
我们今天来了解一下最近很火的sd模型
✨在人工智能领域,生成模型一直是研究的热点之一。随着深度学习技术的飞速发展,一种名为stable diffusion的新型生成模型引起了广泛关注。stable diffusion是一种基于概率的生成模型,它可以学习数据的潜在分布,并生成与训练数据相似的新样本。
web ui
这里我们使用sd的整合包,优点是十分简单迅速,不需要直接手动配置环境。
成功进入web ui界面
采样器选择
对于老派采样器,我们一般使用euler 和 euler a,a的意思是代表为祖先采样器,画面不能收敛(每一步都会向画面添加随机的噪声),所以每一步生成的画面都会有一些随机性,随着采样次数增加,画面也会每次都变化,优点就是可以给画面带来一点随机性,增加一些细节。而euler是可以收敛的采样器,随着采样次数增加,最终会趋向于一个固定的画面。
关于dpm算法:这是我们在stable diffusion用的最多的方法,我们按照时间速度来筛选的话,我们直接选择dpm++ 且后面跟着karras的算法就可以了。比如:dpm++2m karras 。
- 我们还可以选择stable diffusion新版本增加的unipc和restart采样器。
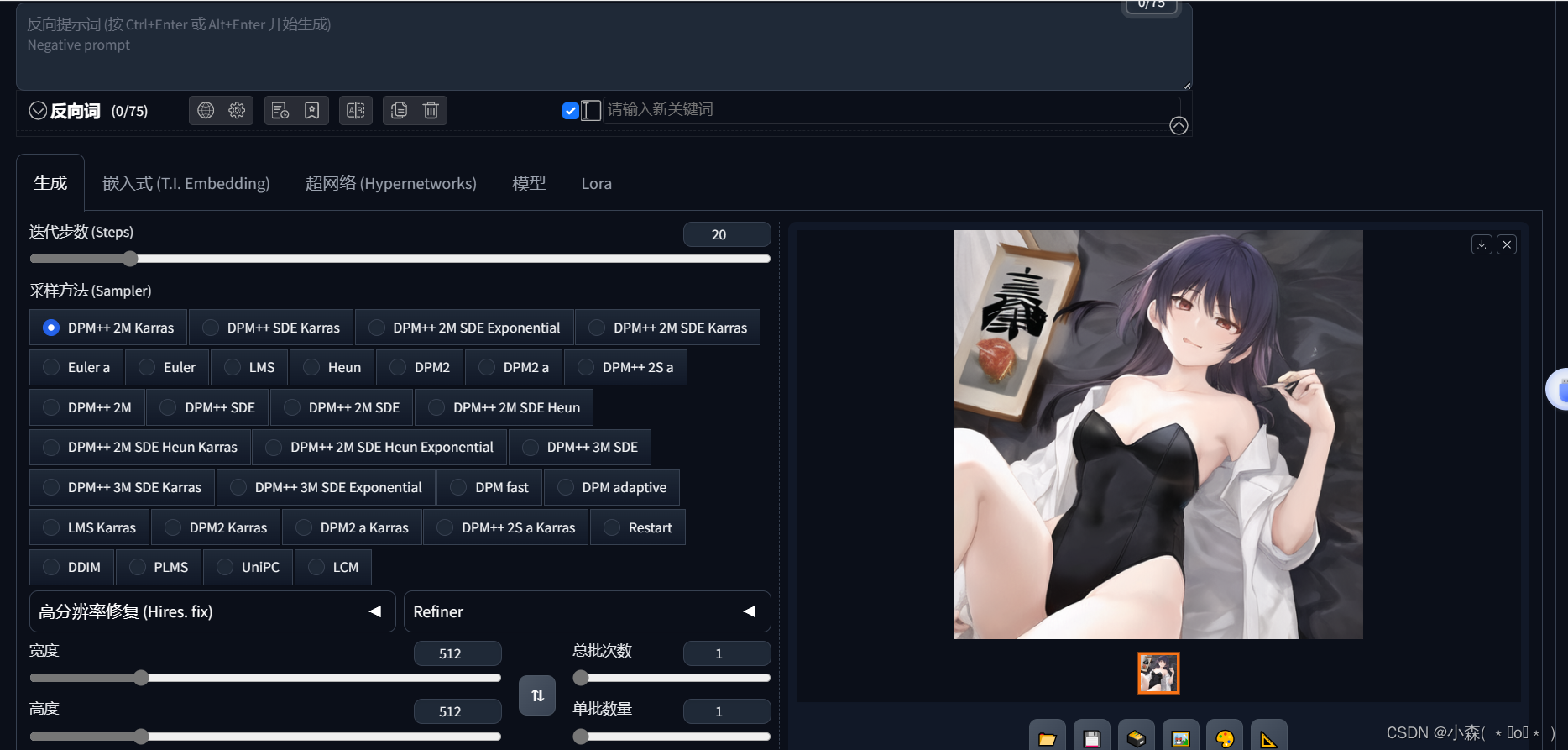
高清修复
此功能只存在于文生图页面中(hires. fix),我们直接在上张图片中的小三角直接点开就可以了,其中的放大倍数设置在2就可以了。
提示词
