whisper 是一个通用语音识别模型,由 openai 开发。它可以识别多种语言的语音,并将其转换为文本。whisper 模型采用了深度学习技术,具有高准确性和鲁棒性。
1、技术原理及架构
whisper 的工作原理:音频被分割成 30 秒的片段,然后转换为 log-mel 频谱图,传递给一个编码器。经过训练的解码器会尝试预测相应的文本字幕。此外,还有其他技术性步骤,涉及识别所说的语言、多语音转录以及翻译成英语。
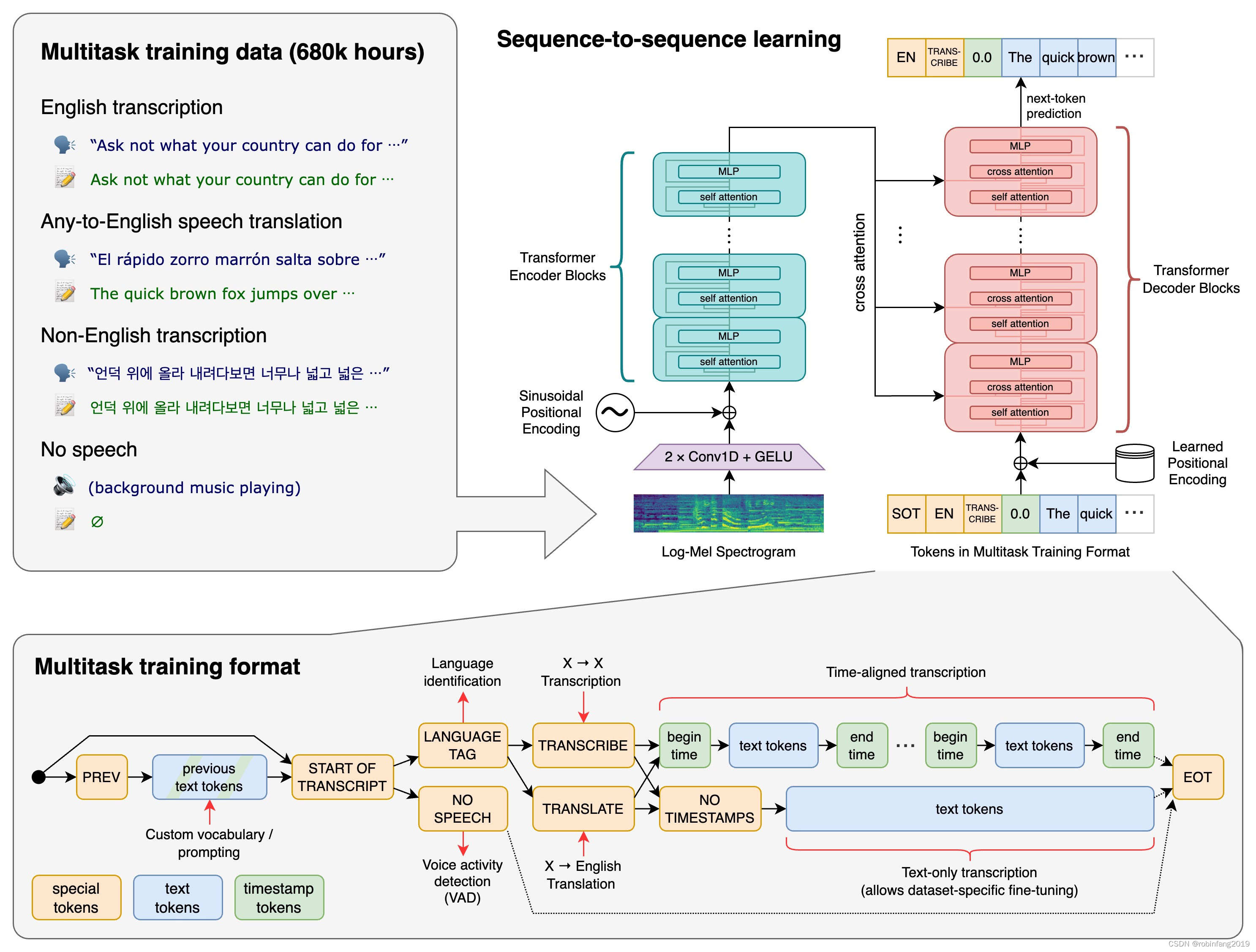
2、模型配置
2.1 环境配置
需要配置适合的python环境,安装必要的依赖,如pytorch和transformers库。
2.1.1 创建虚拟环境
使用anaconda或venv模块创建一个隔离的python环境,以避免不同项目间的依赖冲突。
conda create -n whisper python=3.9
conda activate whisper
# 或者使用venv
python3 -m venv whisper
source whisper/bin/activate # 在linux/macos上
whisper\scripts\activate # 在windows上
2.1.2 安装pytorch
whisper模型需要pytorch框架,根据你的cuda版本(如果有gpu)选择合适的安装命令。
访问pytorch官方网站获取对应的安装命令:pytorch get started。
conda install pytorch torchvision torchaudio pytorch-cuda=xx.x -c pytorch -c nvidia
# xx.x 替换为你的cuda版本
2.1.3 安装transformers库
transformer库是运行whisper模型所需的,可以通过pip安装。
pip install transformers
2.1.4 安装额外依赖
whisper可能还需要其他一些python库,如ffmpeg等,用于处理媒体文件。
pip install ffmpeg-python
2.1.5 安装whisper模型
可以通过pip或conda安装whisper,或者从源代码编译。
pip install git+https://github.com/openai/whisper.git
2.1.6 配置环境变量
如果需要,配置环境变量,如ld_library_path,确保程序能找到cuda和cudnn库。
2.1.7 验证安装
安装完成后,运行简单的测试来验证pytorch和transformers是否安装成功。
