文章目录
一、容器技术发展史
1. docker 崛起的原因
- docker镜像机制解决了paas打包问题;
- docker 容器同开发者之间有着与生俱来的密切关系;
- 当时 paas 概念已经深入人心
2. docker 公司的发展历程
docker 公司在 2014 年发布的 swarm 项目是以一个完整的整体来对外提供集群管理功能的产品。swarm 的最大亮点,则是它完全使用 docker 项目原本的容器管理 api 来完成集群管理。
同时,docker收购了fig 项目(后改名为compose),成了 docker 公司到目前为止第二大受欢迎的项目。
docker compose、swarm 和 machine 共称为docker“三件套”,使得 docker 公司在重新定义 paas 的方向上走出了最关键的一步。
3. docker 公司的尘埃落定
google、redhat 等开源基础设施领域玩家们,共同牵头发起了一个名为 cncf(cloud native computing foundation)的基金会。这个基金会的目的是以 kubernetes 项目为基础,建立一个由开源基础设施领域厂商主导的、按照独立基金会方式运营的平台级社区,来对抗以 docker 公司为核心的容器商业生态。
cncf 社区为了打造基于 k8s 的生态做出了两方面努力:
- 解决 kubernetes 项目在编排领域的竞争力的问题
- cncf 社区必须以 kubernetes 项目为核心,覆盖足够多的场景
面对 kubernetes 社区的崛起和壮大,docker 公司只能选择逐步放弃开源社区而专注于自己的商业化转型。从 2017 年开始,docker 公司先是将 docker 项目的容器运行时部分 containerd 捐赠给 cncf 社区,标志着 docker 项目已经全面升级成为一个 paas 平台;紧接着,docker 公司宣布将 docker 项目改名为 moby,然后交给社区自行维护,而 docker 公司的商业产品将占有 docker 这个注册商标。
二、容器技术基础
容器本身没有价值,有价值的是“容器编排”。
容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造出一个“边界”。对于 docker 等大多数 linux 容器来说,cgroups 技术是用来制造约束的主要手段,而 namespace 技术则是用来修改进程视图的主要方法。
一个正在运行的 docker 容器,其实就是一个启用了多个 linux namespace 的应用进程,而这个进程能够使用的资源量,则受 cgroups 配置的限制。这也是容器技术中一个非常重要的概念,即:容器是一个“单进程”模型。
1. namespace(看的视图的限制)
linux系统中创建进程可以fork,也可以clone,clone系统调用可以指定新的命名空间。当我们用 clone() 系统调用创建一个新进程时,就可以在参数中指定 clone_newpid 参数,比如:
int pid = clone(main_function, stack_size, clone_newpid | sigchld, null);
这时,新创建的这个进程将会“看到”一个全新的进程空间,在这个进程空间里,它的 pid 是 1。之所以说“看到”,是因为这只是一个“障眼法”,在宿主机真实的进程空间里,这个进程的 pid 还是真实的数值,比如 100。
除了刚刚用到的 pid namespace,linux 操作系统还提供了 mount、uts、ipc、network 和 user 这些 namespace,用来对各种不同的进程上下文进行“障眼法”操作。比如,mount namespace,用于让被隔离进程只看到当前 namespace 里的挂载点信息;network namespace,用于让被隔离进程看到当前 namespace 里的网络设备和配置。
在创建容器进程时,指定了这个进程所需要启用的一组 namespace 参数。这样,容器就只能“看”到当前 namespace 所限定的资源、文件、设备、状态,或者配置。而对于宿主机以及其他不相关的程序,它就完全看不到了。所以说,容器其实是一种特殊的进程而已。
docker 为容器启用的6项 namespace:
| namespace | 系统调用参数 | 隔离的内容 |
|---|---|---|
| uts | clone_newuts | 主机名域名 |
| ipc | clone_newipc | 信号量、消息队列与共享内存 |
| pid | clone_newpid | 进程编号 |
| network | clone_newnet | 网络设备、网络栈、端口等 |
| mount | clone_newns | 挂载点 |
| user | clone_newuser | 用户与组 |
namespace 技术实际上修改了应用进程看待整个计算机“视图”,即它的“视线”被操作系统做了限制,只能“看到”某些指定的内容。但对于宿主机来说,这些被“隔离”了的进程跟其他进程并没有太大区别。
2. cgroups(用的资源的限制)
2.1 容器与虚拟机的对比
优势:
- 敏捷
- 高性能
劣势:
- 隔离的不彻底
- 既然容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核。
- 在 linux 内核中,有很多资源和对象是不能被 namespace 化的,最典型的例子就是:时间。
2.2 linux cgroups
linux cgroups 就是 linux 内核中用来为进程设置资源限制的一个重要功能。它的全称是 linux control group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 cpu、内存、磁盘、网络带宽等等。
此外,cgroups 还能够对进程进行优先级设置、审计,以及将进程挂起和恢复等操作。
在 linux 中,cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下。
linux cgroups 的设计还是比较易用的,简单粗暴地理解呢,它就是一个子系统目录加上一组资源限制文件的组合。而对于 docker 等 linux 容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程的 pid 填写到对应控制组的 tasks 文件中就可以了。
2.2.1 实验演示
(1)查看cgroup内容
$ mount -t cgroup
cpuset on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cpu on /sys/fs/cgroup/cpu type cgroup (rw,nosuid,nodev,noexec,relatime,cpu)
cpuacct on /sys/fs/cgroup/cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct)
blkio on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
memory on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
...
