深度测评:sd3模型表现如何?实用教程助你玩转stable diffusion 3 ,最强sd3模型使用攻略,附comfyui实操

sd3模型到底如何?stablediffusion3全面评测!如何使用comfyui遍历题词 | 模型?
大家好,我是猫头虎。今天我要给大家带来一篇关于stable diffusion 3 (sd3) 模型的全面评测和使用指南。作为刚刚开源的最新一代模型,sd3在架构、性能和功能上都有了显著的提升。本期内容不仅会详细解析sd3的各项改进,还会教大家如何通过comfyui进行高效的批处理操作和提示词测试。无论你是ai绘画的新手还是老手,相信这篇文章都能给你带来实用的指导和灵感。话不多说,我们马上开始吧!
本文大纲
- sd第三代模型介绍
- sd3与之前架构的不同
- 基于sdxl的训练
- tve解码部分的增强
- 提示理解的完善
- 三种clip编码的采用
- 模型后缀的含义和特性
- sd3与之前架构的不同
- config ui的批处理操作
- 工作流的介绍
- 基础工作流
- 提词强化工作流
- 传统放大工作流
- 动态提示词插件的使用
- 批量生成图像的方法
- 工作流的介绍
- 模型和资源的获取
- 访问liblib网站获取模型和资源
- 下载和使用题词卡片
- 服务器配置和文件管理
- 模型比较和测试
- 不同模型的生成效果比较
- 提示词的调整和优化
- 在线生成与本地生成的对比
关键词
- sd第三代模型
- config ui
- 批处理操作
- clip编码
- 动态提示词插件
- 模型比较
- 在线生成
适合阅读人群
- 对ai模型和图像生成技术感兴趣的技术人员
- 需要使用或了解sd第三代模型的研究人员
- 对config ui和批处理操作有需求的设计师和开发者
- 希望了解最新ai技术和资源获取方法的用户
术语解释
- sd3: sd第三代模型,基于sdxl进行训练,增强了tve解码部分,改善了对提示的理解和元素融合能力。
- config ui: 配置用户界面,用于管理和操作批处理工作流。
- clip编码: 一种编码技术,sd3采用了三种clip编码,增加了文本编码器,训练数据量更大。
- 动态提示词插件: 一种插件,可以在manager中搜索“dynamic”,安装后可以在新建节点处显示动态提示词,使用通配符文件进行随机调用。
- liblib: 一个资源网站,提供模型和资源下载,支持在线生成。
本期我们将探讨刚刚开源的sd第三代模型。此外,我们还会介绍一些config ui的批处理操作,以配合我们的提示词测试该模型。话不多说,我们直接进入sd官网。

- sd3架构基于sdxl训练,增强了tve解码部分,通道数增至16。
- sd3改善了提示理解和元素融合,能更精确控制画面。
- 新一代模型采用三种clip编码,增加了一个文本编码器,训练数据量达到2b参数。
- tugiface官网提供不同后缀的模型,无后缀模型不含clip编码,带clip标识的包含基础clip编码,t5xxl新增第三种clip编码。
- 模型精度有fp16和8位,大参数模型提供fp16,体积达15g,官方模型至少需12g显存。
- text encoders部分需额外加载clip模型,国内用户需下载并加载这些模型。
最佳访问的资源网站是liblib。在之前讲解stable diffusion时,我曾提及此网站。目前,liblibai是国内较为完善的绘画模型资源网站,不仅提供常用模型,还可在其平台上查看相关内容。
平时都有一些激励活动,所以说有很多原创作者在这个地方玩游戏。

这些模型在cvt网站上不一定能找到,同时一些热门的模型也不一定能找到。
最重要的是,对于不熟悉网络配置的朋友们来说,这个功能非常便捷,可以直接访问,使用起来十分方便。
- sd3模型是目前排名第一的模型,已在其网站上架。
- sd3模型包含三个编码器,无需单独加载clip编码模型。
- 王智能的信息将在视频简介下方提供。
- libreview网站支持v3模型生成,其在线生成速度与4090相当。
- huggenface提供的config ui样本工作流包括basic基础工作流、prompt强化工作流和传统放大工作流(upscale)。
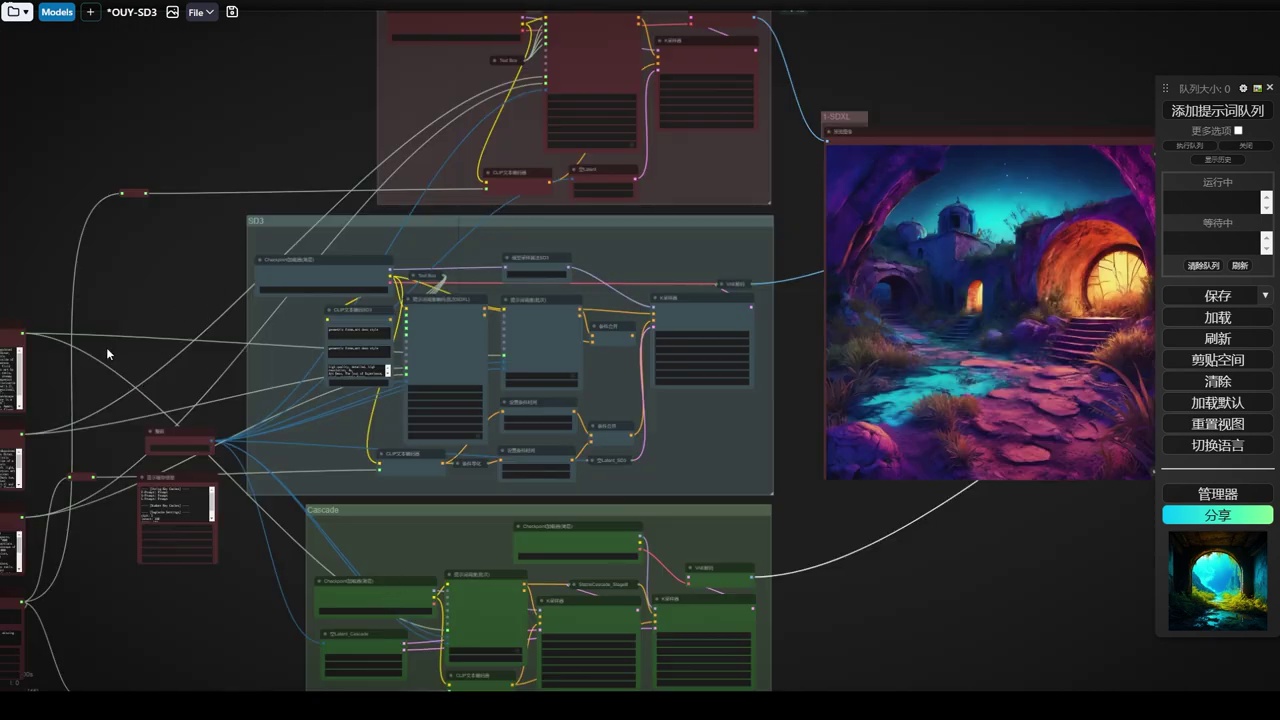
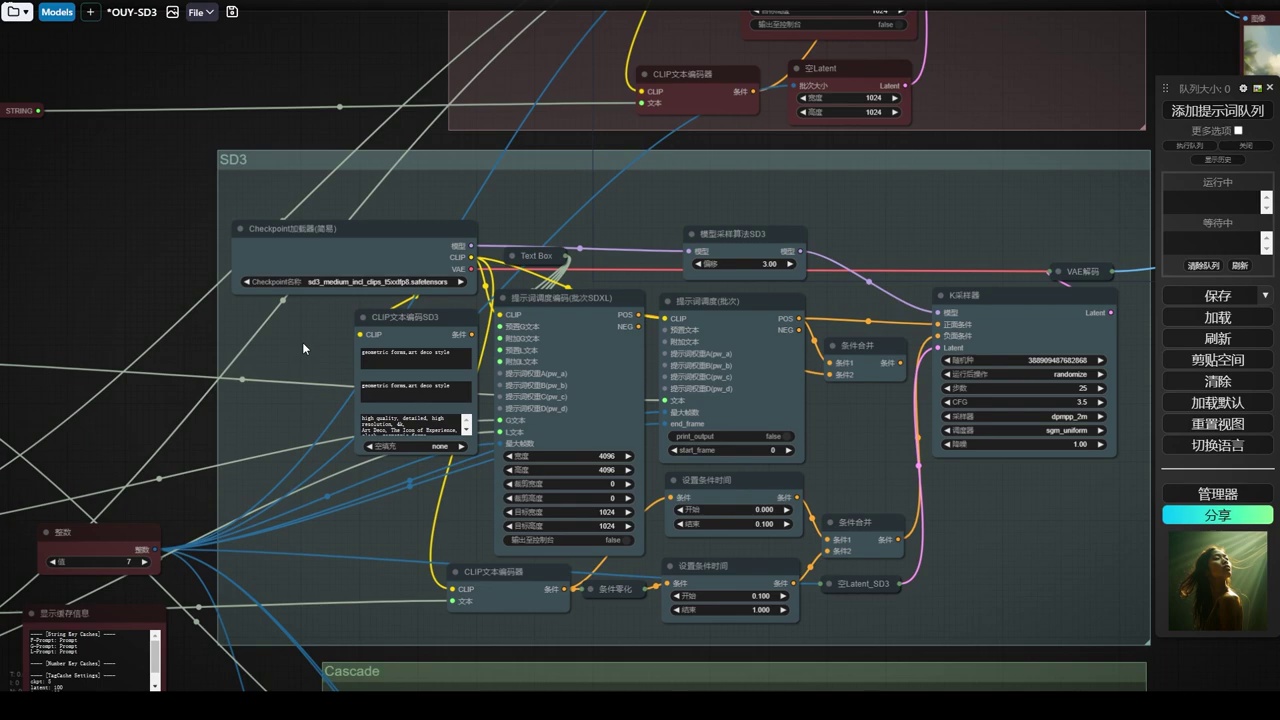
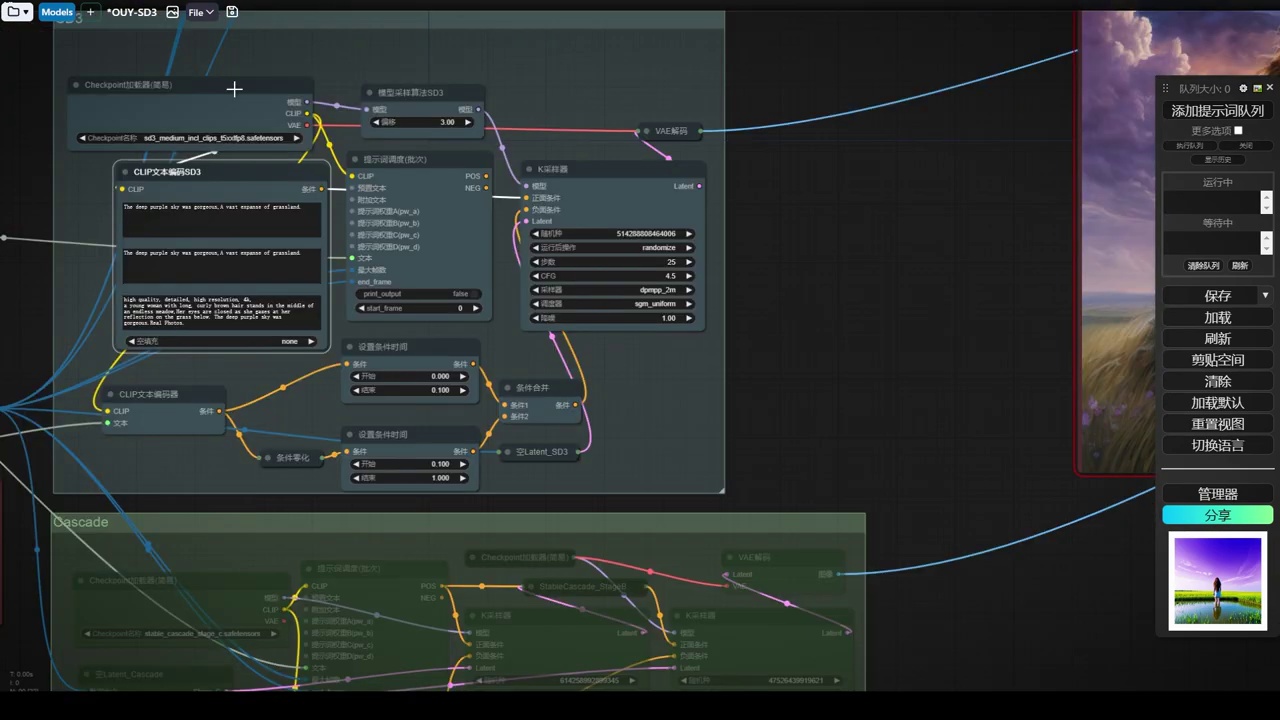
现在直接来到服务器。在服务器这边,我们来直接打开这个工作流。我已经等待半天了。
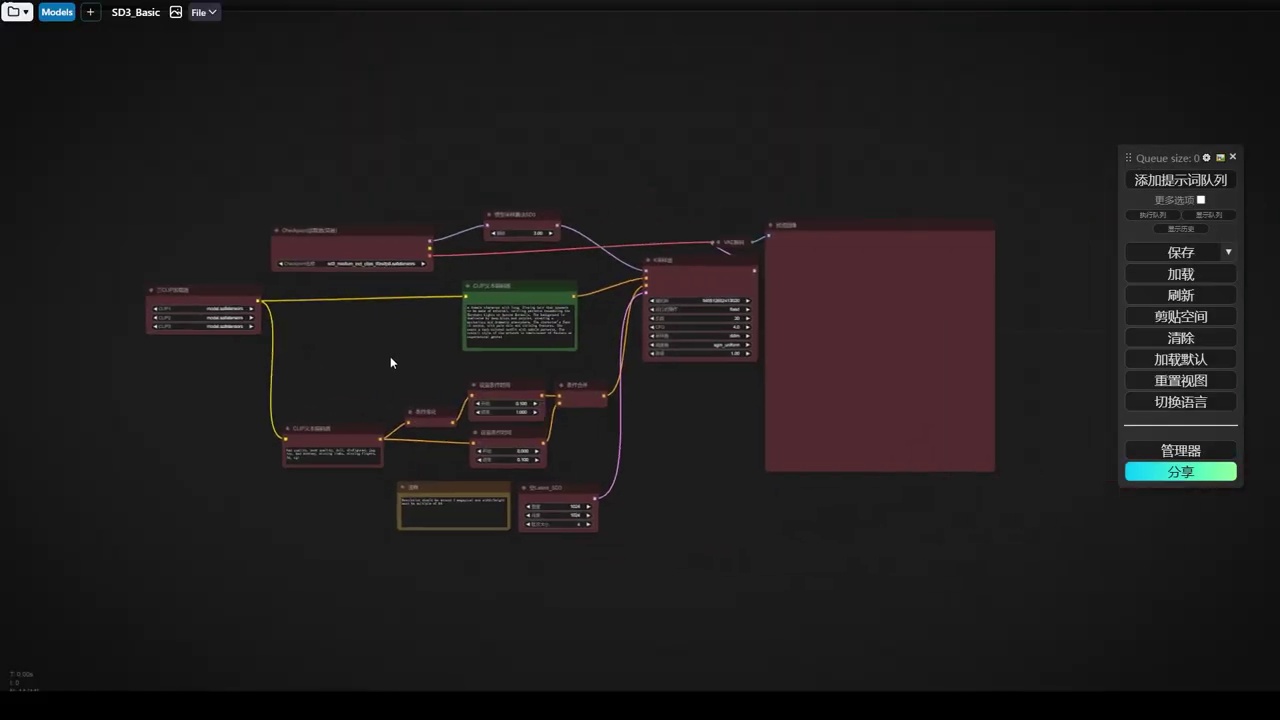
- 工作流中涉及三个clip模型(clip-l、clip-g和t5的clip)的单独加载,用于正向和负向文本编码器。
- 负面处理机制包括两条处理路径,一条无提词(条件归零),另一条有提词和强度设置,通过combine合并,实现线性过渡效果,其中90%的时间无提词作用。
- sd3模型采样算法和模型管道处理算法,包括离散、连续和cascade算法,以及cfg缩放等微调,用于优化模型性能。
- 使用官方提示词和模型参数(如采样器28部,cfg4.5)生成图像,模型已包含三个clip模型,无需单独加载。

