一、引言
在人工智能的浪潮中,大型语言模型(llm)已成为推动自然语言处理(nlp)领域进步的关键力量。它们在机器翻译、文本摘要、情感分析等多个领域展现出了卓越的能力。然而,这些强大模型的部署并非易事,传统上需要专业的知识来配置复杂的运行环境和依赖关系,这无疑增加了使用门槛,限制了技术的普及和应用。
随着技术的发展,我们一直在寻求更高效、更便捷的方式来部署和运行这些模型。正是在这样的背景下,llamafile应运而生,它是一项创新的技术,旨在简化大型语言模型的部署流程,让ai的力量触手可及。
llamafile,一个由mozilla创新团队推出的项目,通过将模型权重和运行环境封装进单个可执行文件中,彻底改变了大型语言模型的分发和运行方式。这项技术的核心在于它的简洁性和易用性,使得即使是没有深厚技术背景的用户也能够轻松地在自己的计算机上部署和运行大型语言模型。

二、什么是llamafile?
llamafile是一种创新的解决方案,它允许用户通过单一的文件来部署和运行大型语言模型(llm)。这种文件包含了模型的所有权重和必要的运行时环境,使得用户无需进行繁琐的环境配置和依赖安装。(一键部署运行)
1、设计目标
- 简化部署:降低技术门槛,使得部署大型模型变得简单快捷。
- 跨平台兼容性:支持多种操作系统,包括但不限于windows、macos、linux。
- 独立运行:不依赖外部环境,减少了运行时出现问题的可能性。
2、技术构成
- llama.cpp:一个c++库,为模型提供运行所需的底层支持。
- cosmopolitan libc:一个跨平台的c标准库,确保了llamafile在不同操作系统上的兼容性。
- 模型权重:直接嵌入到llamafile中,无需额外下载或配置。
3、与传统部署方式的对比
- 环境依赖:传统部署需要用户配置python环境、安装依赖库等,而llamafile无需这些步骤。
- 安装复杂性:传统部署可能需要编译代码、设置环境变量等,llamafile则通过双击运行来替代。
- 分发效率:传统方式可能需要通过复杂的脚本或容器技术来分发模型,llamafile则通过单个文件实现快速分发。
4、一键部署的优势
- 快速启动:用户可以迅速开始使用模型,无需等待漫长的安装过程。
- 易于分享:开发者可以轻松地将模型分享给其他用户,无需担心环境差异导致的问题。
- 降低维护成本:减少了因环境问题导致的维护工作,提高了模型的稳定性和可靠性。
三、核心特性
