k8s pod 基本使用
pod基本概念
pods是在kubernetes集群中创建和管理最小的部署单元,一个pod内部可以运行一个或多个容器,多个容器之间具共享的存储和网络资源,共享运行上下文。pod共享运行时上下文是通过linux 命名空间实现,不同的命名空间存储、网络、cpu相互隔离。pod基于docker容器进一步进行了抽象,类似于一组具有共享命名空间、共享文件存储的容器组。
使用pod
-
pod 模版文件
# 版本信息 apiversion: v1 # 对象类型 kind: pod # pod 元数据定义 metadata: name: nginx spec: # docker 镜像定义 containers: - name: nginx image: nginx:1.14.2 ports: - containerport: 80 -
创建pod
# 根据配置文件创建或更新一个pod对象 kubectl apply -f https://k8s.io/examples/pods/simple-pod.yaml -
查看pod
kubectl get po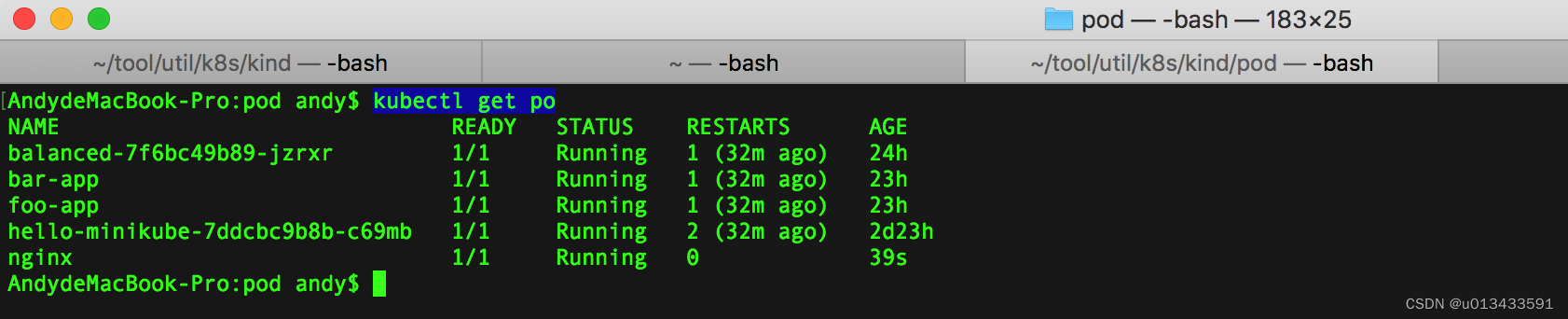
-
查看pod日志
# kubectl logs pod-name kubectl logs balanced-7f6bc49b89-jzrxr
-
查看pod详细信息
# nginx 为pod的名称 kubectl describe pods/nginx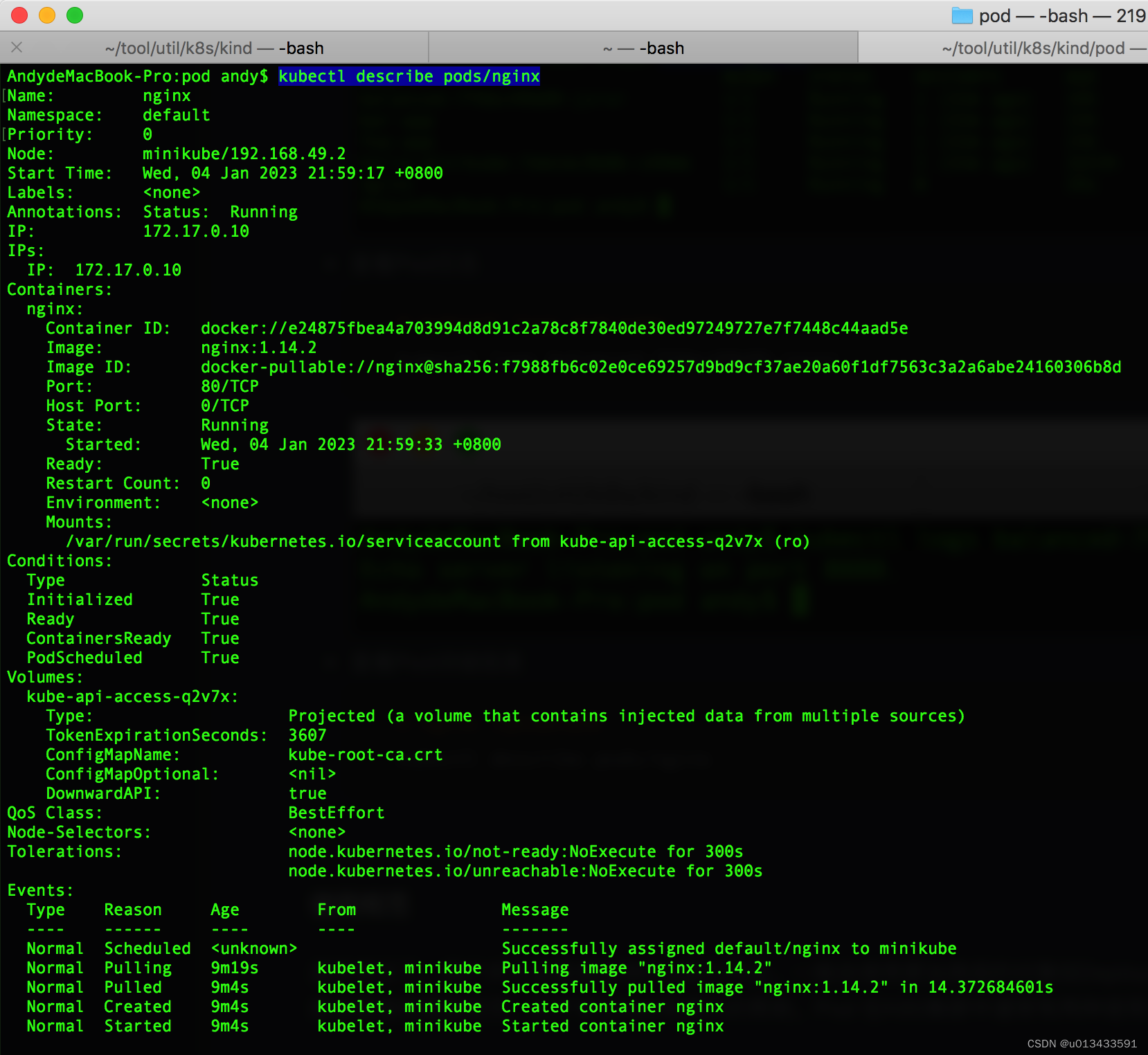
使用规范
通常情况下,用户并不会直接使用pod进行作业。一般会使用更加高级的对象如deployment、rs、rc进行作业。即便如此,学习pod的底层原理和使用规范,对于学习k8s有很大的帮助。pod 在k8s集群中通常有两种使用方式
- pod 运行单个容器 - “每个pod一个容器”模型是最常见的kubernetes用例;在这种情况下,您可以将pod视为单个容器的包装器;kubernetes管理pods,而不是直接管理容器。
- pod 运行多个容器 - 运行需要一起工作的多个容器的pod。pod可以封装由多个紧密耦合且需要共享资源的位于同一位置的容器组成的应用程序。这些位于同一位置的容器形成了一个统一的服务单元,pod将这些容器、存储资源和短暂的网络标识包装为一个单元。
pod生命周期
运行阶段
pod的状态字段是一个podstatus对象,它有一个阶段字段。pod的阶段是对pod在其生命周期中所处位置的简单、高级概括。
| value | description |
|---|---|
pending | 挂起阶段,pod已被k8s系统接收,但仍有一个或者多个容器未被创建,可以通过kubectl describe 查看pending 状态原因 |
running | 运行阶段,pod已经被绑定到一个节点上,并且所有的容器都已经被创建,而且至少有一个是运行状态,正在启动或者重启,可以通过kubectl logs 查看pod日志 |