提示词是模型中最为重要的东西,即使有再好的模型和lora,我们也无法生成好的图片。如果我们感觉提示词很难写,我们也可以使用gpt来生成提示词(ai生成ai):
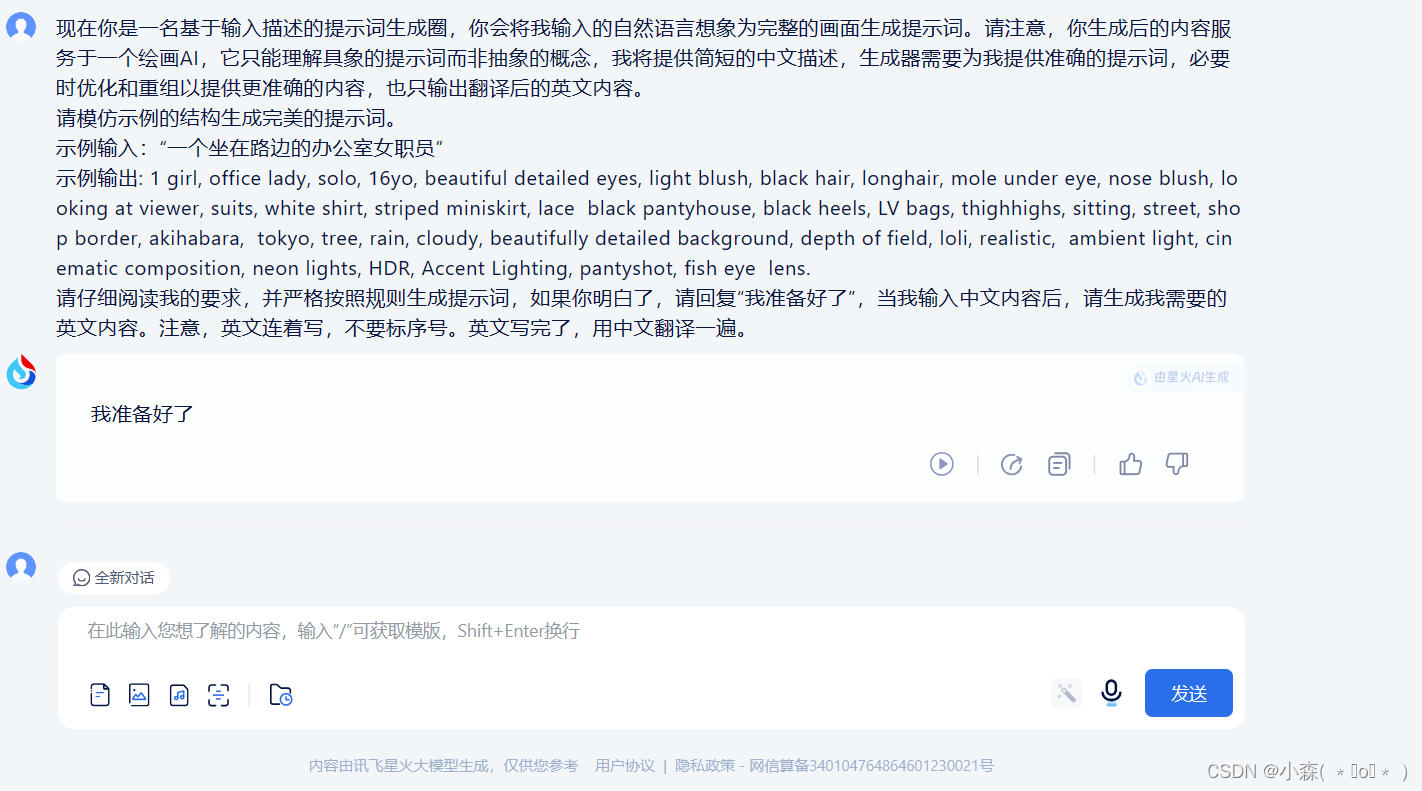
紧接着我们输入中文想要的句子,它还会帮我们拓展出一点内容:
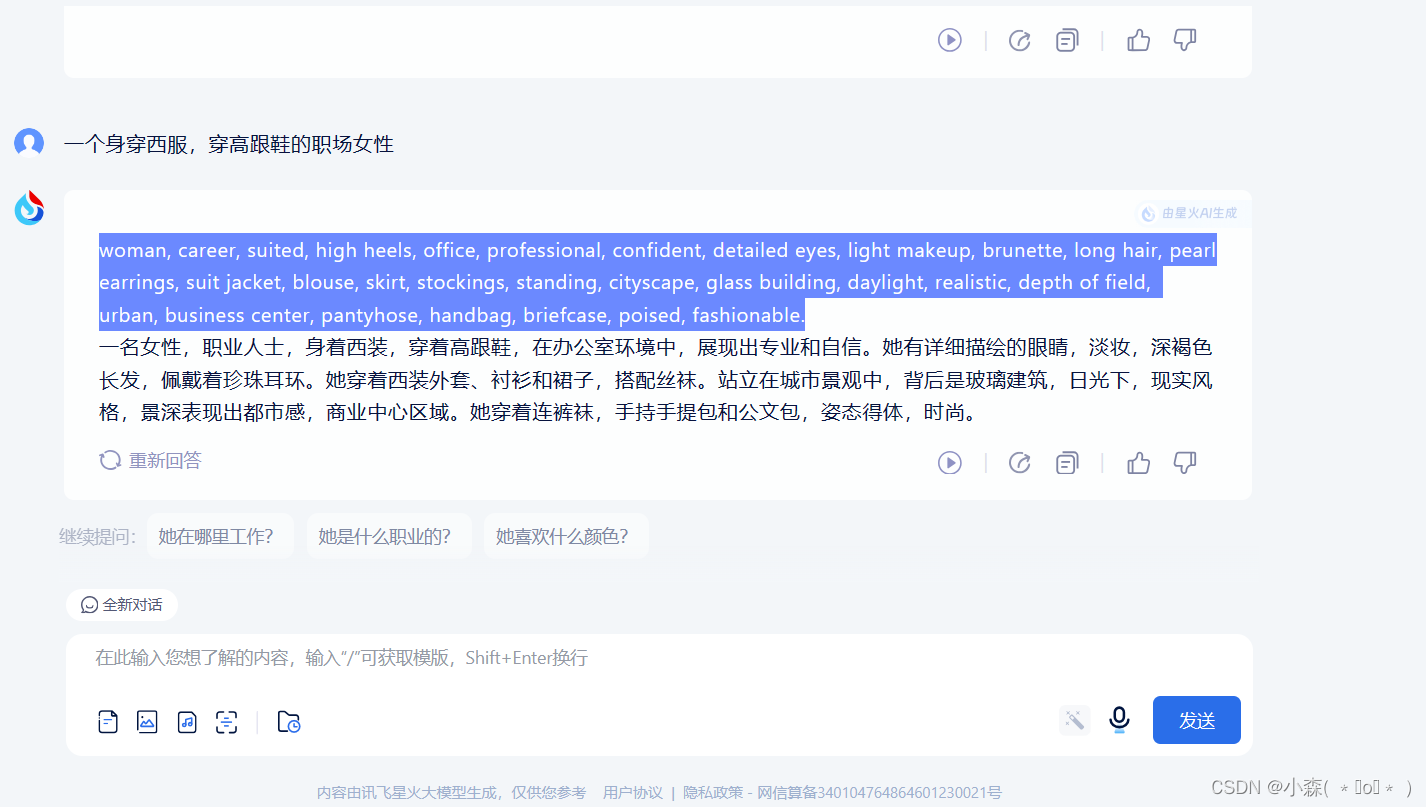
输出:
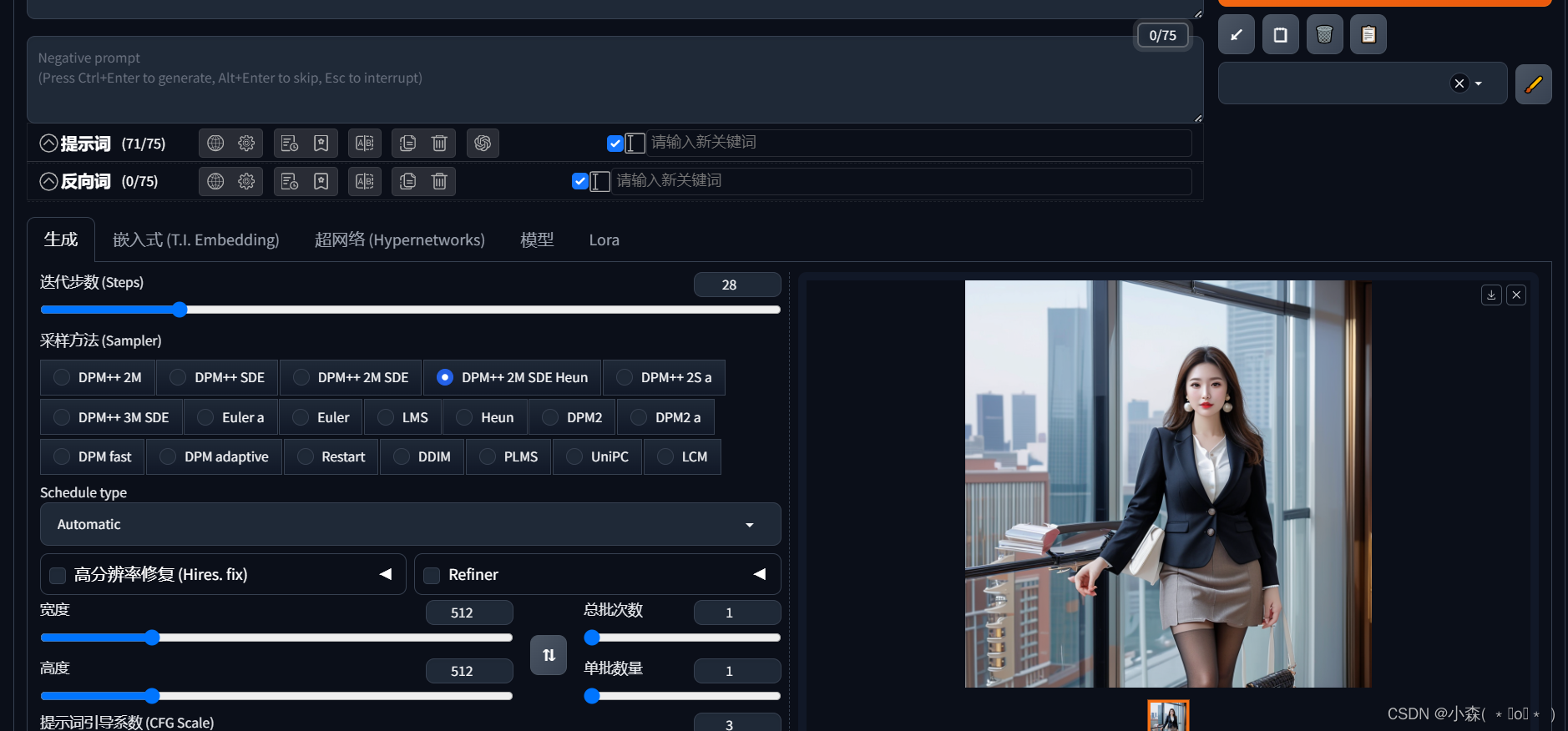