1、一键部署的便捷性
llamafile最引人注目的特性之一是它的一键部署能力。用户只需下载相应的llamafile文件,然后执行这个文件,即可启动模型。这种便捷性的背后是大量的工程努力,将模型的复杂性封装在用户友好的界面之后。
2、跨平台支持
llamafile支持多种操作系统,包括但不限于windows、macos、linux等。这种跨平台的特性使得无论用户使用的是哪种操作系统,都能够轻松地部署和运行大型语言模型。
3、独立可执行文件
每个llamafile都是一个独立的可执行文件,这意味着它们包含了运行模型所需的所有依赖和配置。用户无需担心环境配置问题,也不需要安装额外的软件或库。
4、简化的分发流程
通过将模型和运行环境打包到一个文件中,llamafile简化了模型的分发流程。开发者可以轻松地分享他们的模型,而用户则可以立即开始使用,无需复杂的安装步骤。
5、技术细节
- 权重文件的嵌入:模型的权重文件被直接嵌入到llamafile中,这不仅减少了外部依赖,也加快了模型的加载速度。
- 自包含的运行环境:llamafile包含了一个精简的运行环境,这使得它能够在不同的系统上以一致的方式运行。
- 动态链接库的优化:在需要时,llamafile可以动态链接到系统上的特定库,以提供额外的功能,如gpu加速。
6、用户体验
- 无需专业知识:即使是没有深厚技术背景的用户,也能够轻松地使用llamafile。
- 快速反馈:用户可以立即看到模型的运行结果,无需等待长时间的编译或环境搭建。
- 灵活的交互方式:用户可以通过命令行、web界面或其他客户端与模型进行交互。
7、安全性和隐私
- 本地运行:由于模型在本地运行,用户的数据处理可以保持在本地,增强了隐私性。
- 开源透明:llamafile的开源特性意味着用户可以查看和修改模型的运行代码,增加了透明度。
四、部署流程详解
1、下载模型
部署大型语言模型的第一步是获取模型文件。用户可以从huggingface、modelscope等平台下载所需的llamafile。这些文件通常包含了模型的权重和配置信息,并且已经过优化,以确保在不同系统上都能高效运行。
当前llamafile集合中的模型列表:
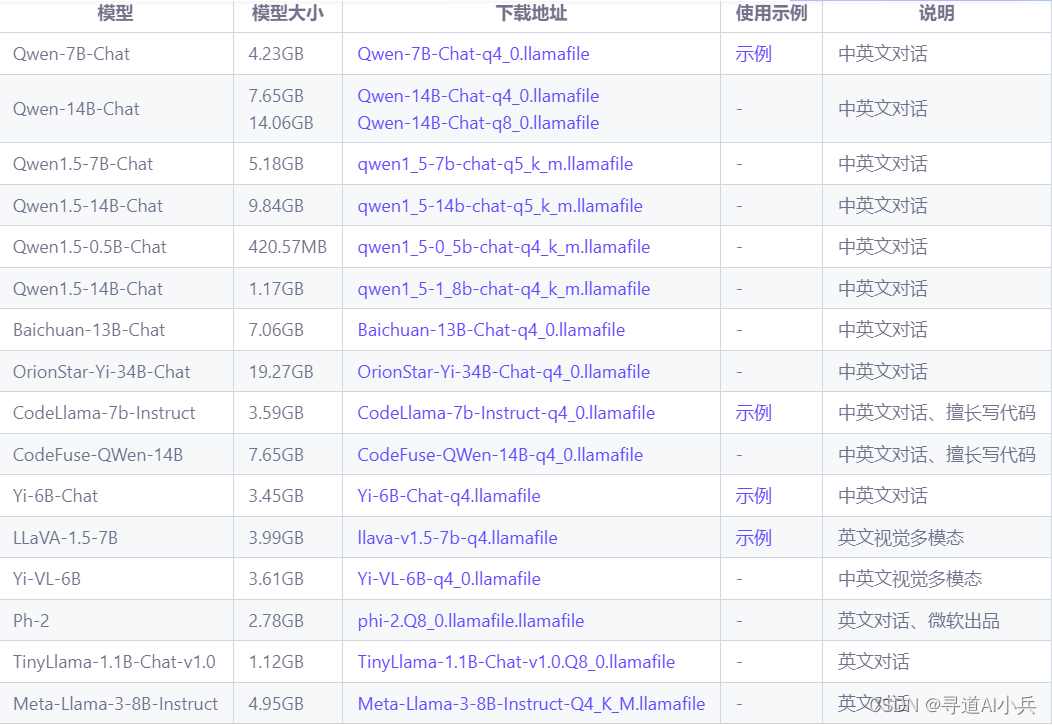
2、操作系统特定的运行步骤
-
linux/macos:
- 下载llamafile到本地。
- 为文件添加执行权限:
chmod +x filename.llamafile。 - 运行模型:
