目录
步骤四:查看"/home/hadoop/"下是否有".ssh"文件夹
步骤五:将 id_rsa.pub 追加到授权 key 文件中
步骤一:将 master 节点的公钥 id_rsa.pub 复制到每个 slave 点
步骤三:在每个 slave 节点删除 id_rsa.pub 文件
步骤三:验证 master 到每个 slave 节点无密码登录
步骤四:验证两个 slave 节点到 master 节点无密码登录
步骤五:配置两个子节点slave1、slave2的jdk环境。
1. 将 hadoop-2.7.1 文件夹重命名为 hadoop
4. 执行以下命令修改 hadoop-env.sh 配置文件
步骤一:在 hdfs 文件系统中创建数据输入目录 确保 dfs 和 yarn 都启动成功
步骤二:将输入数据文件复制到 hdfs 的/input 目录中
步骤三:运行 wordcount 案例,计算数据文件中各单词的频度。
步骤四:查看 java 进程,确认 hdfs 进程已全部关闭
一、hadoop平台安装
一、配置 linux 系统基础环境
步骤一:查看服务器的 ip 地址 查看服务器的 ip 地址
[root@localhost ~]# ip add show
步骤二:设置服务器的主机名称
[root@localhost ~]# hostnamectl set-hostname master
[root@localhost ~]# bash
[root@master ~]# hostname
步骤三:绑定主机名与 ip 地址
[root@master ~]# vi /etc/hosts

步骤四:查看 ssh 服务状态
ssh 为 secure shell 的缩写,是专为远程登录会话和其他网络服务提供安全性 的协议。一般的用法是在本地计算机安装 ssh 客服端,在服务器端安装 ssh服 务,然后本地计算机利用 ssh 协议远程登录服务器,对服务器进行管理。这样可 以非常方便地对多台服务器进行管理。同时在 hadoop 分布式环境下,集群中的 各个节点之间(节点可以看作是一台主机)需要使用 ssh 协议进行通信。因此 linux 系统必须安装并启用 ssh 服务。
centos 7 默认安装 ssh 服务,可以使用如下命令查看 ssh 的状态。
[root@master ~]# systemctl status sshd
步骤五:关闭防火墙
hadoop 可以使用 web 页面进行管理,但需要关闭防火墙,否则打不开 web 页面。 同时不关闭防火墙也会造成 hadoop 后台运行脚本出现莫名其妙的错误。关闭命令如 下: [root@master ~]# systemctl stop firewalld
关闭防火墙后要查看防火墙的状态,确认一下。
[root@master ~]# systemctl status firewalld
看到 inactive (dead)就表示防火墙已经关闭。不过这样设置后,linux 系统如 果重启,防火墙仍然会重新启动。执行如下命令可以永久关闭防火墙。
步骤六:创建 hadoop 用户
[root@master ~]# useradd hadoop
[root@master ~]# echo "1" |passwd --stdin hadoop
更改用户 hadoop 的密码 。
passwd:所有的身份验证令牌已经成功更新。
二:安装 java 环境
步骤一:安装 jdk
hadoop 2.7.1 要求 jdk 的版本为 1.7 以上,这里安装的是 jdk1.8 版 (即java 8)。 安装命令如下,将安装包解压到/usr/local/src 目录下 ,注意/opt/software目录 下的软件包事先准备好。
[root@master ~]# tar -zxvf /opt/software/jdk-8u152-linux-x64.tar.gz -c /usr/local/src/
[root@master ~]# ls /usr/local/src/
步骤二:设置 java 环境变量
在 linux 中设置环境变量的方法比较多,较常见的有两种:
一、是配置 /etc/profile 文件,配置结果对整个系统有效,系统所有用户都可以使用;
二 、是配置~/.bashrc 文件,配置结果仅对当前用户有效。这里使用第一种方法。
[root@master ~]# vi /etc/profile 在文件的最后增加如下两行:
export java_home=/usr/local/src/jdk1.8.0_152
export path=$path:$java_home/bin
执行 source 使设置生效:
[root@master ~]# source /etc/profile
检查 java 是否可用。
[root@master ~]# echo $java_home /usr/local/src/jdk1.8.0_152
[root@master ~]# java -version
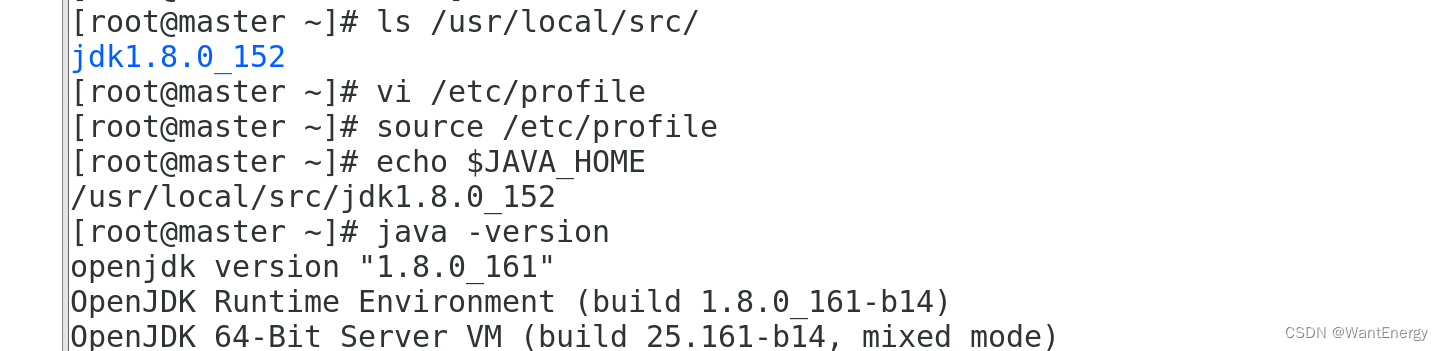
能够正常显示 java 版本则说明 jdk 安装并配置成功。
二、安装 hadoop 软件
一、安装 hadoop 软件
步骤一:安装 hadoop 软件
安装命令如下,将安装包解压到/usr/local/src/目录下
[root@master ~]# tar -zxvf /opt/software/hadoop-2.7.1.tar.gz -c /usr/local/src/
[root@master ~]# ll /usr/local/src/
查看 hadoop 目录,得知 hadoop 目录内容如下:
[root@master ~]# ll /usr/local/src/hadoop-2.7.1/
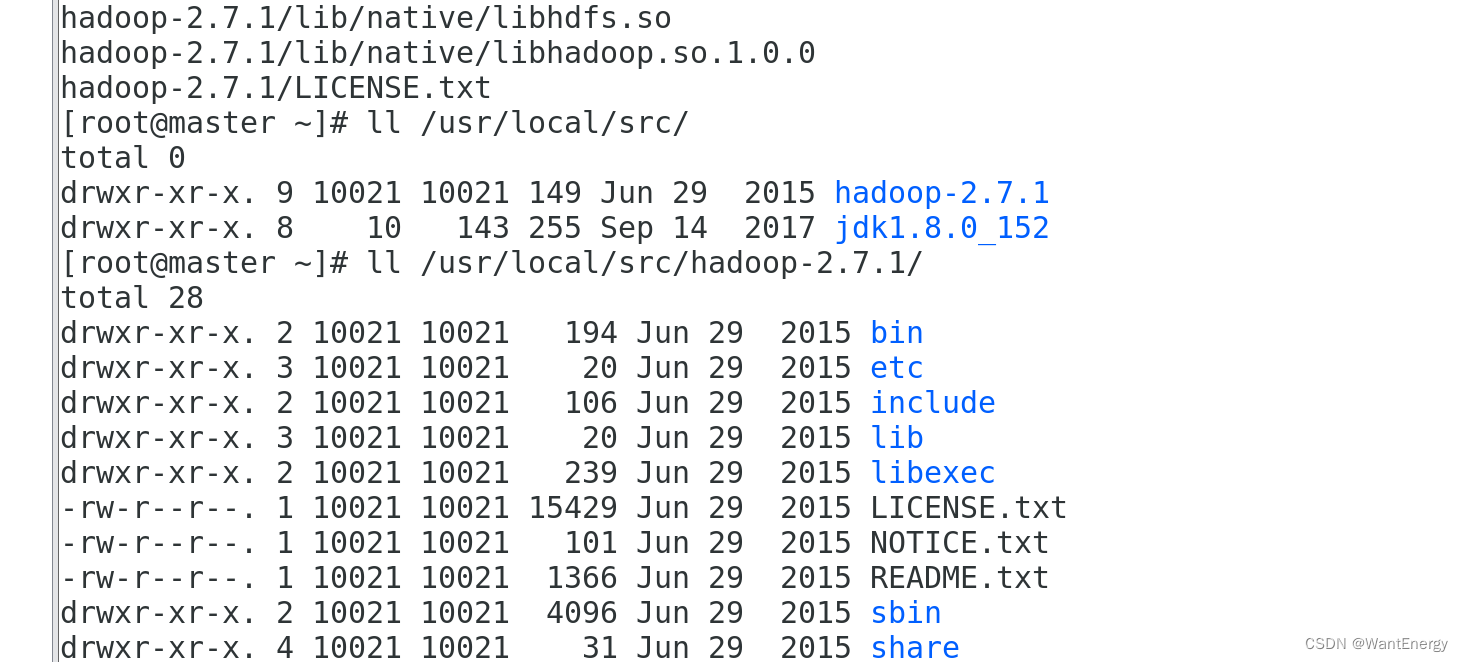
解析: bin:此目录中存放 hadoop、hdfs、yarn 和 mapreduce 运行程序和管理 软件。
etc:存放 hadoop 配置文件。
include: 类似 c 语言的头文件
lib:本地库文件,支持对数据进行压缩和解压。
libexe:同 lib sbin:hadoop 集群启动、停止命令
share:说明文档、案例和依赖 jar 包。
步骤二:配置 hadoop 环境变量
和设置 java 环境变量类似,修改/etc/profile 文件。
[root@master ~]# vi /etc/profile
在文件的最后增加如下两行:
export hadoop_home=/usr/local/src/hadoop-2.7.1
export path=$path:$hadoop_home/bin:$hadoop_home/sbin
执行 source 使用设置生效:
[root@master ~]# source /etc/profile
检查设置是否生效:
[root@master ~]# hadoop
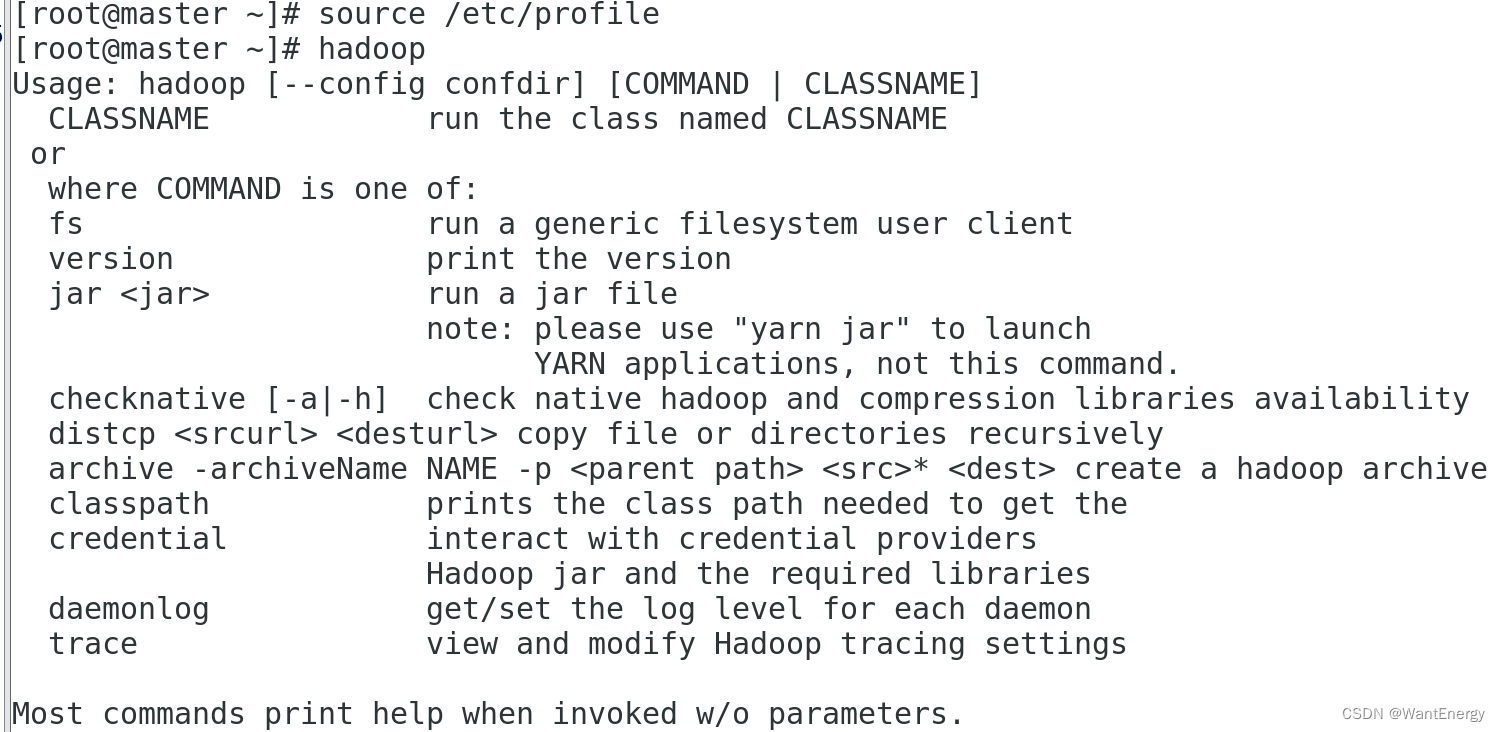
出现上述 hadoop 帮助信息就说明 hadoop 已经安装好了。
步骤三:修改目录所有者和所有者组
上述安装完成的 hadoop 软件只能让 root 用户使用,要让 hadoop 用户能够 运行 hadoop 软件,需要将目录/usr/local/src 的所有者改为 hadoop 用户。
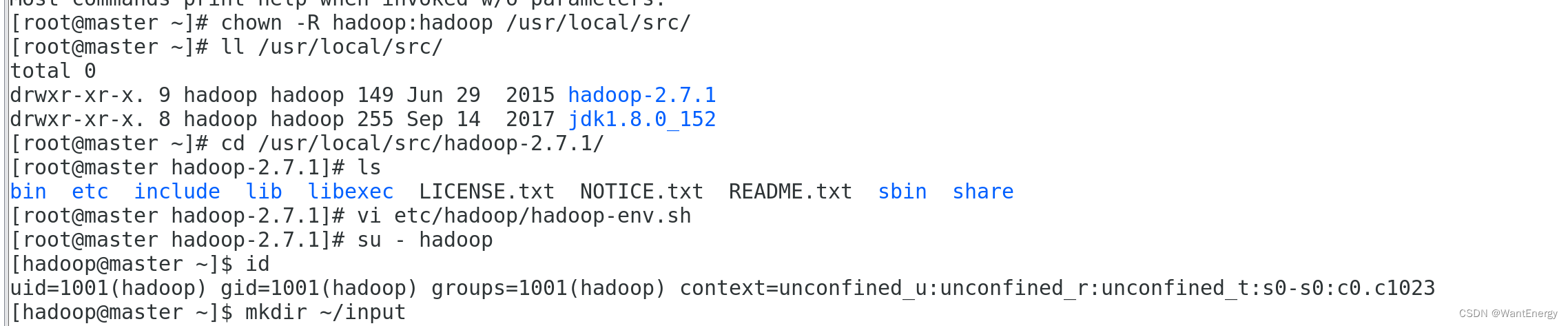
[root@master ~]# chown -r hadoop:hadoop /usr/local/src/
[root@master ~]# ll /usr/local/src/
三、安装单机版 hadoop 系统
一:配置 hadoop 配置文件
[root@master ~]# cd /usr/local/src/hadoop-2.7.1/
[root@master hadoop-2.7.1]# ls
[root@master hadoop-2.7.1]# vi etc/hadoop/hadoop-env.sh
在文件中查找 export java_home 这行,将其改为如下所示内容:
export java_home=/usr/local/src/jdk1.8.0_152
二:测试 hadoop 本地模式的运行
步骤一: 切换到 hadoop 用户
使用 hadoop 这个用户来运行 hadoop 软件。
[root@master hadoop-2.7.1]# su - hadoop
[hadoop@master ~]$ id
步骤二: 创建输入数据存放目录
将输入数据存放在~/input 目录(hadoop 用户主目录下的 input 目录中)。
[hadoop@master ~]$ mkdir ~/input
[hadoop@master ~]$ ls