这一套题词的效果还是可以的,但是我感觉稍微有些油腻,这个脸上
- cfg值被略微降低。
- 尝试使用默认的olera进行测试,但效果不佳。
- 调度器的选择对结果有重要影响,当前使用的调度器效果最佳。
- 模型算法更改为默认模型,变化不大。
- 步数降低至25步,ddim表现正常,而olera效果不佳。
- 为了提高速度,进一步降低步数测试,结果显示变化不大。
- 尝试不使用原先的负面条件进行测试。
- 当前效果不理想,细节展现不足,需注意负面模式。
- 探讨第二个工作流程——提词强化流程。
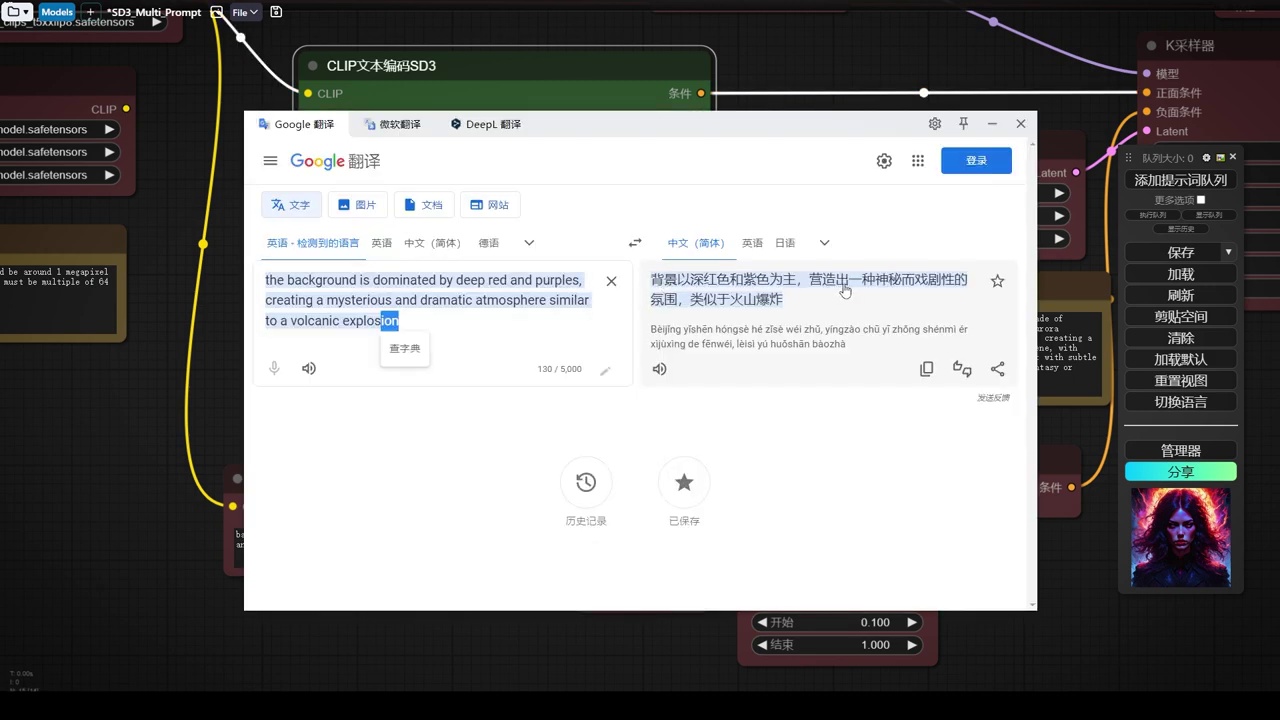
- 除文本编码外,其他组件相同,引入sd3文本编码。
- sd3文本编码包含clip-l、clip-g和t5三个独立clip模型,各负责不同信息。
- 官方演示显示,新提词与之前相同,但效果有显著差异。
- clip i和l主要提供背景色彩、整体氛围和背景形状或风格。
- t5 clip描述了主体,即女性的肖像,包括她的神情、人物特点和艺术品的整体风格。
- 提到了基础案例的提示词。
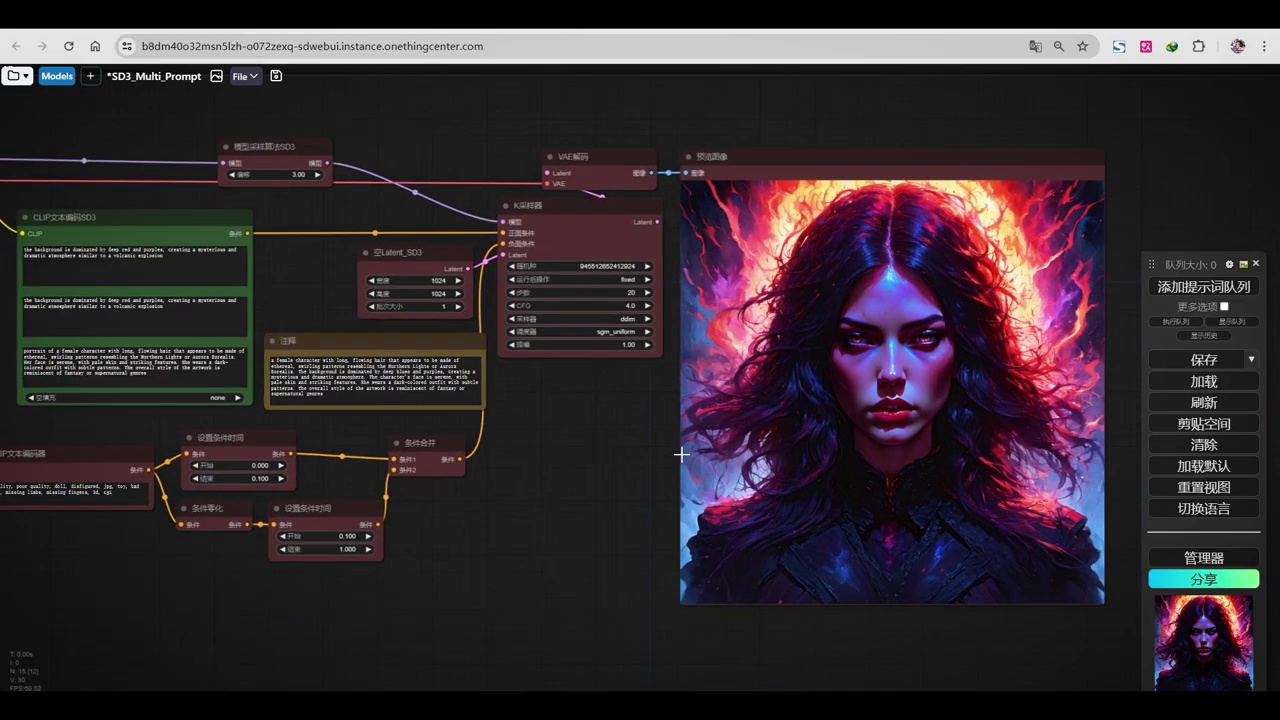
但是没有什么变化的吧。那么所产出的生成的这个效果呢?
这就是三种完全不同的clip模型的应用。
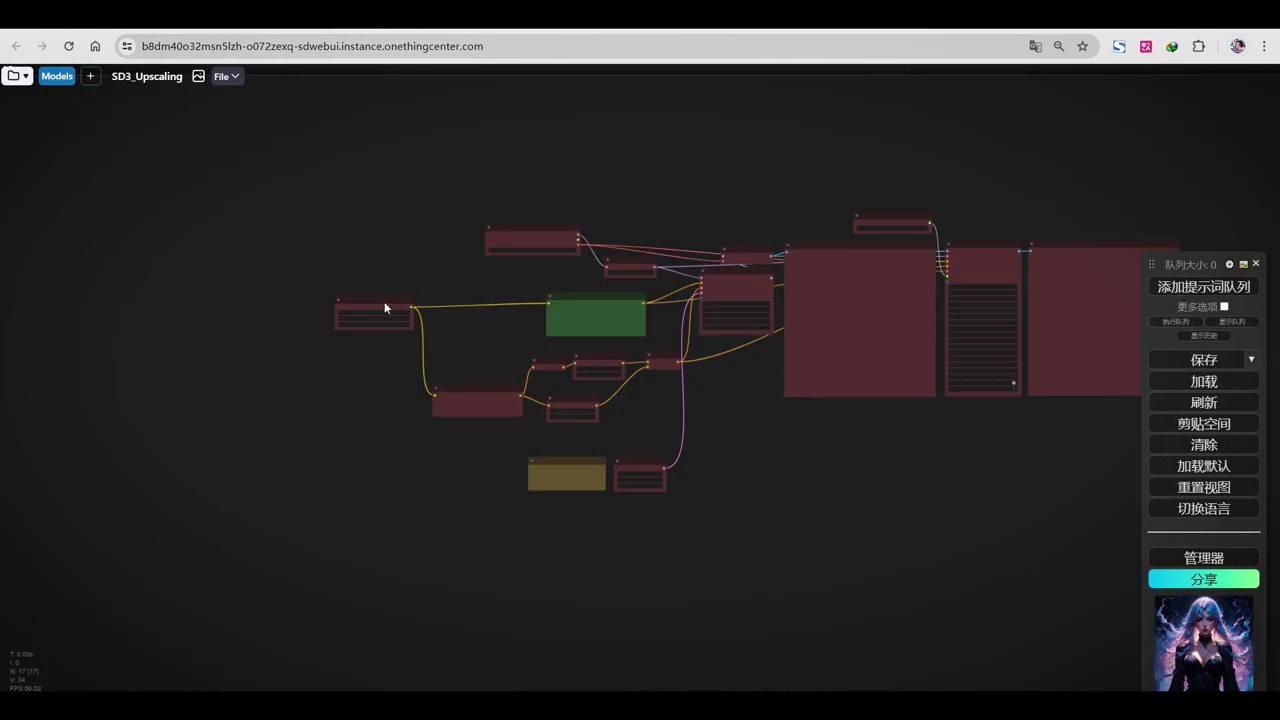
- 探讨了第三个工作流程,该流程主要涉及us放大和sd处理。
- 官方提供了三种不同的工作流。
- 由于sd开源时间短,节点进度未同步,无法使用独特方式遍历提示词。
- 目前只能使用单提示文本编码器进行图像测试。
- 讨论了遍历图像时的差异。
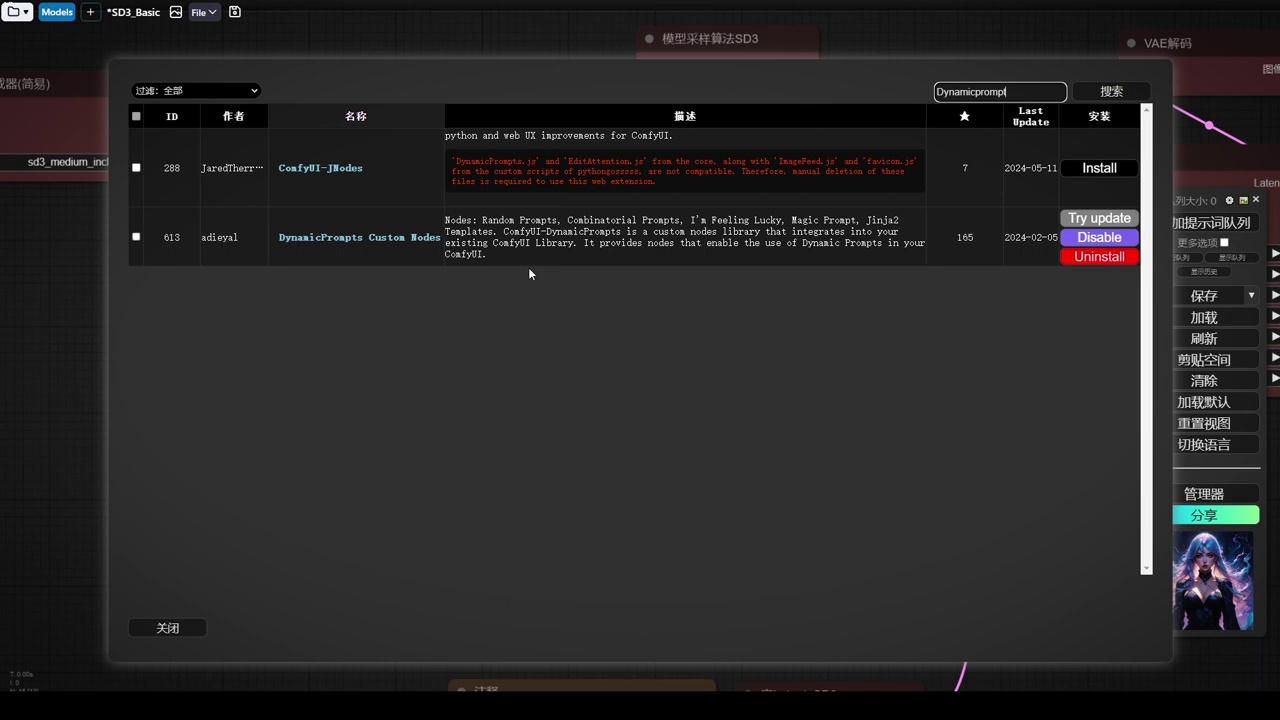
- 插件名为“dynamic”,可在manager中搜索安装。
- 该插件为题词插件,安装后新建节点显示动态提示词。
- 动态提示词节点是program通配符的使用节点。
- 不使用此插件,可选择inspire中的通配符。
- 文中提到将选择随机题词,以随机调用通配符文件。
那么说到文档调用,我们还是要访问liblib的网站,除了模型,我们还可以下载一些其他资源。
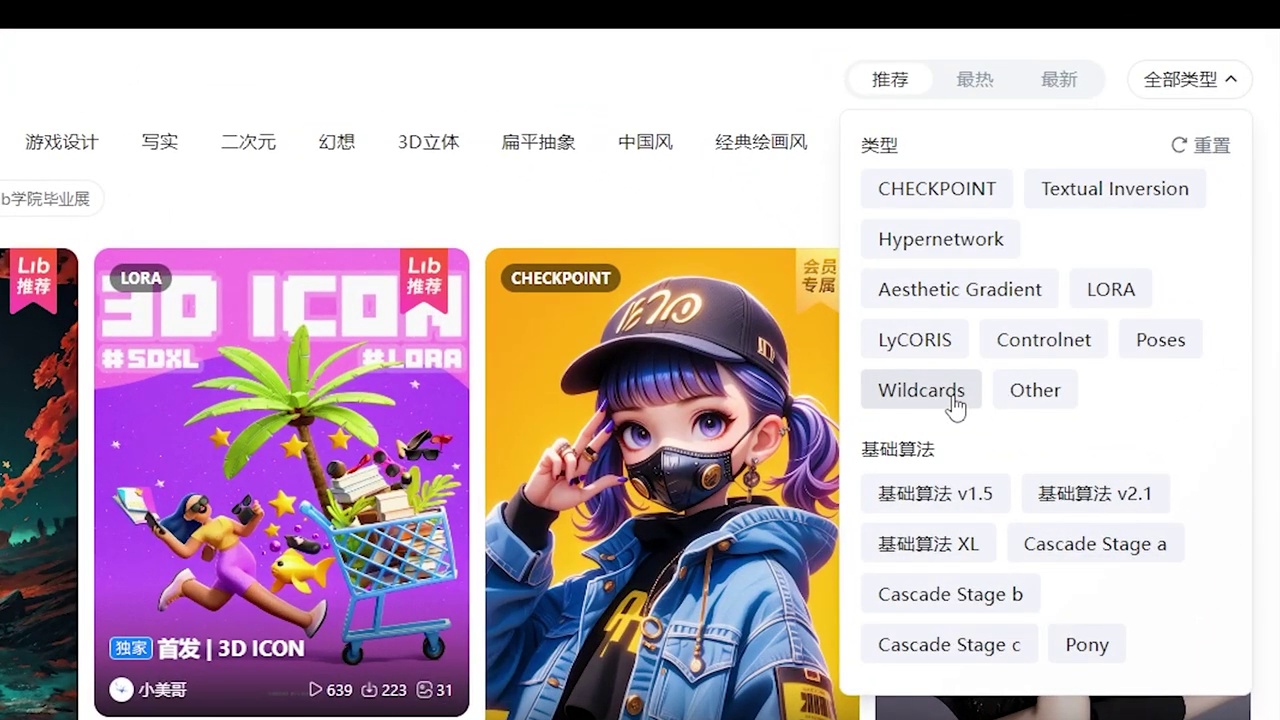
点击右侧,查看全部类型,您会注意到这里有一个word cards,即题词卡片。
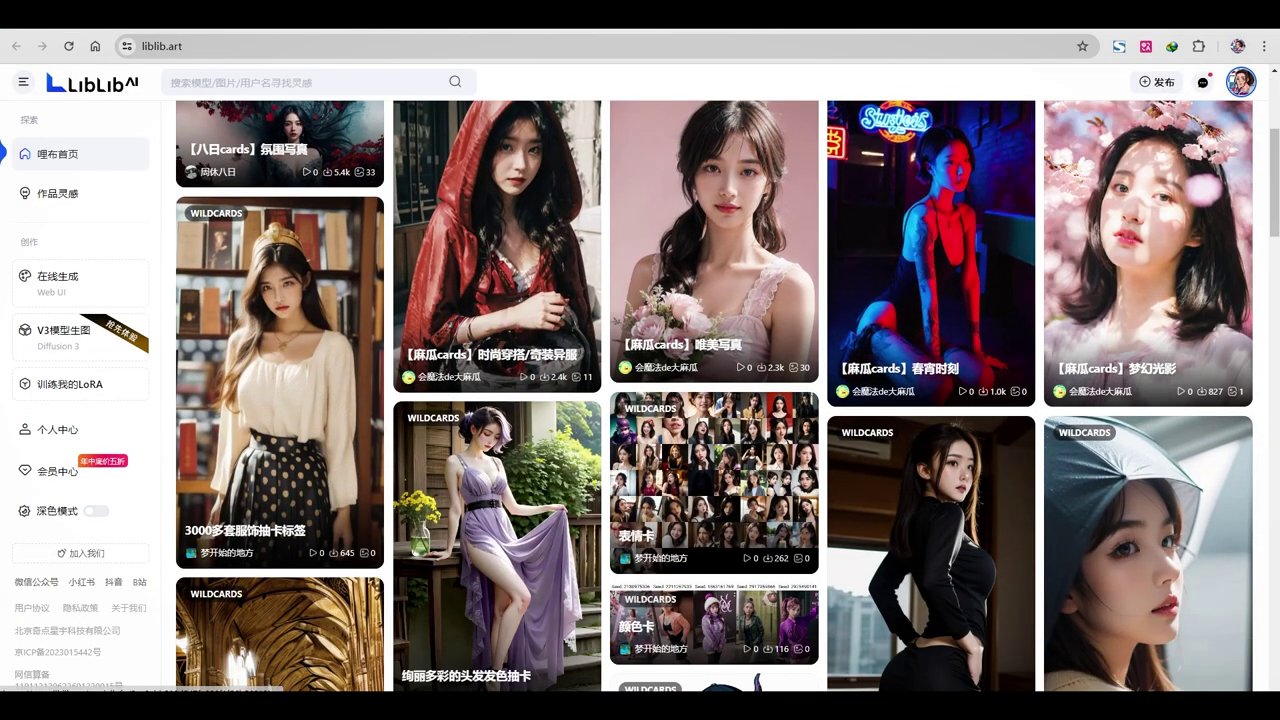
提斯卡吧是一个包含多种类型的平台,其中包括服装、人物、风格、场景以及视角等各类元素。

