〔探索ai的无限可能,微信关注“aigcmagic”公众号,让aigc科技点亮生活〕
前言
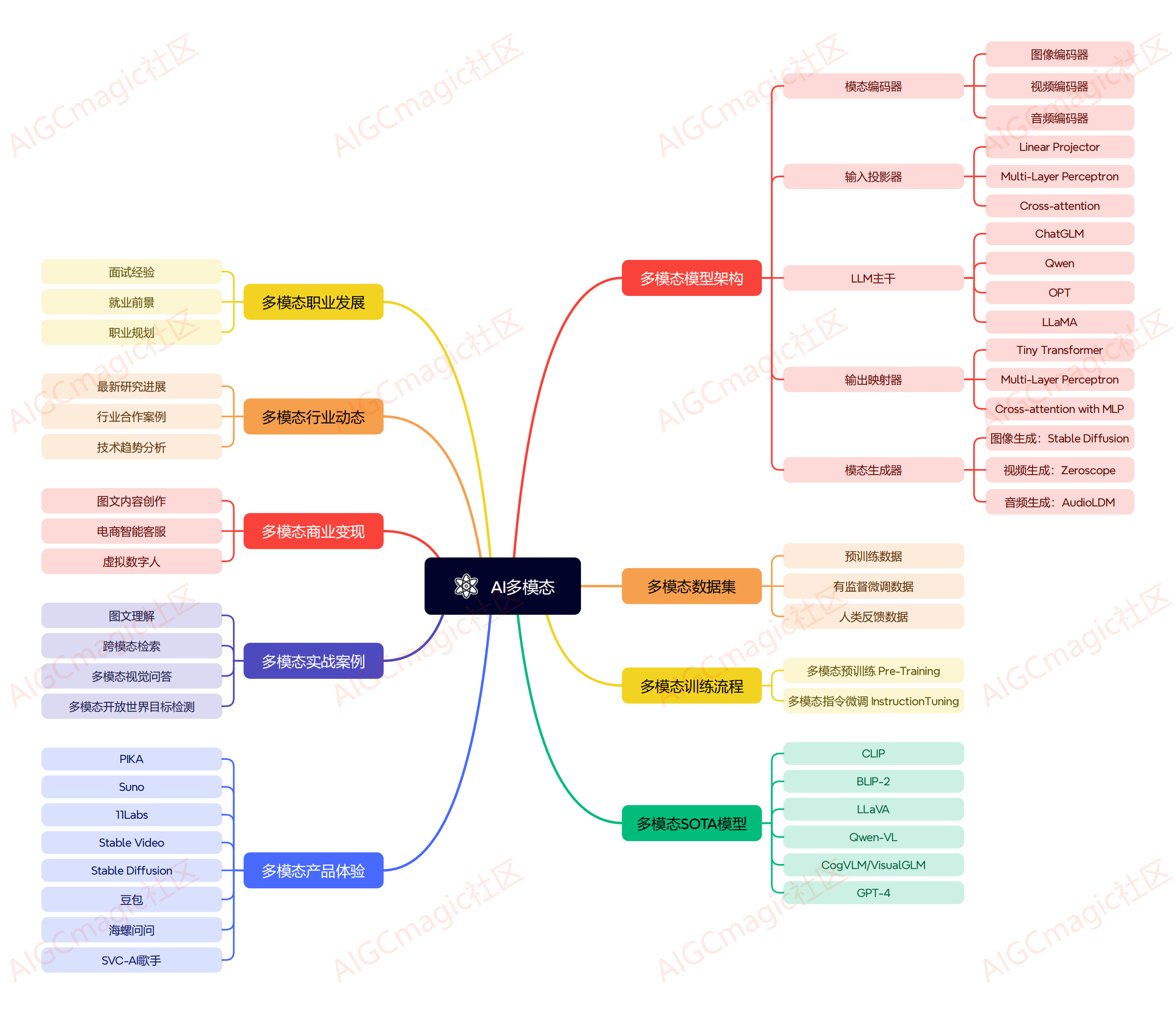
ai多模态大模型发展至今,每年都有非常优秀的工作产出,按照当前模型设计思路,多模态大模型的架构主要包括以下几个部分:
-
模态编码器(modality encoder, me):负责将不同模态的输入编码成特征。常见的编码器包括图像的nfnet-f6、vit、clip vit等,音频的whisper、clap等,视频编码器等。
-
输入投影器(input projector):负责将其他模态的特征投影到文本特征空间,并与文本特征一起输入给语言模型。常用的投影器包括线性投影器、mlp、交叉注意力等。
-
语言模型骨架(llm backbone):利用预训练的语言模型,负责处理各种模态的特征,进行语义理解、推理和决策。常用的语言模型包括chatglm、qwen、llama等。
-
输出投影器(output projector):负责将语言模型输出的信号转换成其他模态的特征,以供后续模态生成器使用。常用的投影器包括tiny transformer、mlp等。
-
模态生成器(modality generator, mg):负责生成其他模态的输出。常用的生成器包括图像的stable diffusion、视频的zeroscope、音频的audioldm等。
在当今人工智能时代,大模型无疑是最引人注目的焦点之一。它们以其强大的自然语言处理能力和广泛的应用场景,正在逐渐改变我们的工作和生活方式。
本文一手会详细解读ai多模态架构中的语言模型骨架(llm backbone),并从chatglm系列、qwen系列、llama系列三个代表性工作,总结当前主流的工作方案!持续更新,欢迎关注!