步骤三: 创建数据输入文件
创建数据文件 data.txt,将要测试的数据内容输入到 data.txt 文件中。
[hadoop@master ~]$ vi input/data.txt 输入如下内容,保存退出。
hello world
hello hadoop
hello husan

步骤四: 测试 mapreduce 运行
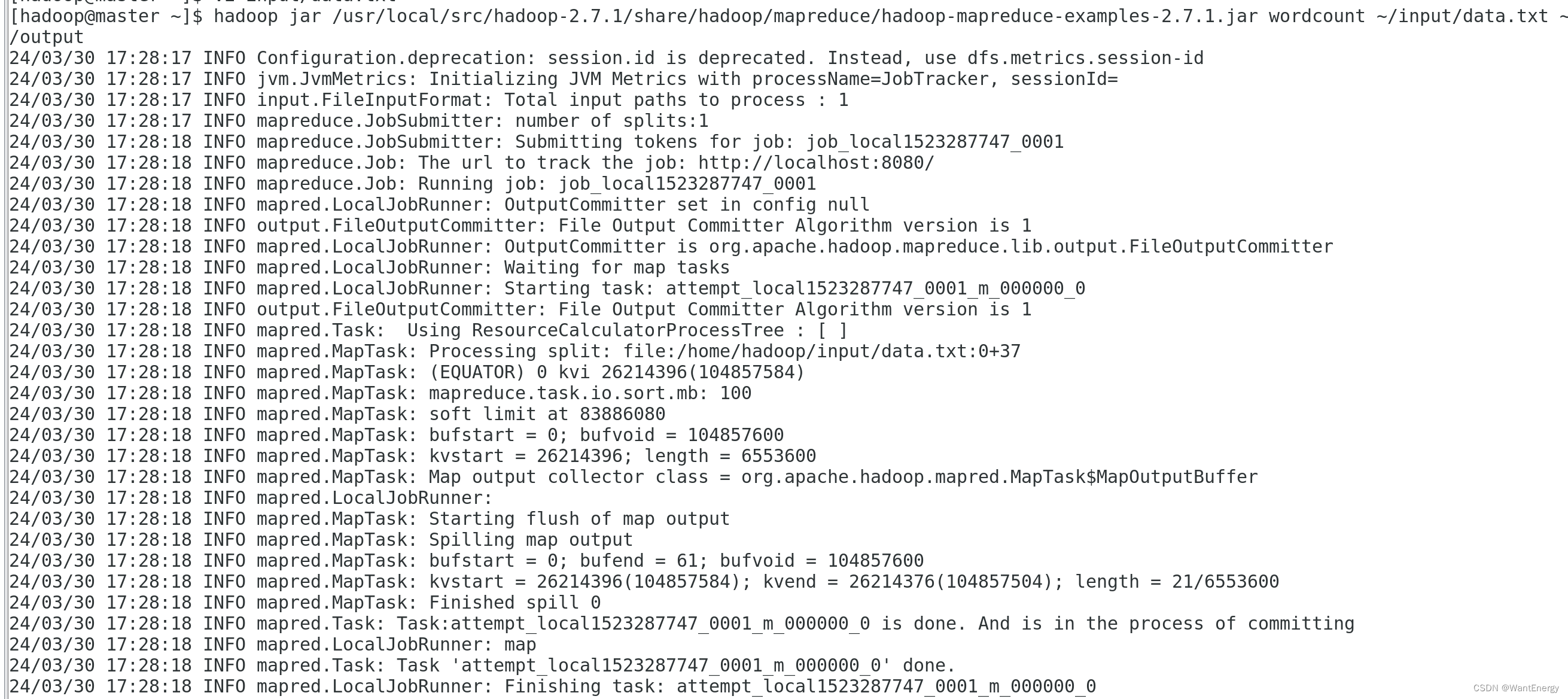
运行 wordcount 官方案例,统计 data.txt 文件中单词的出现频度。这个案例可 以用来统计年度十大热销产品、年度风云人物、年度最热名词等。
命令如下:
[hadoop@master ~]$ hadoop jar /usr/local/src/hadoop2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount ~/input/data.txt ~/output
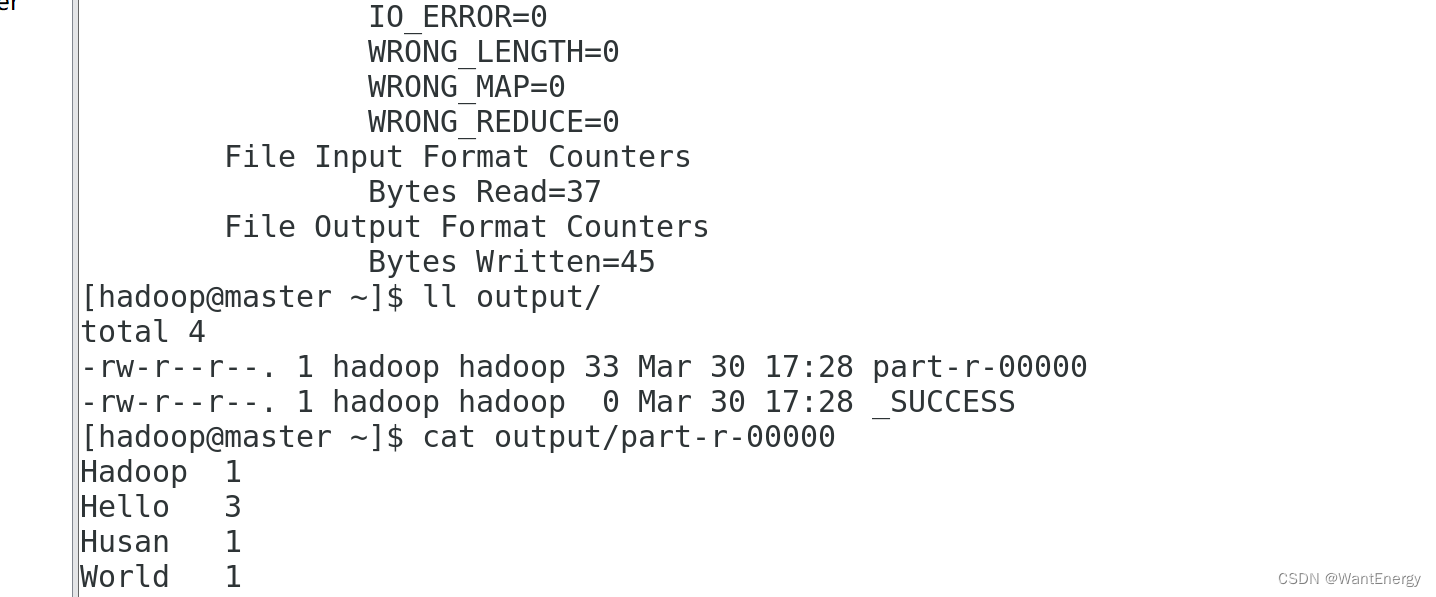
运行结果保存在~/output 目录中(注:结果输出目录不能事先存在),命令执 行后查看结果:
[hadoop@master ~]$ ll output/
文件_success 表示处理成功,处理的结果存放在 part-r-00000 文件中,查看该 文件。 [hadoop@master ~]$ cat output/part-r-00000
四、hadoop平台环境配置
一:实验环境下集群网络配置
修改 slave1 机器主机名
[root@localhost ~]# hostnamectl set-hostname slave1
[root@localhost ~]# bash
[root@slave1 ~]#

修改 slave2 机器主机名
[root@localhost ~]# hostnamectl set-hostname slave2
[root@localhost ~]# bash
[root@slave2 ~]#

根据实验环境下集群网络 ip 地址规划(根据自己主机的ip即可):
master 设置 ip 地址是“192.168.47.140”,掩码是“255.255.255.0”;
slave1 设置 ip 地址“192.168.47.141”,掩码是“255.255.255.0”;
slave2 设置 ip 地址是“192.168.47.142”,掩码是“255.255.255.0”。
根据我们为 hadoop 设置的主机名为“master、slave1、slave2”,映地址是 “192.168.47.140、192.168.47.141、192.168.47.142”,分别修改主机配置文件“/etc/hosts”, 在命令终端输入如下命令:
[root@master ~]# vi /etc/hosts