这里我下载了一些题词卡,解压后均为txt文档。打开后,内容包括镜头、服装、各种职业服装、动物、人文景观及风格。我已上传部分至服务器,但未全部上传。
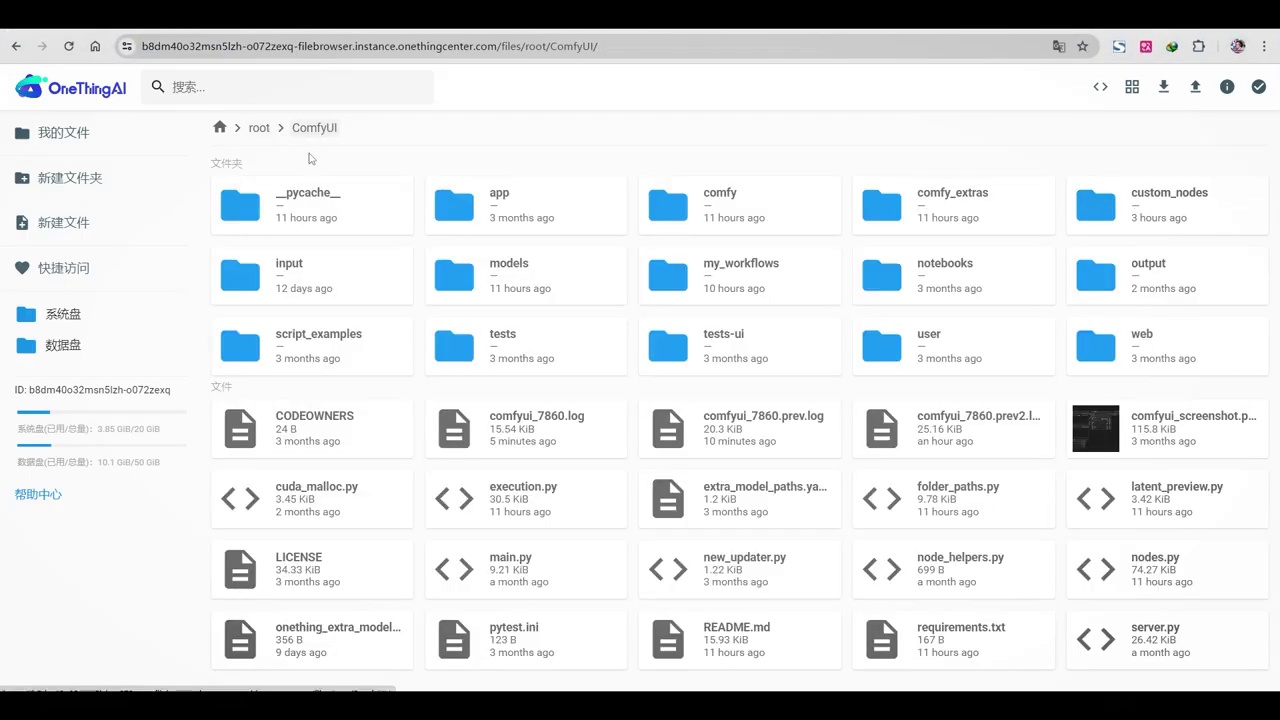
- 文件位置固定:服务器和本地在configurator目录下的文件位置是固定的。
- 自定义节点插件:在configurator下的custom_nodes文件夹中,存放了自定义节点插件。
- 安装的插件:dynamic_prompt是之前安装的插件,位于custom_nodes文件夹内。
- wildcards文件夹:在dynamic_prompt文件夹内,用于存放下载的txt文档。
- 文档内容:放入wildcards文件夹的txt文档包括动物、配置文件、角色服装、风格和场景,其中配置文件需要复杂指令。
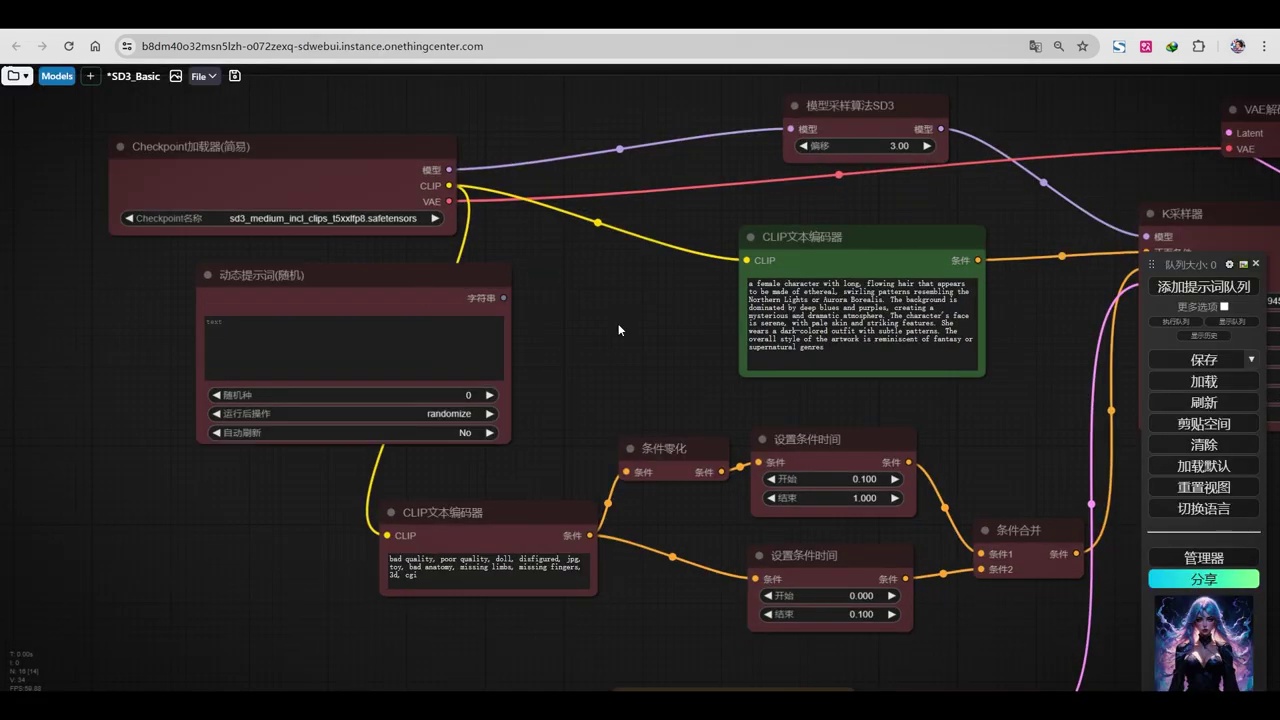
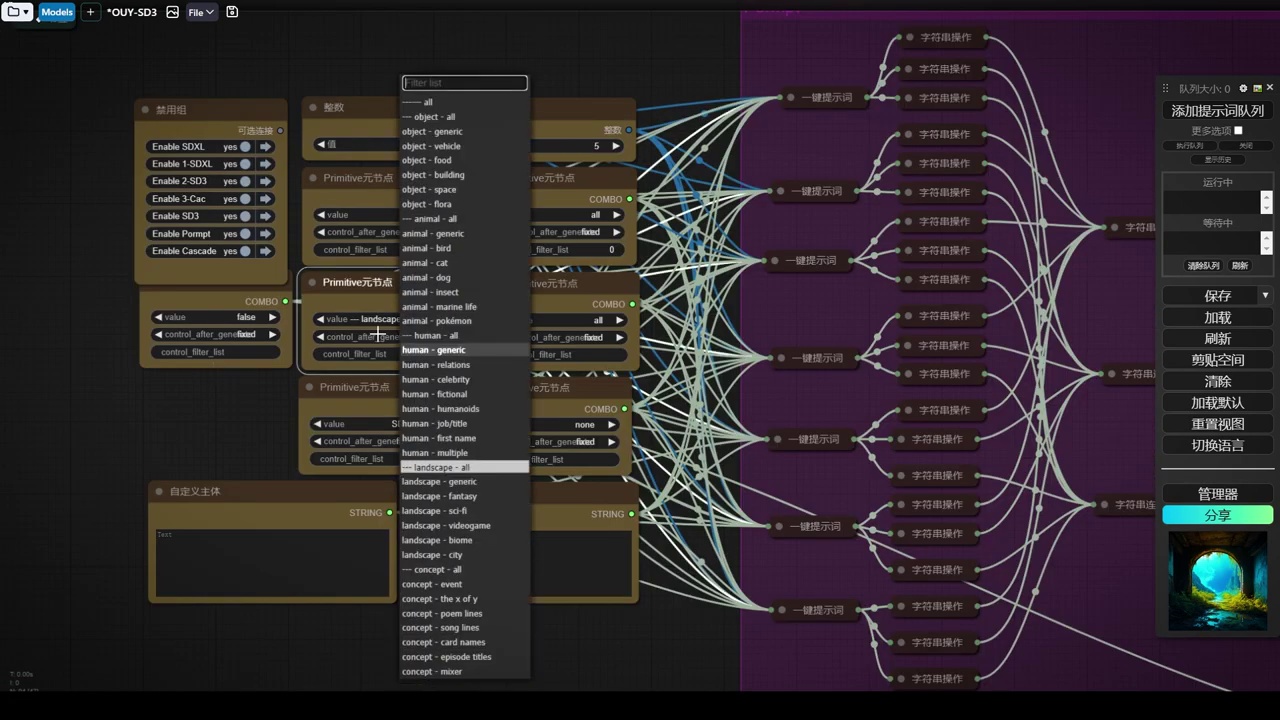
接下来,我们将调用config ui。首先,我们将测试一种风格,在此基础上,我们可以提供不同的动物或场景。随后,我们将涉及两个文档:第一个文档包含各种动物。
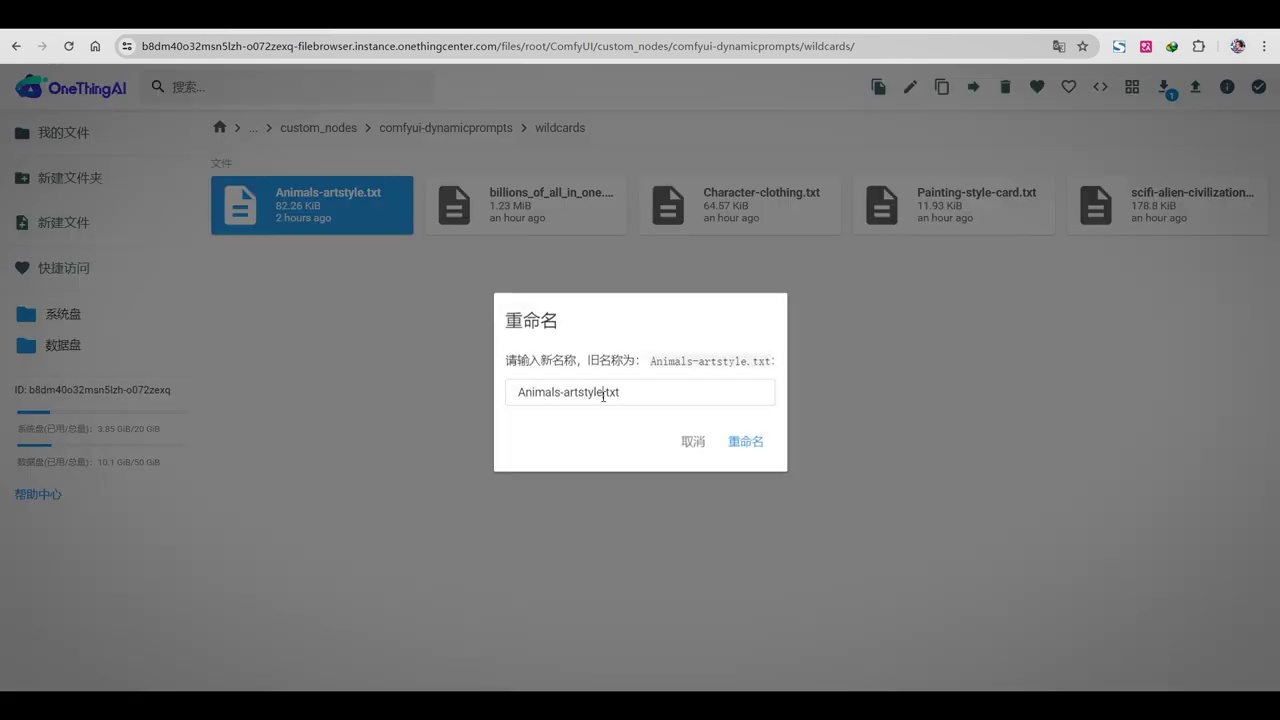
- 文件重命名并复制名称。
- 调用时切换至英文输入法。
- 使用shift键和反斜杠键输入两个下划线。
- 粘贴文件名后再次输入两个下划线。
- 系统随机调用文档中的提示词。
- 需指定一种风格。
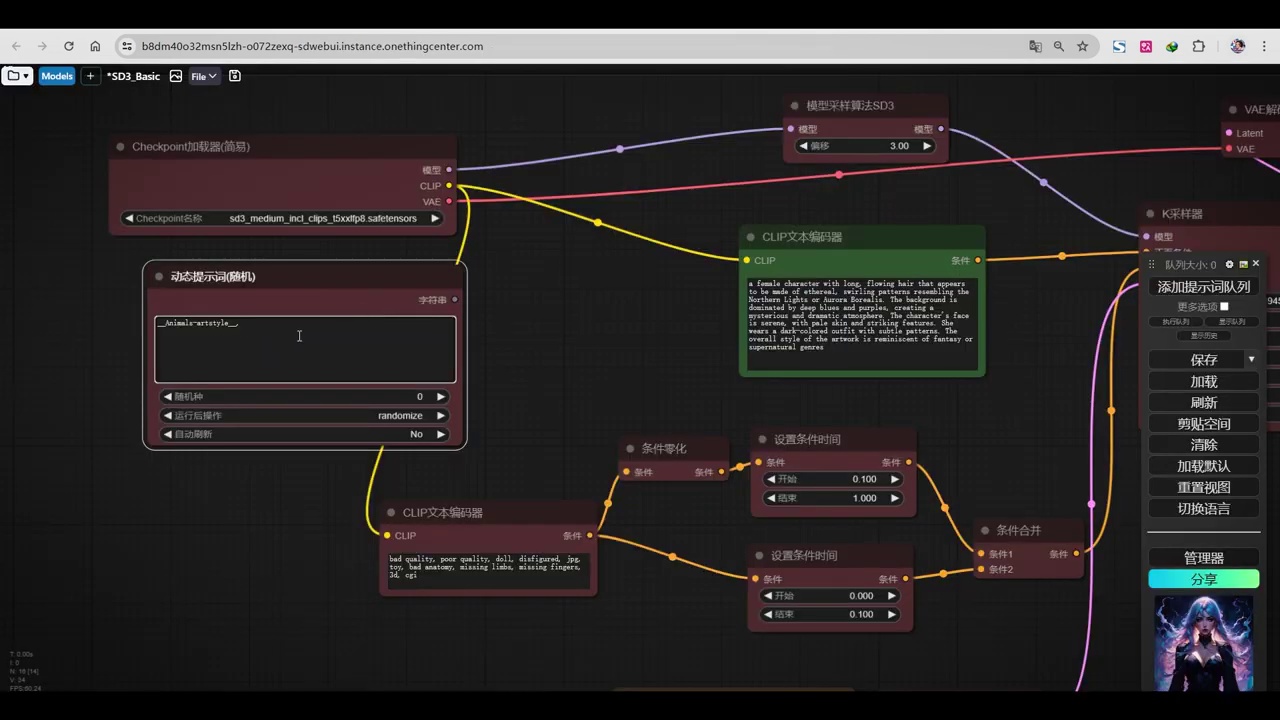
- 复制风格卡的文件名。
- 使用特定的调用方式(两个下划线)嵌入文件名,结合动物与风格。
- 预览提示词,关闭采样器后运行程序。
- 屏幕显示动物描述及风格描述,风格描述紧跟在art后。
- 提升文本变化器的输入,直接应用于文本变化器。
- 对负面提示进行简单修改。