在 /sys/fs/cgroup 下面有很多诸如 cpuset、cpu、 memory 这样的子目录,也叫子系统。这些都是可以被 cgroups 进行限制的资源种类。而在子系统对应的资源种类下,就可以看到该类资源具体可以被限制的方法。比如,对 cpu 子系统来说,我们就可以看到如下几个配置文件,这个指令是:
$ ls /sys/fs/cgroup/cpu
cgroup.clone_children cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release
cgroup.procs cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
输出中的 cpu.cfs_period_us 和 cpu.cfs_quota_us 就是可以组合使用的配置,用来限制进程在长度为 cfs_period 的一段时间内,只能被分配到总量为 cfs_quota 的 cpu 时间。
除 cpu 子系统外,cgroups 的每一个子系统都有其独有的资源限制能力,比如:
- blkio,为块设备设定i/o 限制,一般用于磁盘等设备;
- cpuset,为进程分配单独的 cpu 核和对应的内存节点;
- memory,为进程设定内存使用的限制。
(2)创建cgroup控制组
需要在对应的子系统下面创建一个目录,比如,我们现在进入 /sys/fs/cgroup/cpu 目录下:
root@ubuntu:/sys/fs/cgroup/cpu$ mkdir container
root@ubuntu:/sys/fs/cgroup/cpu$ ls container/
cgroup.clone_children cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release
cgroup.procs cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
这个目录就称为一个“控制组”。操作系统会在你新创建目录下,自动生成该子系统对应的资源限制文件。
(3)使用cgroup
现在在后台执行这样一条脚本:
$ while : ; do : ; done &
[1] 226
它执行了一个死循环,可以把计算机的 cpu 吃到 100%,根据它的输出,我们可以看到这个脚本在后台运行的进程号(pid)是 226。
可以用 top 指令来确认一下 cpu 有没有被打满:
$ top
%cpu0 :100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
可以看到 cpu 的使用率已经 100% 了(%cpu0 :100.0 us)。
通过查看 container 目录下的文件,看到 container 控制组里的 cpu quota 还没有任何限制(即:-1),cpu period 则是默认的 100 ms(100000 us):
$ cat /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
-1
$ cat /sys/fs/cgroup/cpu/container/cpu.cfs_period_us
100000
可以通过修改这些文件的内容来设置限制。比如,向 container 组里的 cfs_quota 文件写入 20 ms(20000 us):
$ echo 20000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
它意味着在每 100 ms 的时间里,被该控制组限制的进程只能使用 20 ms 的 cpu 时间,也就是说这个进程只能使用到 20% 的 cpu 带宽。