[root@slave1 ~]# vi /etc/hosts

[root@slave2 ~]# vi /etc/hosts

二:ssh 无密码验证配置
一、生成 ssh 密钥
步骤一:每个节点安装和启动 ssh 协议
实现 ssh 登录需要 openssh 和 rsync 两个服务,一般情况下默认已经安装(如没有自行安 装),可以通过下面命令查看结果。
[root@master ~]# rpm -qa | grep openssh
[root@master ~]# rpm -qa | grep rsync

步骤二:切换到 hadoop 用户
[root@master ~]# su - hadoop
[hadoop@master ~]$

[root@slave1 ~]# useradd hadoop
[root@slave1 ~]# su - hadoop
[hadoop@slave1 ~]$

[root@slave2 ~]# useradd hadoop
[root@slave2 ~]# su - hadoop
[hadoop@slave2 ~]$

步骤三:每个节点生成秘钥对
#在 master 上生成密钥
[hadoop@master ~]$ ssh-keygen -t rsa
#slave1 生成密钥 [hadoop@slave1 ~]$ ssh-keygen -t rsa
#slave2 生成密钥 [hadoop@slave2 ~]$ ssh-keygen -t rsa
步骤四:查看"/home/hadoop/"下是否有".ssh"文件夹
且".ssh"文件下是否有两个刚 生产的无密码密钥对。
[hadoop@master ~]$ ls ~/.ssh/

步骤五:将 id_rsa.pub 追加到授权 key 文件中
#master
[hadoop@master ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[hadoop@master ~]$ ls ~/.ssh/
#slave1
[hadoop@slave1 ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[hadoop@slave1 ~]$ ls ~/.ssh/

#slave2
[hadoop@slave2 ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[hadoop@slave2 ~]$ ls ~/.ssh/

步骤六:修改文件"authorized_keys"权限
通过 ll 命令查看,可以看到修改后 authorized_keys 文件的权限为“rw-------”,表示所有者 可读写,其他用户没有访问权限。如果该文件权限太大,ssh 服务会拒绝工作,出现无法 通过密钥文件进行登录认证的情况。
#master
[hadoop@master ~]$ chmod 600 ~/.ssh/authorized_keys
[hadoop@master ~]$ ll ~/.ssh/

#slave1
[hadoop@slave1 ~]$ chmod 600 ~/.ssh/authorized_keys
[hadoop@slave1 ~]$ ll ~/.ssh/
#slave2
[hadoop@slave2 ~]$ chmod 600 ~/.ssh/authorized_keys
[hadoop@slave2 ~]$ ll ~/.ssh/
步骤七:配置 ssh 服务
使用 root 用户登录,修改 ssh 配置文件"/etc/ssh/sshd_config"的下列内容,需要将该配 置字段前面的#号删除,启用公钥私钥配对认证方式。
#master
[hadoop@master ~]$ su - root
[root@master ~]# vi /etc/ssh/sshd_config
pubkeyauthentication yes #找到此行,并把#号注释删除。

#slave1
[hadoop@ slave1 ~]$ su - root
[root@ slave1 ~]# vi /etc/ssh/sshd_config
pubkeyauthentication yes #找到此行,并把#号注释删除。
#slave2
[hadoop@ slave2 ~]$ su - root
[root@ slave2 ~]# vi /etc/ssh/sshd_config
pubkeyauthentication yes #找到此行,并把#号注释删除。
步骤八:重启 ssh 服务
设置完后需要重启 ssh 服务,才能使配置生效。
[root@master ~]# systemctl restart sshd
步骤九:切换到 hadoop 用户
[root@master ~]# su - hadoop
步骤十:验证 ssh 登录本机
在 hadoop 用户下验证能否嵌套登录本机,若可以不输入密码登录,则本机通过密钥登录认证成功。
[hadoop@master ~]$ ssh localhost
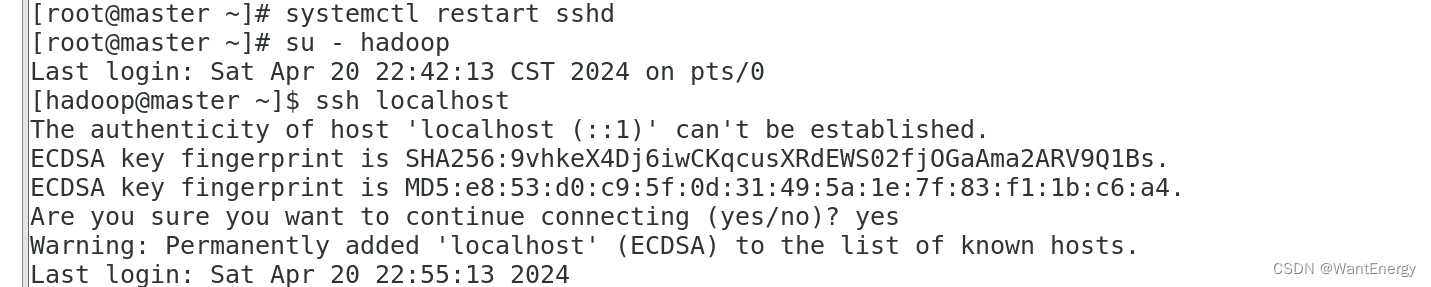
首次登录时会提示系统无法确认 host 主机的真实性,只知道它的公钥指纹,询问用户是 否还想继续连接。需要输入“yes”,表示继续登录。第二次再登录同一个主机,则不会再 出现该提示,可以直接进行登录。
读者需要关注是否在登录过程中是否需要输入密码,不需要输入密码才表示通过密钥认 证成功。
二:交换 ssh 密钥
步骤一:将 master 节点的公钥 id_rsa.pub 复制到每个 slave 点
hadoop 用户登录,通过 scp 命令实现密钥拷贝。
[hadoop@master ~]$ scp ~/.ssh/id_rsa.pub hadoop@slave1:~/
[hadoop@master ~]$ scp ~/.ssh/id_rsa.pub hadoop@slave2:~/
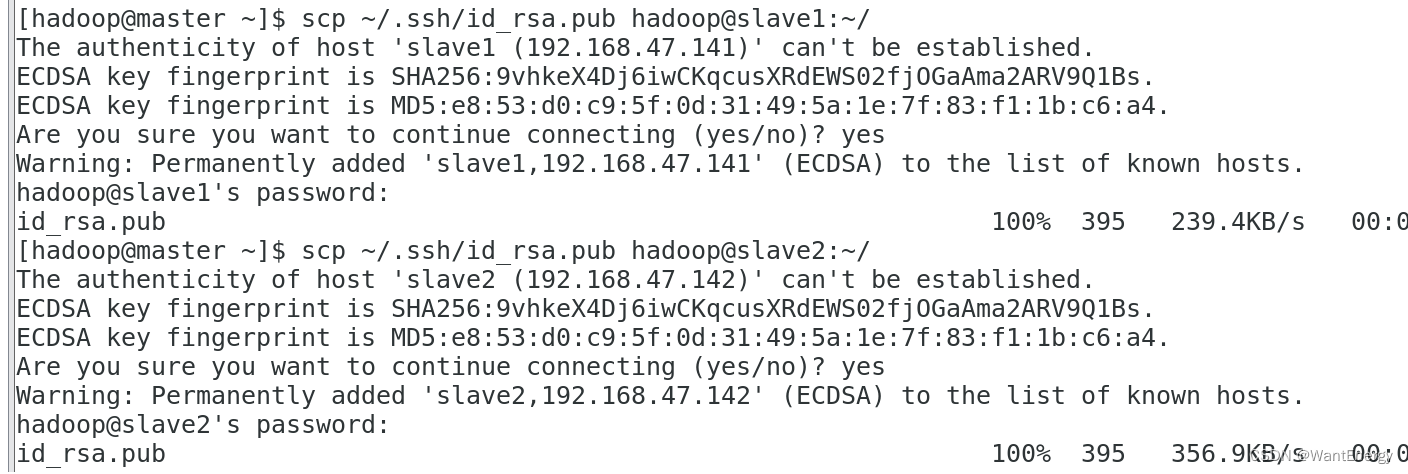
首次远程连接时系统会询问用户是否要继续连接。需要输入“yes”,表示继续。因为目 前尚未完成密钥认证的配置,所以使用 scp 命令拷贝文件需要输入slave1 节点 hadoop 用户的密码。
步骤二:在每个 slave 节点把 master 节点复制的公钥复制到authorized_keys 文件
hadoop 用户登录 slave1 和 slave2 节点,执行命令。
[hadoop@slave1 ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys

[hadoop@slave2 ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys

步骤三:在每个 slave 节点删除 id_rsa.pub 文件
[hadoop@slave1 ~]$ rm -rf ~/id_rsa.pub
[hadoop@slave2 ~]$ rm -rf ~/id_rsa.pub
步骤四:将每个 slave 节点的公钥保存到 master
(1)将 slave1 节点的公钥复制到 master
[hadoop@slave1 ~]$ scp ~/.ssh/id_rsa.pub hadoop@master:~/

(2)在 master 节点把从 slave 节点复制的公钥复制到 authorized_keys 文件
[hadoop@master ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys
(3)在 master 节点删除 id_rsa.pub 文件
[hadoop@master ~]$ rm -rf ~/id_rsa.pub
(4)将 slave2 节点的公钥复制到 master
[hadoop@slave2 ~]$ scp ~/.ssh/id_rsa.pub hadoop@master:~/

(5)在 master 节点把从 slave 节点复制的公钥复制到 authorized_keys 文件
[hadoop@master ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys
(6)在 master 节点删除 id_rsa.pub 文件
[hadoop@master ~]$ rm -rf ~/id_rsa.pub
三:验证 ssh 无密码登录
步骤一:查看 master 节点 authorized_keys 文件
[hadoop@master ~]$ cat ~/.ssh/authorized_keys

可以看到 master 节点 authorized_keys 文件中包括 master、slave1、slave2 三个节点 的公钥。
步骤二:查看 slave 节点 authorized_keys 文件
[hadoop@slave1 ~]$ cat ~/.ssh/authorized_keys

[hadoop@slave2 ~]$ cat ~/.ssh/authorized_keys

步骤三:验证 master 到每个 slave 节点无密码登录
hadoop 用户登录 master 节点,执行 ssh 命令登录 slave1 和 slave2 节点。可以观察 到不需要输入密码即可实现 ssh 登录。
[hadoop@master ~]$ ssh slave1

[hadoop@master ~]$ ssh slave2

步骤四:验证两个 slave 节点到 master 节点无密码登录
[hadoop@slave1 ~]$ ssh master
[hadoop@slave2 ~]$ ssh master

步骤五:配置两个子节点slave1、slave2的jdk环境。
[root@master ~]# cd /usr/local/src/
[root@master src]# ls
[root@master src]# scp -r jdk1.8.0_152 root@slave1:/usr/local/src/
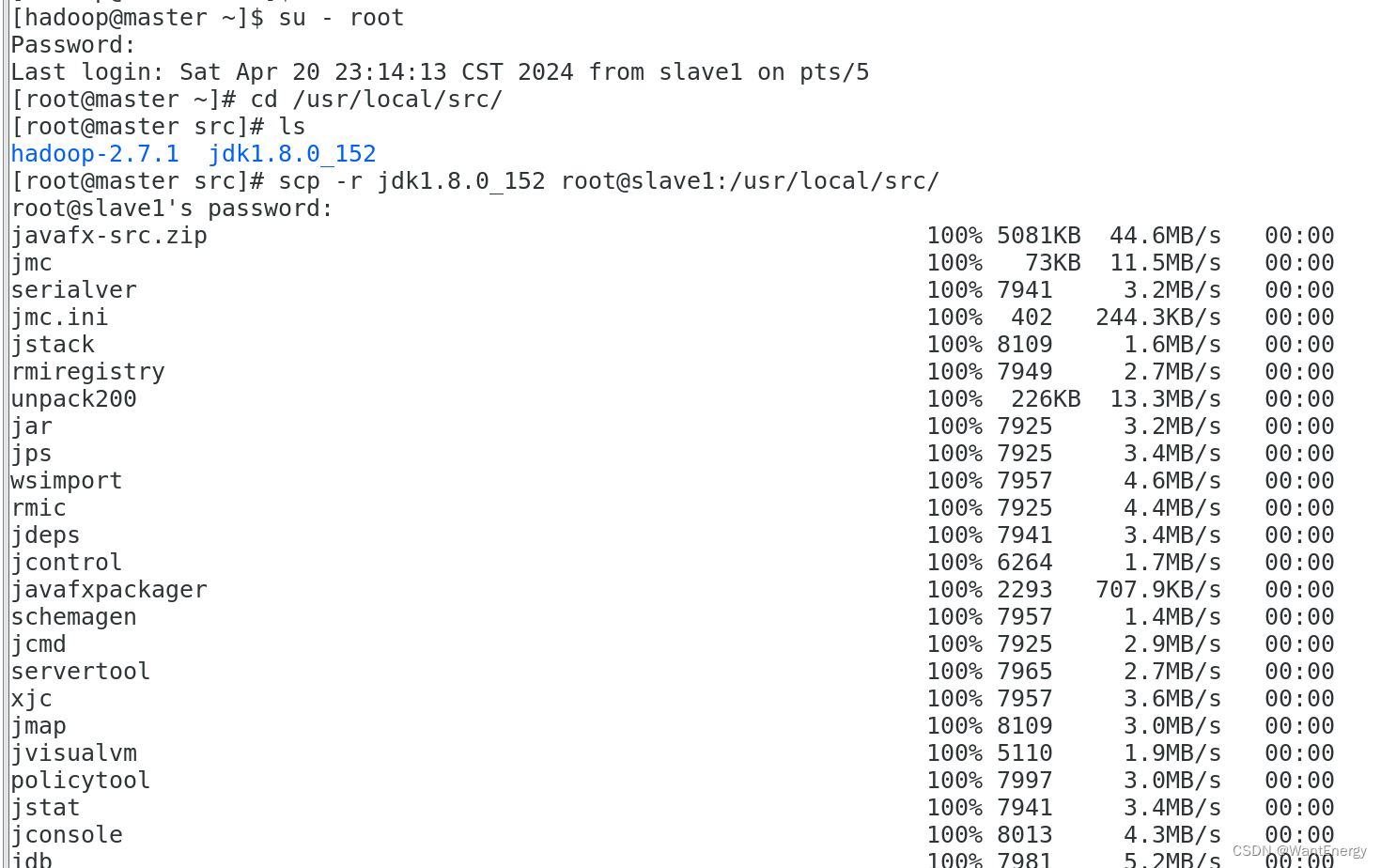
[root@master src]# scp -r jdk1.8.0_152 root@slave2:/usr/local/src/

