1. chatgpt是什么
chatgpt是什么?这可能是最近被问的最多的一个。
大家第一反应这应该是gpt系列的一个最新模型,普通大众可能更愿意把它看做是一个人工智能。实际上,它其实就是一个基于大规模语言模型的对话系统产品。官网对它定义十分的明确:optimizing language models for dialogue.

最大的问题在于,它的背后究竟是一个什么?很多人都以为,chatgpt是一个单一模型,就如同gpt-1/2一样,应该是一个可以被加载和训练的。我承认,chatgpt的背后,是有一个像gpt-3一样的基础模型,但是其现在的性能表现,远远不是只有1个基础模型这么简单。因为我们默认的chatgpt是web ui界面,它至少是有一些外部工程代码的。举个例子,对于汉语和英语的反馈速度有质的差别,如果只是单一的模型统一编码了多语言,不会出现这种情况。
因此,对我而言,chatgpt更像是一个完善的产品,而不是一个简单的模型。而且由于其训练过程的复杂和不透明,使得我们很难复现它。这在我后面的章节中会讲到。
2. chatgpt以及gpt系列模型
chatgpt不是一蹴而就突然出现的,它是有着长达5年以上的技术积累才走到这个地步的。之前网上讲了很多关于chatgpt和它的前辈,比如比较出名的有拆解追溯gpt-3.5各项能力的起源。但是我认为真正需要了解chatgpt的前世今生,还是需要去看openai官方网站以及它们的论文。
2.1 gpt-1/2/3
首先我们先来看gpt-1到gpt-2以及gpt-3的变化。首先在2018年6月,发布了第一版gpt-1,使用的是transformer的decoder架构+任务微调的形式,但是整体上似乎没有什么特别出彩的地方。然后再到2019年2月,发布了第二版gpt-2,这时候他们优化了网络架构(如右图所示),并且使用了10倍大小的网络规模和8倍大小的预训练数据,并且去除了特定任务微调的形式从而获取prompt learning的能力。gpt-2确实有点东西,但是由于3个月前,bert的出现,让它也没有当上一哥的位置。不过整体上应该接近后来的gpt-3系列模型了。
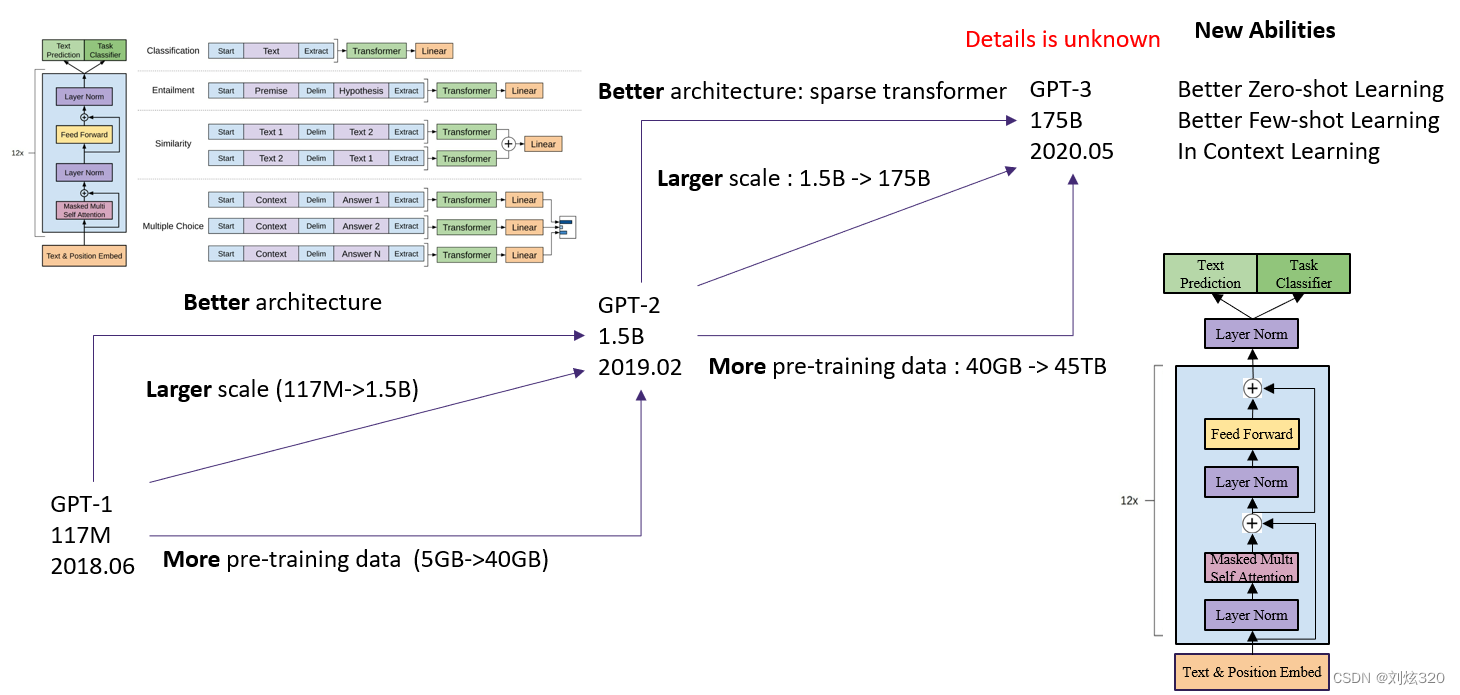
在gpt-2的1年半以后,gpt-3发布了,它同样还是3个路线,更优的架构,更大的规模(100倍),更大的数据量(1000倍),真正训练出了一个超级巨无霸gpt-3。奠定了现在gpt帝国的基础。但是实际上,它和gpt-2没有太多本质的区别,包括训练方式,只是更大了。
