网络爬虫
爬虫的合法性
在使用爬虫时候,我们需要谨记三点:
1、 遵守 robots 协议(君子协议):
2、不能造成对方服务器瘫痪。
3、不能非法获利
爬虫为什么选择python:
1、简单易学。python作为动态语言更适合初学者。python可以让初学者把精力集中在编程对象和思维方法上,而不用去担心语法、类型等,并且python语法清晰简洁,调试起来比java简单的多。
2、稳定。python的强大架构可以使爬虫程序高效平稳地运行。
3、免费开源。python是floss(自由/开放源码软件)之一。使用者可以自由地发布这个软件的拷贝、阅读它的源代码、对它做改动、把它的一部分用于新的自由软件中。
4、速度快。python的底层是用c语言写的,很多标准库和第三方库也都是用c写的,运行速度非常快。
5、可拓展性。如果需要一段关键代码运行得更快,可以部分程序用c或c++编写,然后在python程序中使用它们,因此python适合一些可扩展的后台应用。
6、多线程。爬虫是一个典型的多任务处理场景,请求页面时会有较长的延迟,总体来说更多的是等待。python多线程或进程会更优化程序效率,提升整个系统下载和分析能力。
http协议
工作原理:
http协议定义web客户端如何从web服务器请求web页面,以及服务器如何把web页面传送给客户端。http协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、url、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。

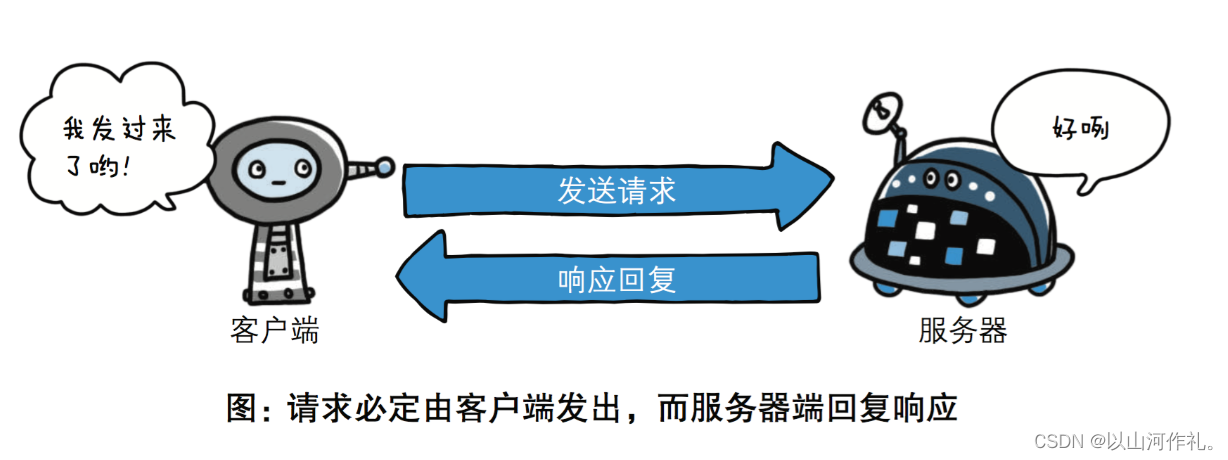
请求与响应(重点)
'''
请求
请求行 请求方式 (get,post)请求地址(url)-》 协议(http)
请求头 -》 放在服务器上要使用的信息,爬虫需要的重要内容(头部,cookie,)
请求体 -》一般放一些参数(get,post)
响应
状态行 -》协议 状态码 (100)
响应头 -》放在客户端上要使用的信息
响应体 —》返回客户端上的数据(html页面,json数据等)
'''
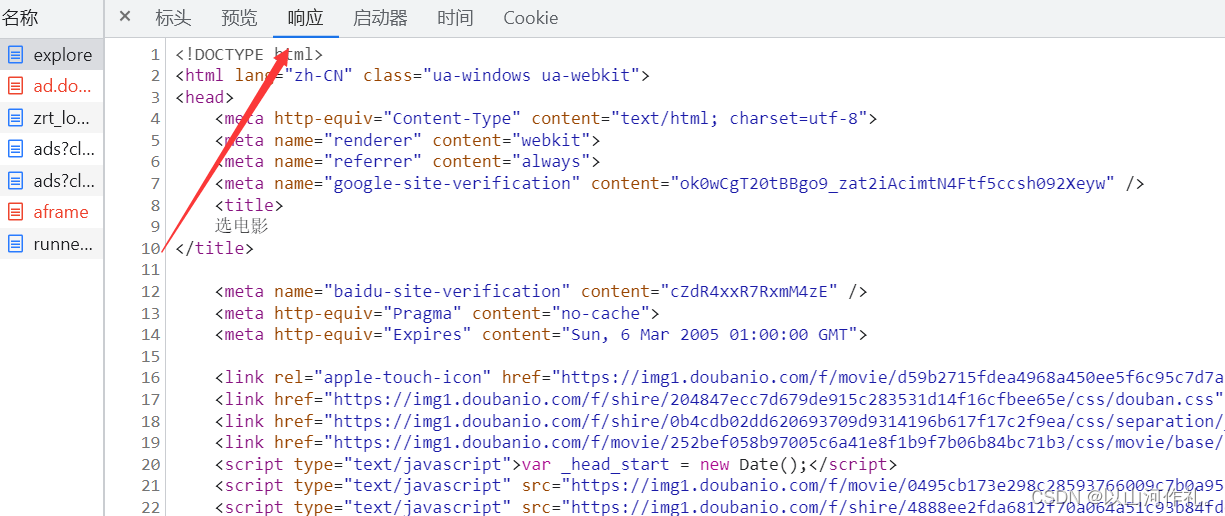
以淘宝网页版举例:
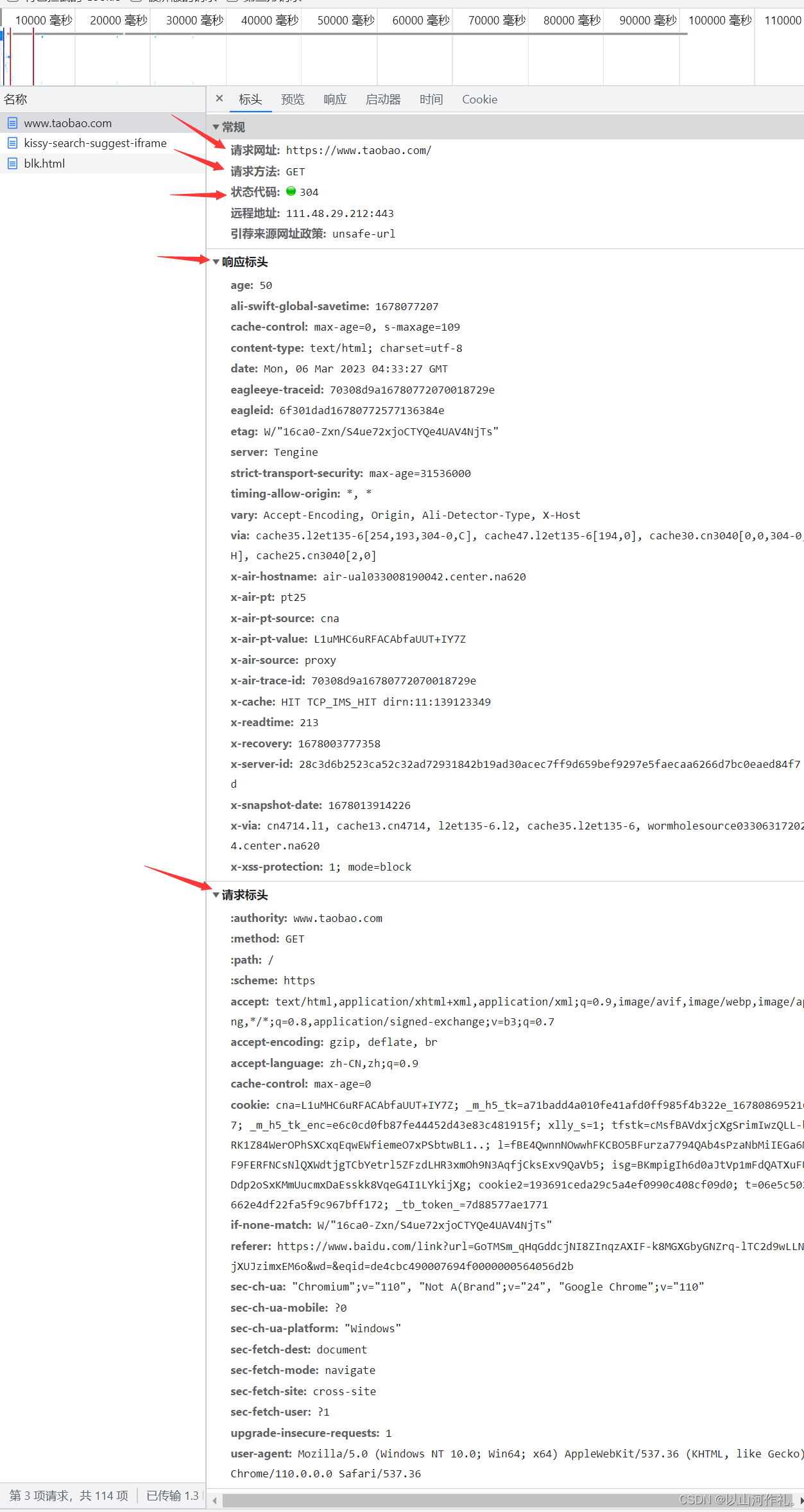
响应体:
状态码:
cookie与session id
cookie
session id
保存sessionid的方式:
悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。
发表评论