代码及注释
class bertforsequenceclassification(bertpretrainedmodel):
def __init__(self, config): # config:bert预训练模型的配置文件
"""调用父类的__init__方法,初始化bert的配置"""
super().__init__(config)
"""几分类"""
self.num_labels = config.num_labels
self.config = config
"""
实例化一个bert模型,并将其作为自己的一个组件。
在后续的前向传播 (forward 方法) 中,self.bert 实例将用于处理输入的文本数据(如 input_ids、token_type_ids 和 attention_mask),产生用于分类任务的特征表示。
这些特征(特别是经过池化后的输出)随后会传递给分类器头部以进行最终的多标签分类。
"""
self.bert = bertmodel(config)
"""
添加一个dropout层,用于防止过拟合
其丢弃比例默认由 config.hidden_dropout_prob 定义。
"""
classifier_dropout = (
config.classifier_dropout if config.classifier_dropout is not none else config.hidden_dropout_prob
)
self.dropout = nn.dropout(classifier_dropout)
"""
分类器层(线性变换层、全连接层)
将bert的池化输出(大小为config.hidden_size)转换为类别预测的logits(大小为config.num_labels,未经过softmax的原始输出)
y = wx + b,w是权重矩阵,x是输入向量,b是偏置向量,y是输出向量
"""
self.classifier = nn.linear(config.hidden_size, config.num_labels)
"""初始化权重并应用最终处理"""
self.post_init()
"""模型的核心推理逻辑部分"""
def forward(
self,
"""整数张量,表示输入序列的token ids"""
input_ids=none,
"""指示哪些token应当被模型注意的二进制张量,0表示忽略,1表示关注"""
attention_mask=none,
"""区分句子对中的两个句子的张量"""
token_type_ids=none,
"""序列中每个token位置的张量"""
position_ids=none,
"""是否掩蔽transformer层中的注意力头,用于精细调整模型"""
head_mask=none,
"""是否直接提供嵌入向量而非通过input_ids,可提供灵活性"""
inputs_embeds=none,
"""
监督学习的标签,定义了损失函数的计算方式(回归或分类)
当config.num_labels == 1时,模型计算回归损失(均方误差损失),
反之则计算分类损失(交叉熵损失)。
"""
labels=none,
"""是否返回注意力权重、隐藏状态以及是否以字典形式返回结果的布尔标志。"""
output_attentions=none,
output_hidden_states=none,
return_dict=none,
):
"""是否使用字典来返回模型的输出"""
return_dict = return_dict if return_dict is not none else self.config.use_return_dict
"""
当调用self.bert(...)时,bert模型会执行以下操作:
1. embedding layer: 将input_ids(或inputs_embeds)转换为词嵌入。
2. positional encoding: 添加位置信息到词嵌入中(如果未直接提供inputs_embeds)。
3. transformer layers: 输入通过一系列的transformer编码器层,每一层包含自注意力(self-attention)和前馈神经网络(feed-forward network)组件。
4. output processing: 根据output_attentions和output_hidden_states参数决定是否返回每层的注意力权重和隐藏状态。
5. final output: 最终输出通常包括last_hidden_state(序列中每个token的最终隐藏状态),也可能包括其他根据参数设定的附加输出。
outputs的结果:
1. last hidden state: `outputs[0]` 是序列中每个token经过bert编码后的最终隐藏状态,形状为 `[batch_size, sequence_length, hidden_size]`。这里,`hidden_size` 通常是768(对于bert-base)或1024(对于bert-large)。
2. pooled output: `outputs[1]` 是整个序列的池化表示(pooling output),它是通过对最后一个隐藏层的`[cls]`标记(分类标记)的输出进行进一步处理得到的,形状为 `[batch_size, hidden_size]`。这个`pooled_output`常用于下游的分类任务,因为它被认为捕获了整个输入序列的语义信息。
"""
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
"""
先获取bert的池化输出,
再通过dropout层,一个正则化技术,随机“丢弃”(设置为0)一部分神经元的输出以减少模型过拟合的风险。
然后将pooled_output映射到类别空间中。