./filename.llamafile。
-
windows:
- 下载并重命名llamafile,添加
.exe后缀:filename.llamafile.exe。 - 双击文件或通过命令行运行。
- 下载并重命名llamafile,添加
3、运行环境配置
- 环境依赖:大多数情况下,llamafile不需要额外的环境依赖,因为它是一个自包含的可执行文件。
- 特殊配置:对于需要gpu加速的情况,可能需要根据所使用的硬件安装相应的驱动程序和sdk。
4、访问web界面
一旦模型运行起来,用户可以通过web界面与模型进行交互。通常,llamafile会在本地启动一个web服务器,用户只需在浏览器中输入对应的url(如http://127.0.0.1:8080)即可访问。
5、命令行交互
除了web界面,用户也可以通过命令行与模型进行交互。这为需要自动化或脚本化交互的用户提供了一个灵活的选择。
6、模型api的使用
对于开发者来说,llamafile还提供了类似于openai的api接口,使得开发者可以通过编程方式与模型进行交互,实现更复杂的应用场景。
7、部署实践样例
7.1 模型下载部署运行
windows 系统 (4g以内)
1)模型下载
下载地址:
qwen1.5-14b-chat(1.17gb)
qwen1_5-1_8b-chat-q4_k_m.llamafile
https://www.modelscope.cn/api/v1/models/bingal/llamafile-models/repo?revision=master&filepath=qwen1.5-1.8b-chat%2fqwen1_5-1_8b-chat-q4_k_m.llamafile
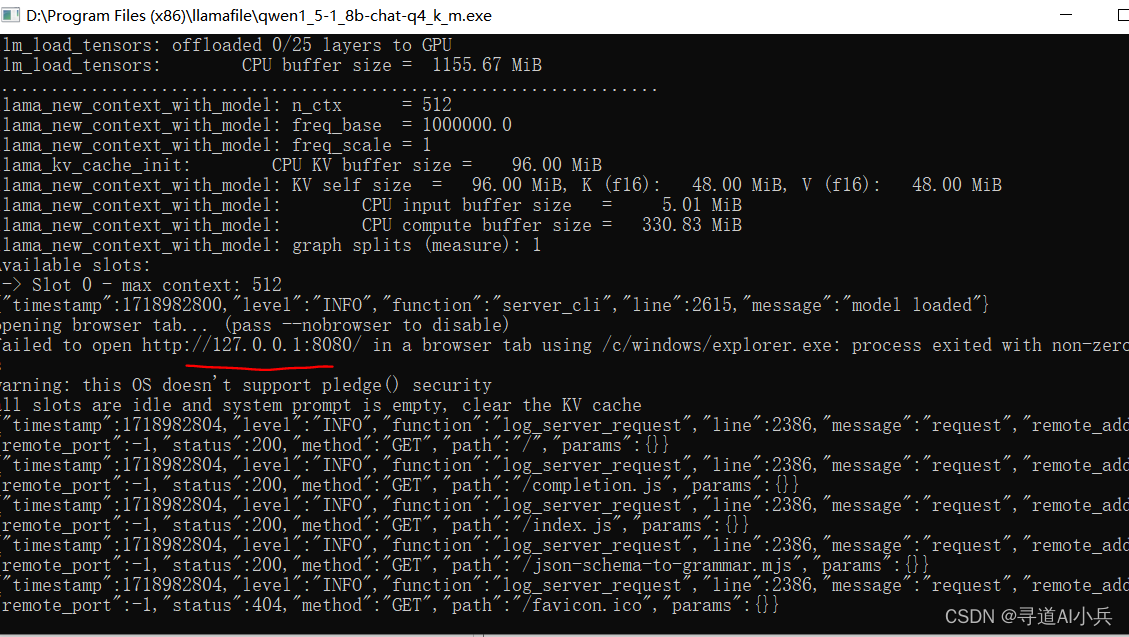
2)模型运行
修改文件名,增加 .exe 后缀,如改成 qwen1_5-1_8b-chat-q4_k_m.exe
双击运行或者打开 cmd 命令行窗口,进入模型所在目录
.\qwen1_5-1_8b-chat-q4_k_m.exe
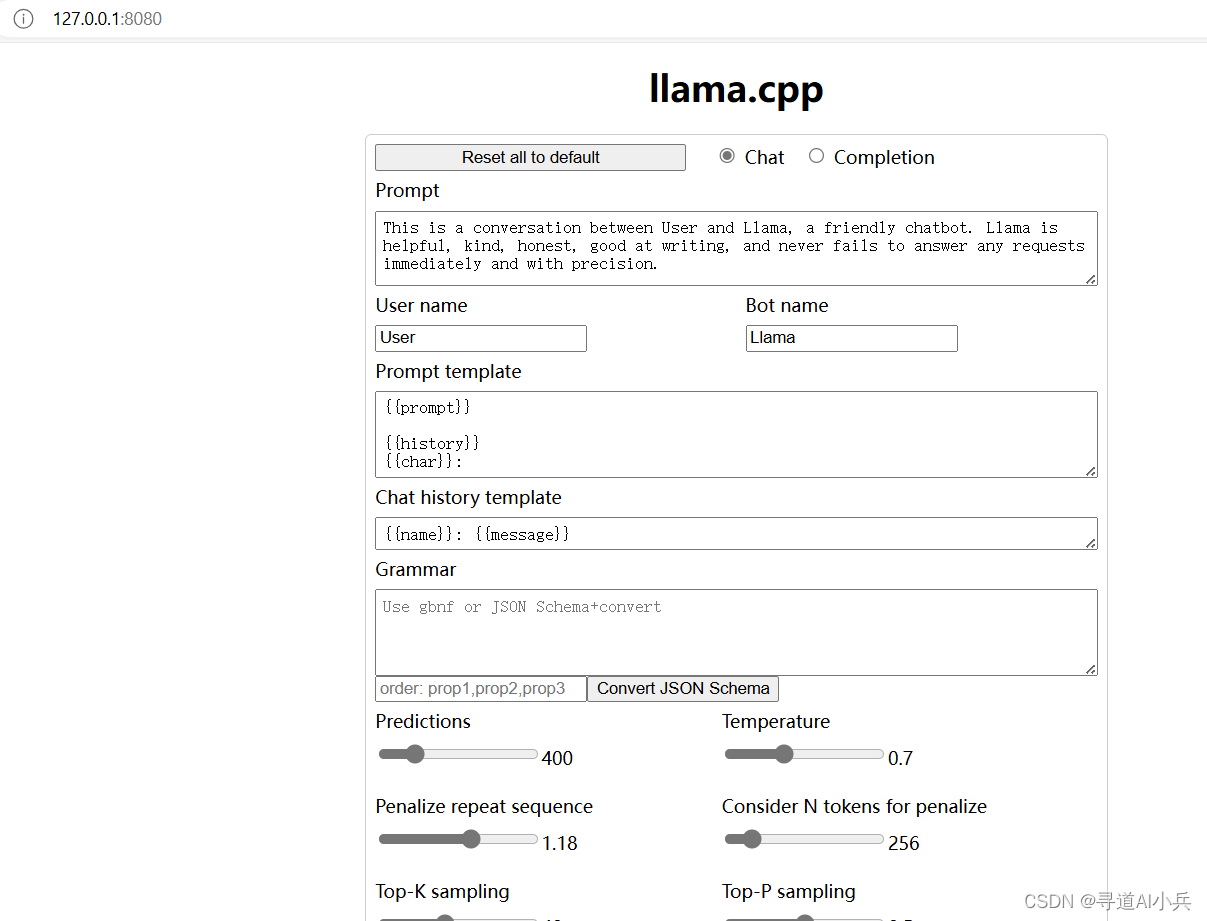
3)模型访问
浏览器打开 http://127.0.0.1:8080 即可开始聊天
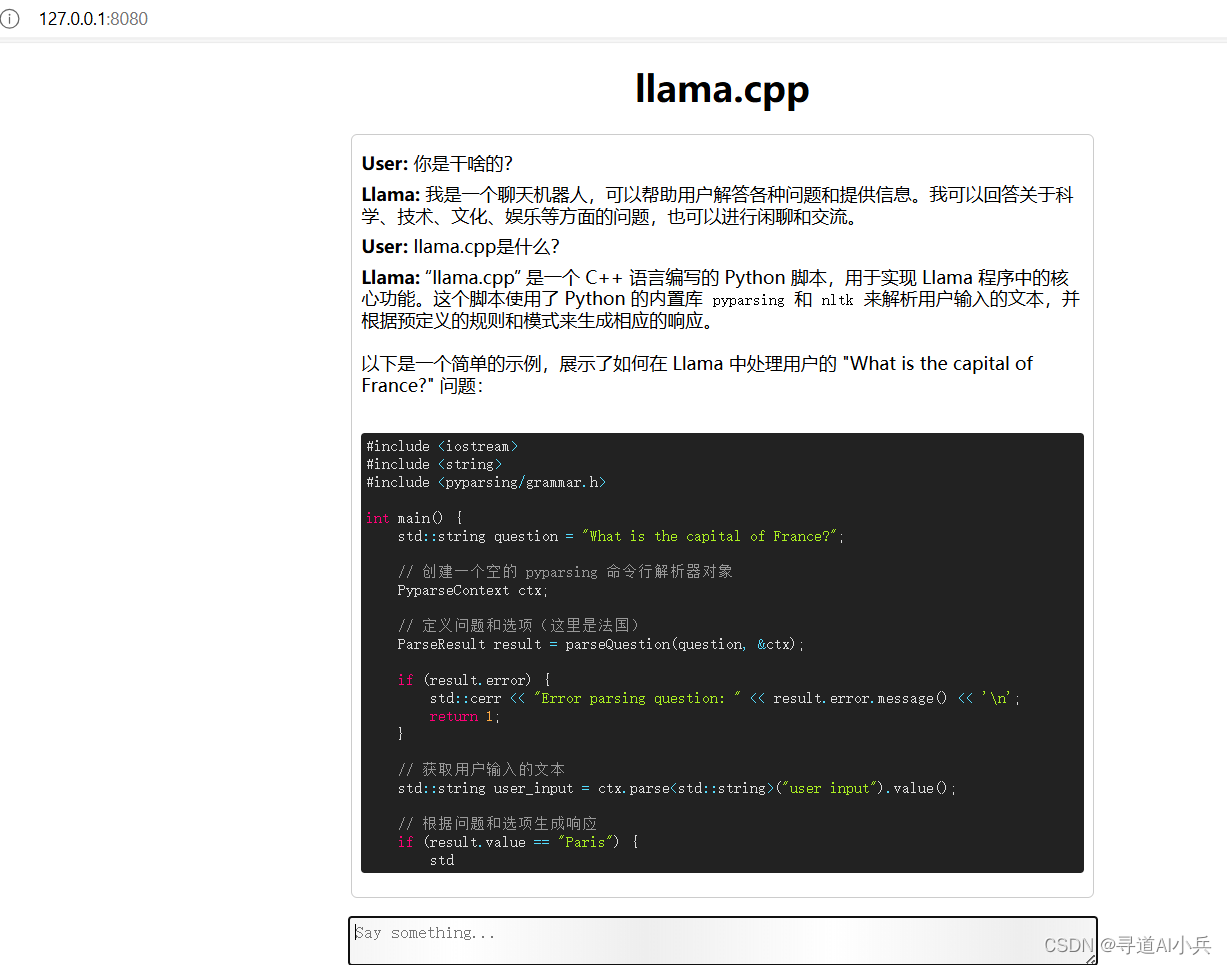
4)聊天对话测试