#slave1
[root@slave1 ~]# ls /usr/local/src/
[root@slave1 ~]# vi /etc/profile #此文件最后添加下面两行
export java_home=/usr/local/src/jdk1.8.0_152
export path=$path:$java_home/bin

[root@slave1 ~]# source /etc/profile
[root@slave1 ~]# java -version
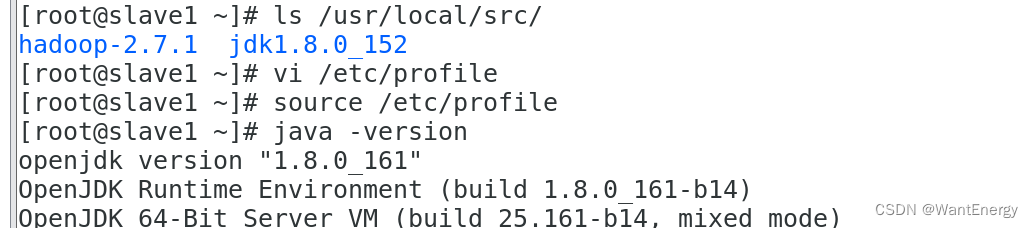
#slave2
[root@slave2 ~]# ls /usr/local/src/
[root@slave2 ~]# vi /etc/profile #此文件最后添加下面两行
export java_home=/usr/local/src/jdk1.8.0_152
export path=$path:$java_home/bin
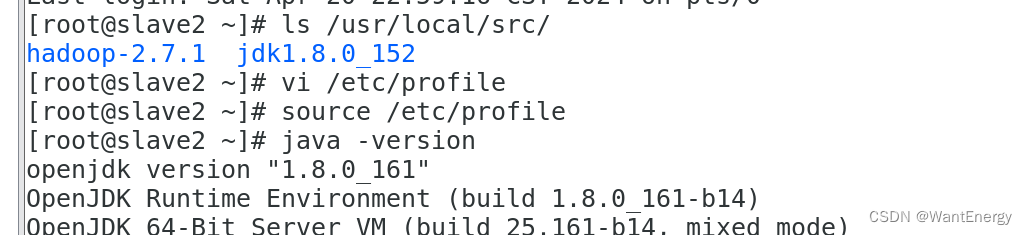
[root@slave2 ~]# source /etc/profile
[root@slave2 ~]# java -version
五、hadoop集群运行
1、hadoop文件参数配置
一:在 master 节点上安装 hadoop
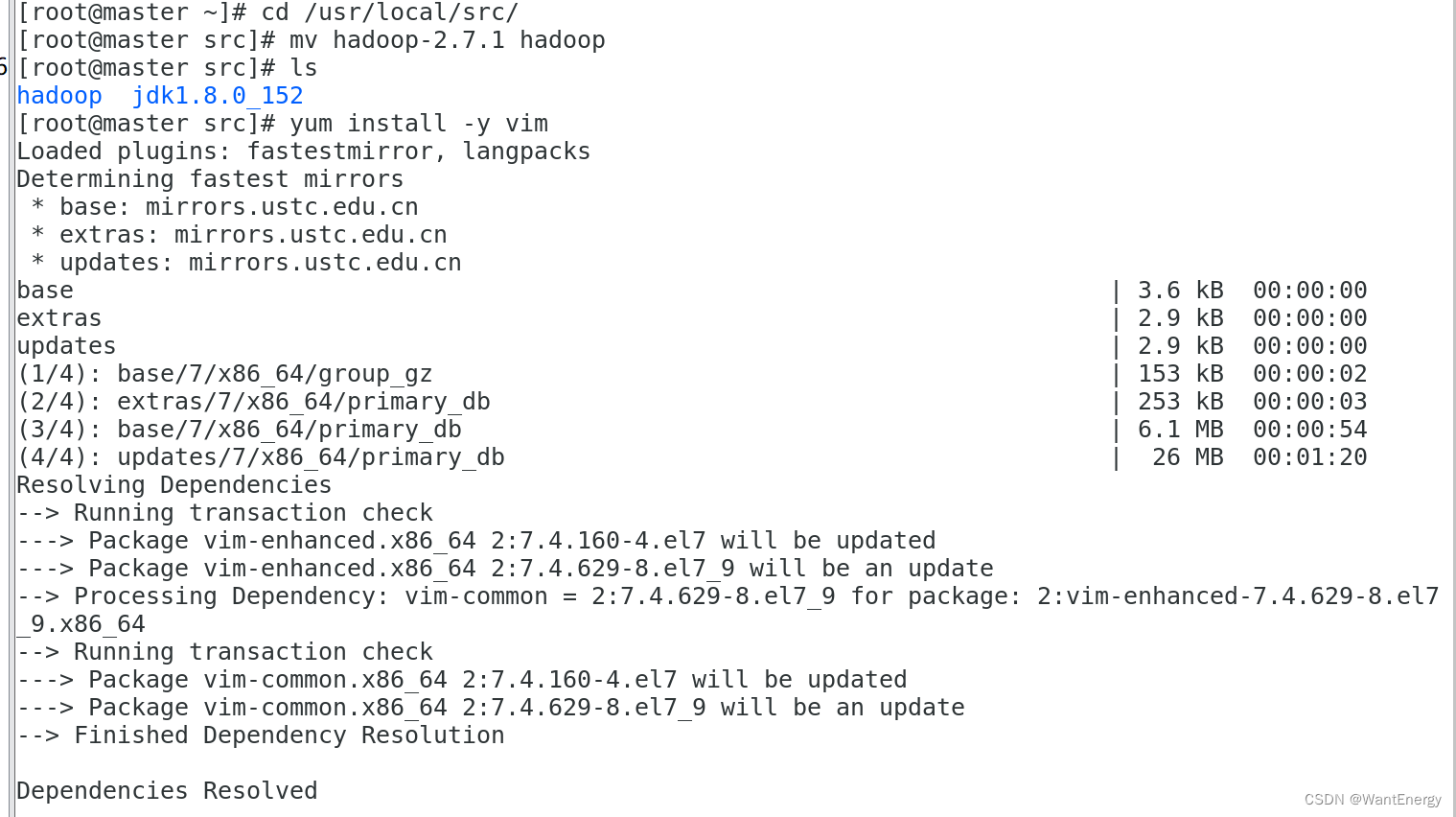
1. 将 hadoop-2.7.1 文件夹重命名为 hadoop
[root@master ~]# cd /usr/local/src/
[root@master src]# mv hadoop-2.7.1 hadoop
[root@master src]# ls
2. 配置 hadoop 环境变量
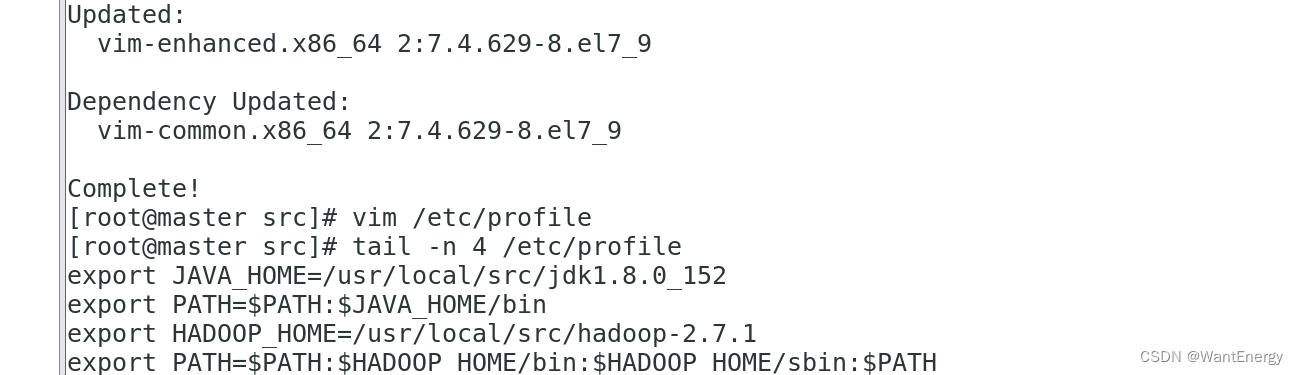
[root@master src]# yum install -y vim
[root@master src]# vim /etc/profile
[root@master src]# tail -n 4 /etc/profile
3. 使配置的 hadoop 的环境变量生效
[root@master src]# su - hadoop
[hadoop@master ~]$ source /etc/profile
[hadoop@master ~]$ exit