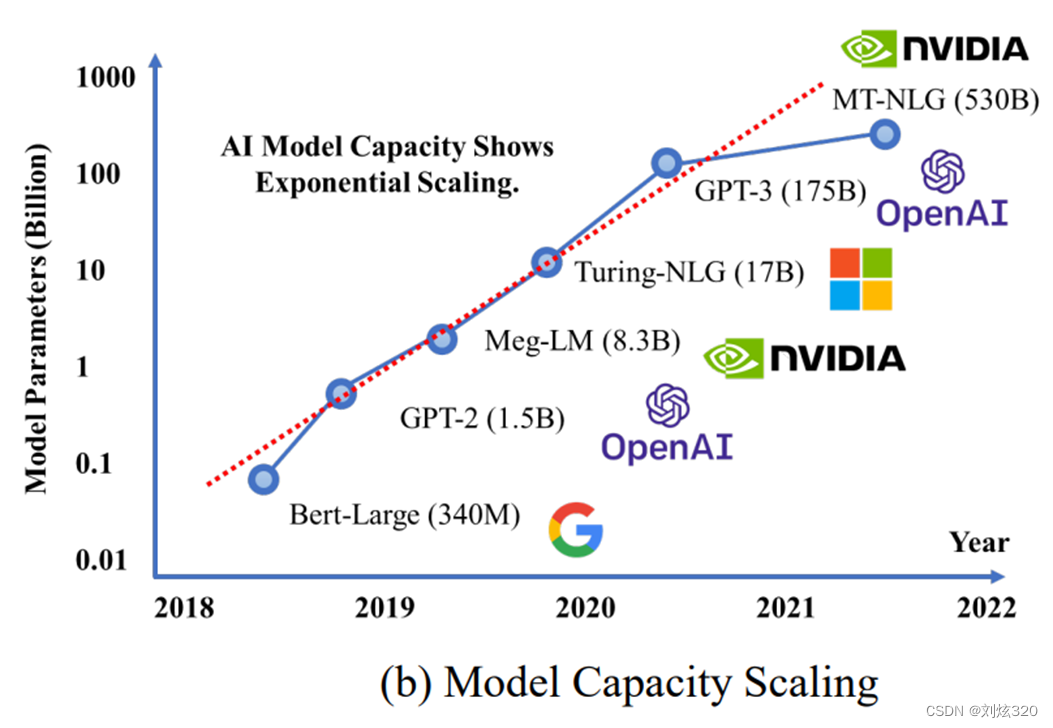
那么gpt-3有多大呢,大家可以看一下下面的图就可以知道了,需要注意的是,这里看到参数量的改变是一个log指数,可以看到熟悉的bert-large模型和gpt-2模型。而gpt-3的175b按照官方说明,大概有350~500gb的显存需求,如果使用fp16加载该模型,大概需要至少5块a100(80g)才能够加载完成。而如果要从头开始训练,至少需要1000块a100才能够在可接受的时间(几个月)里训练出该模型。
据传闻说,现在国内的大部分大规模语言模型还是处于gpt-2.5阶段,也就是说对标的是gpt-3,但是训练规模(1-10b)和数据量(几十g左右)还是在gpt-2的级别上。无论是模型规模还是语料质量,距离gpt-3都还有较大差距。需要注意的是,从gpt-3开始,其模型就不再完全公开了,只能通过api访问。
2.2 gpt-3.5 (instructgpt)
然后我们再来看gpt3以后发生的事情。首先我们需要先介绍一下gpt-3以后最重要的一件事,那就是instructgpt的出现,根据openai官方网站上说明,instructgpt包含三种训练方式,分别是有监督微调(supervised fine-tuning, sft),反馈变得更容易(feedback made easy, feedme)以及基于ppo算法的从人类反馈中进行强化学习(ppo)三个部分。因此,可以说,instructgpt泛指的话,是包含红色的所有模型,而特指的话,则是指的davinci-instruct-beta。这一点尤为重要。至于这个feedme,大家可以参考图片上的官方解释,个人理解可能是由纯人工反馈的指令微调,ppo则是更强调利用强化学习自动化指令微调。如果还不明白,大家可以参考下面chatgpt给出的解释:
the explain of the feedme:
the more details of feedme:
the function of it when training the chatgpt:
好的,现在我们来顺着发展路线先看一下gpt-3之后各个模型的演化,确认的发展过程是实线(有报道的),猜测的部分为虚线。