一、llama-1
1.1 开放和高效的基石语言模型
首先来讲一下meta开发llamal的动机是什么?

从论文题目“open and efficient foundation language models”可以看出,该模型强调了开放和高效两个特点。首先,它使用了完全公开的数据,不包含meta的客户数据,性能上与gpt-3相媲美,对研究社区开放,但不可用于商业用途。
从下图可以观察到,之前的scaling law主要依据计算代价来评估模型效率。例如,观察左侧图表中的训练损失曲线,黄色代表10b模型,红色代表50b模型。随着训练时间的增加,即计算成本的持续增加,两者的损失均持续下降。初期,小模型的损失下降较快,但随着训练的深入,小模型的性能逐渐饱和,下降速度减缓,而大模型的下降速度则超过了小模型。当我们设定一个期望损失时,可以发现大模型的训练成本低于小模型。以往的scaling law均以训练计算花费为评估标准,因此认为在达到预定模型性能时,训练大模型更为经济。然而,meta的观点与此不同,他们认为应更重视推理计算代价,因为训练仅发生一次,而推理则需频繁进行。根据传统scaling law的建议,对于10b模型,应使用2000亿token进行训练,但meta发现,即使是7b模型,使用1万亿token后,性能仍能持续提升。这正是meta所认为的效率。在后续的llama系列中,meta始终认为增加训练数据比扩大模型参数更为有效。

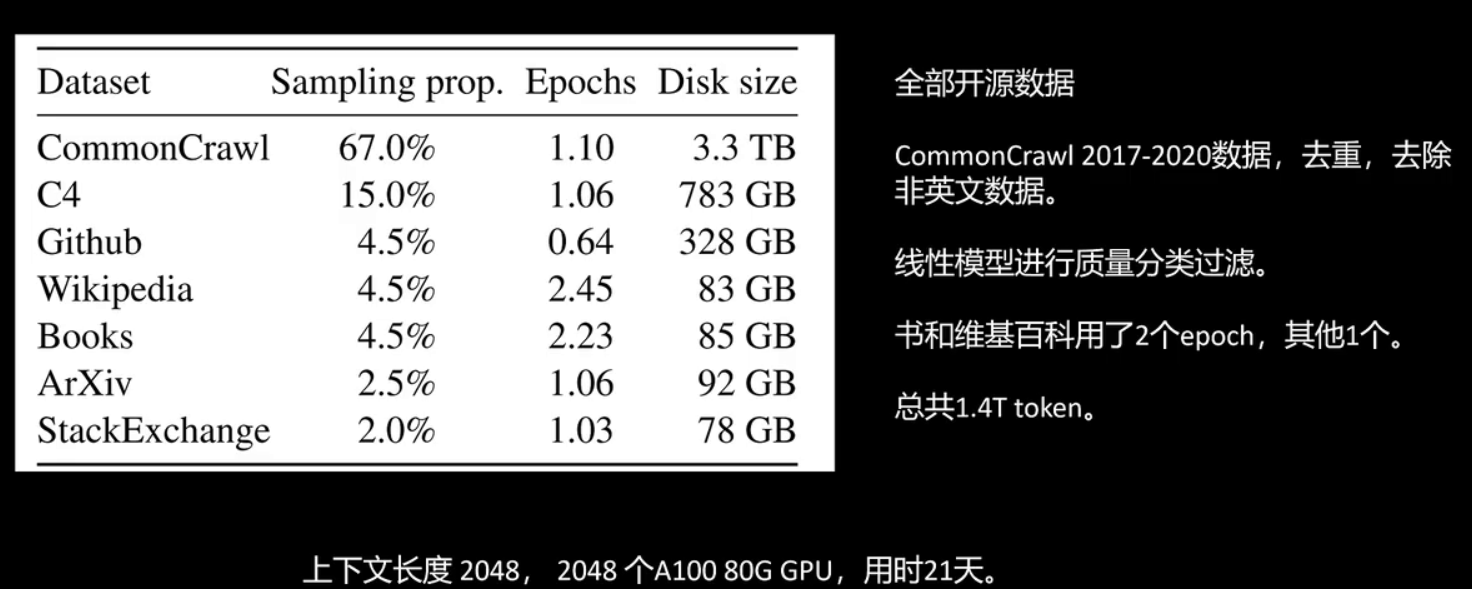
1.2 训练数据和去重处理
接下来看一下llama-1训练使用的数据。llama-1全部采用了公开渠道可以获取的数据,使用了2017至2020年的commoncrawl数据,以及来自书籍和维基百科的文本,并且进行了去重,去掉了非英文数据,用线性模型对文本质量进行了分类。这个线性模型将wikipedia引用的网页作为正例,其他的网页作为负例来训练这个线性模型。来自书和维基百科的文本训练用了两个epoch,其他的文本只用了一个epoch,总共1.4t个token。训练时的上下文长度为2048,用了2048个a100的gpu,训练花费了21天。