succeeded | 成功阶段。所有容器执行成功并终止,并且不会再次重启,可以通过kubectl logs 查看pod 日志 |
failed | 失败阶段。所有容器都已终止,并且至少有一个容器以失败的方式终止,也就是说这个容器要么以非零状态退出,要么被系统终止,可以通过logs 和 describe 查看pod日志和状态 |
unknown | 未知阶段,通常由于通信问题造成的无法获取pod状态 |
容器状态
除了整个pod的阶段,kubernetes还跟踪pod中每个容器的状态。您可以使用容器生命周期挂钩来触发事件,以在容器生命周期的某些点运行。
一旦调度器将pod分配给node,kubelet就开始使用容器运行时为该pod创建容器。有三种可能的容器状态:等待、运行和终止。
要检查pod容器的状态,可以使用kubectl describe pod<name of pod>。输出显示该pod中每个容器的状态。
-
waiting如果容器未处于“正在运行”或“已终止”状态,则为“正在等待”。处于等待状态的容器仍在运行完成启动所需的操作:例如,从容器映像注册表中提取容器映像,或应用机密数据。当您使用kubectl查询一个容器为waiting的pod时,还会看到一个reason字段来总结容器处于该状态的原因。
-
running正在运行状态表示容器正在执行而没有问题。如果配置了poststart钩子,那么它已经执行并完成了。当您使用kubectl查询容器处于运行状态的pod时,您还可以看到有关容器何时进入运行状态的信息。
-
terminated处于terminated状态的容器开始执行,然后运行完成或由于某种原因失败。当您使用kubectl查询容器已终止的pod时,您会看到原因、退出代码以及该容器执行期间的开始和结束时间。
如果容器配置了prestop钩子,则该钩子在容器进入terminated状态之前运行。
容器探针
生产环境中,进程正常启动并不代表能正产的处理业务请求,所以需要有一套合理的健康检查机制。探针是kubelet在容器上定期执行的诊断。目前k8s有三种方式进行探针检测:
- execaction - 在容器内执行一个指定的命令,如果命令返回为0,则认为容器健康
- tcpsocketaction - 通过tcp连接检查容器指定端口,如果端口开放,则认为容器健康
- httpgetaction - 对特定的url进行请求,如果状态码在200-400 之间,则认为容器健康
健康检查方法
使用探针检查容器有四种不同的方法。每个探针必须精确定义以下四种机制之一:
- exec - 在容器内执行指定的命令。如果命令退出时状态代码为0,则认为诊断成功
- grpc - 使用grpc执行远程过程调用。目标应实现grpc运行状况检查。如果响应状态为 serving,则认为诊断成功。grpc探测是alpha功能,只有在启用grpcontainerprobe功能门时才可用
- httpget - 对指定端口和路径上的pod的ip地址执行http get请求。如果响应的状态代码在200-400之间,则认为诊断成功
- tcpsocket - 在指定端口上对pod的ip地址执行tcp检查。如果端口打开,则认为诊断成功。如果远程系统(容器)在连接打开后立即关闭连接,则视为正常