windows 系统 (大于4g)
windows 系统不支持单个 exe 文件超过 4gb 的限制,所以需要分别下载 llamafile 和 gguf 模型运行;此外,也可以通过 windows 的 wsl 子系统(linux)运行,同样可以绕过 4gb 的限制
1)模型下载
下载llamafile:
https://www.modelscope.cn/api/v1/models/bingal/llamafile-models/repo?revision=master&filepath=llamafile-0.6.2.win.zip
下载后解压得到 llamafile-0.6.2.exe 文件。
下载 qwen1.5-7b-chat-gguf 模型:
qwen1.5-7b-chat-gguf: 70 亿参数的 q5_k_m 量化版本,5.15gb。
https://www.modelscope.cn/api/v1/models/qwen/qwen1.5-7b-chat-gguf/repo?revision=master&filepath=qwen1_5-7b-chat-q5_k_m.gguf
2)模型运行
打开 cmd 或者 terminal命令行窗口,进入模型所在目录
.\llamafile-0.6.2.exe -m .\qwen1.5-7b-chat-q5_k_m.gguf -ngl 9999 --port 8080 --host 0.0.0.0
3)模型访问
浏览器打开 http://127.0.0.1:8080 即可开始聊天
linux、mac 系统
终端运行(注意 mac 系统可能需要授权,在【设置】→ 【隐私与安全】点击【仍然打开】进行授权)
./qwen1_5-1_8b-chat-q4_k_m.llamafile
浏览器打开 http://127.0.0.1:8080 即可开始聊天
7.2 模型api调用
#!/usr/bin/env python3
from openai import openaiclient = openai(
base_url="http://localhost:8080/v1", # "http://<your api-server ip>:port"
api_key = "sk-no-key-required"
)
completion = client.chat.completions.create(
model="llama_cpp",