1.3 模型架构与gpt对比
llama-1的模型架构与gpt一样,采用了transformer的decoder架构,并进行了以下修改:
第一,与gpt-3相同,将normalization从每个子层的输出位置移至输入位置。
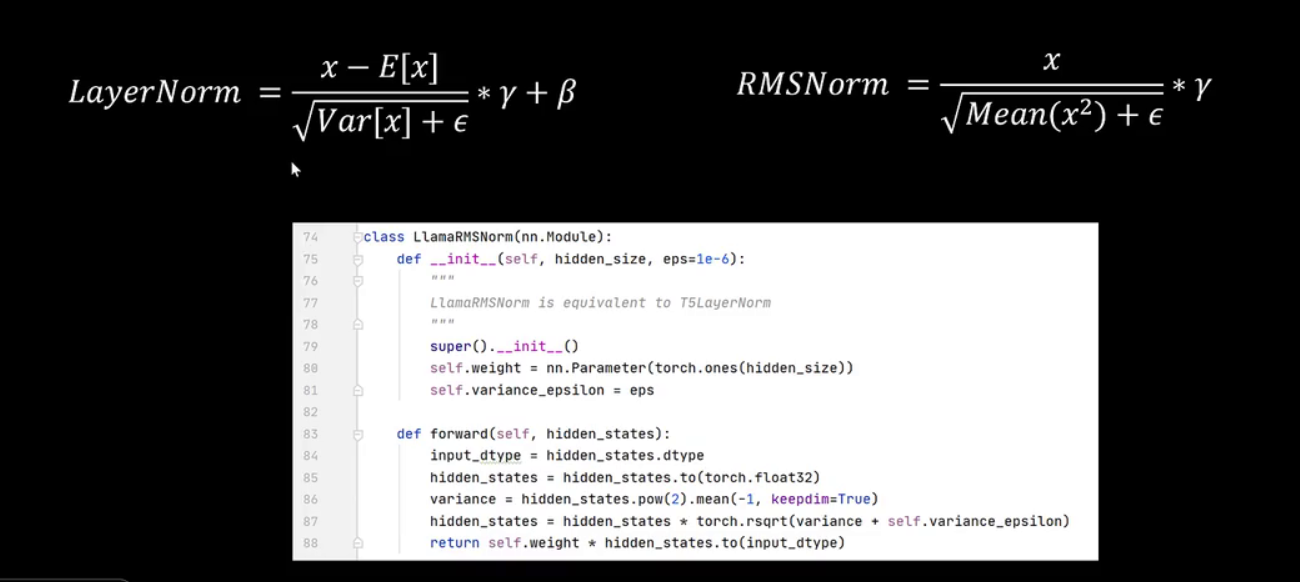
第二,将layernorm改为rmsnorm。
第三,采用旋转位置编码。
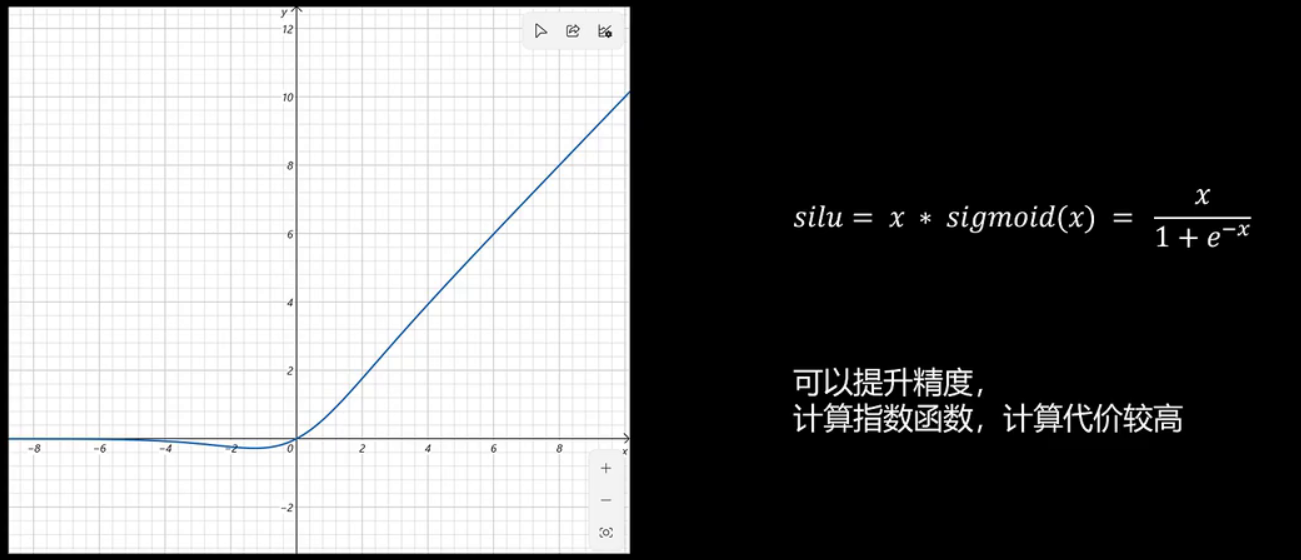
第四,采用silu激活函数。

1.4 训练细节
下面重点讨论rmsnorm和silu激活函数。
rmsnorm是在layernorm的基础上进行了改进。其动机在于:进行normalization时,对特征进行平移不会改变特征的分布,因此可以省略与平移相关的步骤。这包括learnnorm中对输入特征减去均值的操作,以及标准化后进行线性变换时的偏差参数。其公式为x除以根号下x平方的均值,再乘以一个可学习的参数,分母中还包含一个防止除零的小epsilon。查看代码实现,初始化函数中定义了可学习的参数weight,对应公式中的gamma,以及一个极小的epsilon。在forward函数中,对特征进行平方处理,称之为方差,求其均值,随后特征乘以方差的平方根,最终返回时再次乘以weight,即公式中的gamma。
接下来,我们探讨silu激活函数,其公式为x乘以sigmoid x。在接近临界值时,其图形更为平滑。当远离临界值时,函数曲线与silu函数相似。实验表明,silu激活函数通常能提高模型精度,但由于需要计算指数函数,其计算成本较高。
二、llama-2
2.1 开放性、数据量增加、微调chat model