其中总批次数是指我们生成几次图片,单批次量是指每次生成时,一个图片包含几张图片,例如我们发朋友圈经常说的九宫格样式。
我们点击一个lora后,在提示词后面生成了一小段原生lora代码:
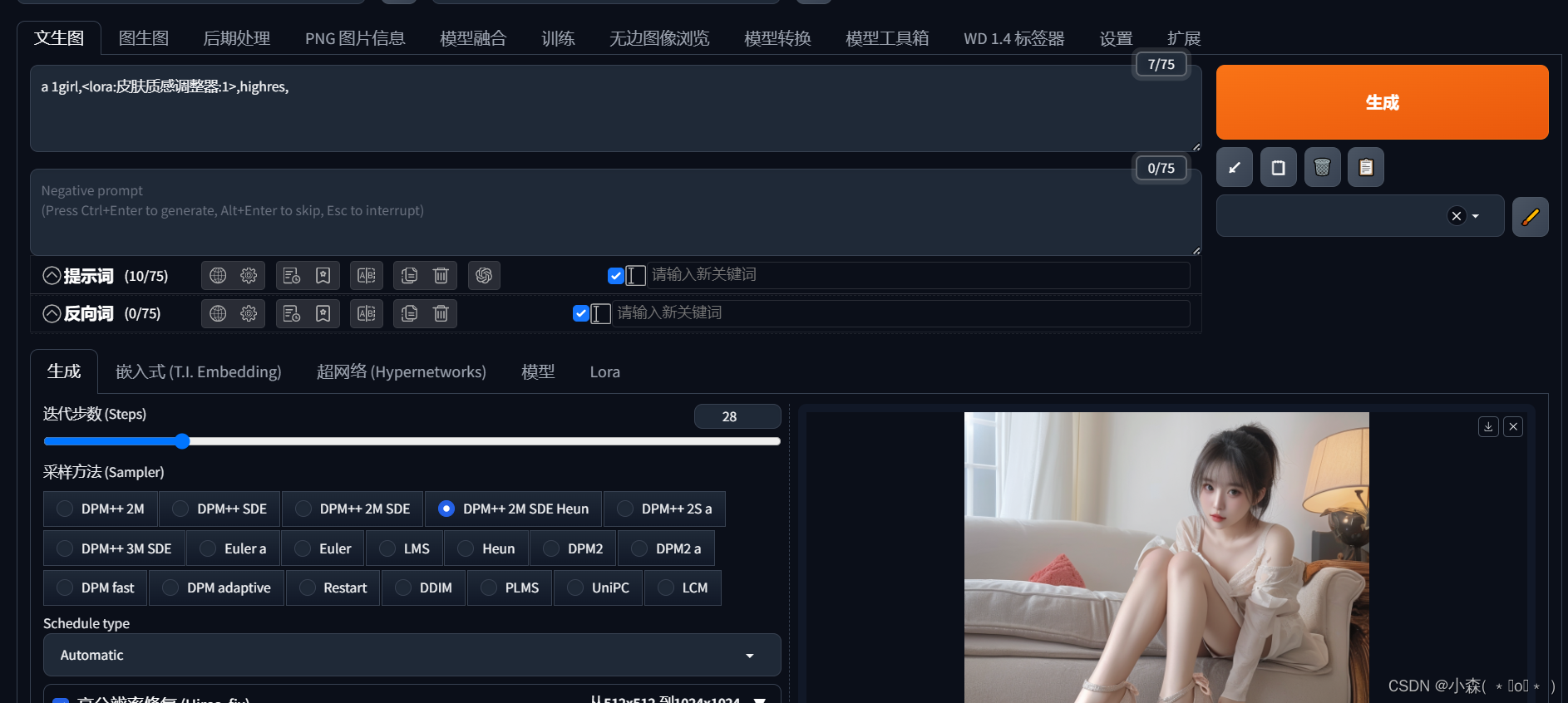
大模型与lora

我们可以去网站下载别人训练好的模型(尾缀 ckpt / safetensors),常见大小:2g -7g