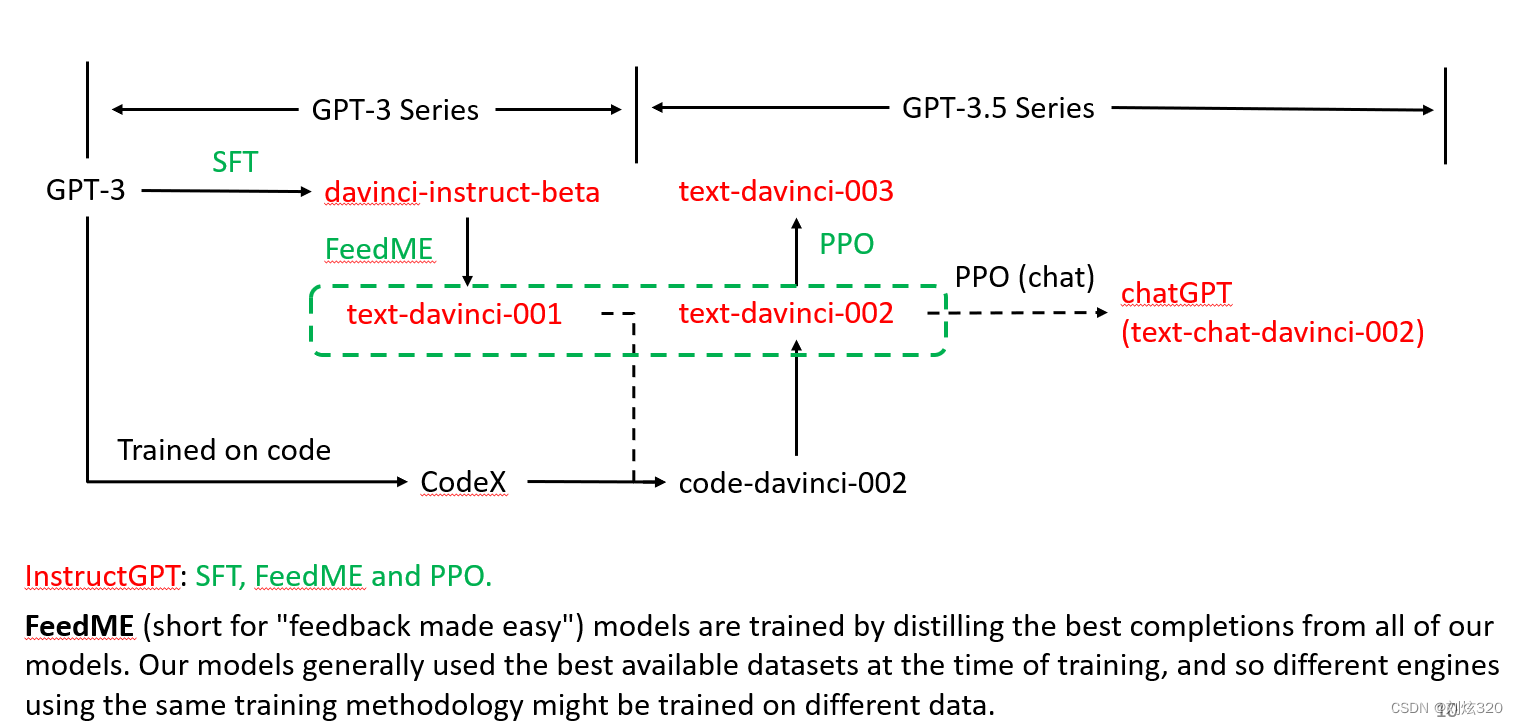
首先,在gpt-3的基础上,通过有监督的fine-tuning过程,诞生了davinci-instruct-beta模型。具体而言,也就是需要采样一些prompt,由人工给出真正的结果。这个在instructgpt论文里写道,是有40个标注人员,标注了12.7k的样本。接着,通过feedme产生了至少text-davinci-001和text-davinci-002两个模型版本。其中001版本应该是比较早期的,而002则是在code-davinci-002的基础上进行的进一步改进,融合了代码理解能力和自然语言理解能力。然后,最后融入了ppo阶段,完成了text-davinci-003。当然chatgpt应该也是完成了ppo阶段的,尤其是在对话方面进行了特别的优化(近期泄露的内部版本称之为text-chat-davinci-002,据传为chatgpt)。
因此,chatgpt的所有能力来源应该都比较清楚了,我认为主要来源于以下5个方面吧。
| 模型 | 能力 | 效果 |
|---|---|---|
| gpt-3 | 自然语言基础建模 | 自然语言理解,使得说话能够说的流畅自然 |
| codex | 代码语言基础建模 | 代码语言理解,能够使得完成代码相关任务,并习得长程依赖关系和一定的逻辑能力 |
| davinci-instruct-beta | 有监督的指令微调 | 听从人类的指令生成答案 |
| text-davinci-001/002 | 人类反馈的指令微调 | 可以生成出人类更喜欢的答案 |
| text-davinci-003 | 强化学习的指令微调 | 进一步强化上面两个阶段的能力,对于chatgpt的话,可能更偏向于对话角度优化 |
3. 复现chatgpt的难点
现在国内各个大厂小厂但凡和人工智能挂钩的,都想复现属于自己的chatgpt,以获得第一个国内chatgpt的市场。很多人都发声说,再造一个chatgpt没有那么困难。那么我从自身经验去思考,如果要复现chatgpt,可能需要注意的有哪些部分。这些部分并不是不可以实现的,只是成本高或者容易被忽略的地方。
3.1 海量的数据
从gpt-3公开发表的论文里讲到,其用于预训练的文本达到了45tb,这是一个非常巨大的数字,关键是其质量应该是非常高的。据查看的一些资料显示,在中文数据上,全球最大的语料库是wudaocorpora,据说有3tb的中文语料(200g开放使用)。