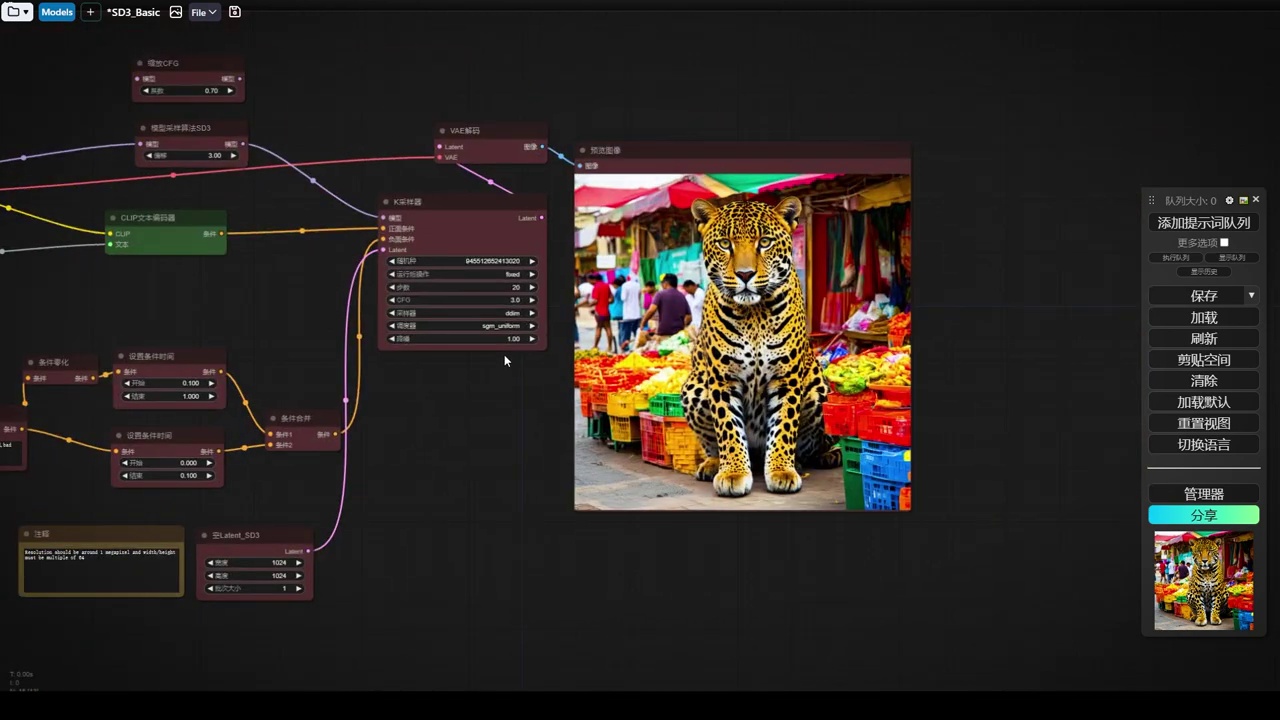
- 描述了使用某种风格生成图像的过程。
- 第一次生成的图像是犀牛,但看起来异常。
- 第二次生成的图像变为豹子,安全系数被调低至3。
- 光线对豹子来说仍然过强。
- 尝试生成小猫的图像,经过多次尝试后,艺术表现有所差异。
- 尝试一次性生成多张图像,但系统重复生成相同图像。
- 需要实现批处理,生成多样化图像,类似于动画制作中的fizz节点。
- 使用stream的合并功能和帧节点,设置不同组件生成不同内容。
- 通过设置帧和提示词,实现自动生成不同图像。
- 使用fizz批次调度,设置最大帧数,批量预览和生成图像。
- 尝试生成人物图像,通过修改提示词实现不同风格。