4. 执行以下命令修改 hadoop-env.sh 配置文件
[root@master src]# cd /usr/local/src/hadoop/etc/hadoop/
[root@master hadoop]# vim hadoop-env.sh #修改以下配置
二:配置 hdfs-site.xml 文件参数
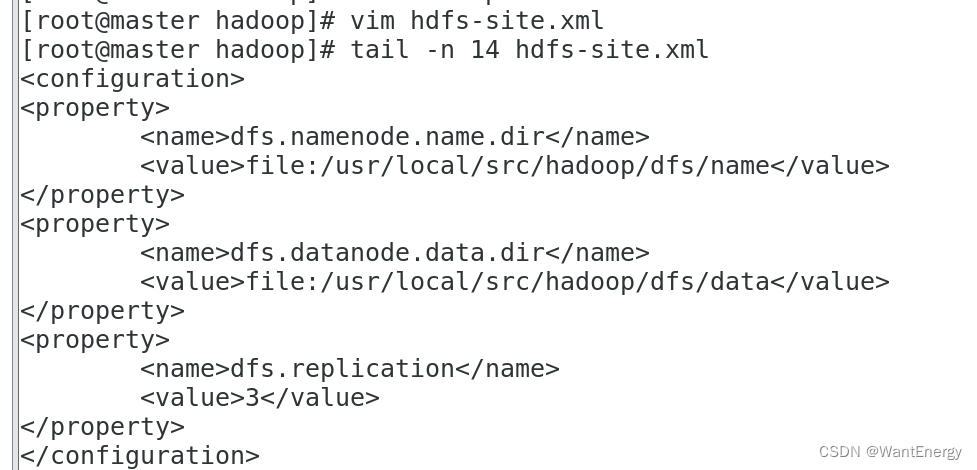
[root@master hadoop]# vim hdfs-site.xml #编辑以下内容
[root@master hadoop]# tail -n 14 hdfs-site.xml
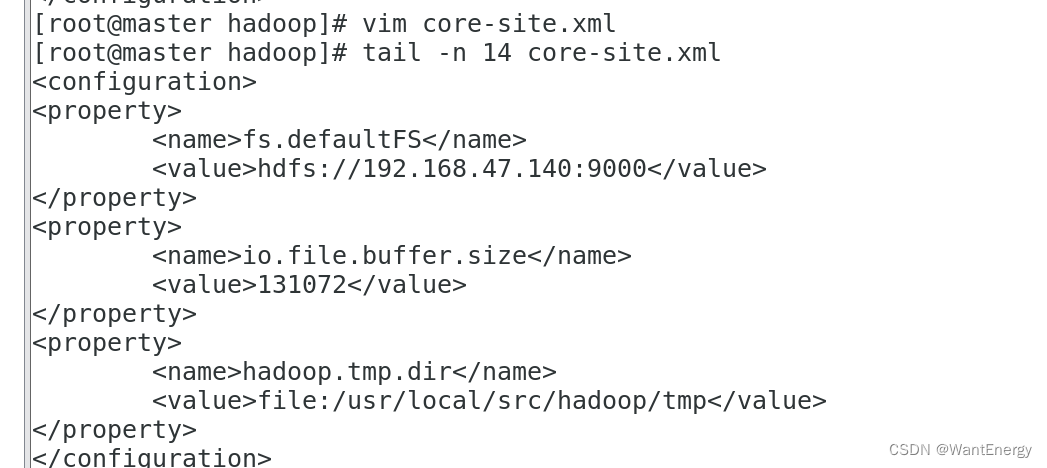
三:配置 core-site.xml 文件参数
[root@master hadoop]# vim core-site.xml #编辑以下内容
[root@master hadoop]# tail -n 14 core-site.xml
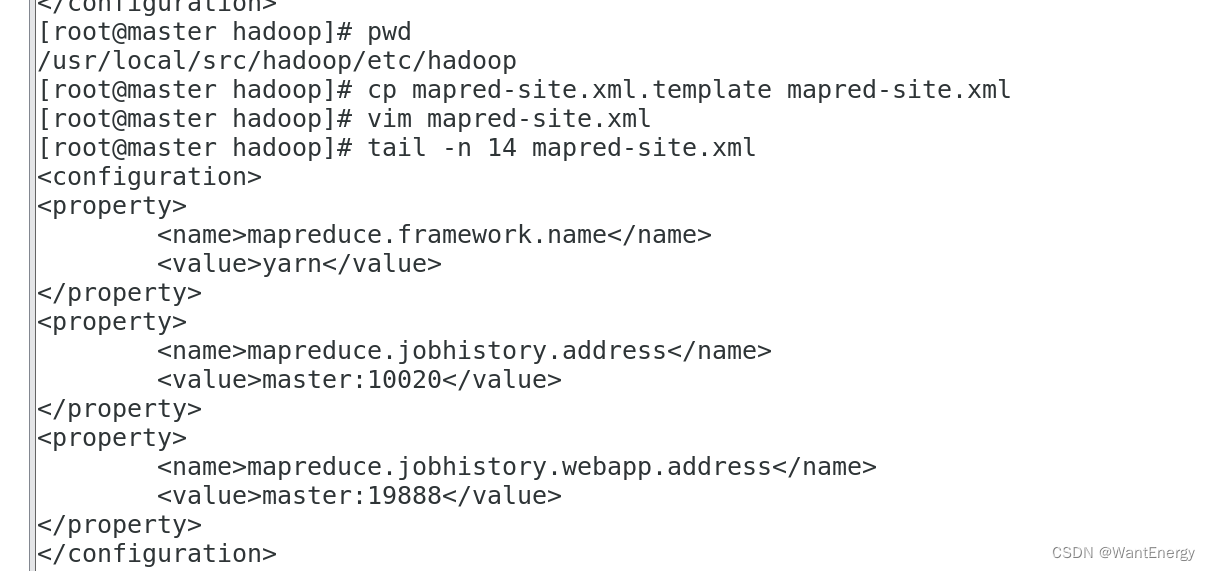
四:配置 mapred-site.xml
[root@master hadoop]# pwd
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vim mapred-site.xml #添加以下配置
[root@master hadoop]# tail -n 14 mapred-site.xml
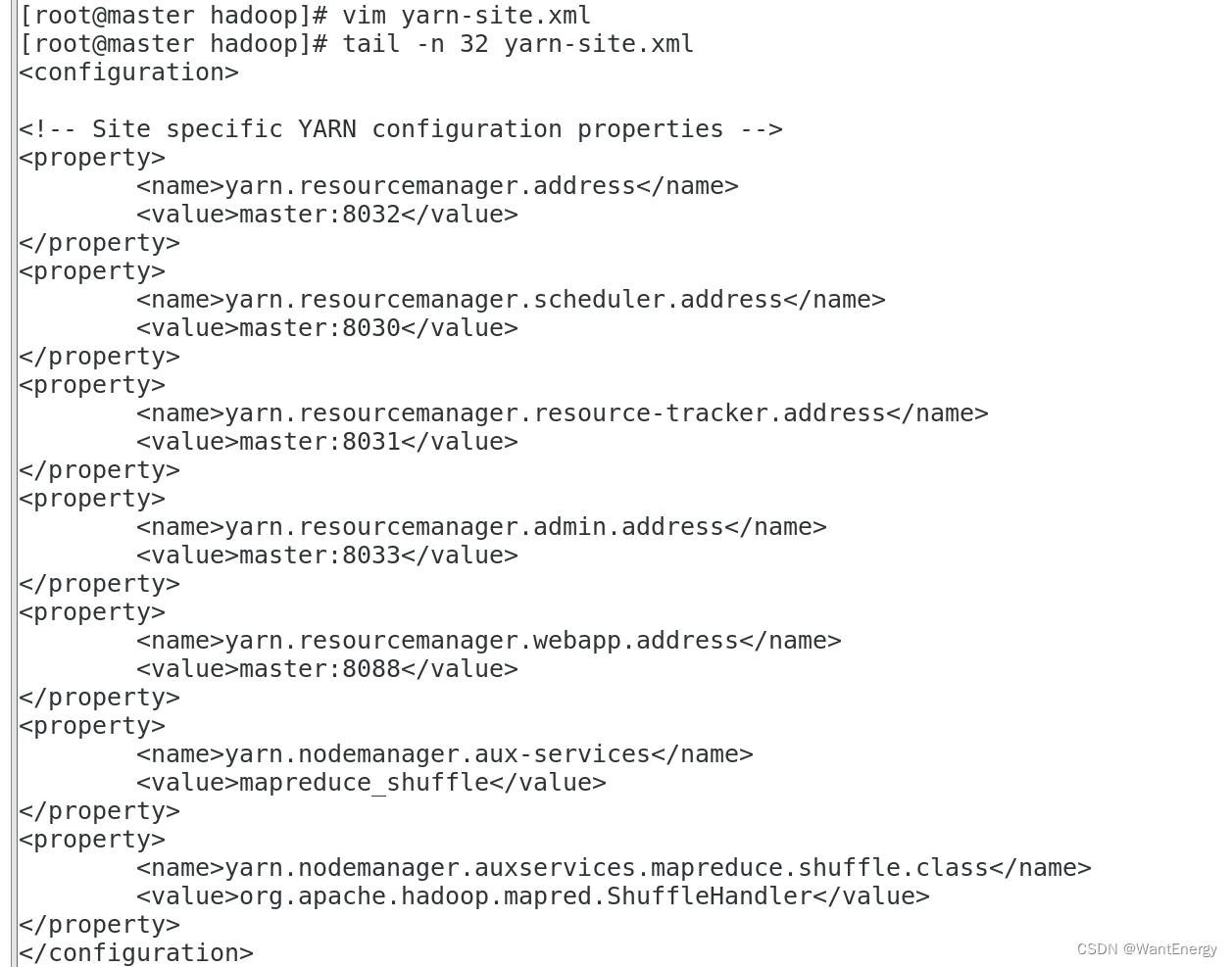
五:配置 yarn-site.xml
[root@master hadoop]# vim yarn-site.xml #添加以下配置
[root@master hadoop]# tail -n 32 yarn-site.xml
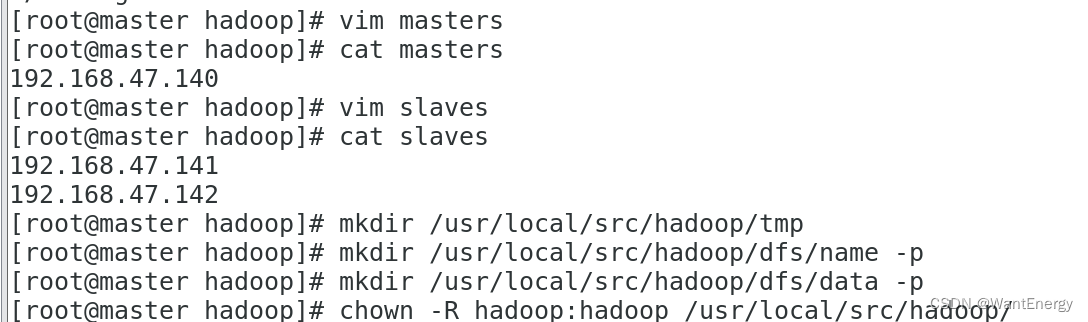
六:hadoop 其他相关配置
1. 配置 masters 文件
[root@master hadoop]# vim masters
[root@master hadoop]# cat masters
2. 配置 slaves 文件
[root@master hadoop]# vim slaves
[root@master hadoop]# cat slaves
3. 新建目录
[root@master hadoop]# mkdir /usr/local/src/hadoop/tmp
[root@master hadoop]# mkdir /usr/local/src/hadoop/dfs/name -p
[root@master hadoop]# mkdir /usr/local/src/hadoop/dfs/data -p
4. 修改目录权限
[root@master hadoop]# chown -r hadoop:hadoop /usr/local/src/hadoop/
5. 同步配置文件到 slave 节点
[root@master ~]# scp -r /usr/local/src/hadoop/ root@slave1:/usr/local/src/
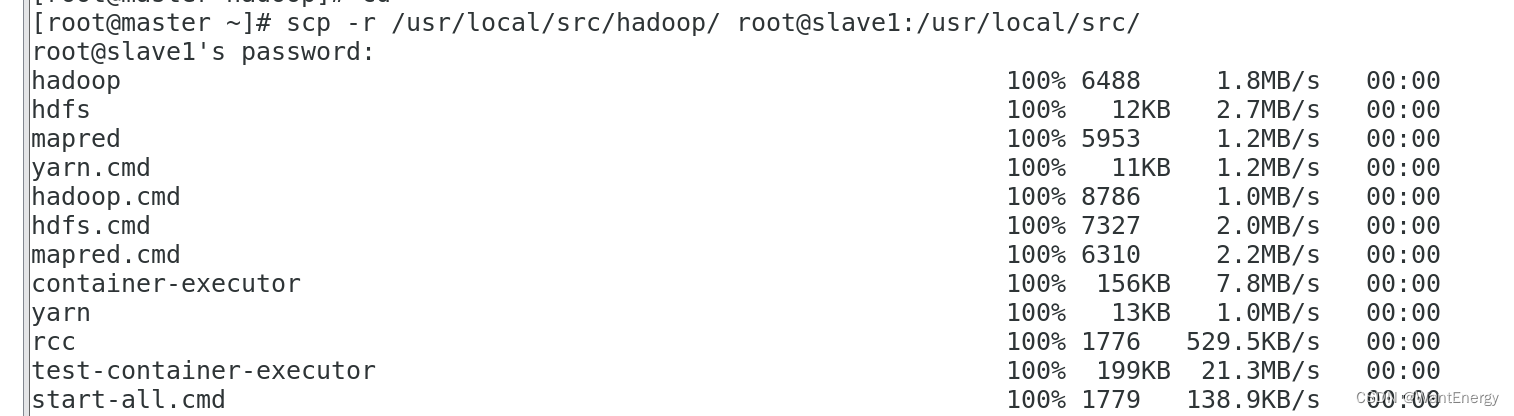
[root@master ~]# scp -r /usr/local/src/hadoop/ root@slave2:/usr/local/src/
#slave1 配置
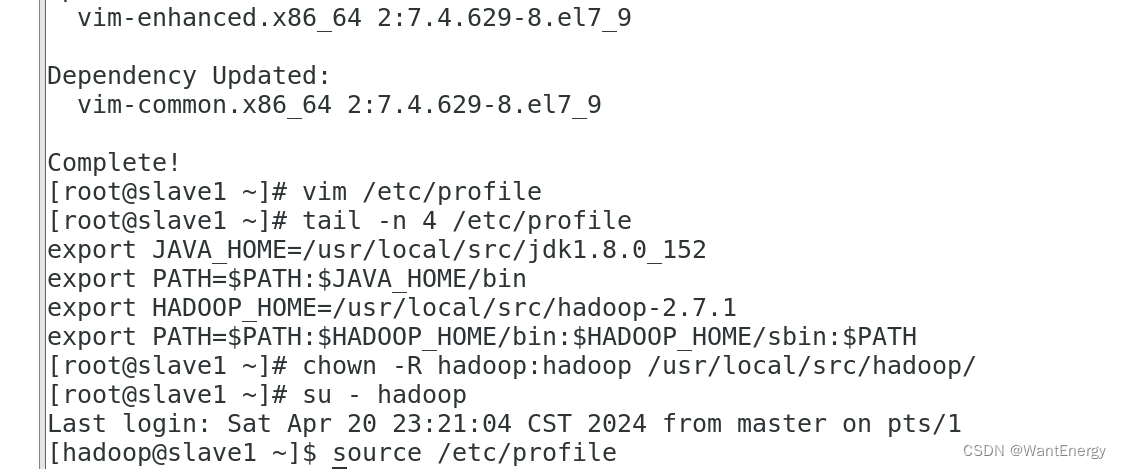
[root@slave1 ~]# yum install -y vim

