前言
前面的一篇文章 go singleflight:防缓存击穿利器 详细介绍 singleflight 包的使用,展示如何利用它来避免缓存击穿。而本篇文章,我们来剖析 singleflight 包的源码实现和工作原理,探索单飞的奥秘。
singleflight 版本:
golang.org/x/sync v0.6.0
结构体解析
group
group 是 singleflight 包的一个核心结构体,它管理着所有的请求,确保同一时刻,对同一资源的请求只会被执行一次。该结构体的源码如下所示:
// group represents a class of work and forms a namespace in
// which units of work can be executed with duplicate suppression.
type group struct {
mu sync.mutex // protects m
m map[string]*call // lazily initialized
}
group 结构体有两个字段:
mu sync.mutex:一个互斥锁,用于保护下面的m映射。在并发环境下,多个goroutine可能会同时对m进行读写操作,所以需要通过互斥锁来确保对m的操作是安全的。m map[string]*call:一个map映射,其键是字符串,值是指向call结构体的指针。do和dochan方法的参数里,其中一个是key,m的键保存的就是这个key。m是惰性初始化的,意味着它在第一次使用时才会被创建。
group 通过维护 m 字段来跟踪每个 key 的调用状态,从而实现将多个请求合并成一个请求,多个请求共享同一个结果。
call
call 结构体表示一个针对特定 key 的正在进行中或者已完成的请求,它确保所有同时对该key调用 do 或 dochan 方法的 goroutine 共享同一个执行结果。该结构体的源码如下所示:
// call is an in-flight or completed singleflight.do call
type call struct {
wg sync.waitgroup
// these fields are written once before the waitgroup is done
// and are only read after the waitgroup is done.
val interface{}
err error
// these fields are read and written with the singleflight
// mutex held before the waitgroup is done, and are read but
// not written after the waitgroup is done.
dups int
chans []chan<- result
}
call 结构体有五个字段:
wg sync.waitgroup:一个等待组,用于等待当前call的完成。当调用do或dochan方法后,内部会增加waitgroup的计数器,当调用完成后,会减少计数器。在调用完成之前,其他想要获取当前call的结果的goroutine会等待waitgroup的完成。val interface{}:调用do或dochan方法的结果值之一,对应着fn函数(do或dochan方法的参数)的第一个返回值val。这个字段在waitgroup完成之前被写入一次,只有在waitgroup完成后才会被读取。err error:这是在调用do或者dochan方法时可能发生的错误。和val类似,这个字段在waitgroup完成之前被写入一次,只有在waitgroup完成后才会被读取。dups int:用于计数当前call的重复调用数量。这个计数是在singleflight的互斥锁保护下进行的,在waitgroup完成之前可以读写,在waitgroup完成后只能读取。目前该字段的作用是判断call的结果是否被共享。chans []chan<- result:一个通道切片,用于存储所有等待当前call结果的通道。这些通道在call完成时接收到结果。这个字段同样是在singleflight的互斥锁保护下进行的,在waitgroup完成之前可以读写,在waitgroup完成后只能读取。
一句话概括就是:call 结构体用于跟踪 do 或 dochan 方法的调用状态,包括等待其完成的 goroutine、调用的结果、发生的错误以及跟踪重复的调用次数,对于 singleflight 在共享调用结果中起到关键作用。
result
result 是一个封装了请求调用结果的结构体,在dochan 方法返回结果时使用。该结构体的源码如下所示:
// result holds the results of do, so they can be passed
// on a channel.
type result struct {
val interface{}
err error
shared bool
}
result 结构体有三个字段:
val interface{}:存储dochan方法调用的结果值之一,对应着fn函数(dochan方法的参数)的第一个返回值val。err error:存储dochan方法调用过程中可能发生的错误。shared bool:表示调用结果是否被多个请求(goroutine)共享。该字段的值,取决于call结构体的dups字段值,如果dups大于 0,shared的值则为true,否则为false。
panicerror
panicerror 用于封装从 panic 中恢复的任意值和在给定函数执行期间产生的堆栈跟踪信息。该结构体的源码如下所示:
// a panicerror is an arbitrary value recovered from a panic
// with the stack trace during the execution of given function.
type panicerror struct {
value interface{}
stack []byte
}
// error implements error interface.