- 手动调整风格,包括水彩、幻想风、写实照片和动漫风格。
- 去除通用符,进行逐一修改。
- 添加正向提示词,设置在指定文本中,并将女孩添加到附加文本中。
- 重复添加正向提示词的操作。
这里我们来看一下这个风格,第一个水彩的,第二个是写实的。
- 描述了几个手部模型的效果,指出它们存在问题,如多出一根手指、细节处理不佳。
- 提到这些模型是基础模型,细节未深入调校。
- 计划进行宏观分析和多模型比较,并已进行了一些调整。
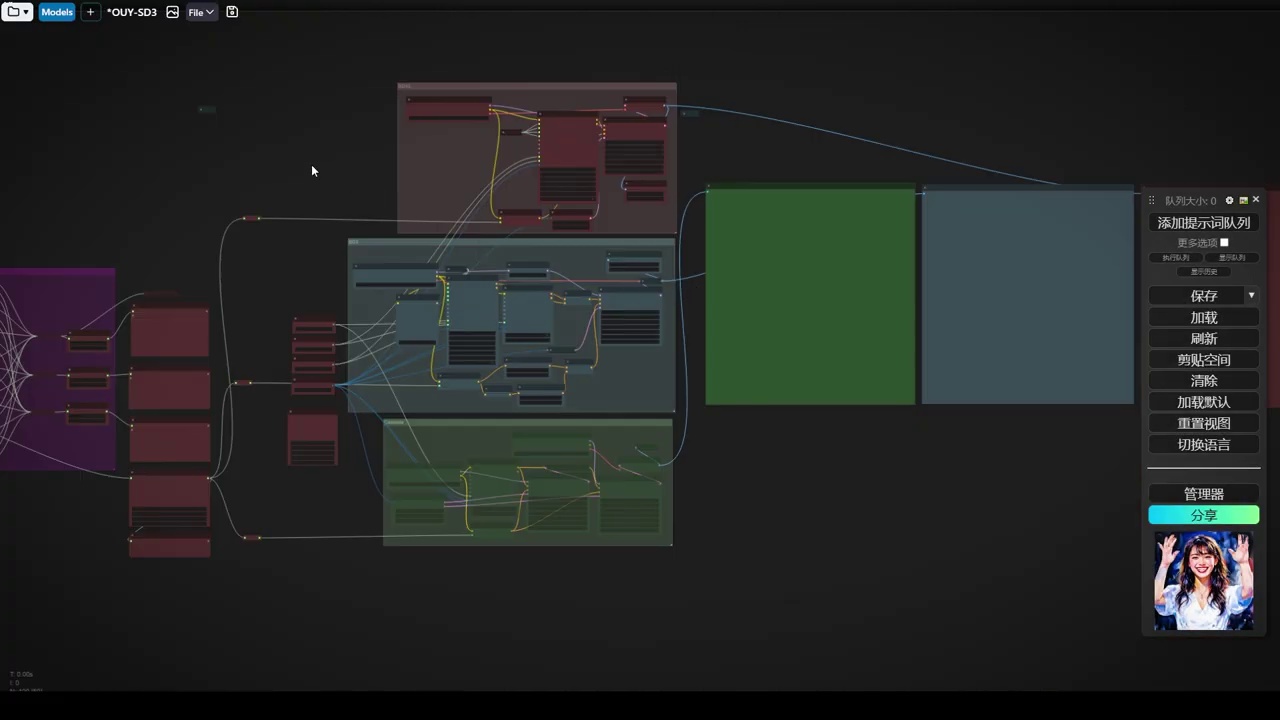
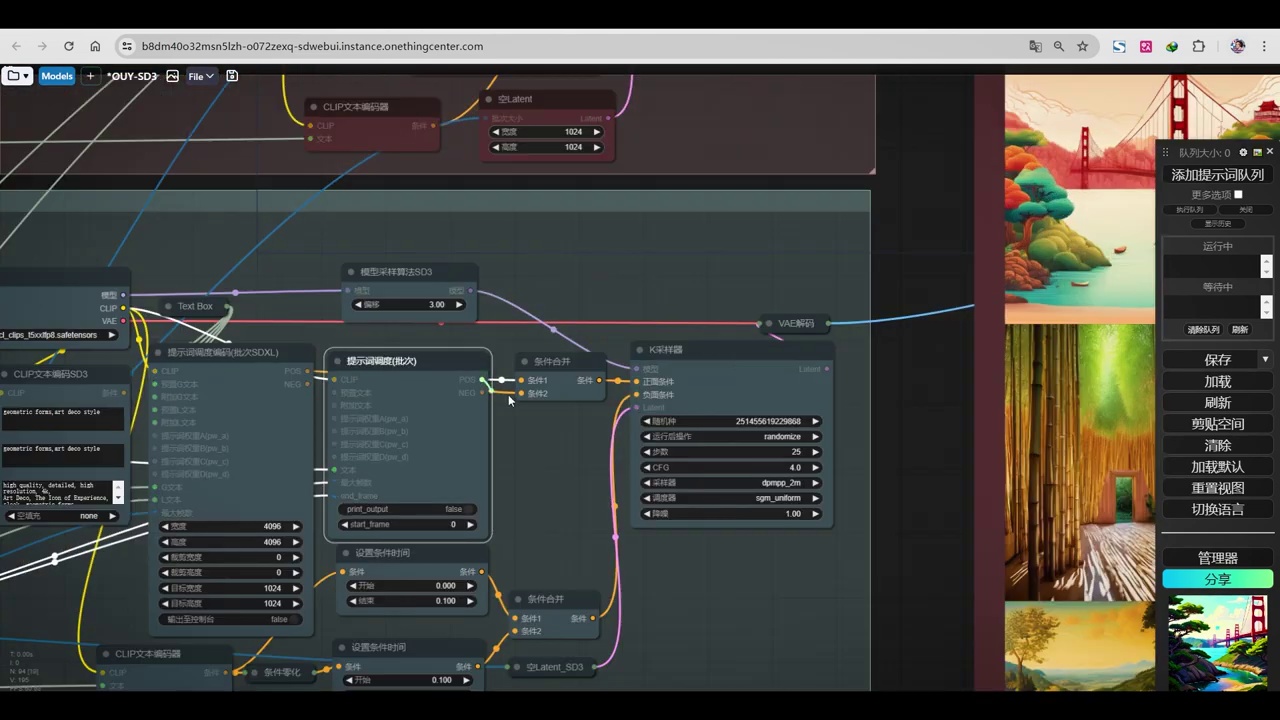
下午时间创建了一个测试工作流,该工作流规模较大,我们可以观察到。
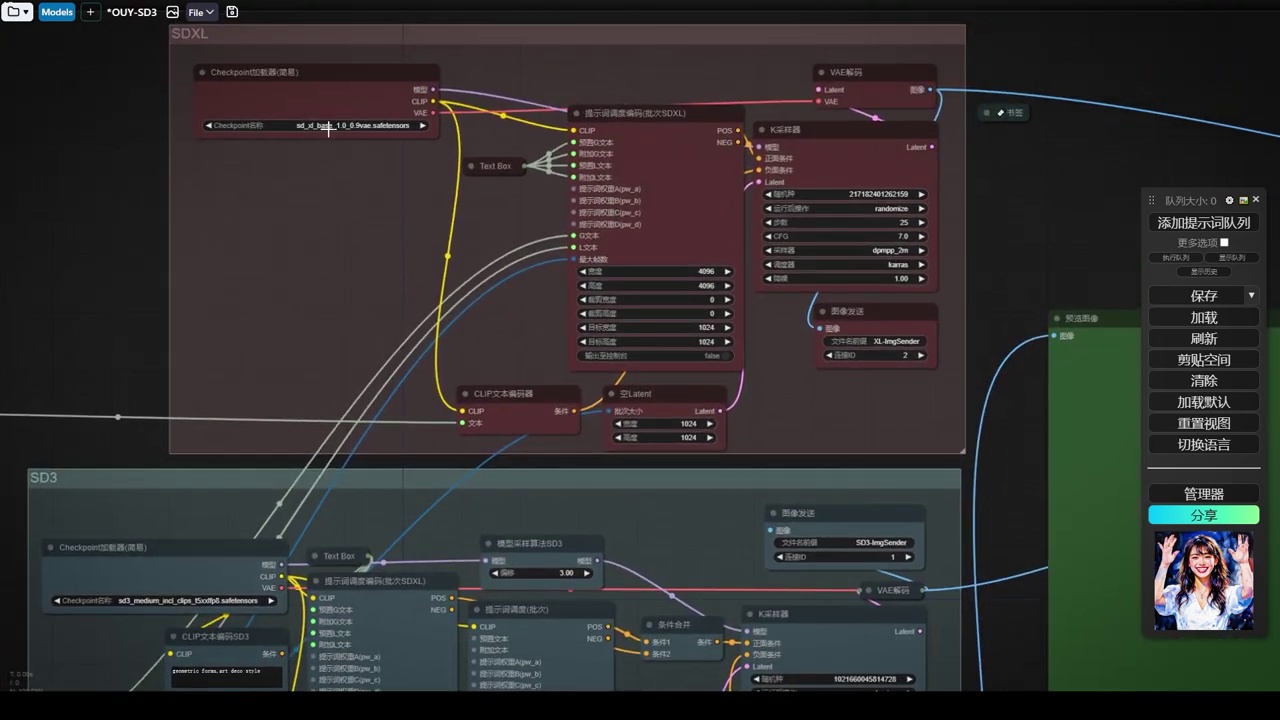
这里放置了三种不同的模型,第一种是sdxl,我使用的是基础版本1.0的sdxl模型。
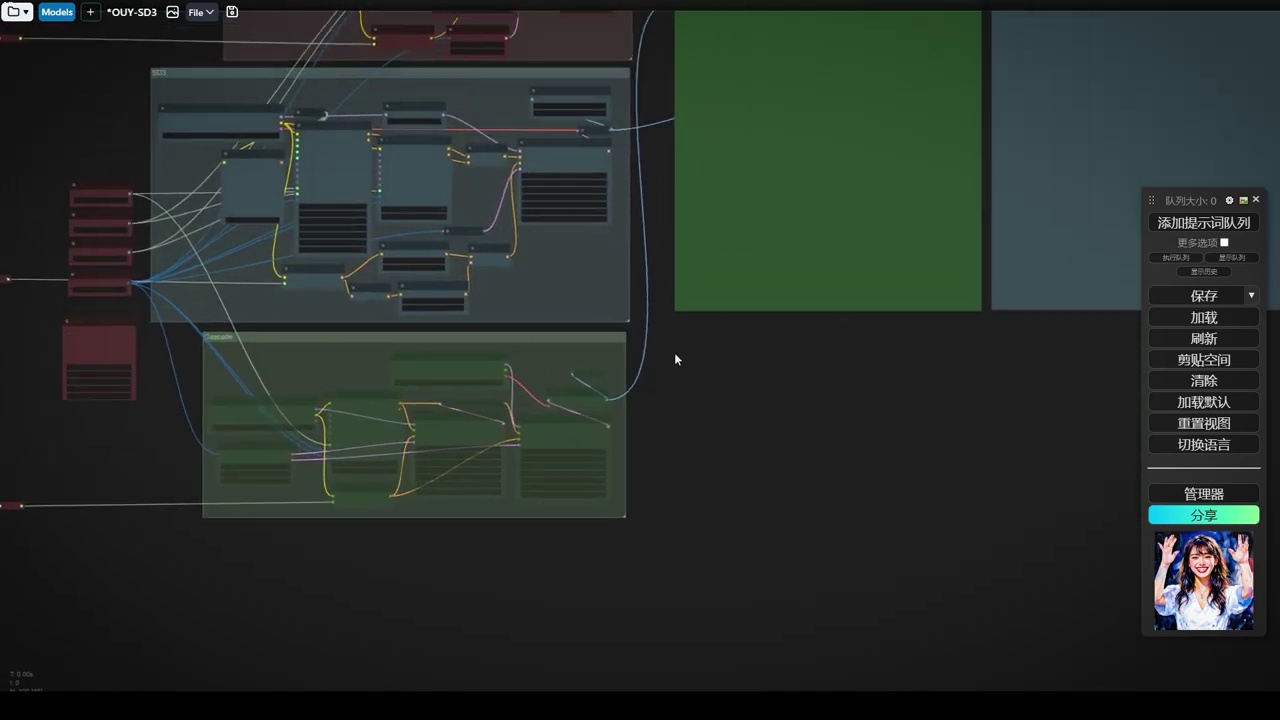
那么第三个呢就是cascade,这三个模型生成了三个模型。
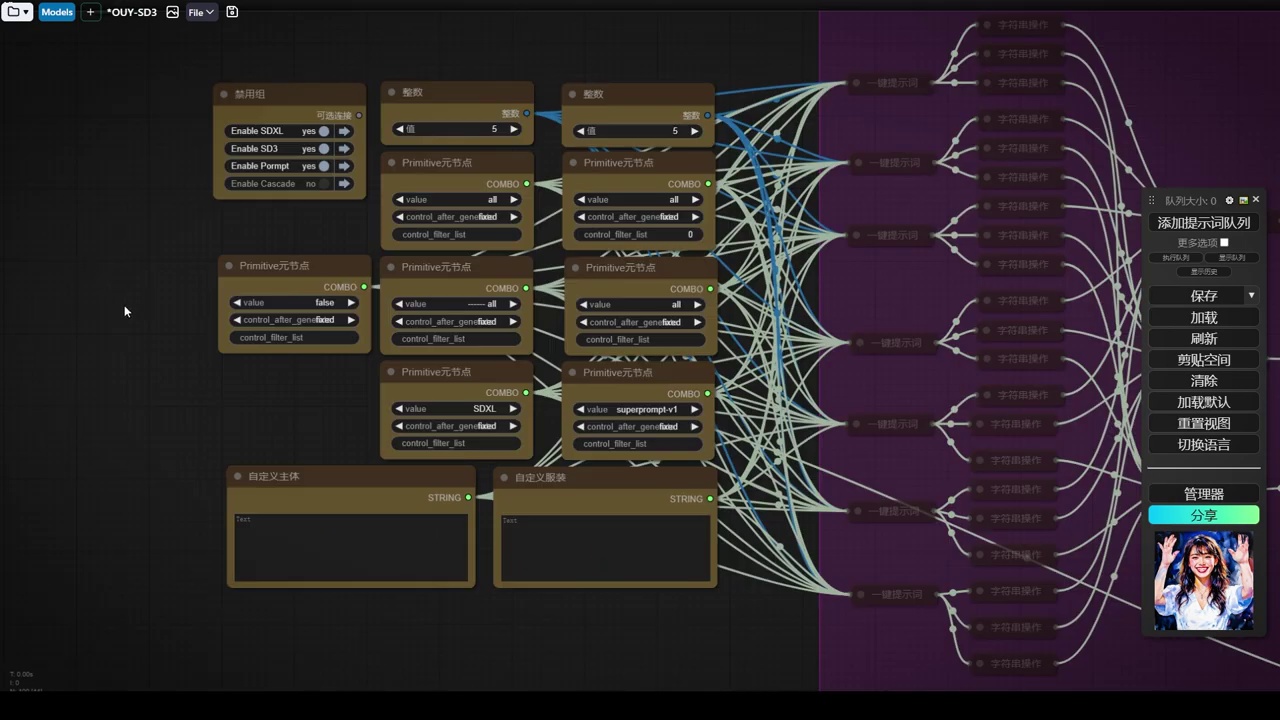
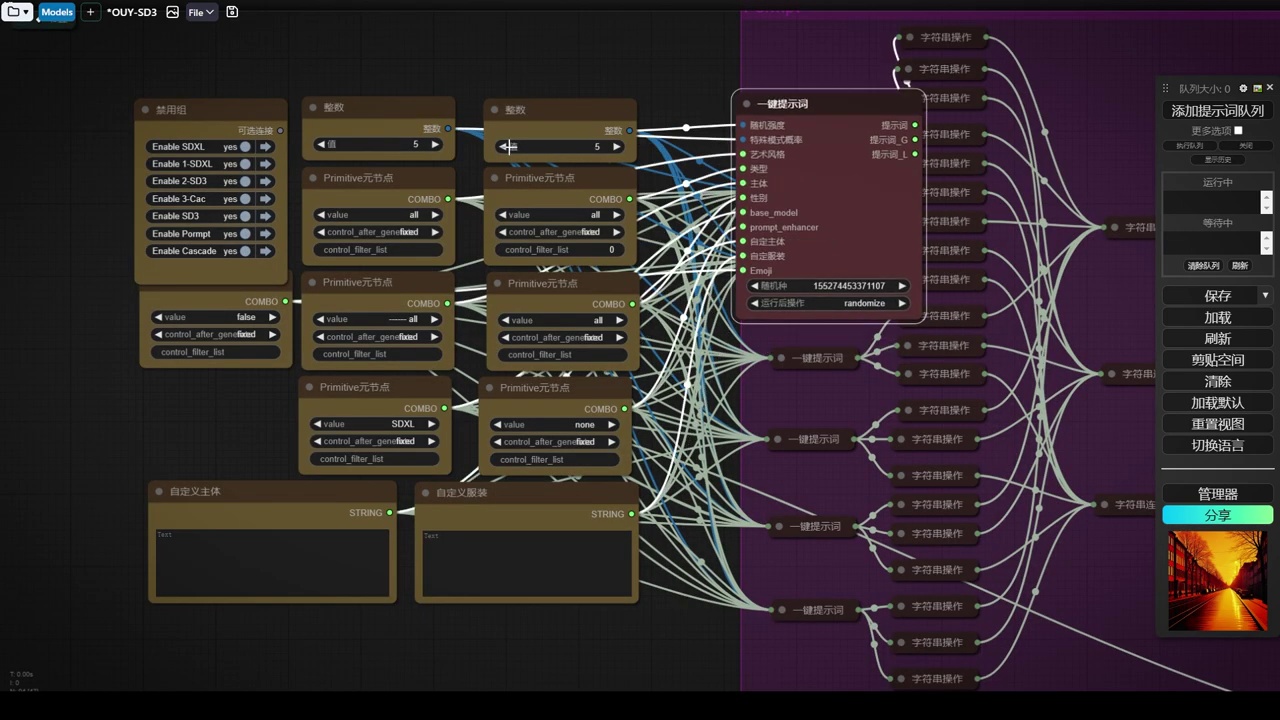
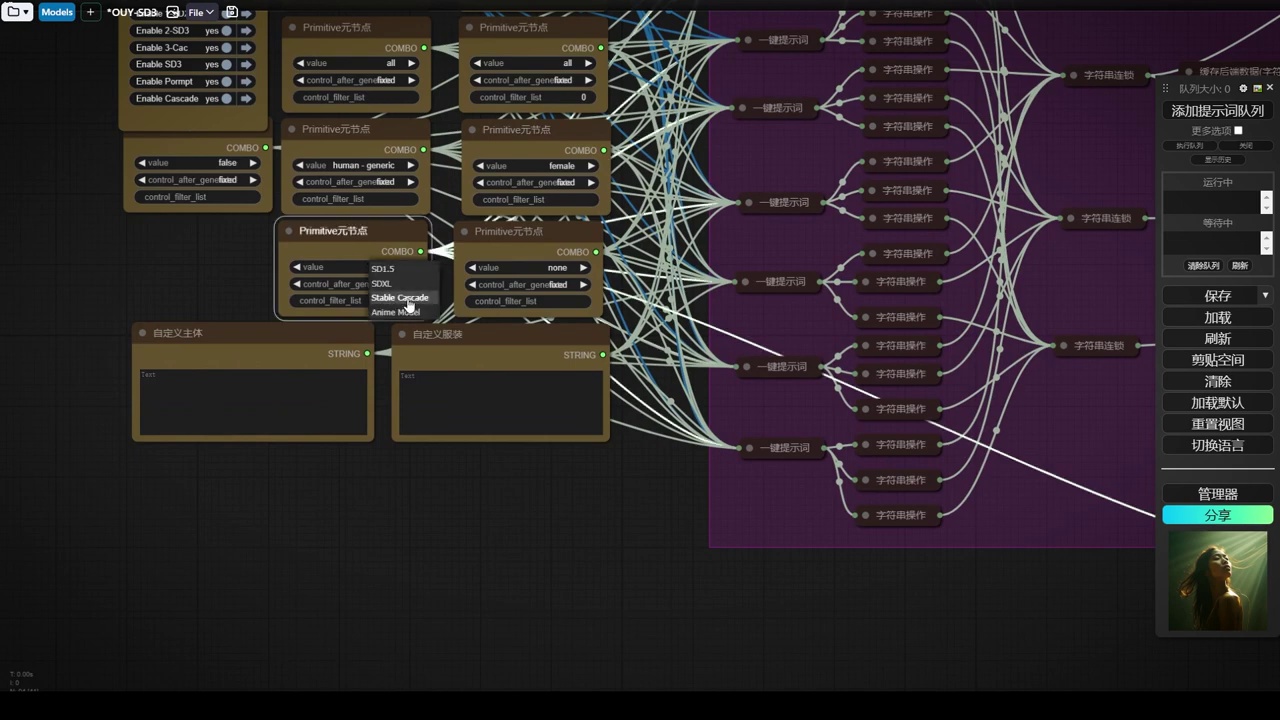
- 使用了sd中的一键题词插件,该插件支持gl和提示词通道。
- 插件允许选择不同风格、类型、主体和emoji表情。
- 目前插件未更新专门针对sd3的题词,因此统一使用sdxl的题词。
- 插件可以生成三个不同clip所需的文本,并随机选择艺术风格、类型、主体等。
- 作者对插件进行了调整,单独提升了题词所需的所有组件,包括随机强度。
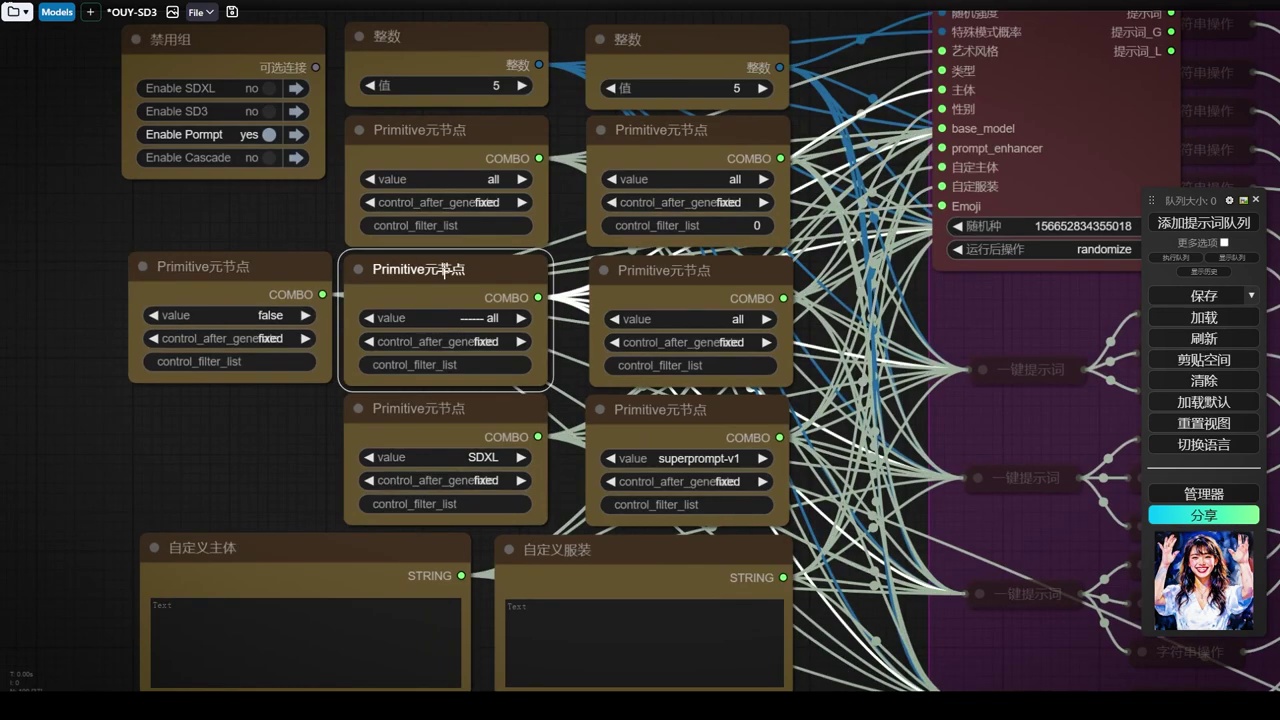
之后,我进行了字符串处理,因为一键提示词生成的提示词可能包含双引号。
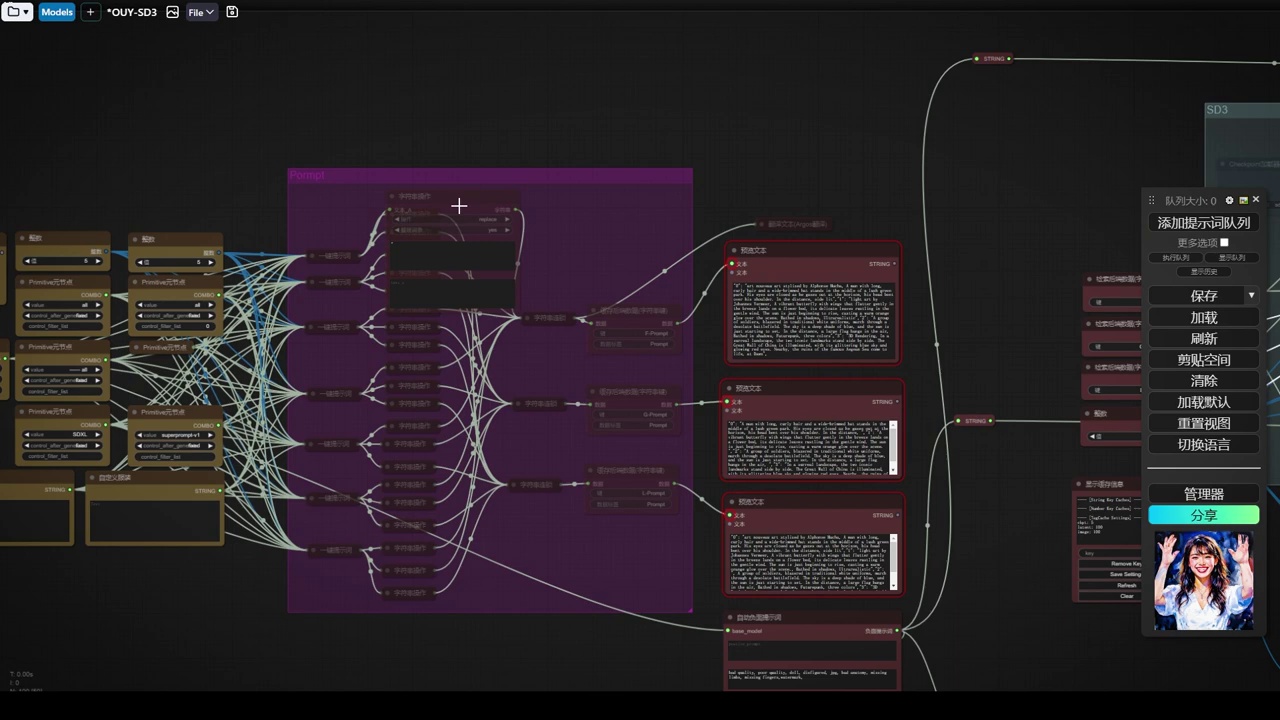
- 双引号是zif节点的一种特殊格式。
- 零帧是zif节点处理的一种方式。
- 如果提示词中夹杂其他字符,zif节点无法正确识别。
- 为了解决识别问题,所有包含特定符号的提示词被替换为空。
- 对提示词的gli进行了字符串操作测试,并得到了结果反馈。
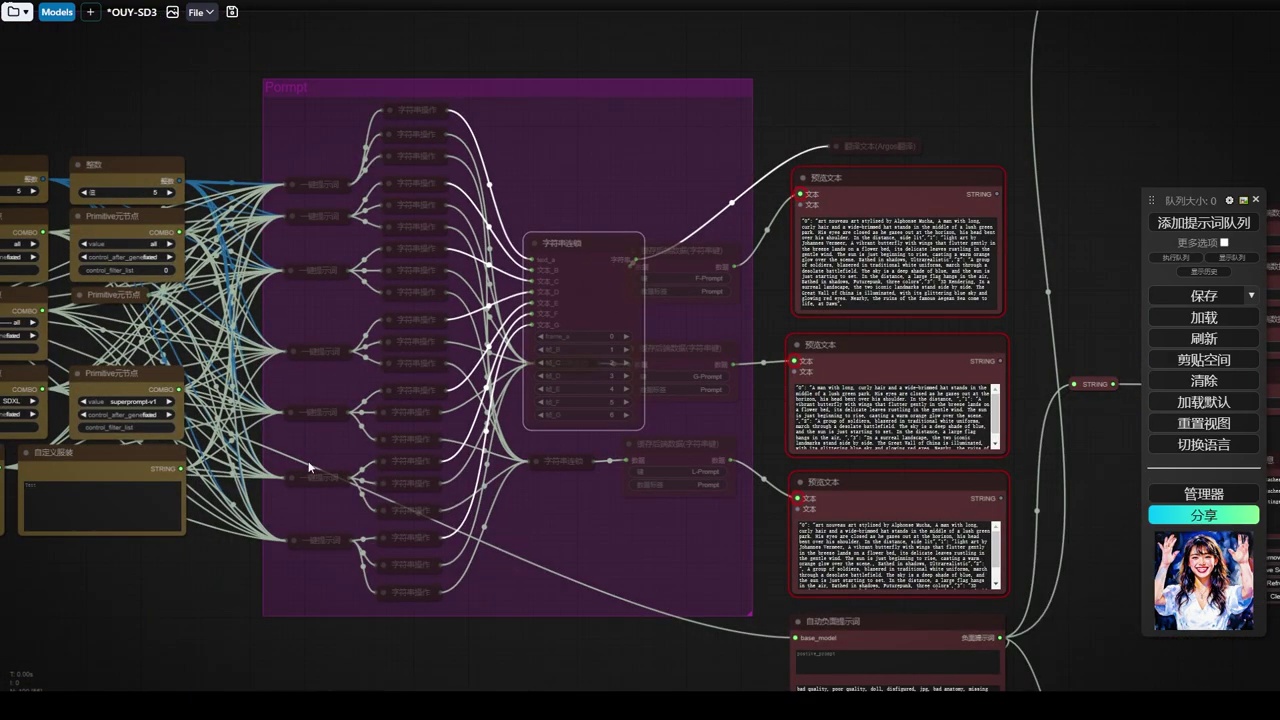
- 创建了7个字符串连接。
- 生成的字符串被存入缓存。
- 可以预览缓存中的内容。
- 从缓存中读取数据,包括g、l和全局提示词f。
- 数据对接至生成工作流。
- 使用了“one button prompt”插件的自动负面提示词功能。
- 生成了一个负面提示词。
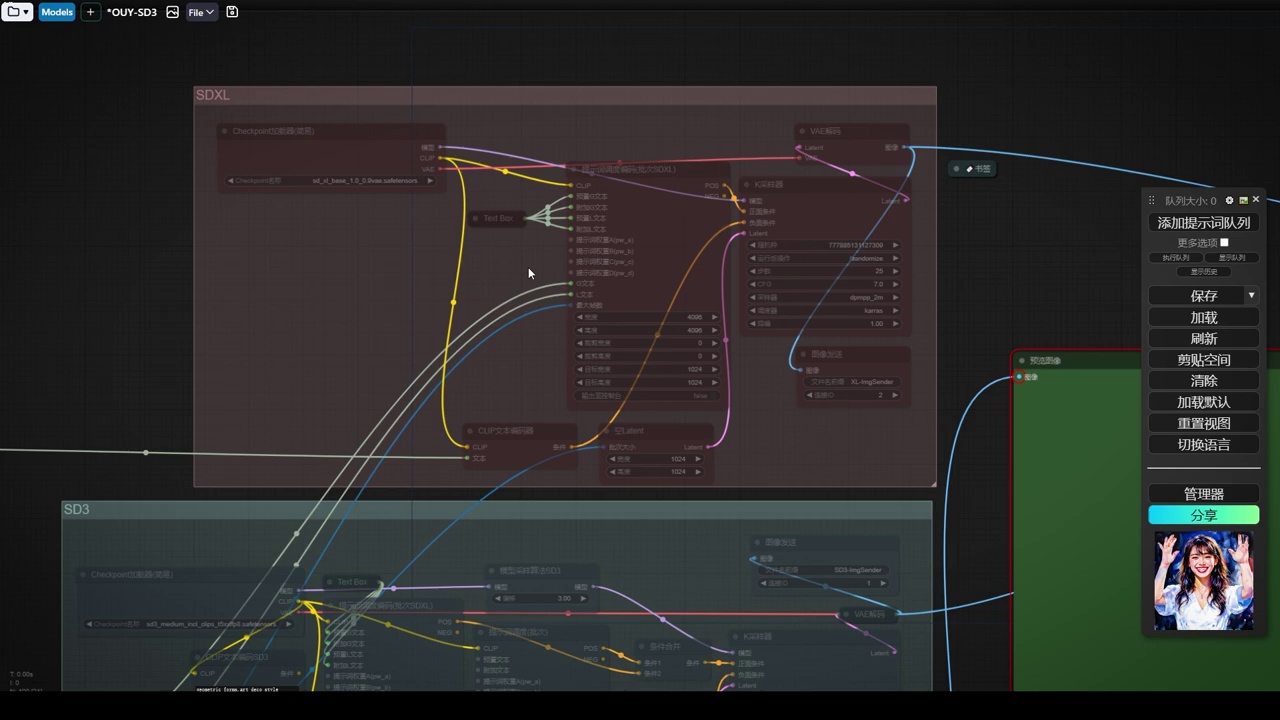
- 提供了三个不同的流程:sdxl、cascade和sd3。
- sdxl流程中,输入的是g和l的文本。
- cascade流程中,只有一个文本输入,使用全局提示词。
- sd3流程中,实验性地进行了提示词的分离,包括宏观提示词和sdxl的l和g输入,并通过combine将两者结合。
- 提出了使用t5专门的编码器作为更好的文本处理方式,但由于其专业性,未被采用。
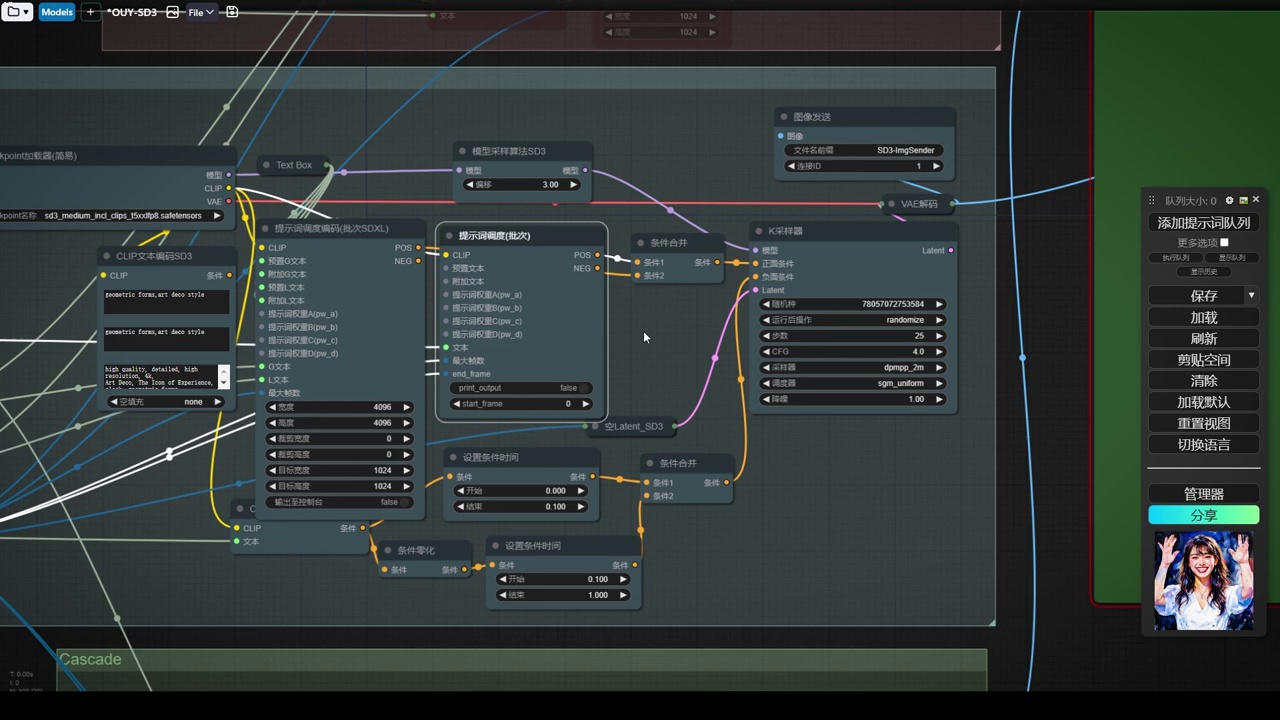
由于文本编码框不支持批处理,因此无法进行此操作。希望未来fizz能够开启sd3调度功能,预计后续会进行更新,目前尚未更新,因此我们只能暂时使用现有流程。后续步骤与之前相同,即遵循此流程。
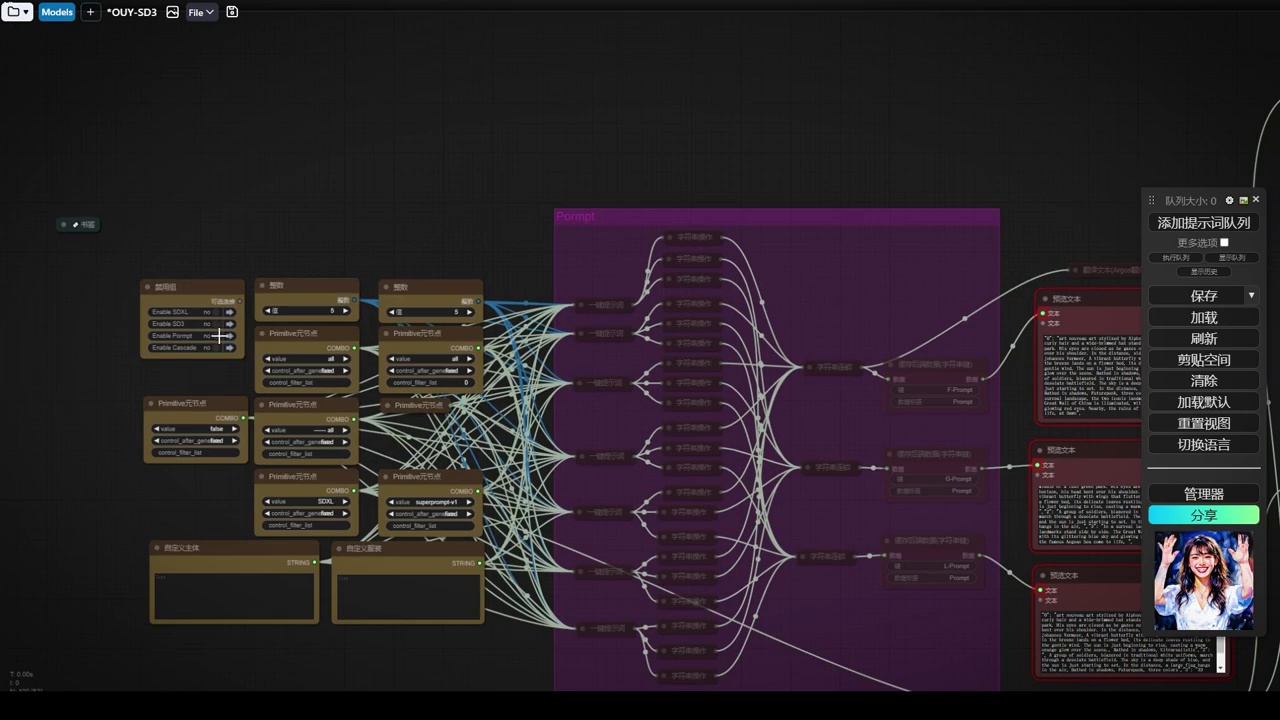
然后我们使用这个提示词,随意生成一些内容,首先打开我们的提示词组。
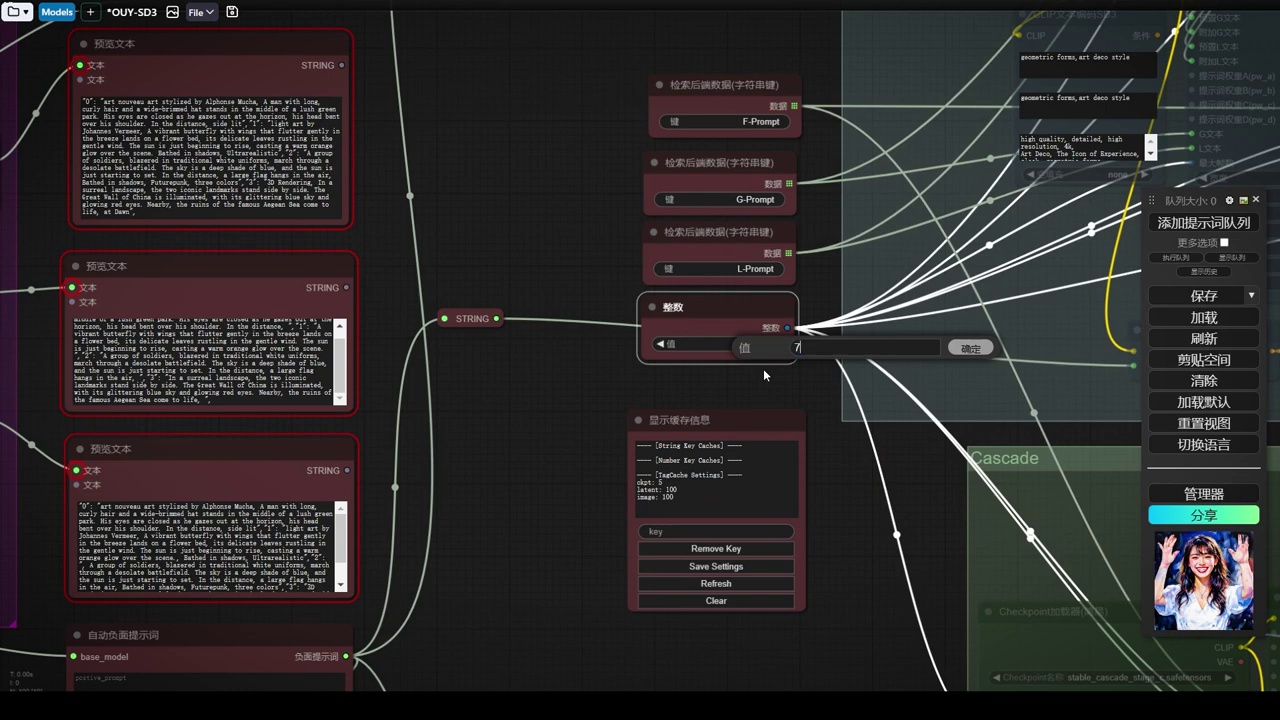
- 参数设置为7,用于生成7张不同图像。
- 关闭了其他所有组,只保留一个缓存,防止重复调用。
- 未设定风格主题,系统将随机选择并生成图像。
- 生成过程中,系统会逐一提示关键词。
- 生成完成后,相关文本将自动标记关键帧。
- 之后,关闭提示词功能,开启xl渲染、sd3渲染和casket渲染。
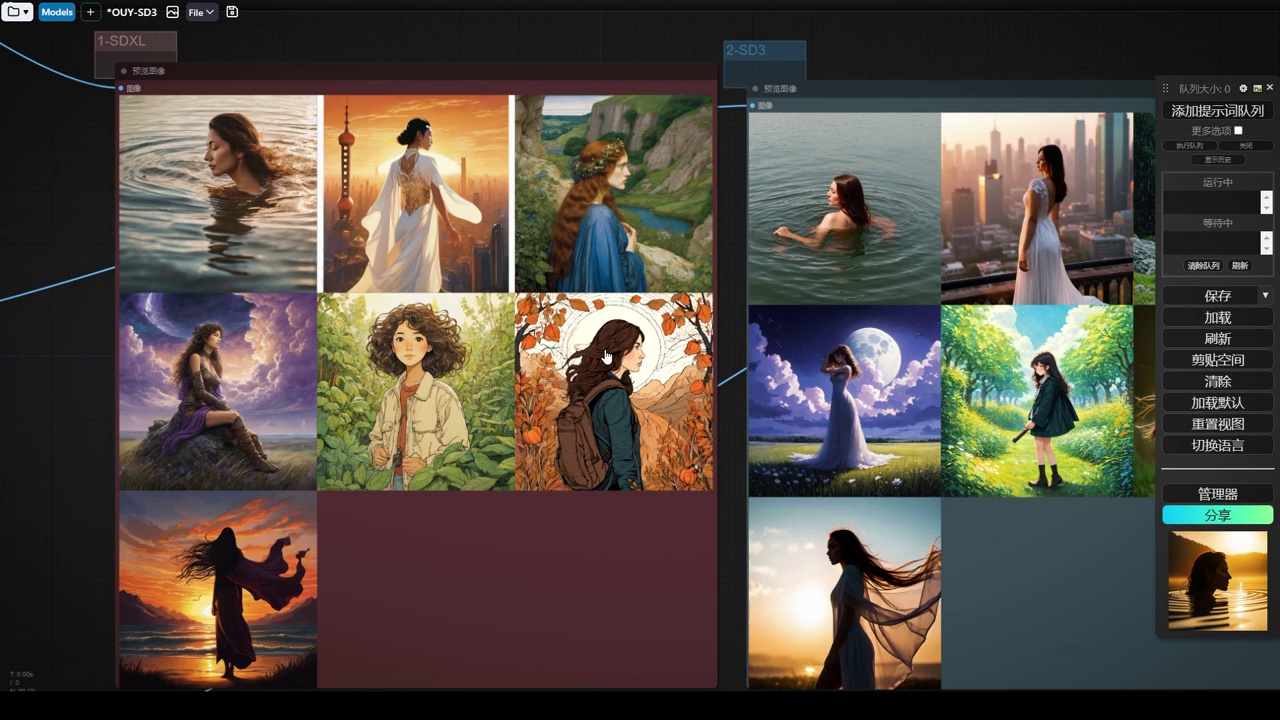
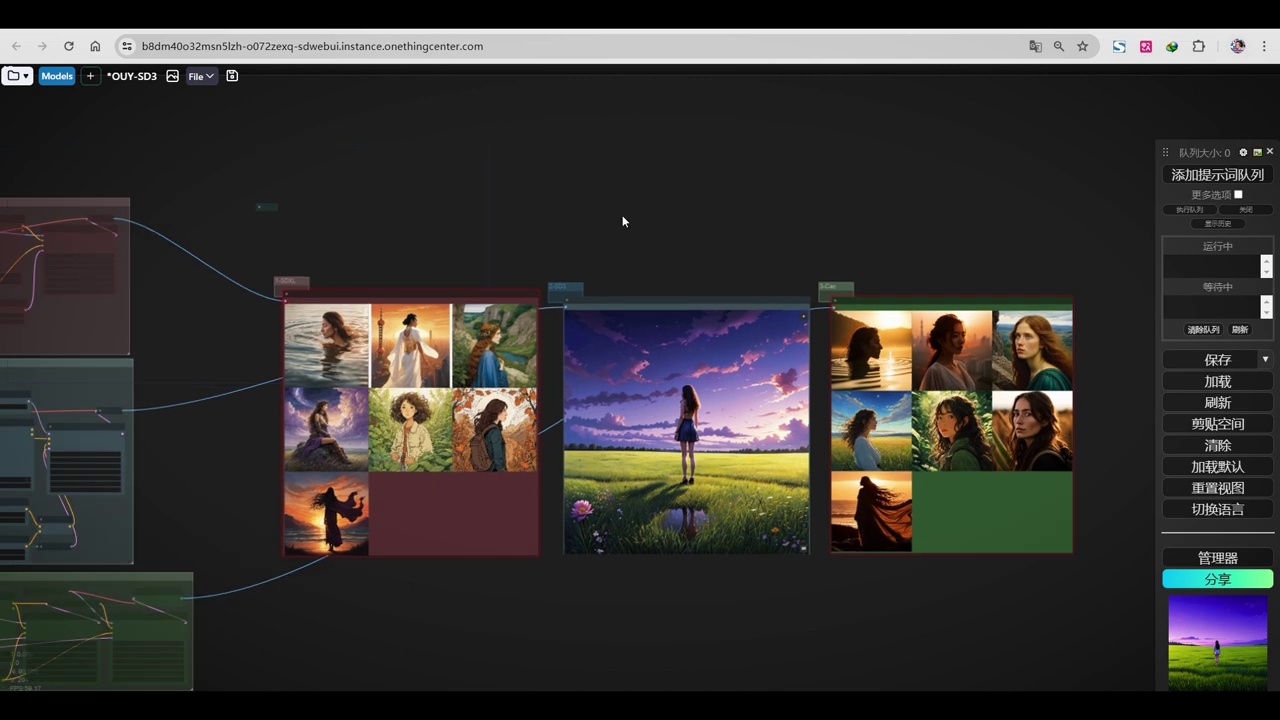
然后呢,我们来直接渲染声场。
最左边是cascade,中间是sd3,右边是sdxl。