llama2模型,其标题为“open foundation and fine-tuned chat models”。llama2模型的三个关键特点包括:
首先,它具有更高的开放性,允许商业使用;
其次,训练数据量显著增加,体现了meta公司关于增加数据量比增加模型参数更为有效的理念;
最后,通过微调训练chat model,以对标chatgpt。

2.2 训练数据和监督微调
llama2的训练数据比llama1多出40%,达到2万亿个token。其上下文长度从2048翻倍至4096,共发布了7b、13b和70b三个不同大小的版本。监督微调过程中使用了10万条数据,这些数据包括人类提出的问题及其回答。此外,还收集了100万条人类偏好数据,用于对同一问题下模型的多个回答进行人工排序,以供强化学习使用。70b模型在训练中消耗了172万gpu小时。
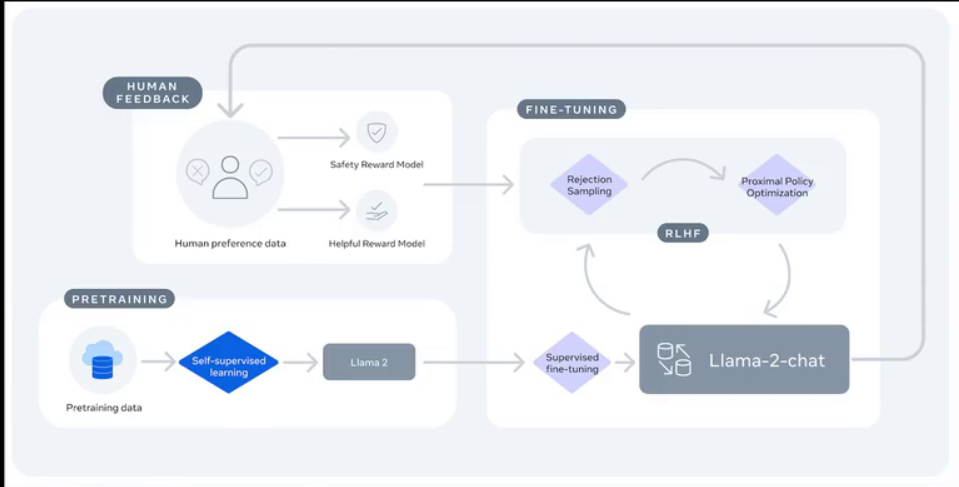
来看一下llama2的训练流程。首先,是在处理好的无标注文本数据上进行自回归预训练。然后,进行监督微调训练。接下来,通过人类偏好数据训练两个模型,一个是安全奖励模型,一个是有用奖励模型。之后,再利用强化学习对模型进行训练,最终得到了llama2 chat模型。强化学习的内容我们将在后续专门讲解,此处若理解困难亦无妨。
通过下面这张图我们可以看到,即使使用了2万亿的token进行训练,不同大小的模型都还有进一步提升的空间。看来数据量还可以更大,后面在训练llama2,meta确实也这么做了。

2.3 模型架构优化:gqa
在模型架构中引入了gqa,即group query attention,这是对multihead attention的一种优化,旨在减少模型参数量及kv cache的大小。后续将详细讨论kv cache。观察下图,左侧为熟悉的multihead attention,每个token的特征生成相同数量的q、k、v头,例如均为8个头。token 1的q将与自身及其他token的k进行注意力计算。再看右侧图,每个token仍生成8个q,但仅生成一个value和一个k。所有q均与其他token及自身唯一的k进行相似度计算,此为multiquery attention。