func (p *panicerror) error() string {
return fmt.sprintf("%v\n\n%s", p.value, p.stack)
}
func (p *panicerror) unwrap() error {
err, ok := p.value.(error)
if !ok {
return nil
}
return err
}
func newpanicerror(v interface{}) error {
stack := debug.stack()
// the first line of the stack trace is of the form "goroutine n [status]:"
// but by the time the panic reaches do the goroutine may no longer exist
// and its status will have changed. trim out the misleading line.
if line := bytes.indexbyte(stack[:], '\n'); line >= 0 {
stack = stack[line+1:]
}
return &panicerror{value: v, stack: stack}
}
字段
panicerror 结构体有两个字段:
value interface{}:存储从panic中恢复的值,这个值是任意类型的,可能是error类型,也可能是其它类型。stack []byte:存储堆栈跟踪信息的字节切片,这个堆栈跟踪提供了panic发生时的函数调用层次结构和顺序,有助于调试和诊断问题。
方法
panicerror 结构体有两个方法:
error() string:实现了error接口的error方法。它将panicerror结构体的value和stack字段的格式化成一个字符串。unwrap() error:实现了wrapper接口的unwrap接包方法,尝试将value字段断言为error类型并返回。如果value不是一个error类型,它将返回nil。这个方法使得panicerror能够与 go 的错误处理机制(如errors.is和errors.as)更好地集成。
初始化函数
newpanicerror(v interface{}) error:这个函数用于创建一个新的 panicerror 实例。它接受从 panic 中恢复的值作为参数,然后通过 debug.stack 获取堆栈信息,并移除堆栈信息的第一行(如 goroutine 的编号和状态),因为这一行包含的信息可能会因为 panic 的恢复而变得不准确。最后,返回指向 panicerror 实例的指针。
核心方法解析
do
func (g *group) do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool) {
// 获取锁
g.mu.lock()
// 懒初始化 map
if g.m == nil {
g.m = make(map[string]*call)
}
// 判断特定 key 的 call 是否正在进行调用
if c, ok := g.m[key]; ok {
// 重复调用次数加 1
c.dups++
// 解锁
g.mu.unlock()
// 挂起,等待调用的完成
c.wg.wait()
// 判断是否发生了 panic
if e, ok := c.err.(*panicerror); ok {
// panic
panic(e)
} else if c.err == errgoexit { // 判断是否发生了 runtime.goexit
// 执行 runtime.goexit,停止当前 goroutine 的执行,并确保所有 defer 语句的执行