这三张我觉得cascade比较好的,那sdxl也很适合。
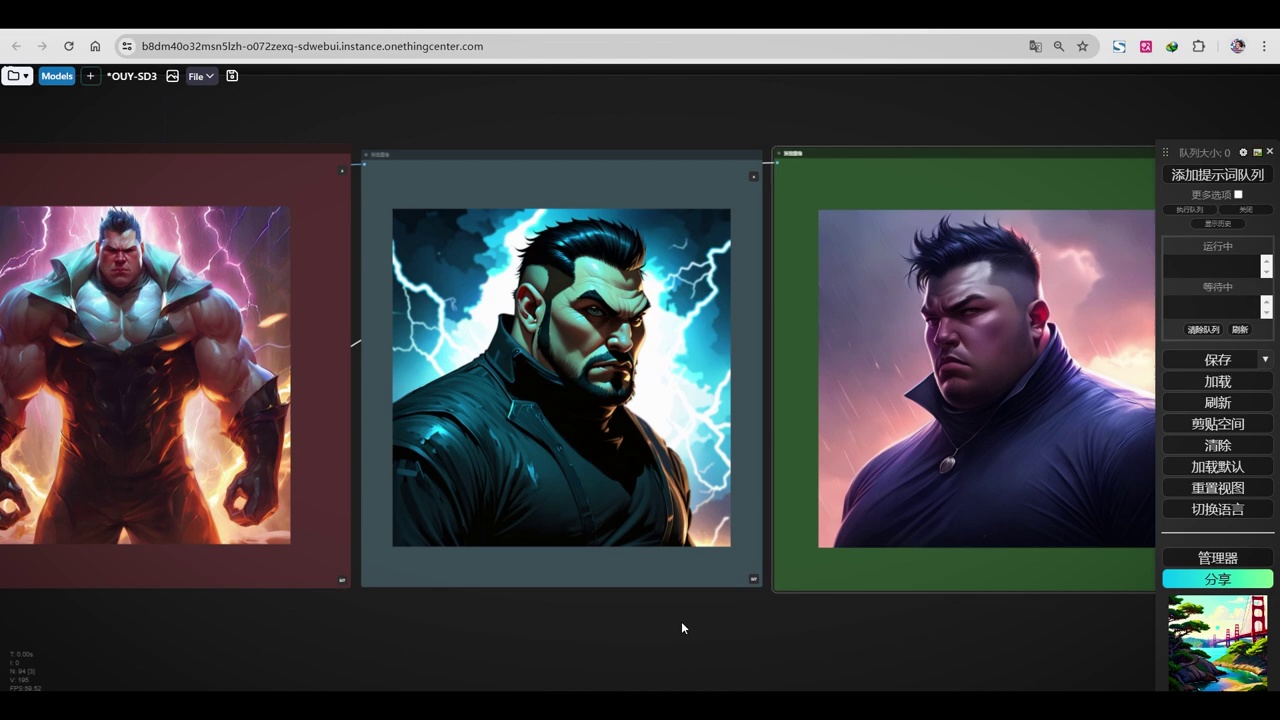
对于人物而言,cascade模型更具有风格性,特别是sd3模型。
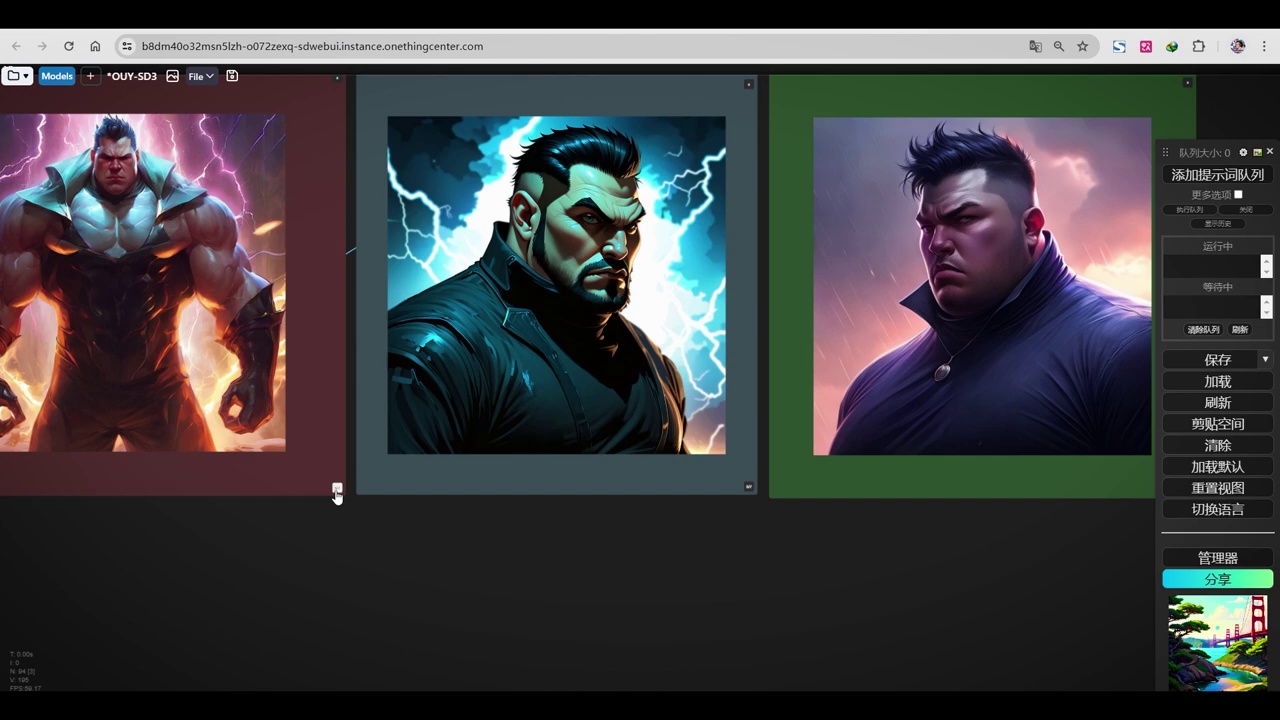
该作品风格性不强,画面存在问题,可能是由于合并方式不当所致,但整体观感尚可。
- 提示词使用可能不准确,建议直接使用单独的提示词。
- 描述了三组不同的生成图像:
- 第一组是sdxl,内容为一组车的风景。
- 第二组是sd3,内容为一组车的风景,增加了一个人物,两侧均为车辆,无异常。
- 第三组是cascade,内容为人物特写,展示的是sd4。
- sd3的图像风格中规中矩,无特定风格。