messages=[
{"role": "system", "content": "您是一个人工智能助手。您的首要任务是帮助用户实现他们的请求,以实现用户的满足感。"},
{"role": "user", "content": "写一个与龙有关的故事"}
]
)
print(completion.choices[0].message)
7.3 可选参数说明
-- ngl 9999 表示模型的多少层放到 gpu 运行,其他在 cpu 运行,如果没有 gpu 则可设置为 -ngl 0 ,默认是 9999,也就是全部在 gpu 运行(需要装好驱动和 cuda 运行环境)。
-- host 0.0.0.0 web 服务的hostname,如果只需要本地访问可设置为 --host 127.0.0.1 ,如果是0.0.0.0 ,即网络内可通过 ip 访问。
-- port 8080 web服务端口,默认 8080 ,可通过该参数修改。
-- t 16 线程数,当 cpu 运行的时候,可根据 cpu 核数设定多少个内核并发运行。
-- 其他参数可以通过 --help 查看。
五、llamafile支持说明
1、llamafile支持以下操作系统(最低标准安装说明)
2、llamafile支持以下cpu类型
3、llamafile 对 gpu 的支持说明
六、优势与局限性
1、优势概述
- 易用性: llamafile极大地简化了部署大型语言模型的复杂性,使得用户无需深入了解底层技术即可运行模型。
- 跨平台性: 支持多种操作系统,包括windows、macos、linux等,提供了广泛的适用性。
- 快速部署: 用户可以迅速下载并运行模型,无需等待漫长的安装过程。
- 资源共享: 易于分享的特性促进了知识的传播和资源的共享,有助于社区的协作和创新。
2、局限性探讨
-
硬件依赖性:尽管llamafile简化了软件部署,但运行大型语言模型仍然需要相对较强的硬件支持,特别是对于需要大量计算资源的模型。用户可能需要高性能的cpu或gpu来确保模型运行的流畅性。
-
更新维护:模型和底层库的更新可能需要用户定期下载新的llamafile文件,这可能会带来额外的维护工作。此外,每次更新后,用户可能需要重新适应新的功能或接口变化。
-
特定功能的限制:某些特定功能或优化可能需要额外的配置或依赖,这可能会增加部署的复杂性。例如,利用gpu加速可能需要用户进行特定的设置或安装相应的驱动程序。
-