runtime.goexit()
}
// 返回结果
return c.val, c.err, true
}
// 创建一个新的调用
c := new(call)
// 等待组加 1
c.wg.add(1)
// key 和 call 映射
g.m[key] = c
// 释放锁
g.mu.unlock()
// 调用开始,执行所接受的函数 fn
g.docall(c, key, fn)
// 返回结果
return c.val, c.err, c.dups > 0
}
do 方法的执行流程如下所示:
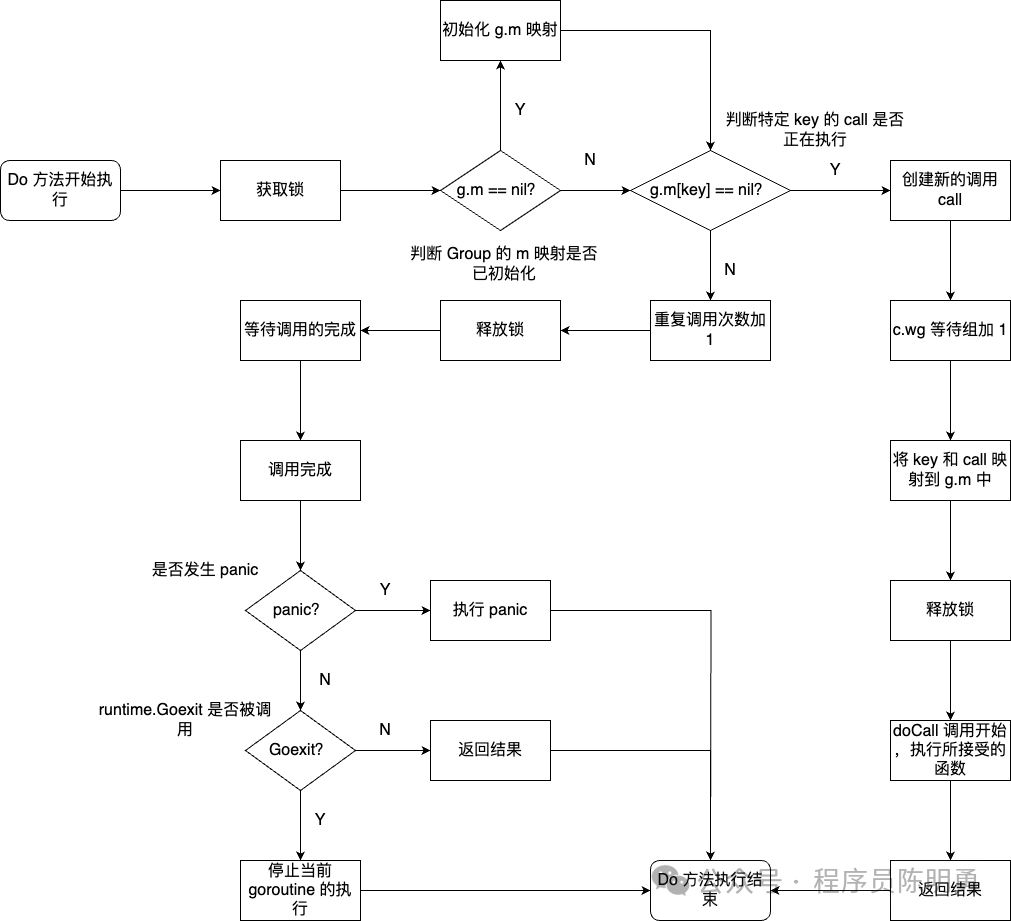
1、获取锁:通过 g.mu.lock() 加锁,确保对内部的 g.m(一个 map,用于跟踪 key 的调用状态) 和 c.dups(对于该 key 的重复调用次数) 的访问是并发安全的。
2、初始化 map:如果 g.m == nil,意味着是第一次调用 do 方法且没有调用过 dochan 方法,所以初始化 g.m。
3、检查是否有正在进行的调用:通过 c, ok := g.m[key]; ok 检查是否有一个对于该 key 的调用正在进行,如果 ok 为 true,则说明有一个对于该 key 的调用正在进行:
- 增加重复调用次数
c.dups,表示来了一个新的goroutine在等待这个调用结果。 - 释放锁
g.mu.unlock(),因为不再需要修改共享资源。 - 等待
c.wg.wait(),直到当前的调用完成。 - 检查错误类型,并按需处理(如果是
panicerror或errgoexit,则分别触发panic或goexit)。 - 返回当前进行的调用的结果。
4、初始化并执行新的调用:如果没有一个对于该 key 的调用正在进行,则:
- 创建一个新的
call实例。 c.wg等待组计数加 1,标记新操作的开始,后续有相同调用的请求将会等待该操作的完成并共享结果。- 在
g.m中注册key和新创建的call实例的映射g.m[key] = c。 - 释放锁。
- 调用
g.docall(c, key, fn)执行实际的函数调用。 - 返回调用结果。
do 方法的关键在于综合使用等待组(sync.waitgroup)、互斥锁(sync.mutex)以及一个映射(map),以确保:
- 对于相同的
key,fn函数只会被执行一次。这是通过map检查当前key是否存在对应的call实例来实现的。如果已存在,意味着函数调用正在执行或已完成,不需要再次执行。 - 同一时刻,所有请求同一
key的调用都能得到同一个结果。通过map追踪特定key对应的调用结果,确保所有的goroutine对同一key发起do方法调用都能共享相同的结果。 - 正确地处理并发和同步。通过
sync.mutex保护并发环境下map的读写操作,避免并发冲突;通过sync.waitgroup等待异步操作完成,保证所有请求都在函数执行完成后才返回结果。
docall
docall 方法负责执行给定 key 的函数 fn,并处理可能的错误和同步执行结果,确保所有请求该key的goroutine 得到统一的结果。该方法的源码如下所示:
func (g *group) docall(c *call, key string, fn func() (interface{}, error)) {
// 定义正常返回标志
normalreturn := false
// 定义 panic 标志
recovered := false
// 使用双重 defer 来区分 panic 和 runtime.goexit
defer func() {
// fn 函数里面调用了 runtime.goexit 函数
if !normalreturn && !recovered {