- sd3模型权重偏高,建议调整至3.5。
- 风景图像处理效果尚可,但人脸图像处理不佳。
- 图像变形问题源于基础数据质量不佳。
- 房间描述模糊导致图像风格不一致。
- 最后一张图像的水珠和水滴效果最佳,推荐使用sdxl模型。
首先我们来看一组风景。我们来到设置界面,由于翻译插件的问题,我将这些名称进行了修改。但重新加载工作流后,它们又恢复了原样。这是无法避免的,只能重新查找。我们选择一个风景主题。

我们保持其他设置不变,直接生成。初步观察,sdx的表现更为出色。相比之下,sd3的表现较为平淡,但其色彩处理和想象力较为丰富。这主要涉及到风格训练的问题。我们已降低了相应的权重。

- 作者对sdxl、casekit和sd3的表现进行了评价,认为sdxl表现最好,其次是casekit,sd3排名第三。
- 作者指出,单独比较提示词时,这些工具的表现并不特别突出。
- 作者计划进行进一步的测试。
一组人物吧,测试一组女性。
大家应该都喜欢看这位美女,接下来我们进行调整,选择通用选项,其他设置保持不变,再次生成,可以看到效果仍然不尽人意。
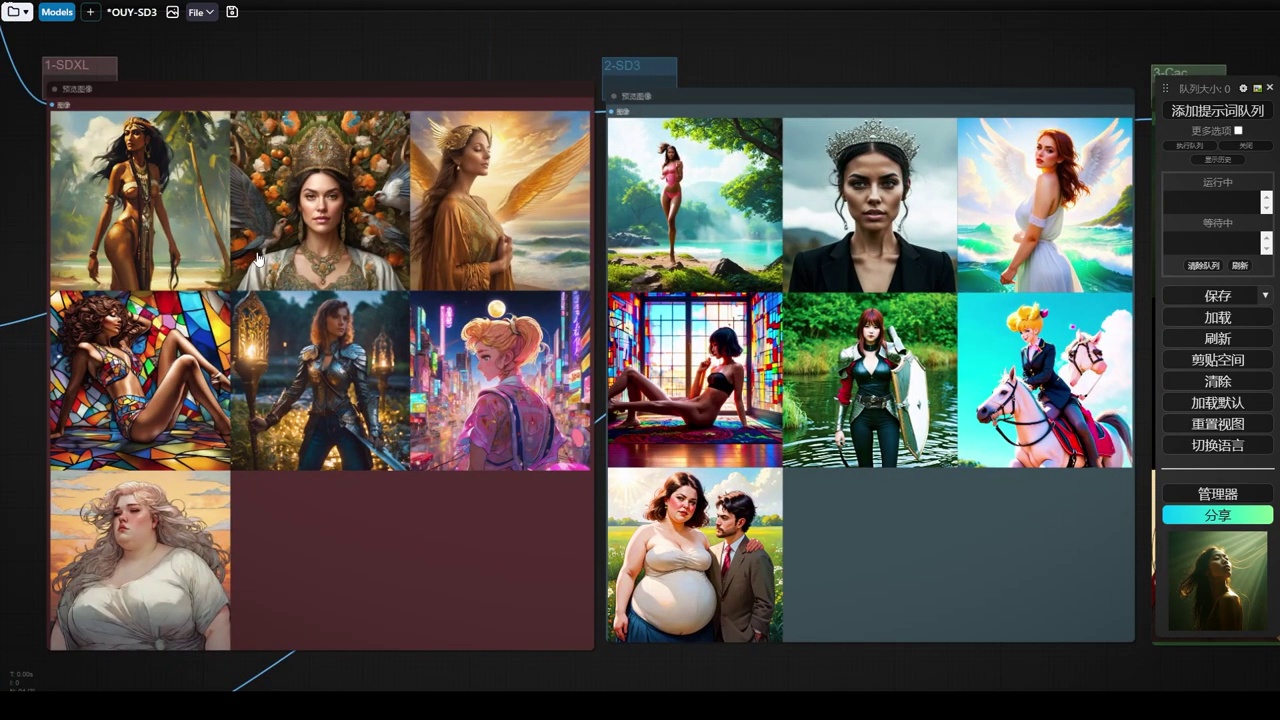
一样最好的还是sdxl。要注意我现在用的这个sdxl
xl是基础模型,最原始的base 1.0的模型。
能体现出来整体的风格。那cascade呢,稍微有些一般吧。
对于动漫的可以看到它就不太强,而对于sd3真的就不太强。
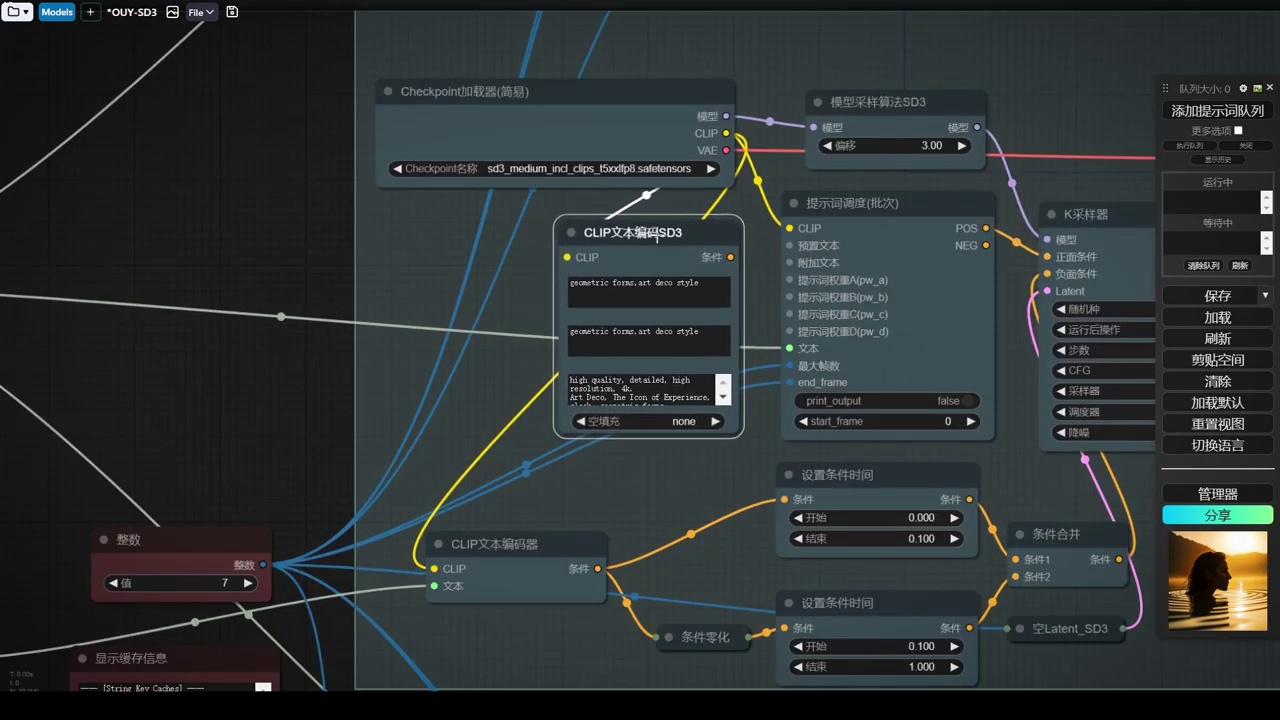
我怀疑是否配置错误,因为我们使用的是pf8的精度,并非实际的pf8。
- 讨论了使用不同版本的提示词(sdxl、1.5版本、cascade风格)对效果的影响。
- 指出如果需要提供cascade的ghl张量,可能会导致sdxl调度编码报错,因为张量不一致。
我们将直接统一设置为默认的 sdxl,不再使用其他选项如 g 或 l,取消这些设置,仅提供一个提示词,然后重新生成一轮。
其实用处不太大。

