在之前的篇章《【aigc】本地部署 ollama(gguf) 与项目整合》中我们已经使用 ollama 部署了一个基于预量化(gguf)的 qwen1.5 模型,这个模型除了提供研发使用外,我还想提供给公司内部使用,因此还需要一个 ui 交互界面。
显然,这对于我们开发人员来说不是什么难事(毕竟 ollama 已经提供了相对比较完善的 api 接口了),但都 2024 年了与其自己开发还不如先找个开箱即用的…你看,这不已经有大神开发出 open-webui 了吗,我们开箱即用即可。
本文将记录部署过程中遇到的问题以及解决方式,希望对你有所帮助(open-webui 采用 docker 进行部署)。
1. 无法访问 huggingface 官网问题
由于 open-webui 有提供模型下载功能,因此需要在 docker 启动命令中添加 hf_endpoint 环境变量:
sudo docker run -d \
...
-e hf_endpoint=https://hf-mirror.com \
...
ghcr.io/open-webui/open-webui:main
hf_endpoint 将指向国内 hf-mirror 镜像站。
2. docker host 模式(ollama 宿主机直接部署的话)
open-webui 容器采用 host 模式是最方便的的做法。由于我的 ollama 是宿主机直接部署的,open-webui 容器host 模式能够直接通过 127.0.0.1 进行通讯。如果你的 ollama 是 docker 容器,那么你可以将 open-webui 部署在与 ollama 同一个网络中,然后通过桥接只公开 open-webui 访问。
在启动命令中还需要设置环境变量 ollama_base_url 来指定 ollama 的访问地址:
sudo docker run -d \
--network=host \
-e hf_endpoint=https://hf-mirror.com \
-e ollama_base_url=http://127.0.0.1:11434 \
...
ghcr.io/open-webui/open-webui:main
3. 关于镜像拉取
有人说 ghcr.io/open-webui/open-webui 镜像拉取很慢需要通过 docker proxy 镜像加速 进行转换。这个… 我没有这种感受。各人看自己的情况吧,若感觉到慢的话还是先转换一下。
4. 数据挂载
open-webui 是需要注册使用的。注册数据会保存到容器内部,因此在 docker 部署时还需要挂载数据目录到宿主机以免发生误删容器导致数据丢失的情况。
sudo docker run -d \
--network=host \
-v /home/ubuntu/documents/open-webui/data:/app/backend/data \
-e hf_endpoint=https://hf-mirror.com \
...
ghcr.io/open-webui/open-webui:main
5. 其他配置项
sudo docker run -d \
--network=host \
-v /home/ubuntu/documents/open-webui/data:/app/backend/data \
-e hf_endpoint=https://hf-mirror.com \
-e ollama_base_url=http://127.0.0.1:11434 \
-e default_user_role=user \
-e default_models=qwen1 5-14b \
-e enable_image_generation=true \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
- default_user_role:默认用户类型
- default_models:默认模型
- enable_image_generation:是否能够生成图片(使用 sd 模型时需要建议开启)
配置完以上信息后就可以启动容器了。这时我们通过日志可以看到 open-webui 在创建 webui_secret_key 文件
no webui_secret_key provided
generating webui_secret_key
loading webui_secret_key from .webui_secret_key
...
info: started server process [1]
info: waiting for application startup.
在所有文件都创建后才会真正启动
___ __ __ _ _ _ ___
/ _ \ _ __ ___ _ __ \ \ / /__| |__ | | | |_ _|
| | | | '_ \ / _ \ '_ \ \ \ /\ / / _ \ '_ \| | | || |
| |_| | |_) | __/ | | | \ v v / __/ |_) | |_| || |
\___/| .__/ \___|_| |_| \_/\_/ \___|_.__/ \___/|___|
|_|
v0.1.122 - building the best open-source ai user interface.
https://github.com/open-webui/open-webui
info:apps.litellm.main:start_litellm_background
info:apps.litellm.main:run_background_process
info:apps.litellm.main:executing command: ['litellm', '--port', '14365', '--host', '127.0.0.1', '--telemetry', 'false', '--config', '/app/backend/data/litellm/config.yaml']
info: application startup complete.
info:apps.litellm.main:subprocess started successfully.