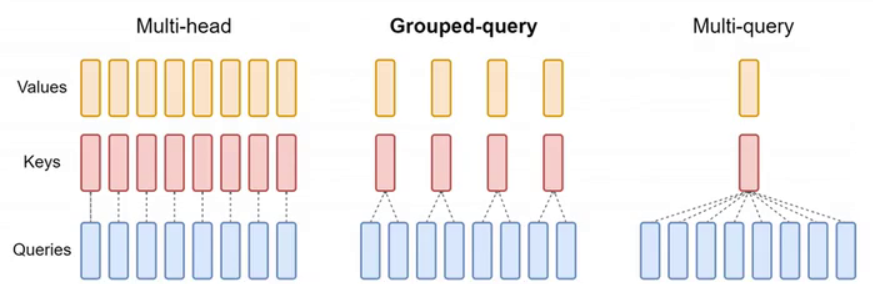
中间图展示的是lama2采用的group query attention,即分组注意力,它是multihead attention与multiquery attention的折中方案。该方法将query分组,例如每两组对应一个k和value。接下来探讨其实现细节。
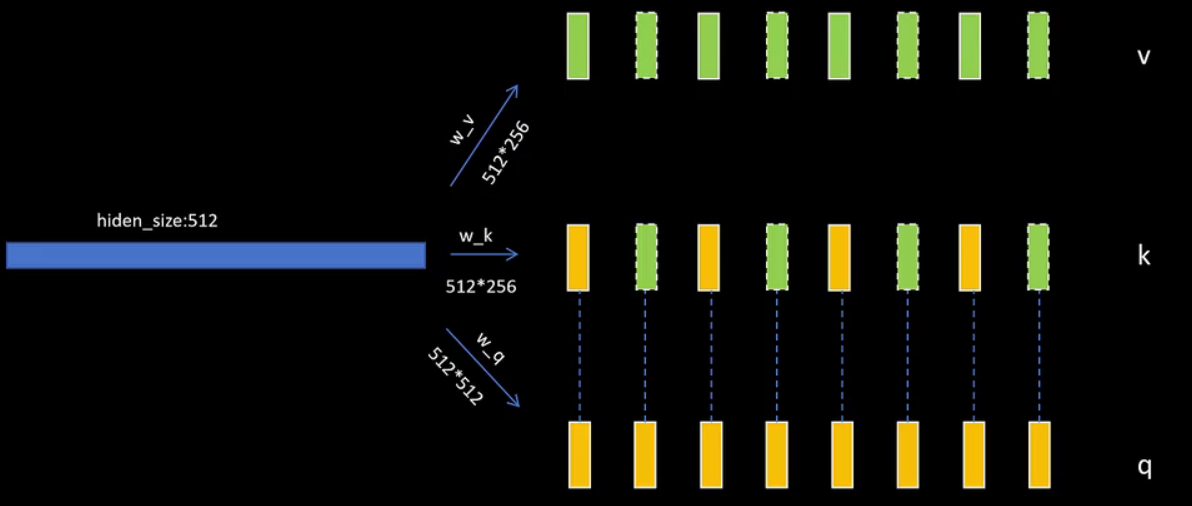
上图是原始的multiheadattention,假设原始的token维度为512,则wq、wk、wv线性层的权重矩阵都为512x512。生成的q、k、v也都是512维,分为8个头,每个头的维度就是64。然后q和k一一对应。接着我们看,如果每两个query一组的话,那么对于v和k向量,对应的wk和wv只需要512x256维度就可以了,这里节省了模型的参数量。这样,k有8个头,q也有8个头,但k和v只有4个头。实现时,为了利用矩阵乘法,还是将k和v的头部都复制一份,这样q、k、v的头就又一一对应了。后面的逻辑就和multiheadattention一致了。
下面代码中定义了 wk,其输出维度为 head 的个数乘以 head 的维度。而 wk 和 wv 的输出维度为 num_key_value_heads 乘以 head 的维度。接着,有一个名为 repeat_kv 的函数,其作用是对 kv 的 head 进行复制。最后,在 forward 函数中,首先对 kv 矩阵进行复制,随后执行标准的 multi-head attention 代码。
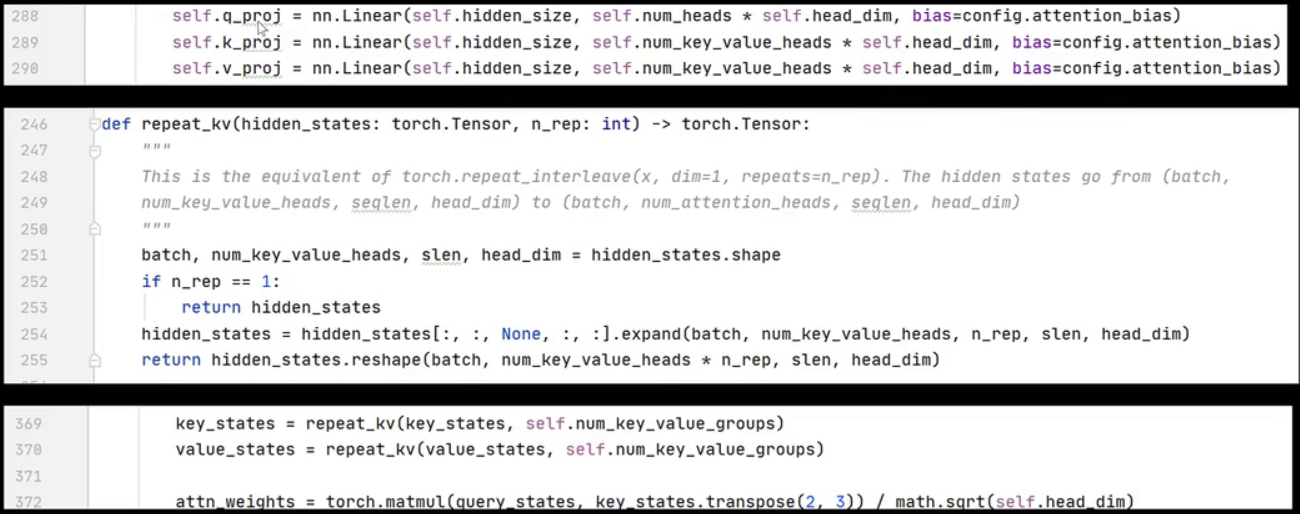