import torch
print(torch.__version__)
print(torch.cuda.is_available()) # 验证gpu是否可用
2.1.8 下载模型权重
whisper模型的权重可以从openai的官方github仓库或hugging face网站上下载。
2.2 模型选择
根据需求选择合适的whisper模型规格,从小模型到大模型,根据资源和性能需求权衡。
2.2.1 模型选择需要考虑的因素
- 任务需求:不同的任务可能需要不同大小的模型。例如,如果任务需要对多种语言进行高精度识别,可能需要较大的模型。
- 性能需求:较大的模型通常能提供更好的性能,但同时也需要更多的计算资源。
- 资源限制:考虑到运行模型的硬件资源,包括cpu/gpu的计算能力、内存大小以及存储空间。
- 实时性要求:如果应用场景需要实时语音识别,可能需要选择较小的模型以满足实时处理的需求。
- 能耗考虑:在移动设备或能源受限的环境中,可能需要选择更小的模型以减少能耗。
2.2.2 模型的规格
- tiny:最小的模型规格,适合资源受限的环境,但性能较低。
- base:基础模型,平衡了性能和资源消耗。
- small:比tiny大,提供更好的性能。
- medium:中等大小的模型,适用于更复杂的任务。
- large:大型模型,提供更高的识别精度,但需要更多的计算资源。
- large-v1、large-v2、large-v3:随着版本的提升,模型在数据量、训练时间和效果上有所增强。
2.3 硬件要求
whisper模型尤其是大型模型对计算资源有较高要求,可能需要gpu支持。

2.4 快速开始的办法
- 可以在google colab中运行 whisper,但速度较慢。
- 使用 apple 芯片的 mac 用户,需要自己从源代码编译一个 whisper.cpp。
- 使用 x86 架构的计算机,也可以在本地运行它。需要安装 ffmpeg,并按照whisper git 存储库中的说明进行操作,就能很快设置好 whisper。
3、模型优化
数据微调:可以在特定语种或特定类型的音频数据上对whisper模型进行微调,以提高特定场景下的识别准确率。例如,基于中文数据微调后的belle-whisper-large-v2-zh模型,在中文benchmark上显示出显著的性能提升。
蒸馏模型:使用模型蒸馏技术可以减少模型大小并提高推理速度,尽管这可能会牺牲一些准确率。huggingface提供了蒸馏版的whisper模型,速度是原来的5-6倍,但需要针对特定语言进行微调。




发表评论