[root@slave1 ~]# vim /etc/profile
[root@slave1 ~]# tail -n 4 /etc/profile
[root@slave1 ~]# chown -r hadoop:hadoop /usr/local/src/hadoop/
[root@slave1 ~]# su - hadoop
[hadoop@slave1 ~]$ source /etc/profile
#slave2 配置
[root@slave2 ~]# yum install -y vim
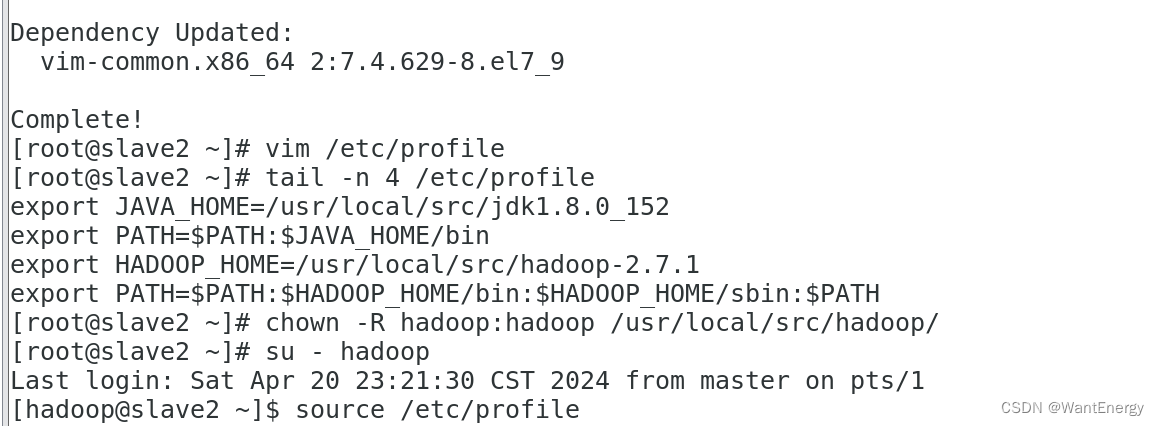
[root@slave2 ~]# vim /etc/profile
[root@slave2 ~]# tail -n 4 /etc/profile
[root@slave2 ~]# chown -r hadoop:hadoop /usr/local/src/hadoop/
[root@slave2 ~]# su - hadoop
[hadoop@slave2 ~]$ source /etc/profile
2、大数据平台集群运行
一:配置 hadoop 格式化
步骤一:namenode 格式化
将 namenode 上的数据清零,第一次启动 hdfs 时要进行格式化,以后启动无 需再格式化,否则会缺失 datanode 进程。另外,只要运行过 hdfs,hadoop 的 工作目录(本书设置为/usr/local/src/hadoop/tmp)就会有数据,如果需要重 新格式化,则在格式化之前一定要先删除工作目录下的数据,否则格式化时会 出问题。
执行如下命令,格式化 namenode
[root@master ~]# su – hadoop
[hadoop@master ~]# cd /usr/local/src/hadoop/
[hadoop@master hadoop]$ bin/hdfs namenode –format

步骤二:启动 namenode
执行如下命令,启动 namenode:
[hadoop@master hadoop]$ hadoop-daemon.sh start namenode

二:查看 java 进程
启动完成后,可以使用 jps 命令查看是否成功。jps 命令是 java 提供的一个显示当前所有 java 进程 pid 的命令。
[hadoop@master hadoop]$ jps

