导入数据
import pandas as pd
df = pd.dataframe([['liver','e',89,21,24,64],
['arry','c',36,37,37,57],
['ack','a',57,60,18,84],
['eorge','c',93,96,71,78],
['oah','d',65,49,61,86]
],
columns = ['name','team','q1','q2','q3','q4'])df
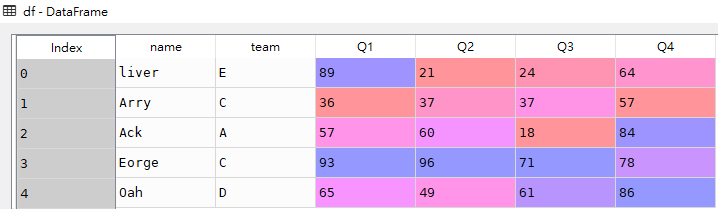
上述dataframe中的index索引列默认是从0开始的,那么我们如何设置index索引列起始值从1开始呢?
方法1
df.index = df.index + 1
方法2
df.index = range(1,len(df)+1)
df
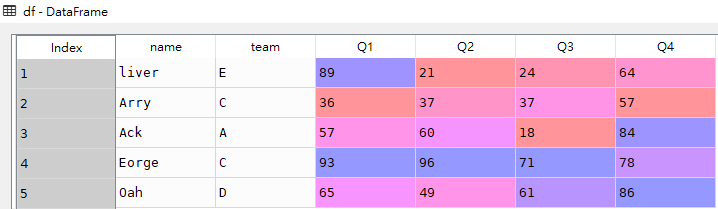
到此这篇关于pandas设置dataframe的index索引起始值为1的两种方法的文章就介绍到这了,更多相关pandas索引起始值为1内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!


![Python报错:OSError: [Errno 22] Invalid argument解决方案及应用实例](https://images.3wcode.com/3wcode/20240724/s_0_202407241131475453.jpg)


发表评论