安全性和隐私问题:虽然本地运行模型可以增强数据隐私,但这也意味着用户需要对模型的安全性负责。如果llamafile文件来源不可靠,可能会带来安全风险。
-
可定制性的限制:llamafile作为一个封装好的执行文件,可能在某些情况下限制了用户对模型进行定制或扩展的能力。对于需要深度定制模型以适应特定应用场景的用户来说,这可能是一个限制。
-
错误诊断和调试难度:由于llamafile封装了模型和环境,一旦出现问题,用户可能难以快速定位和解决问题。相比于开放的环境,黑盒式的部署可能会增加调试的难度。
-
平台兼容性问题:虽然llamafile支持多平台,但在一些特定的系统配置或操作系统版本上可能会出现兼容性问题,需要额外的调整或等待开发者发布补丁。
用户应根据自己的需求和资源情况,权衡llamafile的优势和局限性,选择最合适的部署方案。
七、结语
llamafile的意义
llamafile的推出标志着大型语言模型部署方式的重要转变。它不仅降低了技术门槛,还扩大了ai技术的受众范围,使得更多的人能够接触和利用这一强大的技术。
对开发者和企业的影响
对于开发者而言,llamafile提供了一个快速原型和测试模型的工具,加速了开发流程。对于企业来说,它简化了产品的集成和部署过程,有助于快速响应市场变化。
对ai技术普及的贡献
llamafile通过简化部署流程,为ai技术的普及做出了重要贡献。它让更多人能够体验到ai的强大能力,激发了对ai技术的兴趣和探索。
未来展望
随着技术的不断发展,我们期待llamafile能够继续进化,解决现有的局限性,提供更加强大和灵活的模型部署方案。同时,我们也希望看到更多的创新工具和平台出现,共同推动ai技术的进步。
最后的思考
llamafile是ai领域的一个重要里程碑,但它只是开始。随着技术的不断进步,我们期待一个更加开放、易用和高效的ai生态系统的建立,让每个人都能享受到ai带来的便利和乐趣。
相关资料链接
llamafile 模型合集:https://www.modelscope.cn/models/bingal/llamafile-models/
llamafile github:https://github.com/mozilla-ocho/llamafile
llamafile 中文使用指南:https://www.bingal.com/posts/ai-llamafile-usage/

🎯🔖更多专栏系列文章:aigc-ai大模型开源精选实践


发表评论