步骤一:slave节点 启动 datanode
执行如下命令,启动 datanode:
[hadoop@slave1 hadoop]$ hadoop-daemon.sh start datanode
[hadoop@slave2 hadoop]$ hadoop-daemon.sh start datanode
[hadoop@slave1 hadoop]$ jps
[hadoop@slave2 hadoop]$ jps
步骤二:启动 secondarynamenode
执行如下命令,启动 secondarynamenode:
[hadoop@master hadoop]$ hadoop-daemon.sh start secondarynamenode
[hadoop@master hadoop]$ jps
查看到有 namenode 和 secondarynamenode 两个进程,就表明 hdfs 启动成功。
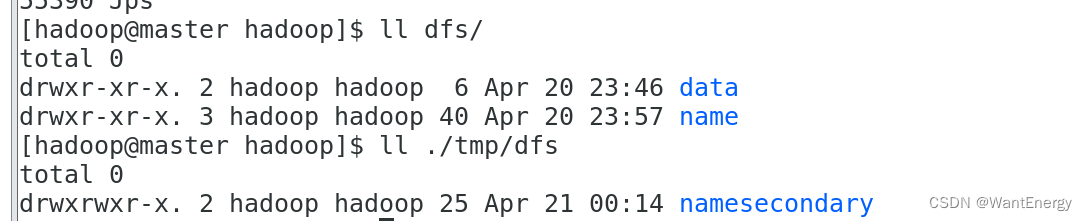
步骤三:查看 hdfs 数据存放位置
执行如下命令,查看 hadoop 工作目录:
[hadoop@master hadoop]$ ll dfs/
[hadoop@master hadoop]$ ll ./tmp/dfs
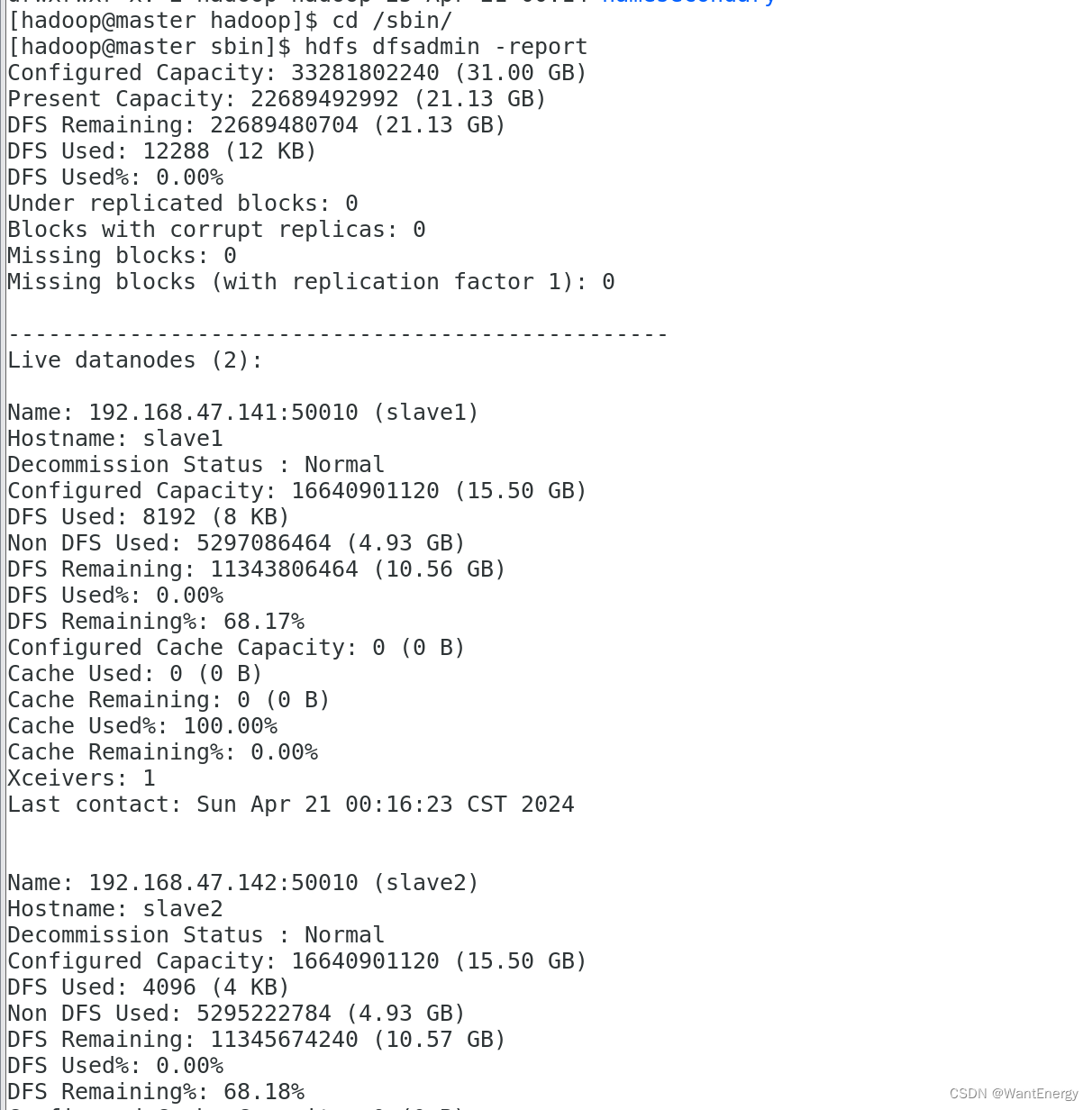
三:查看 hdfs 的报告
[hadoop@master sbin]$ hdfs dfsadmin -report
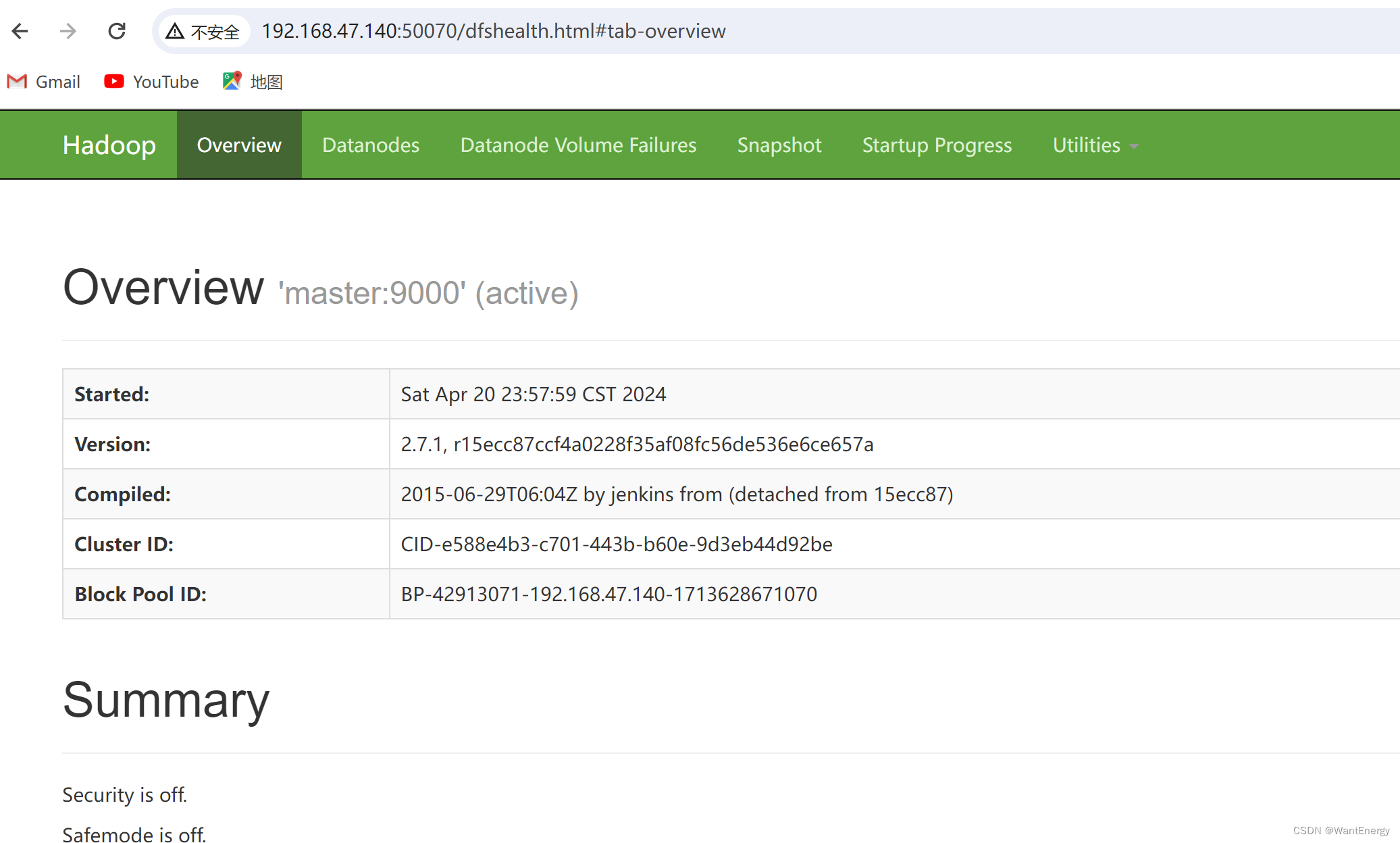
四:使用浏览器查看节点状态
在浏览器的地址栏输入http://master:50070,进入页面可以查看namenode和datanode 信息。
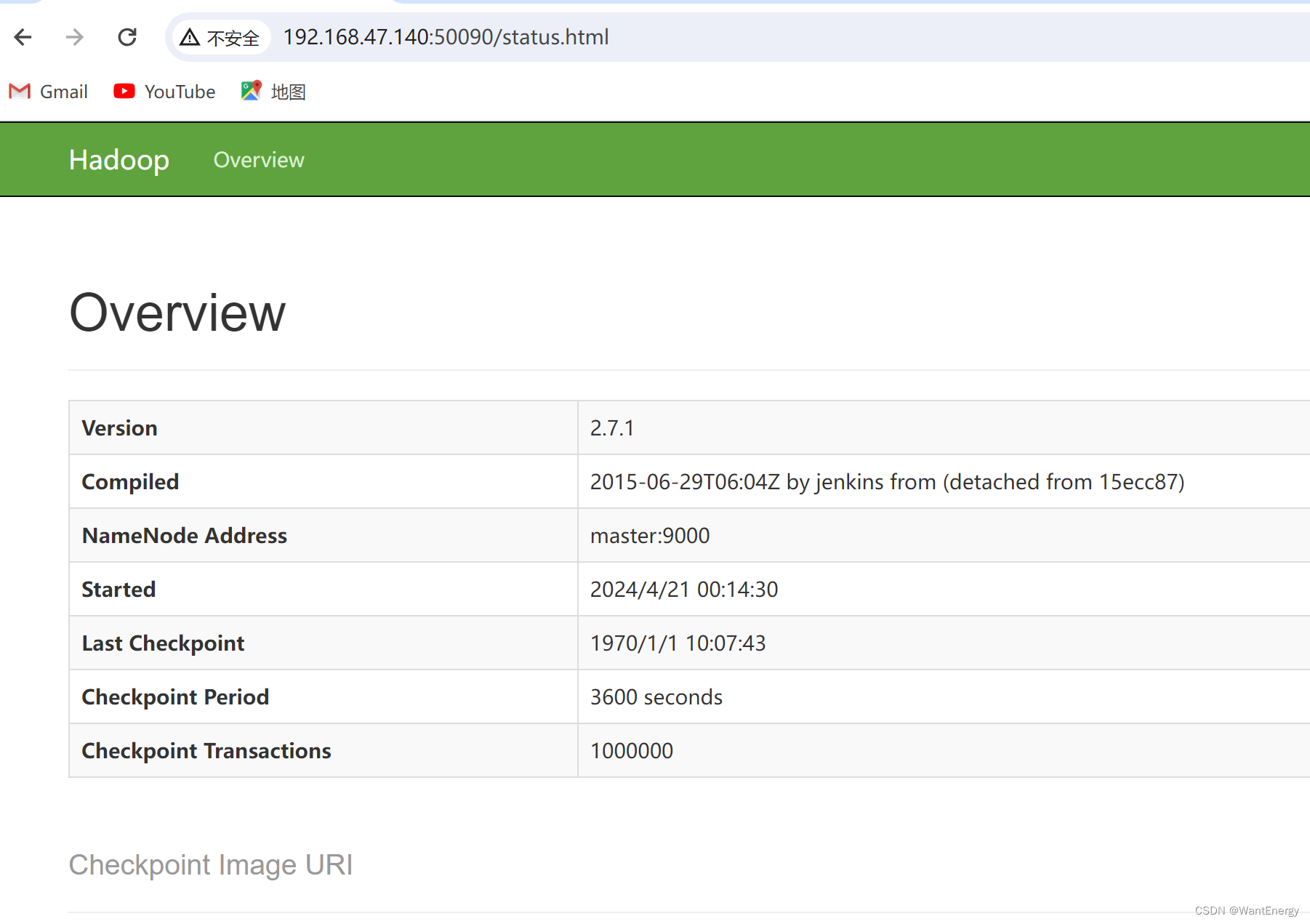
在浏览器的地址栏输入 http://master:50090,进入页面可以查看 secondarynamenode信息
可以使用 start-dfs.sh 命令启动 hdfs。这时需要配置 ssh 免密码登录,否则在 启动过程中系统将多次要求确认连接和输入 hadoop 用户密码。
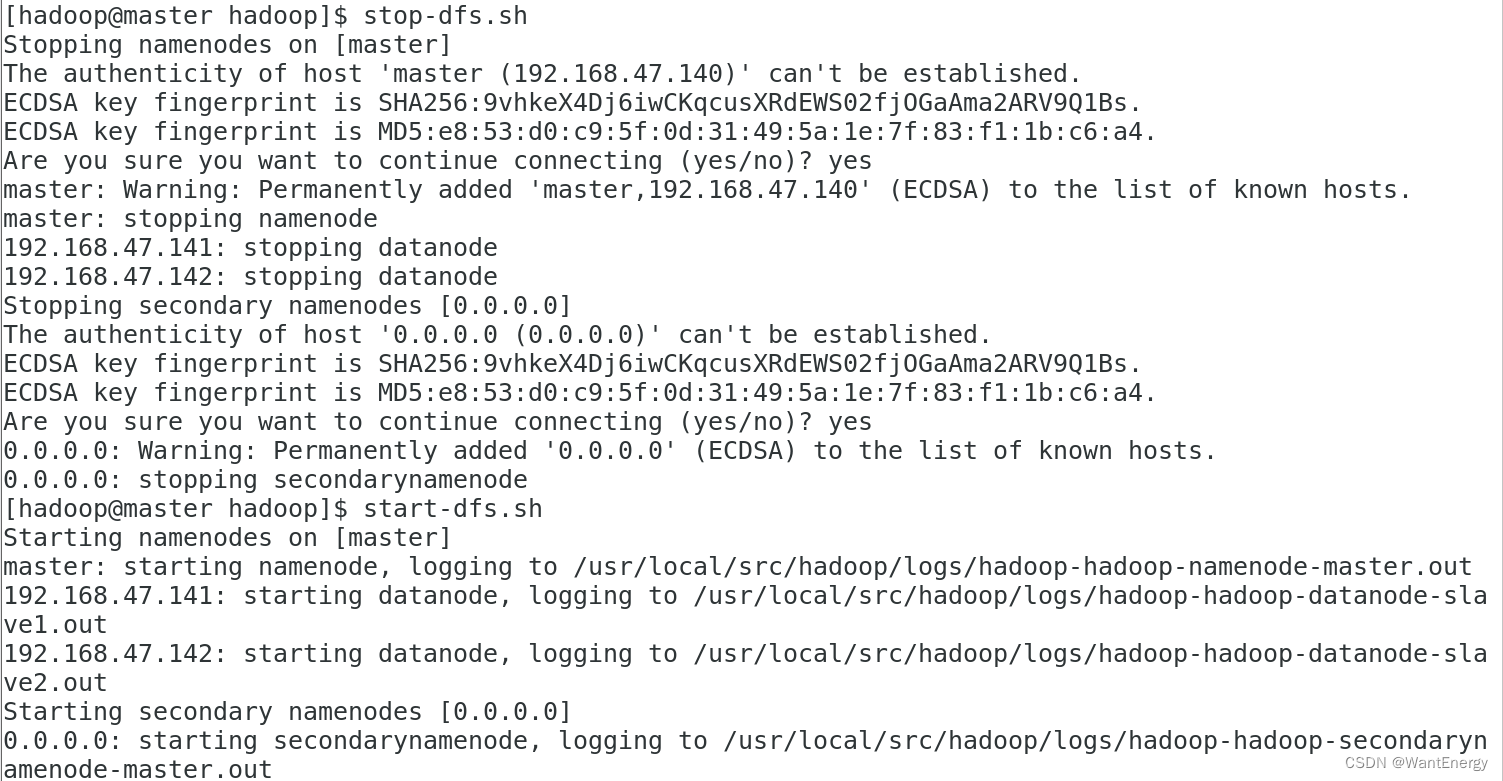
[hadoop@master hadoop]$ stop-dfs.sh
[hadoop@master hadoop]$ start-dfs.sh
运行测试: 下面运行 wordcount 官方案例,统计 data.txt 文件中单词的出现频度。这个案例可 以用来统计年度十大热销产品、年度风云人物、年度最热名词等。
步骤一:在 hdfs 文件系统中创建数据输入目录 确保 dfs 和 yarn 都启动成功
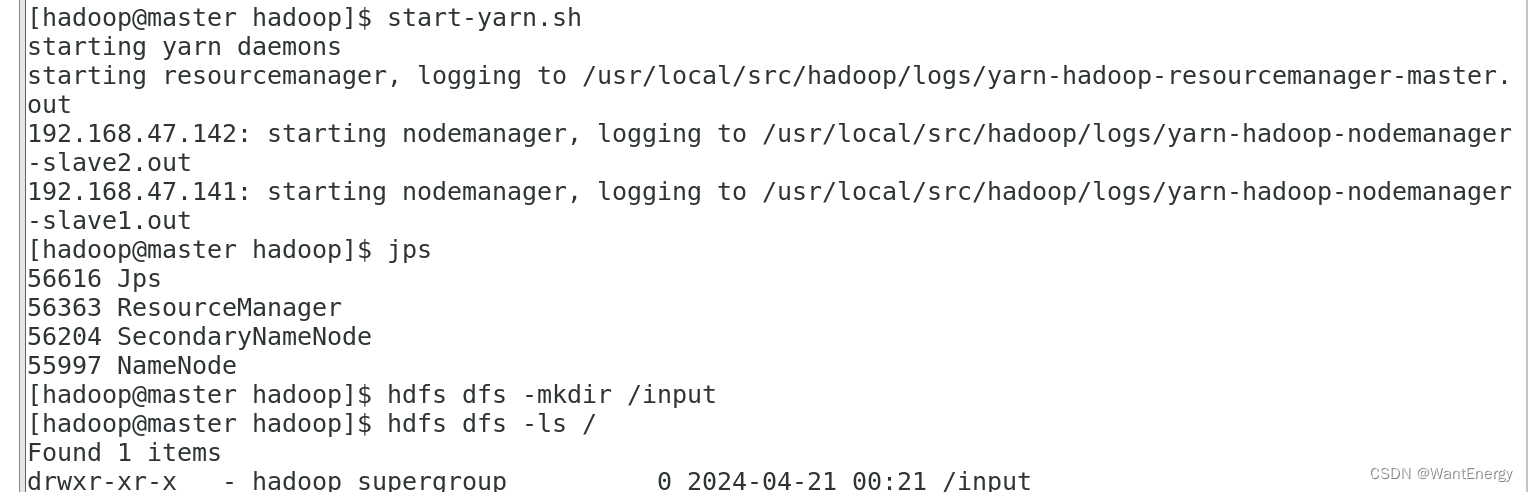
[hadoop@master hadoop]$ start-yarn.sh
[hadoop@master hadoop]$ jps
如果是第一次运行 mapreduce 程序,需要先在 hdfs 文件系统中创建数据输入目 录,存放输入数据。这里指定/input 目录为输入数据的存放目录。 执行如下命 令,在 hdfs 文件系统中创建/input 目录:
[hadoop@master hadoop]$ hdfs dfs -mkdir /input
[hadoop@master hadoop]$ hdfs dfs -ls /
此处创建的/input 目录是在 hdfs 文件系统中,只能用 hdfs 命令查看和操作。
步骤二:将输入数据文件复制到 hdfs 的/input 目录中
测试用数据文件仍然是上一节所用的测试数据文件~/input/data.txt,内容如下所示。
[hadoop@master hadoop]$ cat ~/input/data.txt
执行如下命令,将输入数据文件复制到 hdfs 的/input 目录中:
[hadoop@master hadoop]$ hdfs dfs -put ~/input/data.txt /input
确认文件已复制到 hdfs 的/input 目录:
[hadoop@master hadoop]$ hdfs dfs -ls /input