x4d xl 的质量略有下降,casket 也未进行调整。

- ouysd3 模型表现不佳。
- 其他两个模型在各方面优于 ouysd3。
- ouysd3 属于基础模型,风格训练不足。
- 尽管数据训练充分,但使用提示词测试时差距明显。
如果我们在此基础上采用这种方式进行丰富,观察是否能得到改善。这是第四章,我们直接复制第四章的提示词,并进行更为精彩的处理。
- 使用特定方法后,效果未达预期。
- 原因不明,可能与模型本身或版本有关。
- 建议尝试重新下载pf16版本。
- 提到liblib支持在线生成,将进行进一步验证。
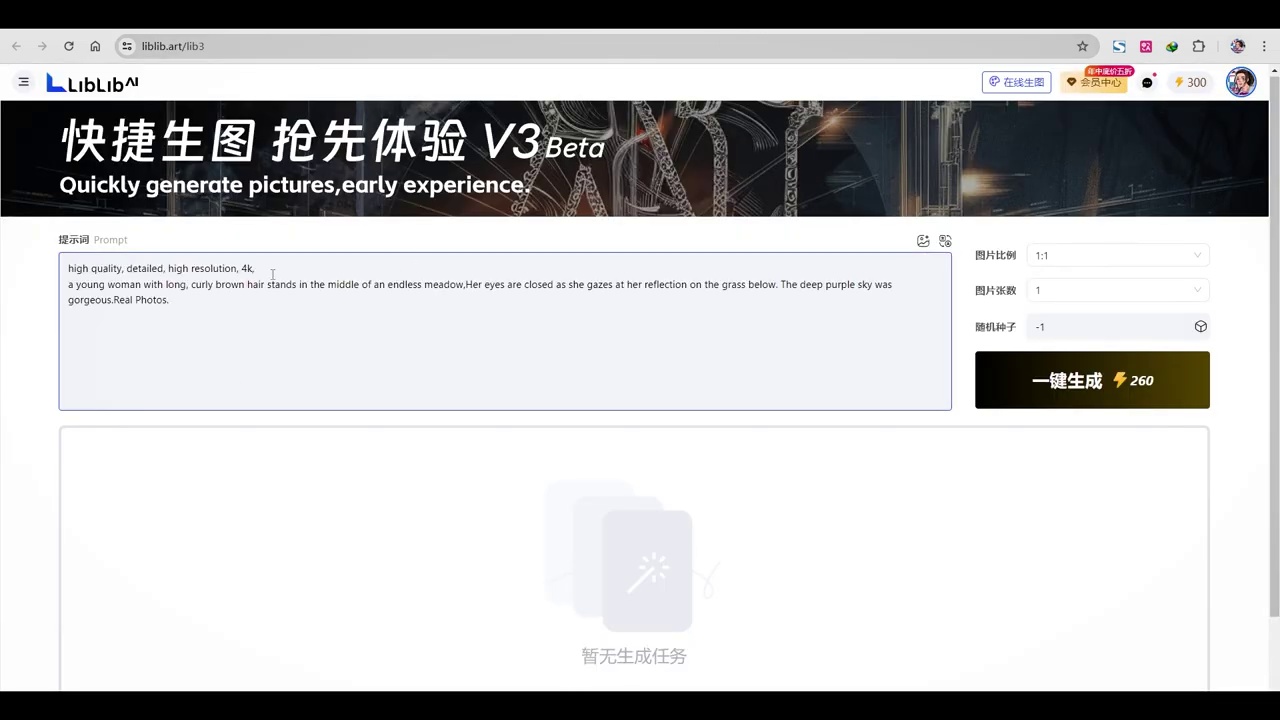
我们使用liblibartlib3的在线生图功能,直接复制了提示词。
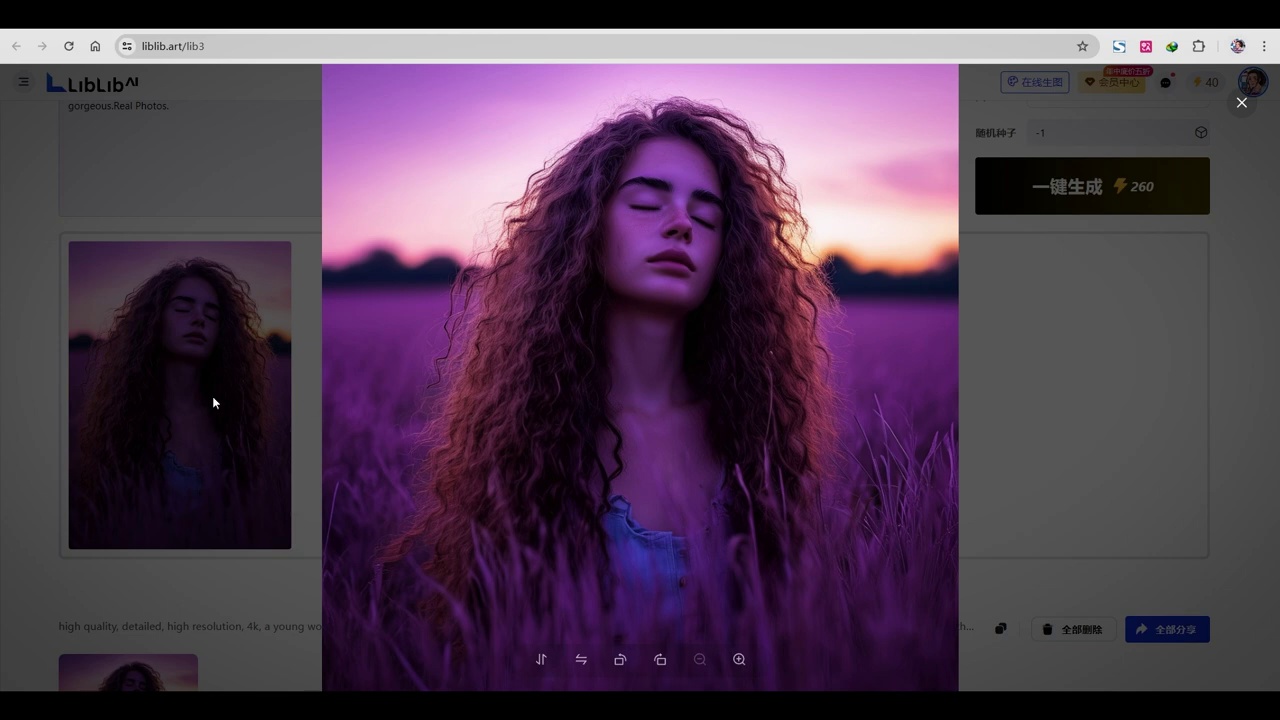
- liblibartlib3模型表现尚可,但仍需优化。
- 作者计划进一步探讨liblibartlib3的具体问题。
- 作者之前偏好cascade模型,但测试显示sd模型效果更佳。
- 作者将分享工作流,供大家测试不同模型和流程。
- 鼓励大家在评论区交流优化模型和流程的经验。
- 提供交流群供新手和有经验者共同探讨问题。
- 目前存在两种版本的v3:在线生成的v3和高级版v3。
- 高级版v3可能通过调用官方api实现,其效果显著。
- 计划对比官方api调用与本地模型调用的效果,以验证是否使用的是优化后的高级模型。
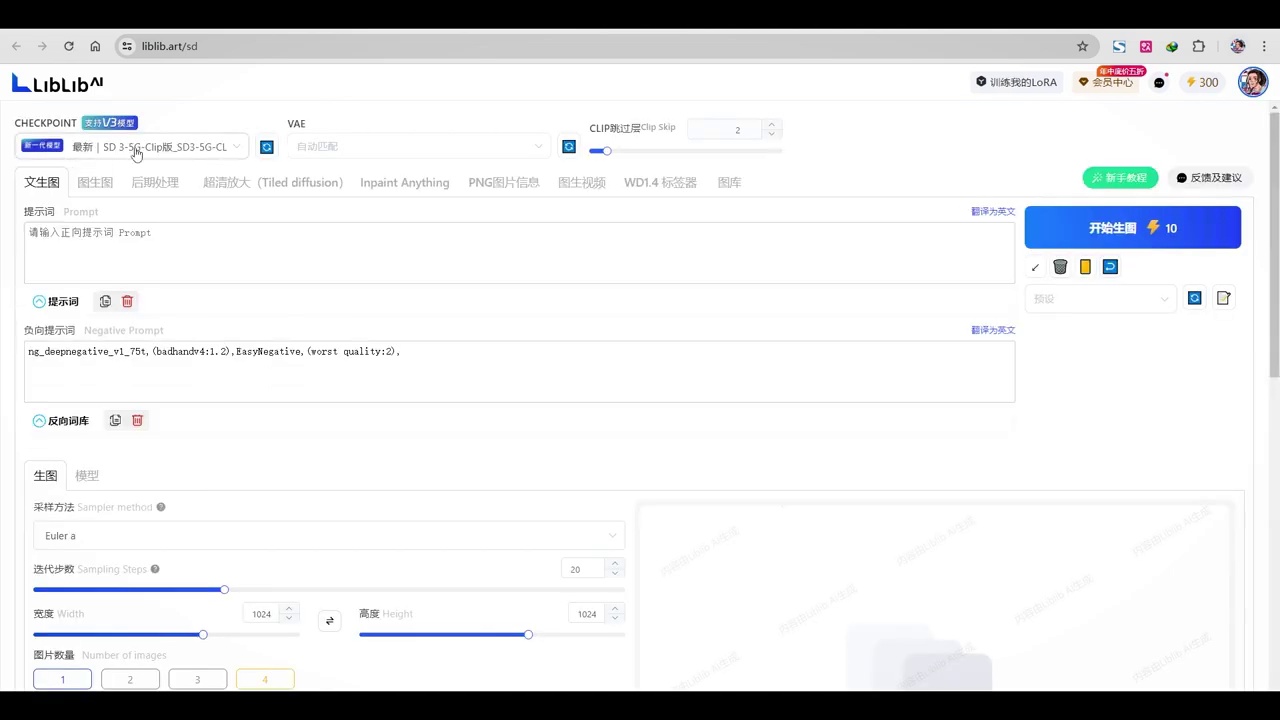
- libu在线生成平台全面支持sd3模型的调用。
- 该平台可能是sd3上线最快的在线生成平台。
- 用户复制粘贴提示词并设置采样器。
- 默认选择2m,迭代步数设为25步,提示强度调整为3.5。
- 图片数量增加至3张,用于对比。
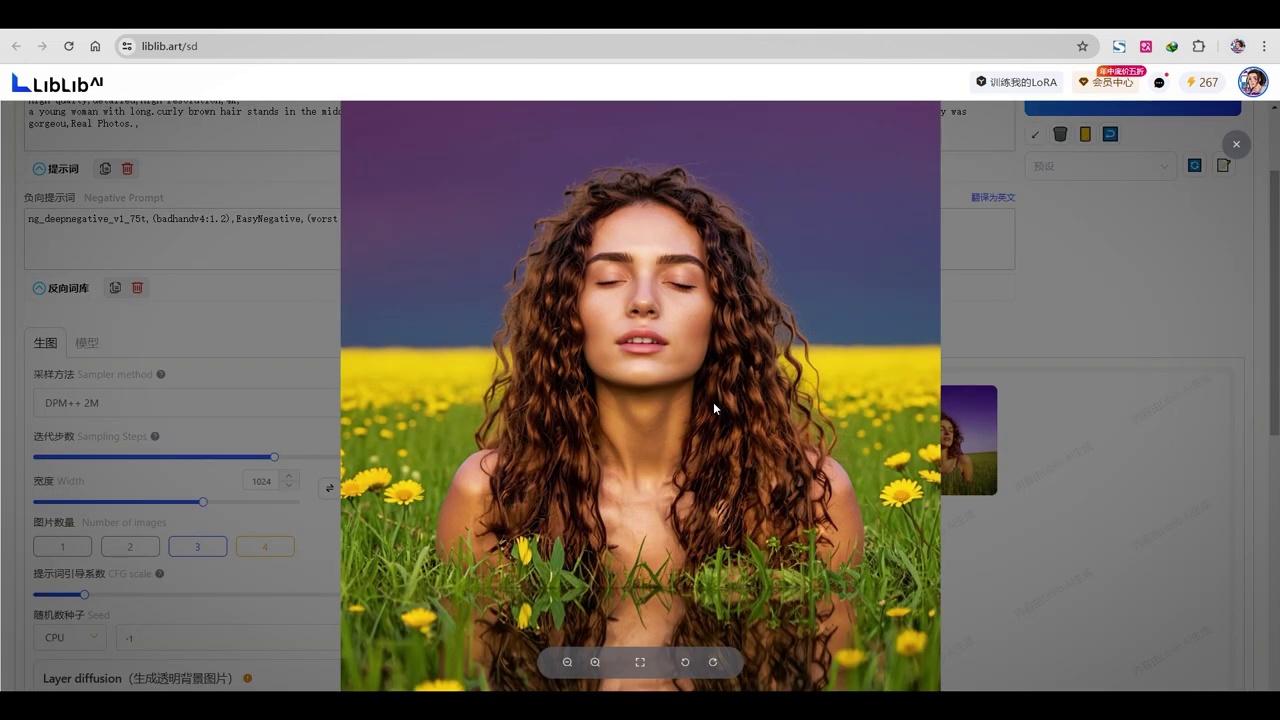
- 讨论了conf ui的noise生成方式与sd生成方式的差异。
- 建议尝试将生成方式改为sd以观察效果改善。
- 指出使用web ui进行生成操作的便捷性。
本期内容已全部分享完毕。若对您有所启发和参考价值,请不要忘记点击关注。后续还将有更多资讯、新闻及应用与大家分享。本期到此结束,下期再见。
本文总结
- sd第三代模型sd3基于sdxl进行训练,增强了tve解码部分,改善了对提示的理解和元素融合能力。
- sd3采用了三种clip编码,增加了文本编码器,训练数据量更大。
- 介绍了config ui的批处理操作,包括不同工作流的使用和动态提示词插件的安装。
- 讨论了模型的获取和配置,以及如何通过liblib网站下载和使用资源。
- 进行了不同模型的生成效果比较,探讨了提示词的调整和优化,以及在线生成与本地生成的差异。
金句摘抄
- “sd3的架构基于sdxl进行训练,首先我们可以看到tve解码部分得到了大幅增强,现在通道数为16。”
- “这一新一代模型采用了三种clip编码,在sdxl中,我们有两个编码器,一个是l,一个是g。”
- “对于国内用户,需下载并加载这些模型,最佳访问的资源网站是liblib。”
- “在服务器这边,我们来直接打开这个工作流,我已经等待半天了。”
- “我们来看一下这个风格,第一个水彩的,第二个是写实的。”
qa
- sd3与之前的模型架构有何不同?
- sd3基于sdxl进行训练,增强了tve解码部分,改善了对提示的理解和元素融合能力,并采用了三种clip编码。
- config ui的批处理操作包括哪些内容?
- config ui的批处理操作包括基础工作流、提词强化工作流和传统放大工作流,以及动态提示词插件的使用。
- 如何获取和配置模型资源?
- 可以通过访问liblib网站下载模型和资源,配置服务器和文件管理,以及使用题词卡片。
- 不同模型的生成效果如何比较?
- 通过调整提示词和优化设置,可以比较不同模型的生成效果,探讨在线生成与本地生成的差异。
- 如何使用动态提示词插件?
- 动态提示词插件可以在manager中搜索“dynamic”,安装后可以在新建节点处显示动态提示词,使用通配符文件进行随机调用。
结语
通过本篇文章的详细评测与教程,相信大家对最新的stable diffusion 3 (sd3) 模型有了更深入的了解。无论是模型的架构改进、性能提升,还是实际使用中的小技巧,我们都进行了全面的覆盖和解析。希望这些内容能为您的ai绘画创作提供帮助和灵感。
如果您觉得本期内容对您有所启发和参考价值,请不要忘记点击关注我们。关注不仅能让您第一时间获取最新的技术资讯和应用指南,还能帮助我们为您提供更优质的内容。此外,您也可以扫描下方的二维码,加入我们的交流社群。群内有众多ai技术爱好者和专业人士,大家可以在这里分享经验、解决疑问、共同进步。

期待与您在社群中交流,我们下期再见!

![[AI 大模型] 百度 文心一言](/images/newimg/nimg3.png)


发表评论