// 将 errgoexit 的值赋给 c.err
c.err = errgoexit
}
// 加锁
g.mu.lock()
// 函数执行结束时释放锁
defer g.mu.unlock()
// 标记 call 的完成
c.wg.done()
// 保险起见,判断当前 key 对应的 call 是否被覆盖,没有被覆盖就从 map 中移除这个 key
if g.m[key] == c {
delete(g.m, key)
}
// 判断执行 fn 的时候是否发生 panic
if e, ok := c.err.(*panicerror); ok {
// 避免等待中的通道永久阻塞,如果发生了 panic,需要确保这个 panic 不能被捕获
if len(c.chans) > 0 {
// 开一个新的协程去 panic,这个 panic 就不会被捕获了
go panic(e)
// 保持当前 goroutine 的存活,这样等到 panic 之后,关于当前 goroutine 的信息就会出现在堆栈中
select {}
} else {
// 直接 panic
panic(e)
}
} else if c.err == errgoexit {
// 如果是 errgoexit,什么都不用做,因为之前已经执行了 runtime.goexit
} else {
// 向等待中的通道发送结果
for _, ch := range c.chans {
ch <- result{c.val, c.err, c.dups > 0}
}
}
}()
func() {
defer func() {
// 如果 fn 没有正常执行完
if !normalreturn {
// 获取从 panic 中恢复的值
if r := recover(); r != nil {
// 创建一个 `panicerror` 实例并赋值给 c.err
c.err = newpanicerror(r)
}
}
}()
// 执行函数调用
c.val, c.err = fn()
// 设置正常返回标志为 true
normalreturn = true
}()
// 如果 fn 没有正常执行完,则发生了 panic
if !normalreturn {
// 设置 panic 标志为 true
recovered = true
}
}
代码剖析:
- 标志位定义:定义
normalreturn和recovered用来区分fn是否正常执行完成或者发生了panic。 - 双重
defer机制:目的是为了能够区分fn函数的正常执行完成、fn函数里发生的panic以及fn函数里调用runtime.goexit终止协程的情况。第一个
defer用于清理资源和处理结果。- 如果非正常函数执行完成并且没有发生
panic,则fn里执行了runtime.goexit函数。 - 加锁,调用
c.wg.done()以标记call调用完成,然后从g.m映射中移除当前key。 - 错误处理。
- 如果
fn函数中发生了panic,先判断是否有通道正在等待结果,有的话,新开一个协程去panic,确保panic不能被恢复,这里还用到了select{}来阻塞当前线程,保证panic之后,当前goroutine的信息会出现在堆栈中。如果没有通道正在等待结果,则直接panic。 - 如果是
errgoexit错误,说明fn函数中执行了runtime.goexit,这时什么都不用做。
- 如果
- 结果同步。如果没有发生
error,就向正在等待的通道发送结果。
- 如果非正常函数执行完成并且没有发生
第二个
defer在一个匿名函数里,它的目的是执行fn函数和捕获panic。如果fn函数正常执行完成,normalreturn就会被设置为true;在defer里,如果normalreturn为false,则说明可能发生了panic,通过recover()函数尝试恢复panic并新建一个panicerror存储信息。