如果分类任务有n个类别,那么logits将会是一个形状为(batch_size, n)的张量,
每一行对应一个样本,每一列对应一个类别的logit得分。
"""
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
loss = none
"""检查是否有实际的标签数据用于计算损失。
如果没有标签(例如,在预测阶段),则不需要计算损失。"""
if labels is not none:
if self.config.problem_type is none:
if self.num_labels == 1:
self.config.problem_type = "regression"
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = mseloss()
if self.num_labels == 1:
loss = loss_fct(logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = crossentropyloss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = bcewithlogitsloss()
loss = loss_fct(logits, labels)
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not none else output
return sequenceclassifieroutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
解释:
last_hidden_state中的[cls]位置输出:前向传播结束后,最后一层的隐藏状态输出矩阵中的第一行(或第一个元素,具体取决于维度排列)。它对应于输入序列开始处的特殊标记[cls](分类标记)的隐状态,用于代表整个句子的语义信息。- bert的池化输出
pooler_output:一个高维向量,具体数值依赖于输入bert的具体文本内容。假设我们有一个经过训练的bert模型,并且我们输入一句话:“i really enjoyed the movie.”,bert会对这句话进行编码处理,最终在所有处理步骤后,会得到一个与`[cls]`标记相关的隐藏状态,该隐藏状态可能会被用作`pooler_output`。这个输出通常是一个浮点数列表,表示了输入文本在bert的高维语义空间中的嵌入。一个简化的示例 `pooler_output` 可能看起来像这样(实际数值仅为示意):[0.123, -0.456, 0.987, ..., -0.321]这里的数组长度与bert的隐藏层维度相对应,对于bert-base模型,这个维度是768。每个值代表了输入文本在该维度上的特征强度,这些特征综合起来捕获了句子的整体意义。真实的`pooler_output`数值会根据模型权重和输入文本的具体内容有所不同。此向量可以用于后续的分类任务,比如判断这句话的情感倾向等。 - logits:未经归一化的分数向量,表示输入样本属于各个类别的概率分布的原始预测值。在多分类任务中,logits通常通过softmax函数转换为概率值。(归一化)
pooler_output是通过对last_hidden_state中的[cls]位置的输出向量进行进一步处理得到的。具体来说,bert模型会将这个[cls]向量传递给一个线性层(通常后面跟着一个激活函数,如tanh),从而产生一个固定维度的向量,相对于[cls]更抽象和浓缩。- 分类头利用
pooler_output(bert是如此,因为顶部是池化输出,其他或直接使用last_hidden_state的[cls]位置输出)进一步计算出类别预测所需的logits。这个过程可以视为从高层次语义表示到具体类别预测的映射。
单标签分类 vs 多标签分类
交叉熵损失 vs 带logits的二元交叉熵损失
交叉熵损失(cross-entropy loss)
- 适用场景:主要用于多分类问题,其中目标类别不止两个,而是存在多个类别。例如,图像分类任务中,可能需要从1000个不同的类别中选择正确的类别。
- 公式表示:对于多分类任务,假设模型输出为经过softmax函数处理后的概率分布yi,真实标签为one-hot编码形式pi,则交叉熵损失定义为
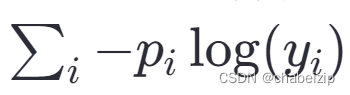 。
。
- 特点:鼓励模型的预测概率分布尽可能接近真实的标签分布,从而最小化两者之间的信息熵差异。
带logits的二元交叉熵损失(binary cross-entropy loss with logits)
- 适用场景:专为二分类问题设计,即目标只有两个类别(例如,是/否,正类/负类)。也适合改为多标签分类问题的损失函数。
- 公式表示:在这种情况下,模型直接输出未经softmax处理的logits——z,而真实标签 t 通常为0或1。损失函数定义为
![]()
,其中![]() 是sigmoid函数,用于将logits转化为概率。
是sigmoid函数,用于将logits转化为概率。
- 特点:二元交叉熵损失直接在logits层面计算,避免了额外的softmax操作,这样可以提高数值稳定性,并且在某些情况下计算更高效。它直接衡量了模型输出的logits与实际标签的匹配程度,非常适合处理二分类任务。
区别总结
- 适用范围:交叉熵损失适用于多分类问题,二元交叉熵损失专门用于二分类问题且适合改为用于多标签分类。
- 输出处理:交叉熵损失通常用在softmax之后的概率分布上,而二元交叉熵损失直接作用于模型的logits输出。
- 计算效率与稳定性:二元交叉熵损失由于直接在logits层面计算,有时能提供更好的数值稳定性和计算效率,尤其是在二分类问题中。




发表评论