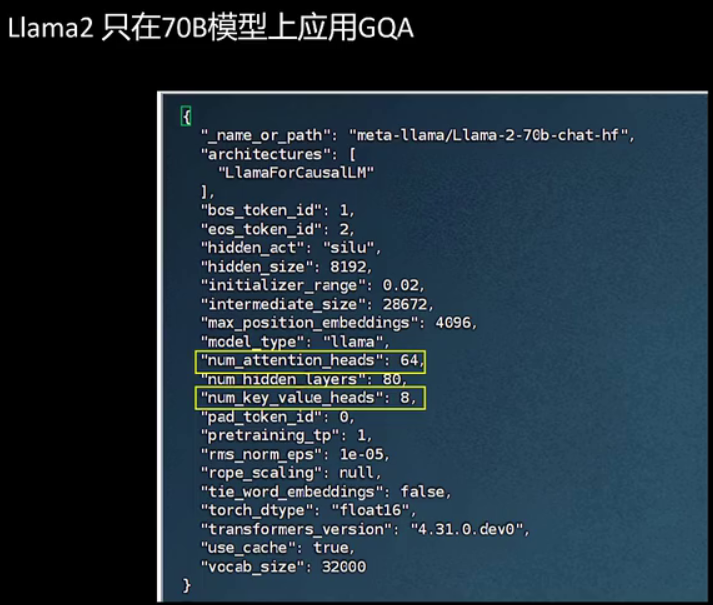
另外需要注意的是,gqa在llama2中仅应用于最大的模型llama70b。在模型的配置文件中可以看到,num_attention_heads为64,num_key_value_heads为8,即8个query共用1个key和value。
三、llama-3
3.1 目标与性能
llma3已经发布了8b和70b的模型,但尚未完成训练。因此,目前还没有详细的技术报告。在此,我们先解读一下llma发布llma3的官方文章。llma3的目标是开发一个能够与最佳商业大模型相媲美的开源大模型。llma3仍在训练中,后续将陆续发布400b的模型,并推出多语言和多模态模型。

llama3的性能远远高于llama2,llama3 8b的模型性能已经远高于llama2 70b的模型。llama3 70b的性能在5项测评中有3项高于gpt4。

3.2 模型架构更新
看一下llma3的模型架构。它的字典大小从32,000个token扩充了4倍,达到了128,000个token,这大大提高了推理效率。例如,原来一个中文被编码为多个token,现在只需要编码成一个token。原来需要多次推理才能输出一个汉字,现在只需要推理一次就可以输出一个汉字。因为字典增大,embedding层和分类头层增加,所以最小的模型参数也从7b变为了8b。另一个改变是,llma2只有70b采用了gqa,但是llma3所有的模型,包括8b模型都使用了分组注意力机制。训练时,序列长度从4096扩充到了8192。
3.3 训练数据与缩放定律
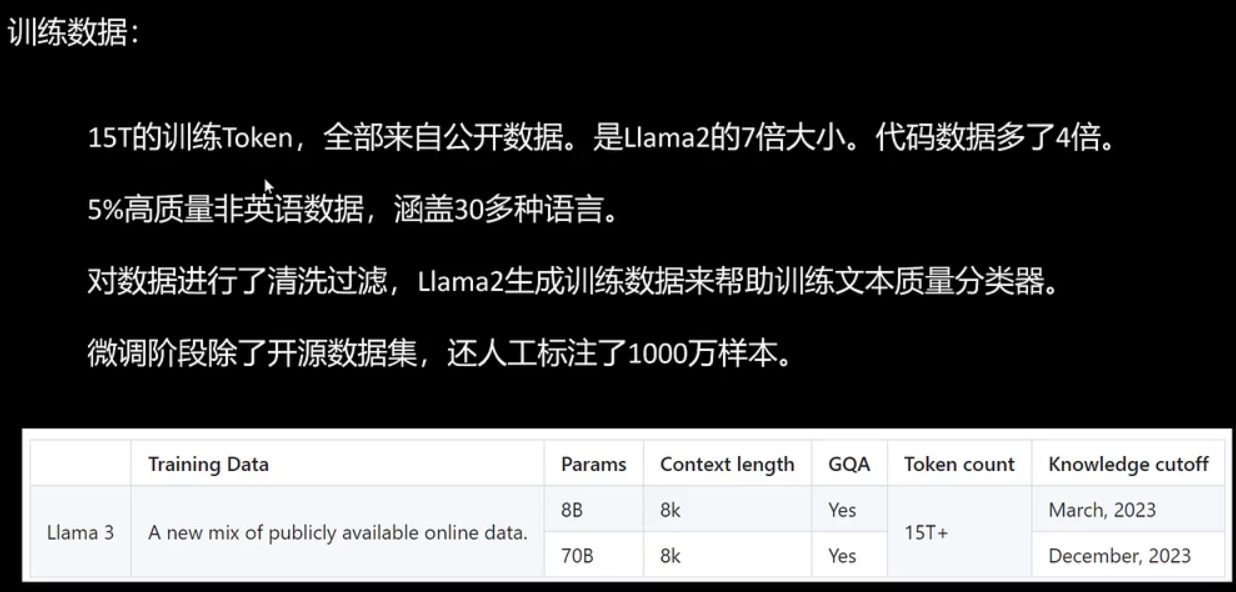