存放路径一定要为:根目录\models\stable-diffusion
而lora则是微调模型,常见大小:100m左右
存放目录:根目录\models\lora
如果我们误将lora模型放到大模型目录下或相反,则我们在界面将无法正常切换模型。
同时我们还可以使用官方给出的提示词来copy:
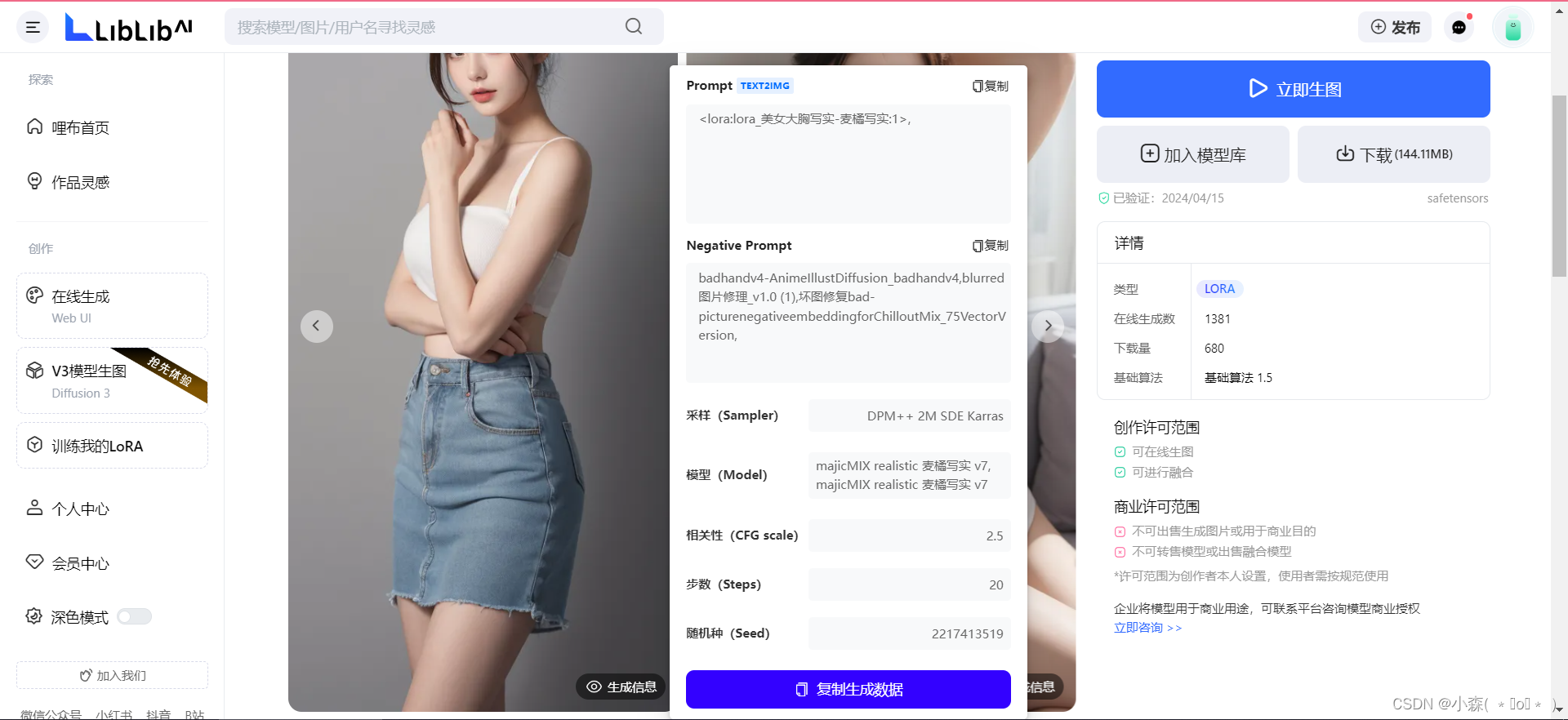
我们今天先分享到这,下期我们再学习高级操作~



发表评论