步骤三:运行 wordcount 案例,计算数据文件中各单词的频度。
运行 mapreduce 命令需要指定数据输出目录,该目录为 hdfs 文件系统中的目录,会自 动生成。如果在执行 mapreduce 命令前,该目录已经存在,则执行 mapreduce 命令会出 错。
例如 mapreduce 命令指定数据输出目录为/output,/output 目录在 hdfs 文件系统中已 经存在,则执行相应的 mapreduce 命令就会出错。所以如果不是第一次运行 mapreduce,就要先查看hdfs中的文件,是否存在/output目录。如果已经存在/output 目录,就要先删除/output目录,再执行上述命令。自动创建的/output 目录在 hdfs 文件 系统中,使用 hdfs 命令查看和操作。
[hadoop@master hadoop]$ hdfs dfs -mkdir /output
先执行如下命令查看 hdfs 中的文件:
[hadoop@master hadoop]$ hdfs dfs -ls

上述目录中/input 目录是输入数据存放的目录,/output 目录是输出数据存放的目录。执 行如下命令,删除/output 目录。
[hadoop@master hadoop]$ hdfs dfs -rm -r -f /output

执行如下命令运行 wordcount 案例:
[hadoop@master hadoop]$ hadoop jar share/hadoop/mapreduce/hado map op-- reduce-examples-2.7.1.jar wordcount /input/data.txt /output

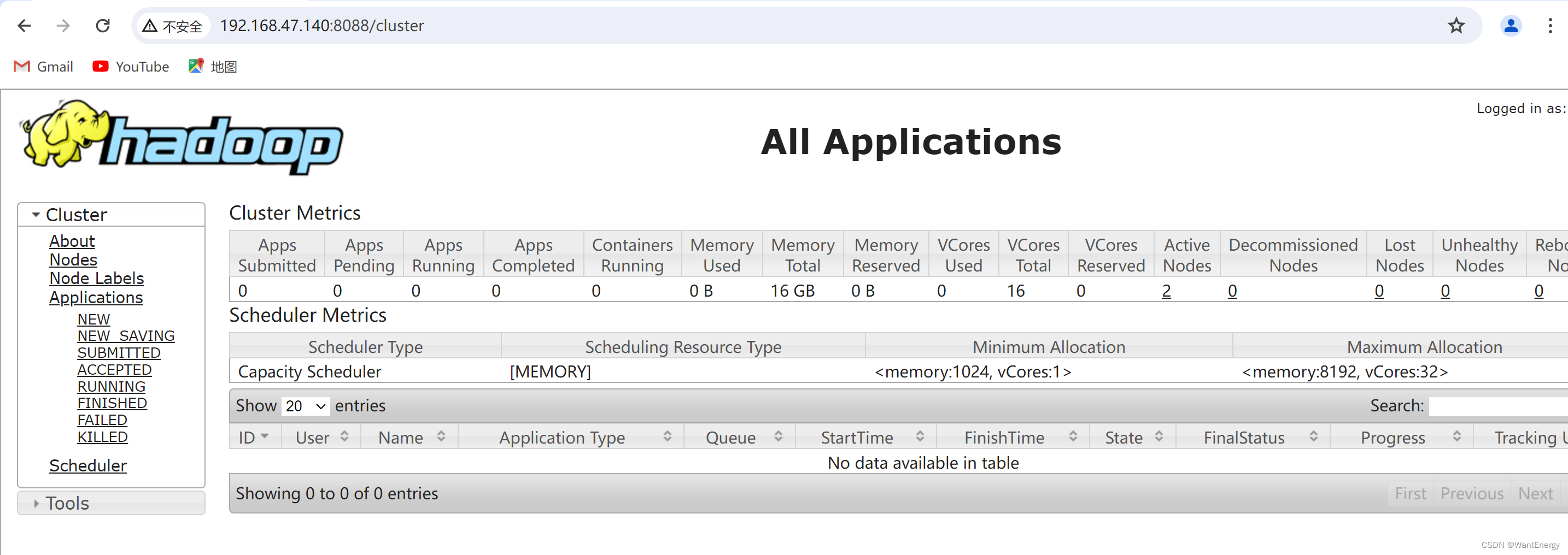
由上述信息可知 mapreduce 程序提交了一个作业,作业先进行 map,再进行 reduce 操作。 mapreduce 作业运行过程也可以在 yarn 集群网页中查看。在浏 览器的地址栏输入:http://master:8088 可以看到 mapreduce 程序刚刚完成了一个作业。
除了可以用 hdfs 命令查看 hdfs 文件系统中的内容,也可使用网页查看 hdfs 文件 系统。在浏览器的地址栏输入 http://master:50070,进入页面,在 utilities 菜单中 选择 browse the file system,可以查看 hdfs 文件系统内容。查看 hdfs 的根目录,可以看到 hdfs 根目录中有三个目录,input、output 和 tmp。
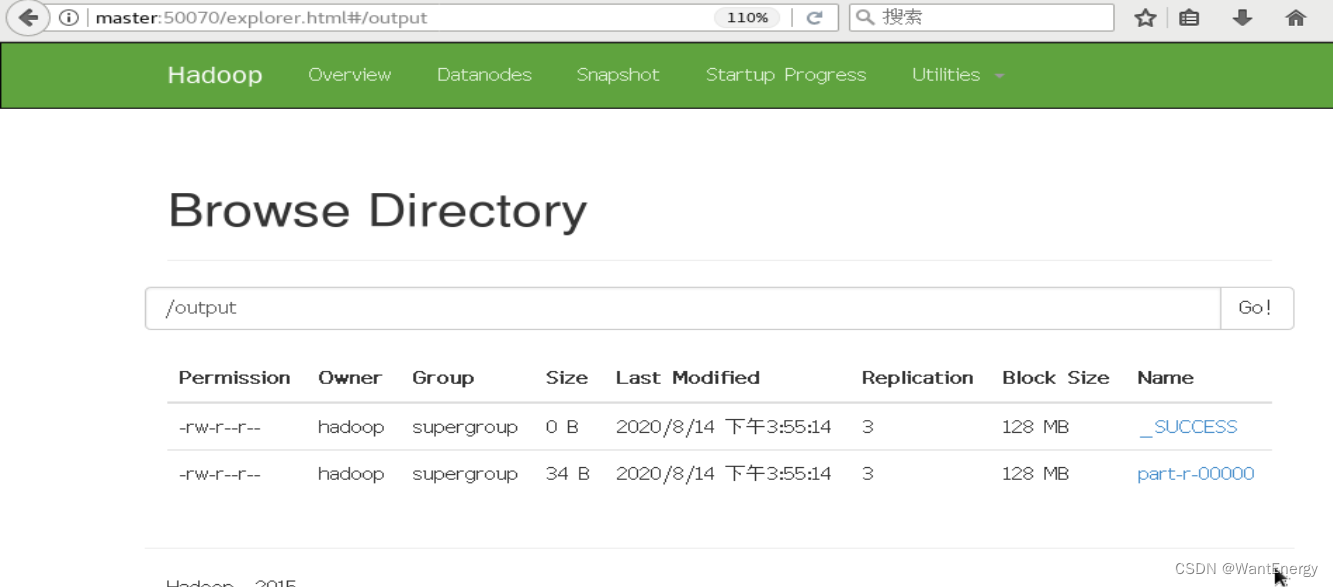
查看 output 目录,发现有两个文件。文件_success 表示处理成功,处理的结果 存放在 part-r-00000 文件中。在页面上不能直接查看文件内容,需要下载到本地系统才行。
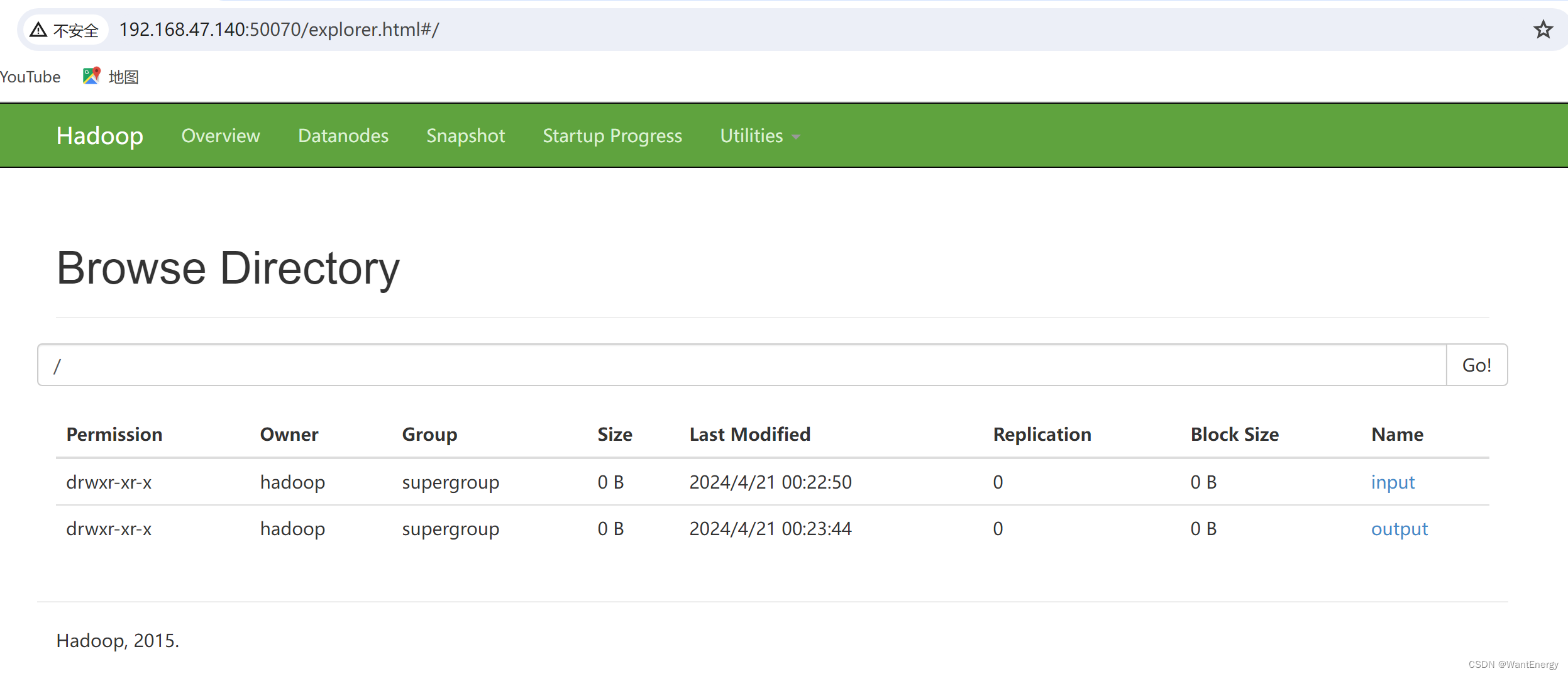
可以使用 hdfs 命令直接查看 part-r-00000 文件内容,结果如下所示:
[hadoop@master hadoop]$ hdfs dfs -cat /output/part-r-00000
五:停止 hadoop
步骤一:停止 yarn
[hadoop@master hadoop]$ stop-yarn.sh

步骤二:停止 datanode
[hadoop@slave1 hadoop]$ hadoop-daemon.sh stop datanode

[hadoop@slave2 hadoop]$ hadoop-daemon.sh stop datanode
步骤二:停止 namenode
[hadoop@master hadoop]$ hadoop-daemon.sh stop namenode
步骤三:停止 secondarynamenode
[hadoop@master hadoop]$ hadoop-daemon.sh stop secondarynamenode
步骤四:查看 java 进程,确认 hdfs 进程已全部关闭
[hadoop@master hadoop]$ jps


发表评论