这时可通过浏览器输入 http://127.0.0.1:8080 进行访问。
6. windows 无法连接问题
若 ollama 是部署在 windows,且 open-webui 是部署在远程的机器上的话会发现 open-webui 无法远程访问 ollama 。这时 ollama 虽然已在 windows 上正常运行,但你还需要配置一下环境变量。如下图:
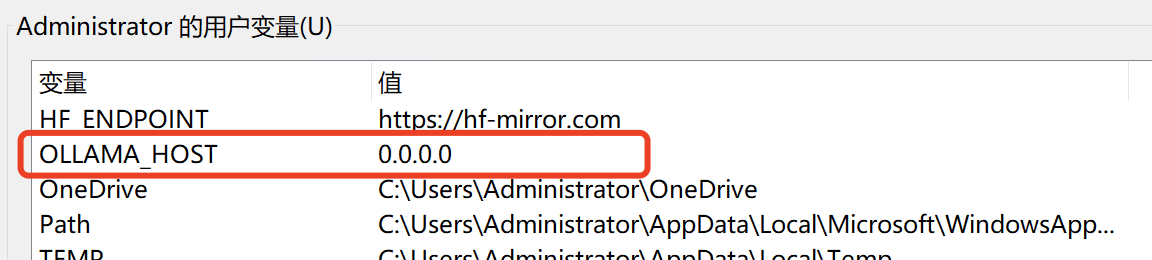
这样 ollama 才能够公开访问。
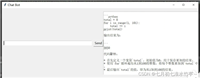
最后,访问 http://127.0.0.1:8080 ,在完成注册后可以看到以下页面(与 chatgpt 一个样):
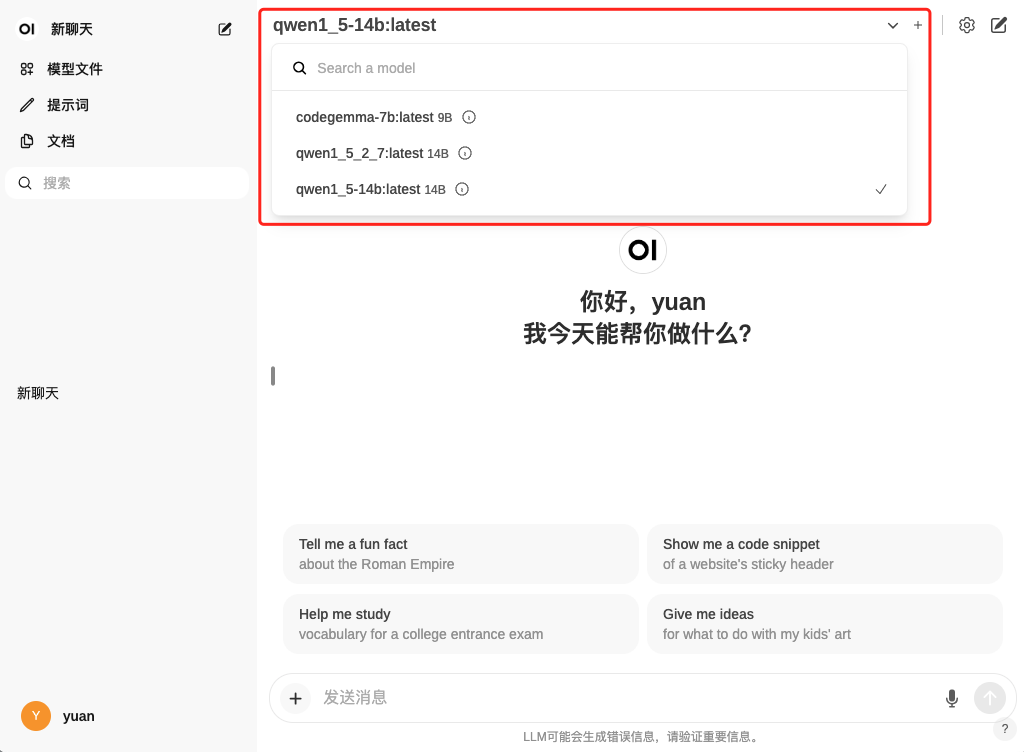