recovered标志更新:如果fn函数非正常执行成功(normalreturn为false),则将recovered赋值为true,表示发生了panic。
call 方法的关键在于使用了双重 defer 机制,结合标志 normalreturn 和 recovered 来判断 fn 函数的状态。normalreturn 和 recovered 有三组值:
normalreturn为true,recovered为false:表明fn函数执行成功,后续执行第一个defer时,除了资源清理以外,还会向等待中的通道发送调用完成的结果。normalreturn为false,recovered为true:表明在fn函数里发生了panic,并且这个panic被成功捕获并恢复。后续执行第一个defer时,除了资源清理以外,会再次触发panic。normalreturn为false,recovered为false:这种情况说明在fn函数里,调用了runtime.goexit函数终止当前协程,不再执行后续的代码。这意味着normalreturn = true和recovered = true代码都不可能被执行,因此normalreturn和recovered的值都为false。后续执行第一个defer时不会向等待的通道发送任何结果,仅仅是进行资源清理。
dochan
dochan 方法与 do 方法类似,但是它返回的是一个通道,通道在操作完成时接收到结果。返回值是通道,意味着我们能以非阻塞的方式等待结果。该方法的源码如下所示:
func (g *group) dochan(key string, fn func() (interface{}, error)) <-chan result {
// 创建一个通道,类型为 result
ch := make(chan result, 1)
// 加锁
g.mu.lock()
// 懒初始化 map
if g.m == nil {
g.m = make(map[string]*call)
}
// 判定该 key 是否有正在进行的调用
if c, ok := g.m[key]; ok {
// 重复调用次数加 1
c.dups++
// 将新通道添加到通道切片里
c.chans = append(c.chans, ch)
// 释放锁
g.mu.unlock()
// 返回通道
return ch
}
// 创建一个 call 实例,并将 ch 通道作为参数传递
c := &call{chans: []chan<- result{ch}}
// 等待组加 1
c.wg.add(1)
// key 和 call 映射
g.m[key] = c
// 释放锁
g.mu.unlock()
// 异步执行调用
go g.docall(c, key, fn)
// 返回通道
return ch
}
dochan 方法的执行流程如下所示:
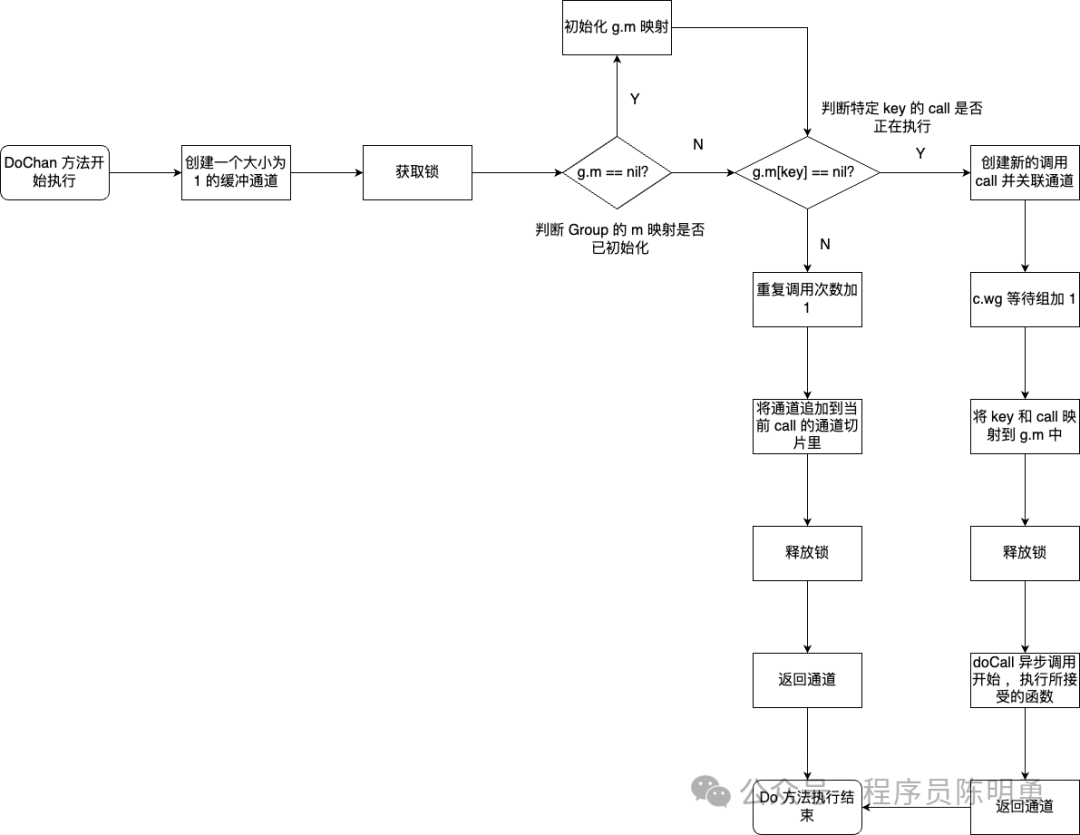
1、创建一个大小为 1 的缓冲通道。
2、获取锁:通过 g.mu.lock() 加锁,确保对内部的 g.m(一个 map,用于跟踪 key 的调用状态) 和 c.dups(对于该 key 的重复调用次数)以及 c.chans(通道切片) 的访问是并发安全的。
3、初始化 map:如果 g.m == nil,意味着是第一次调用 do 方法且没有调用过 dochan 方法,所以初始化 g.m。
4、检查是否有正在进行的调用:通过 c, ok := g.m[key]; ok 检查是否有一个对于该 key 的调用正在进行,如果 ok 为 true,则说明有一个对于该 key 的调用正在进行:
- 增加重复调用次数