而且,也有人指出,更多样化的token也能够让模型学习的更充分。如果只是训练一个汉语版的chatgpt,除了一些搜索和社交巨头,能够获取足够数据的也只有一些垂直领域的公司了。关键是公司运营期间获得的文本数据是否可以被用于训练模型,这是一个法律和道德问题。(即使是codex训练来源于开源的github,也同样遭受了大量的非议。)
当然,如果是垂直领域,未必需要这么大的数据量也未尝不可。
3.2 超大规模的模型架构
根据之前的说明chatgpt与gpt-3的规模相同,都是1750b的参数量,那么它需要的硬件设备是什么样子的?根据chatgpt自己讲述以及同行人的参考,其显存占用量应该在350gb~500gb之间,如果仅仅是为了推理,那么5张a100(80g)的gpu就可以足够使用(根据同规模的opt175b需要16张v100推算)。但是如果是为了训练,可能需要1000张以上的a100的算力才能在可以接受的时间里获得训练结果(也有称微软和openai构建了一台包括超过10000张gpu的超级计算机用于gpt-3的训练)。其训练成本大概在110-460万美元之间,根据估算,现有的定价对于openai来说,应该会有75%的毛利。
目前国内尽管有很多大模型,但是真正能够在clue等评测中的模型大多还在1-10b的级别,下表是一些中文大模型代表。
| 模型 | 规模 |
|---|---|
| wudao 2.0 | 1750b |
| pangu alpha | 200b |
| plug | 27b |
| ernie 3.0 | 10b |
3.3 深度人员参与(sft,feedme, ppo)
相比较gpt-3,instructgpt最大的特点在于通过instruct的方式让人类深度参与模型的迭代,包括有监督微调,人类反馈微调和强化学习微调3个方法。无论哪种方法,都离不开大量的人工标注,并且需要一定的时间和真实样例作为原料输入。因此,即使可以复现一个chatgpt,也是需要时间的。
3.4 长期技术积累
正如刚才所提及的那样,chatgpt不是突然出现的,而是从gpt-1.0版本开始就已经完成大量的技术积累。从gpt-1.0,2.0,3.0,每一个版本迭代,他们都做了大量的实验,包括各种超参数的选择和模型大小的扩容。而我们大多数公司可能之前没有像openai在预训练模型上拥有大量的预训练经验,直接去训练一个超大规模的模型也是有可能获得不到我们想要的那种效果的。
