一、一个简单的单词统计程序
首先,创建一个 maven 项目,在pom.xml中增加所需的 flink 依赖:
<dependencies>
<dependency>
<groupid>org.apache.flink</groupid>
<artifactid>flink-java</artifactid>
<version>1.12.1</version>
</dependency>
<dependency>
<groupid>org.apache.flink</groupid>
<artifactid>flink-streaming-java_2.11</artifactid>
<version>1.12.1</version>
</dependency>
<dependency>
<groupid>org.apache.flink</groupid>
<artifactid>flink-clients_2.11</artifactid>
<version>1.12.1</version>
</dependency>
</dependencies>
创建一个wordcount.java文件:
package com.flink;
public class wordcount {
public static void main(string[] args) throws exception {
}
}
接着第一步是创建一个执行环境 executionenvironment类,用来设置参数和创建数据源以及提交任务的操作:
executionenvironment env = executionenvironment.getexecutionenvironment();
下一步创建一个数据集dataset,存放的类型是string类型,并初始化了三个英文句子:
dataset<string> text = env.fromelements("this a book", "i love china", "i am chinese");
我们把数据再转化一下为tuple2类型的数据,tuplen: 代表有n个元素,通过查看源码可以看到在flink-core-1.12.1.jar中,n的最大值为25。这里tuple2第一个元素是string类型,用来存放单词,第二个元素是integer类型,表示出现次数。goupby(0)表示按第一个元素分组,sum(1)表示将第二个元素加起来。最后实现一个 flatmap 类来做解析字符串的工作,如下所示:
dataset<tuple2<string, integer>> ds = text.flatmap(new linesplitter()).groupby(0).sum(1);
定义一个实现flatmap函数相关的类来实现解析字符串,把字符串按照空格分割开,然后把每个单词次数计数一次,装配进colloector,以提供给程序最后分组及计算。
static class linesplitter implements flatmapfunction<string, tuple2<string,integer>> {
@override
public void flatmap(string string, collector<tuple2<string, integer>> collector) throws exception {
for (string word: string.split(" ")) {
collector.collect(new tuple2<string, integer>(word,1));
}
}
}
完整的程序如下,可以直接执行main函数,在控制台可以看到打印出来的结果。
package com.flink;
import org.apache.flink.api.common.functions.flatmapfunction;
import org.apache.flink.api.java.dataset;
import org.apache.flink.api.java.executionenvironment;
import org.apache.flink.api.java.tuple.tuple2;
import org.apache.flink.util.collector;
public class wordcount {
public static void main(string[] args) throws exception {
executionenvironment env = executionenvironment.getexecutionenvironment();
dataset<string> text = env.fromelements("a chinese", "china", "i am chinese");
dataset<tuple2<string, integer>> ds=text.flatmap(new linesplitter()).groupby(0).sum(1);
// 输出数据到目的端
ds.print();
}
static class linesplitter implements flatmapfunction<string, tuple2<string,integer>> {
@override
public void flatmap(string string, collector<tuple2<string, integer>> collector) throws exception {
for (string word:string.split(" ")) {
collector.collect(new tuple2<string, integer>(word,1));
}
}
}
}
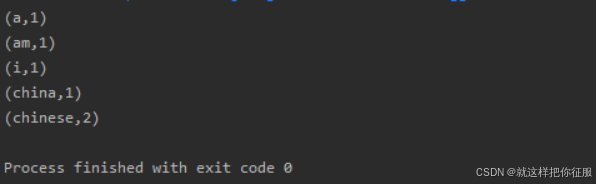
程序运行结果:
二、通过流窗口实现单词统计
此程序连接到服务器socket读取字符串作为数据源,在这里我们使用netcat工具作为服务器socket进行测试。
首先定义一个数据流,读取字符串类型的数据,以换行符为一次输入结果:
datastream<string> text = env.sockettextstream(hostname, port, "\n");
我们定义一个解析类,用来存放解析过程中的结果,变量word存放解析出来的单词,count存放单词的统计个数:
public static class wordwithcount {
public string word;
public long count;
}
然后通过flatmap来解析源数据,使用keyby函数按照wordwithcount 中word的值进行分组,并定义以每隔5秒为一个处理时间窗口,统计5秒内输入的单词的个数,最后使用reduce方法把筛选出相同的单词,把他们的count值相加,然后返回传递给下次调用,完整的代码如下:
package com.flink;
import org.apache.flink.api.common.functions.flatmapfunction;
import org.apache.flink.api.common.functions.reducefunction;
import org.apache.flink.streaming.api.datastream.datastream;
import org.apache.flink.streaming.api.environment.streamexecutionenvironment;



发表评论