然后把被限制的进程的 pid 写入 container 组里的 tasks 文件,上面的设置就会对该进程生效了:
$ echo 226 > /sys/fs/cgroup/cpu/container/tasks
用 top 指令查看一下:
$ top
%cpu0 : 20.3 us, 0.0 sy, 0.0 ni, 79.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
可以看到,计算机的 cpu 使用率立刻降到了 20%(%cpu0 : 20.3 us)。
2.2.2 docker 容器的cgroup演示
执行 docker run 时指定 cpu 相关设置参数:
$ docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash
在启动这个容器后,可以通过查看 cgroups 文件系统下,cpu 子系统中,“docker”这个控制组里的资源限制文件的内容来确认:
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_period_us
100000
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_quota_us
20000
这表明这个 docker 容器,只能使用到 20% 的 cpu 带宽。
2.3 cgroups 的缺点
cgroups 对资源的限制能力也有很多不完善的地方,被提及最多的自然是 /proc 文件系统的问题。
linux 下的 /proc 目录存储的是记录当前内核运行状态的一系列特殊文件,用户可以通过访问这些文件,查看系统以及当前正在运行的进程的信息,比如 cpu 使用情况、内存占用率等,这些文件也是 top 指令查看系统信息的主要数据来源。
如果在早期没有完整隔离的容器里执行 top 指令,就会发现,它显示的信息是宿主机的 cpu 和内存数据,而不是当前容器的数据。造成这个问题的原因就是,/proc 文件系统并不知道用户通过 cgroups 给这个容器做了什么样的资源限制,即:/proc 文件系统是全局针对整个系统的,它不了解 cgroups 限制的存在。
lxcfs 最初是为了增强 lxc(linux 容器)和 lxd(容器的轻量级虚拟化管理器)的容器体验而设计的。尽管 docker 最初是基于 lxc 构建的,但在 0.9 版本之后,docker 引入了自己的容器运行时,称为 libcontainer(现在是容器的标准运行时 runc 的一部分),并逐渐摒弃了对 lxc 的依赖。使用 lxcfs 来提供容器内部的 /proc 和 /sys 文件系统的隔离视图,是一种补充方式,主要用于提升 lxc/lxd 容器的用户体验。docker 的用户如果需要 lxcfs 类似的功能,通常需要手动进行配置和集成,因为 docker 默认提供的隔离机制已经能够满足大多数使用场景的需求。
2.3.1 lxcfs
lxcfs 是通过文件挂载的方式,把 cgroup 中关于系统的相关信息读取出来,通过 docker 的 volume 挂载给容器内部的 proc 系统。 然后让 docker 内的应用读取 proc 中信息的时候以为就是读取的宿主机的真实的 proc。
lxcfs 的工作原理架构图:
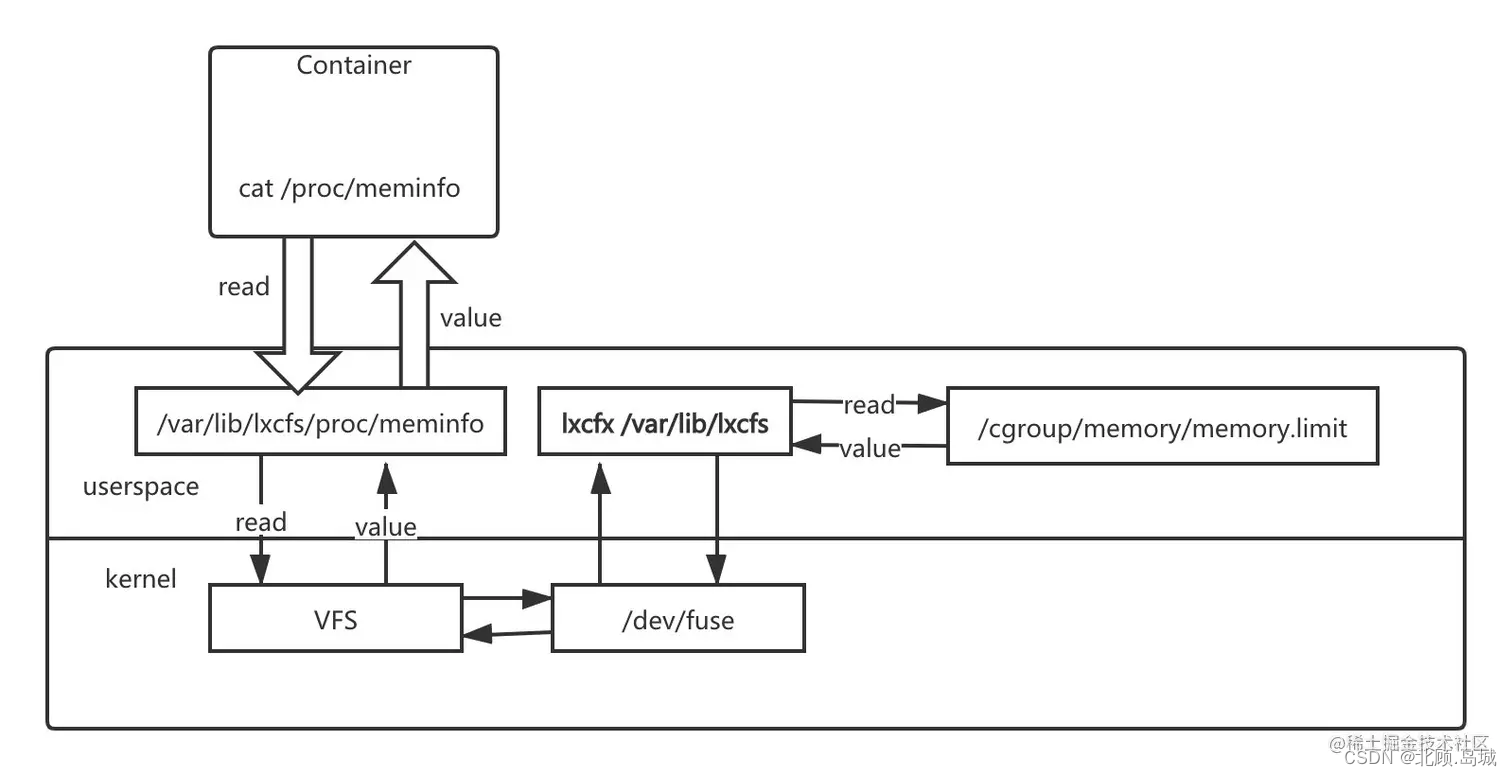
当我们把宿主机的 /var/lib/lxcfs/proc/memoinfo 文件挂载到 docker 容器的 /proc/meminfo 位置后,容器中进程读取相应文件内容时,lxcfs 的 /dev/fuse 实现会从容器对应的 cgroup 中读取正确的内存限制。从而使得应用获得正确的资源约束。 cpu 的限制原理也是一样的。


发表评论