pod探针检查,容器返回的结果
- success - 容器通过检测
- failure - 容器检测失败
- unknown - 检测失败 状态未知
pod探针检查种类
- startupprobe - 用于判断容器内的应用程序是否启动成功。如果配置了startupprobe,就会先禁用其他探针,直至它成功为止。如果检测失败,kubelet会杀死容器,之后根据重启策略进行处理
- livenessprobe - 用于探测容器是否在运行,如果探测失败,kubelet会杀死容器并根据重启策略进行相应的处理。如果未指定该探针,默认为success
- readinessprobe - 用于检测容器内的程序是否健康,即判断容器是否为就绪(ready)状态. 如果是,则可以处理请求,否则endpoints controller 将从所有service 的endpoints 中删除此容器所在的pod的ip地址。如果未指定,将默认为 success
重启策略
yaml pod定义文件中 spec下有一个restartpolicy属性,可能值为always、onfailure和never。默认值为 always。
该属性 - restartpolicy适用于pod中的所有容器,作用是当pod容器遇到意外状况奔溃时,指定重启的策略。restartpolicy仅指kubelet在同一节点上重新启动容器。在pod中的容器退出后,kubelet会以指数级延迟(10s、20s、40s…)重新启动它们,延迟上限为5分钟。一旦容器执行了10分钟而没有任何问题,kubelet就会重置该容器的重新启动回退计时器。如下
apiversion: batch/v1
kind: job
metadata:
name: hello
spec:
template:
# this is the pod template
spec:
containers:
- name: hello
image: busybox:1.28
command: ['sh', '-c', 'echo "hello, kubernetes!" && sleep 3600']
restartpolicy: onfailure # 指定重启策略
# the pod template ends here
终止进程
因为pods表示在集群中的节点上运行的进程,所以允许这些进程在不再需要时优雅地终止是很重要的(而不是突然被kill信号停止,没有机会清理)。
设计目标是让您能够请求删除并知道进程何时终止,同时也能够确保删除最终完成。当您请求删除pod时,集群会记录并跟踪pod被强制终止之前的预期宽限期。随着强有力的停机跟踪到位,kubelet尝试优雅的停机。
# 使用kubectl delete 命令删除pod对象
kubectl delete pods/nginx
# 支持指定时间范围删除pod对象
# 默认30秒内优雅的关闭pod对象 此处设置为10秒
kubectl delete pods/nginx --grace-period=10


发表评论