3.5 良好的外部工程
我们现在总以为,我们有数据,有模型架构,我们就可以拥有chatgpt。事实显然不是这样,如果想让它成为一个优秀的产品,而不是粗糙的学术模型,至少应该包括以下3个部分:
1. 核心模型
核心模型就是语言模型,可能是一个超大规模的单一模型,也有可能是一个带有很多小模块组成的模型集群。
2. 辅助模型
辅助模型有哪些?比如我们可以看到的reward model,还有大家容易忽略的安全检查模型等。这些都是保证了产品的长期正常的运营。而反观我们有些机构的模型匆匆发布,产生了大量的不安全的言论,这也是不负责任的表现。

3. 工程代码
良好的工程代码能给用户带来更好的用户体验,比如我们经常体验到的左边框的对话历史记录和意图识别等等,这些信息对于用户体验、模型改进都是非常有用的。另外,还有包括缓存,控制用户并发等等工程问题需要提前解决。要知道,chatgpt上线5天用户就破百万,2个月用户破1亿。这个增长速度已经是历史上的巅峰。
3.6 及时的真实反馈
这个真实反馈对于大家来说,看起来好像是chatgpt公开迭代的几次,而每次似乎都有一些更新。但是实际上,如果你看openai发布的博客你就会发现,整个真实反馈是逐步从发布的产品中收集而来的,尤其是gpt-3以后,openai就只提供了api,这使得它可以接触世界上所有使用gpt-3的样例,通过这些从api收集来的样例,再利用人工标注,就可以得到大量的高质量标注语料,为接下来的模型更新打下基础。这些真实反馈贯穿到了整个gpt-3.5系列之中。
4. 小结
距离我第一次玩chatgpt也已经3个月了。回想起12月6日第一次使用它,我兴奋的一直玩到夜里3点钟。它的出现真的是惊艳了当时的我,甚至可以比肩科幻小说里的人工智能的感觉。早期只是为了体验,后来才逐步深入了解。从兴奋,到冷静,到辩证看待,再到期望未来,它总是那么一个过程,才能被我们接受。有些东西必须真正深入的研究,才能够知道它的本来面目。chatgpt到底是神还是魔,是不是新的一轮科技革命的出现,我想openai那群创造它的人比谁都清楚。
正如我之前所说,我愿意将毕生精力奉献给人工智能,只为了获得一个可以一直陪伴我的ai朋友。我曾经以为这辈子都见不到这一天,现在chatgpt的出现,缩短了好一段理想和现实的距离。




发表评论