训练数据部分采用了庞大的15t token数据,全部来源于公开数据,数据量是llama2的7倍,其中代码数据量增加了4倍。研究表明,代码数据能有效提升模型的逻辑推理能力。此外,训练数据中包含5%的高质量非英语数据,覆盖30多种语言。所有数据均经过清洗,并利用llama2生成的数据辅助训练文本质量分类器。需要注意的是,这里训练的是数据清洗阶段的文本质量分类器,并非直接使用llama2生成的数据来训练llama3。在微调阶段,除了使用开源数据集外,还人工标注了1000万样本。8b模型的知识截止日期为2023年3月,70b模型的知识截止日期为2023年12月。
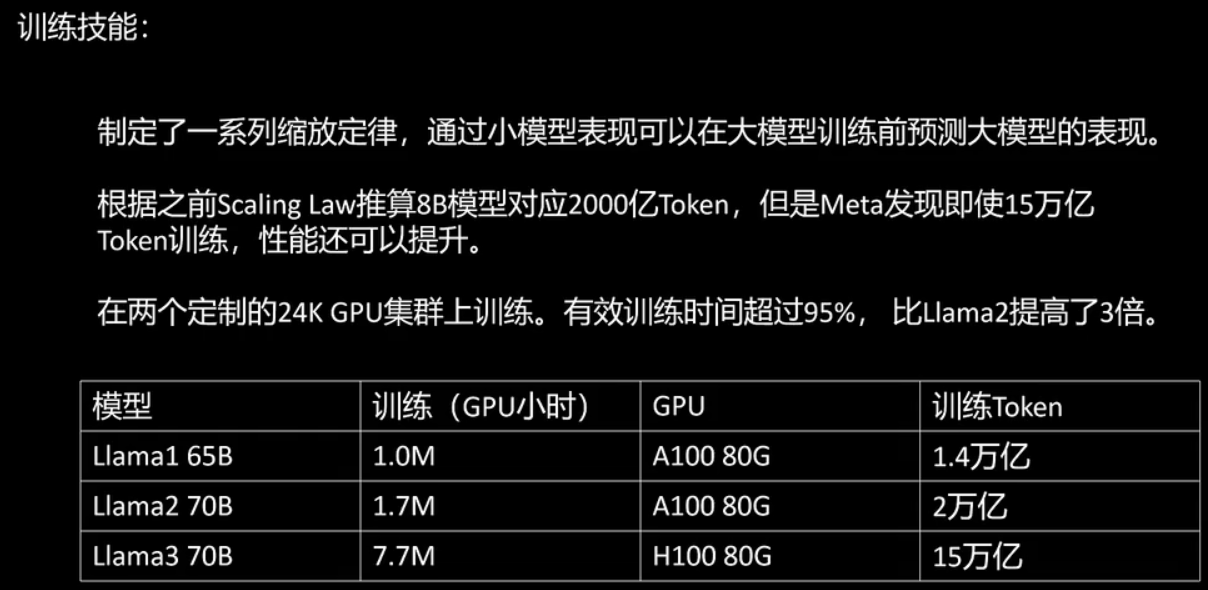
在训练技能方面,meta已经达到了炉火纯青的水平,他们制定了一系列的缩放定律。通过小模型的表现,可以在大模型训练前预测大模型的表现。之前我们提到这是openai的独家技术,现在meta也已掌握。此外,meta强调增加数据量比增加模型参数更为有效。即使是8b的模型,使用15万亿的token进行训练,性能仍未饱和,仍有提升空间。meta还展示了其硬件实力,lama3在两个由24000多个gpu组成的集群上进行训练,使用的是h100 gpu。有效训练时间超过95%,比lama2提高了三倍。我们来看这张表,对比了lama1 65b、lama2 70b、lama3 70b在训练时使用的gpu小时数、gpu型号以及训练用的token数。
3.4 指令微调
最后,我们来看一下llama3的指令微调。在llama2时期,微调后的模型被称为llama2chat,而现在的llama3微调后则称为llama3 instruct。这表明,大型模型不仅限于聊天应用,更多地被用于指令跟随,在智能应用中执行各种任务。llama3的指令微调采用了sft、拒绝采样、ppo和dpo等技术。
四、总结
4.1 技术细节
- 训练数据和去重处理:llama-1使用2017至2020年的commoncrawl数据,书籍和维基百科文本,进行去重和质量分类。
- 模型架构:llama系列模型采用transformer decoder架构,进行了多项优化,如normalization位置调整、rmsnorm、旋转位置编码和silu激活函数。