c.dups,表示来了一个新的goroutine在等待这个调用结果。 - 将新创建的通道追加到当前
call的通道切片里。 - 释放锁
g.mu.unlock(),因为不再需要修改共享资源。 - 返回新创建的通道。
5、初始化并异步执行新的调用:如果没有一个对于该 key 的调用正在进行,则:
- 创建一个新的
call实例,并关联新创建的通道。 c.wg等待组计数加 1,标记新操作的开始,后续有相同调用的请求将会等待该操作的完成并共享结果。- 在
g.m中注册key和新创建的call实例的映射g.m[key] = c。 - 释放锁。
- 异步调用
g.docall(c, key, fn)执行实际的函数调用。 - 返回新创建的通道。
dochan 与 do 方法的区别在于同步共享结果的方式:
do 方法:
- 如果有其他请求正在进行(对同一个
key),它会使用sync.waitgroup等待这个请求完成以共享结果。 - 如果是针对给定
key的新请求,它将直接启动docall来执行函数调用,等待执行完成且call实例的更新,然后返回结果。
dochan 方法:为每个调用创建一个新的通道,将其加入到对应 key 的 call 实例的通道切片里,然后返回一个通道。这样,等 g.docall 正常异步调用完成后,会向各个通道发送结果。
forget
forget 方法用于从 g.m 移除特定 key 的调用。
func (g *group) forget(key string) {
// 加锁
g.mu.lock()
// 移除特定的 key
delete(g.m, key)
// 释放锁
g.mu.unlock()
}
该方法在删除特定 key 前执行加锁操作,保护并发环境下 map 的读写操作,避免并发冲突。
小结
本文对 go singleflight 的源码进行剖析,该包的主要作用是用于防止重复的请求,它确保给定的 key,函数在同一时间内只执行一次,多个请求共享同一结果。singleflight 能实现这种效果,关键点在于:
将多个相同请求合并成一个请求,确保函数只执行一次:singleflight 为了解决这个问题,引入了互斥锁 sync.mutex 和 map。
互斥锁用于保护在并发环境下 map 的读写操作,避免并发冲突。
map 则负责将每一个唯一的 key 映射到 call 实例上,该实例包含了fn 函数的返回值和可能的错误等。
- 遇到一个尚未在
map中记录的key请求时,创建并执行一个新的call实例。 - 如果
map中已存在该key对应的call实例,表明有一个相同的请求正在执行或已完成,此时仅需等待此call完成并直接其共享结果。
结果共享机制:singleflight 通过阻塞式和非阻塞式两种方式,实现了结果的共享。
阻塞式机制:当多个请求通过 do 方法进行相同的调用时,它们处于等待状态(里面借助了 sync.waitgroup 来实现阻塞的效果),直到首个请求的 fn 函数的执行完毕。此后,等待的请求会接收到已完成的请求结果。
非阻塞式机制:相比于阻塞等待,当请求通过 dochan 方法发起时,每个请求会立即获得一个专属的通道。这些请求可以继续执行其他操作,直到它们准备好从各自的通道接收结果。在接收结果时,如果结果尚未发送过来,也会暂时处于阻塞状态。
除了以上两个关键点,还需要考虑错误的处理,singleflight 通过使用双重 defer 的机制,用于辨别 函数正常执行完成、函数里发生了 panic 以及 函数里调用了 runtime.goexit() 函数 三种情况,每种情况采取不同的处理机制。
到此这篇关于源码剖析golang中singleflight的应用的文章就介绍到这了,更多相关go singleflight内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论