左上角可以选择 ollama 现存模型。但是在你真正使用之前我还建议你先做下面的一步操作:
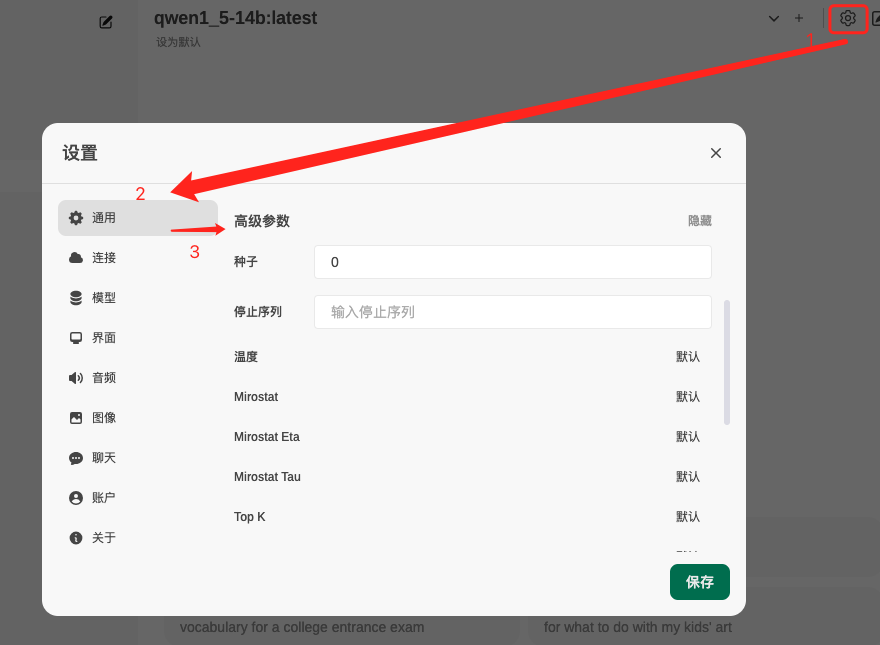
打开“设置”对话框选择“通用”,再选择高级参数“显示”之后找到“保持活动”:
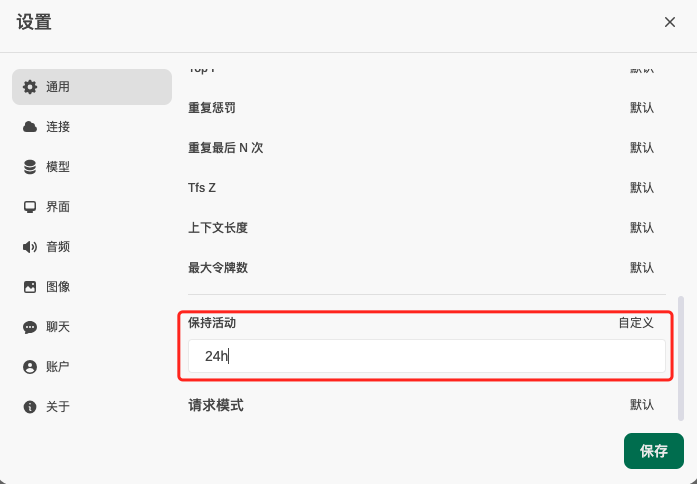
这里填写一个较大的数。因为 gguf 预量化模型的本质是需要将模型加载到内存来使用的,如果“保持活动”参数过小(默认 5 分钟),模型就会在规定的时间后进行释放,需要用到的时候又要重新加载,而这个加载过程将会非常缓慢(相对于使用 gpu 模式来说),因此这里我设置了 24 小时,先保证它能够在办公时间内能够快速响应。
之后就能愉快地与人工智能玩耍了,enjoy!
发表评论