- 训练细节:特别强调了rmsnorm和silu激活函数的重要性和实现细节。
- 模型架构优化:llama-2引入了gqa,优化了multihead attention,减少了模型参数量和kv cache大小。
- 训练数据与缩放定律:llama-3使用了15t token的公开数据,包括代码数据和多语言数据,强调了增加数据量的重要性。
4.2 性能和影响
- 性能提升:llama-3的性能在多项测评中超越了llama-2和gpt-4。
- 开源社区影响:llama系列的开源特性对研究社区具有积极影响,推动了ai技术的发展和应用。
4.3 指令微调
- llama3指令微调:采用了sft、拒绝采样、ppo和dpo等技术,使模型能够更好地执行指令跟随任务。
4.4 结论
llama系列模型展示了ai多模态大模型在开放性、数据量、模型架构和指令微调等方面的持续进步和创新。通过不断的优化和扩展,这些模型在提高性能的同时,也为ai技术的未来发展奠定了坚实的基础。
推荐阅读:
《aigcmagic星球》,五大aigc方向正式上线!让我们在aigc时代携手同行!限量活动
《三年面试五年模拟》版本更新白皮书,迎接aigc时代
aigc |「多模态模型」系列之onechart:端到端图表理解信息提取模型
ai多模态模型架构之模态编码器:图像编码、音频编码、视频编码
ai多模态模型架构之输入投影器:lp、mlp和cross-attention
ai多模态教程:从0到1搭建visualglm图文大模型案例
智谱推出创新ai模型glm-4-9b:国家队开源生态的新里程碑
技术交流:
加入「aigcmagic社区」群聊,一起交流讨论,涉及 「ai视频、ai绘画、sora技术拆解、数字人、多模态、大模型、传统深度学习、自动驾驶」等多个不同方向,可私信或添加微信号:【lzz9527288】,备注不同方向邀请入群!!





发表评论