程篇(二):dify智能体开发平台一键部署
ai智能体研发之路-工程篇(三):大模型推理服务框架ollama一键部署
ai智能体研发之路-工程篇(四):大模型推理服务框架xinference一键部署
ai智能体研发之路-工程篇(五):大模型推理服务框架localai一键部署
《ai—模型篇》
ai智能体研发之路-模型篇(一):大模型训练框架llama-factory在国内网络环境下的安装、部署及使用
ai智能体研发之路-模型篇(二):deepseek-v2-chat 训练与推理实战
ai智能体研发之路-模型篇(四):一文入门pytorch开发
ai智能体研发之路-模型篇(五):pytorch vs tensorflow框架dnn网络结构源码级对比
ai智能体研发之路-模型篇(六):【机器学习】基于tensorflow实现你的第一个dnn网络
ai智能体研发之路-模型篇(七):【机器学习】基于yolov10实现你的第一个视觉ai大模型
ai智能体研发之路-模型篇(八):【机器学习】qwen1.5-14b-chat大模型训练与推理实战
ai智能体研发之路-模型篇(九):【机器学习】glm4-9b-chat大模型/glm-4v-9b多模态大模型概述、原理及推理实战
《ai—transformers应用》
【ai大模型】transformers大模型库(一):tokenizer
【ai大模型】transformers大模型库(二):automodelforcausallm
【ai大模型】transformers大模型库(三):特殊标记(special tokens)
【ai大模型】transformers大模型库(四):autotokenizer
【ai大模型】transformers大模型库(五):automodel、model head及查看模型结构



发表评论