前言
目前gpt本质上是续写,所以在待测函数函数定义清晰的情况下,单元测试可以适当依赖它进行生成。
收益是什么:
- 辅助生成测试用例&测试代码,降低单元测试编写的心智成本
- 辅助code review,帮助发现代码显式/潜在问题
本文测试环境:
- gpt: gpt-3.5-turbo
- go:go 1.17
本文实践场景:企业微信美图鉴赏机器人
生成单元测试的工作流如下:
- 选定你的待测函数
- 分析函数的依赖:结构体定义、repo依赖、repo interface抽象(用fx和wire框架依赖注入的话会方便很多)
- 组织prompt,准备施法
- 吟唱魔法,得到输出单元测试代码
- copy到ide里面缝缝补补,与预期出入太多的话,调整prompt重来/要求gpt按照某个标准重写(比如:请按照testcases的写法重写组织测试数据)
- 运行测试用例
话不多说,先上基础prompt:
写下列写下列代码中[待测函数名]函数的单测,要求覆盖全部逻辑。
断言使用require包。
测试用例以testcases的形式输出。
下面的部分,我按照工作流的繁杂程度,简单区分了下easy/normal/hard情况。
part1 easy:单个函数,无复杂依赖
单个函数,并且外部依赖都是开源库,那么直接把代码贴上去就行。
这里我们用图片压缩的独立函数举例: (prompt前摇咒语 + 代码片段)
写下列代码中compresspicture函数的单测,要求覆盖全部逻辑。
断言使用require包。
测试用例以testcases的形式输出。
// compresspicture the picture by resizing it to the specified width.
func compresspicture(picdata []byte, width uint) ([]byte, error) {
// decode the input image.
oldbuffer := bytes.newbuffer(picdata)
inputimg, _, err := image.decode(oldbuffer)
if err != nil {
return nil, err
}
// resize the image to the specified width.
outputimg := resize.resize(width, 0, inputimg, resize.lanczos3)
// encode the output image as png and write it to a buffer.
newbuffer := new(bytes.buffer)
err = png.encode(newbuffer, outputimg)
if err != nil {
return nil, err
}
// return the compressed image as a byte slice.
return newbuffer.bytes(), nil
}
chatgpt输出的代码块如下:
func testcompresspicture(t *testing.t) {
// setup test data
imgdata, err := os.readfile("test-image.png")
if err != nil {
t.fatalf("failed to read test image file: %v", err)
}
testcases := []struct {
name string
width uint
}{
{"compress with a valid width", 500},
{"compress with an invalid width", 0},
}
for _, tc := range testcases {
t.run(tc.name, func(t *testing.t) {
// invoke the function being tested.
compresseddata, err := compresspicture(imgdata, tc.width)
// check the result.
if err != nil {
t.fatalf("unexpected error: %v", err)
}
if len(compresseddata) == 0 {
t.fatalf("compressed data is empty")
}
create, err := os.create("test-image-compressed.png")
if err != nil {
return
}
defer create.close()
_, err = create.write(compresseddata)
})
}
}
放到ide里,完美运行,说明简单函数的单元测试生成还是很强的~
part2 normal :里面有一些外部import
有外部定义引入的时候,最好把外部定义直接贴上(不涉及mock)。
这里举例的函数出现了外部依赖 entity.archivewithdata等定义,所以最好要加上外部定义在输入中:
写下列代码中convertarchivewithdatatobottextmsg函数的单测,要求覆盖全部逻辑。
断言使用require包。
测试用例以testcases的形式输出。
// convertarchivewithdatatobottextmsg 将画作稿件信息转换为企微机器人文本消息
func convertarchivewithdatatobottextmsg(data *entity.archivewithdata) *entity.botmsgreq {
var mentionedlist []string
proxyurl := data.info.urls.original
rawpixivurl := fmt.sprintf("https://www.pixiv.net/artworks/%d", data.info.pid)
txt := &entity.bottext{
content: fmt.sprintf("proxy图源:%s\npixiv图源:%s", proxyurl, rawpixivurl),
mentionedlist: mentionedlist,
}
posttext := &entity.botmsgreq{
msgtype: entity.botmsgtext,
text: txt,
}
return posttext
}
一些导入的定义如下:
type bottext struct {
content string `json:"content"`
mentionedlist []string `json:"mentioned_list"`
}
type botmsgreq struct {
msgtype botmsgtype `json:"msgtype"`
text *bottext `json:"text,omitempty"`
}
const (
botmsgtext botmsgtype = "text"
)
type archivewithdata struct {
info archive
data []byte
}
下面是生成的代码,经过少量修改后可以直接运行:(因为少输入了一个结构体的定义,导致它猜测了一些字段)
func test_convertarchivewithdatatobottextmsg(t *testing.t) {
testcases := []struct {
name string
data *entity.archivewithdata
expected *entity.botmsgreq
}{
{
name: "regular data",
data: &entity.archivewithdata{
info: entity.archive{
pid: 123456,
urls: entity.picurl{
original: "https://example.com/image.jpg",
},
},
data: []byte{},
},
expected: &entity.botmsgreq{
msgtype: entity.botmsgtext,
text: &entity.bottext{
content: "proxy图源:https://example.com/image.jpg\npixiv图源:https://www.pixiv.net/artworks/123456",
},
},
},
{
name: "data with special characters",
data: &entity.archivewithdata{
info: entity.archive{
pid: 789012,
urls: entity.picurl{
original: "https://example.com/image(with)special&characters.jpg",
},
},
data: []byte{},
},
expected: &entity.botmsgreq{
msgtype: entity.botmsgtext,
text: &entity.bottext{
content: "proxy图源:https://example.com/image(with)special&characters.jpg\npixiv图源:https://www.pixiv.net/artworks/789012",
},
},
},
}
for _, tc := range testcases {
t.run(tc.name, func(t *testing.t) {
result := convertarchivewithdatatobottextmsg(tc.data)
require.equal(t, tc.expected, result)
})
}
}
part3 hard:对外部repo进行mock(gomock举例)
外部依赖越多,prompt template的构建可能就越复杂
ps.实际上gomonkey它也可以写
外部依赖repo的部分,要求gpt使用gomock进行对应repo的mock即可。
外部定义最好进行剪枝。
输入:
写下列代码中getsetudescslice函数的单测,要求覆盖全部逻辑。
断言使用require包。
测试用例以testcases的形式输出。
对于m.reposetu.getarchiveinfoslice的调用,使用gomock进行mock处理,假设已经有mock文件。
func (m *crontab) getsetudescslice(ctx context.context, setuconfig config.setuconfig) (entity.queryresult, error) {
queryresslice, err := m.reposetu.getarchiveinfoslice(ctx, &entity.query{
r18: setuconfig.r18,
num: 1,
tag: setuconfig.tags,
size: setuconfig.picsize,
proxy: setuconfig.proxy,
})
if err != nil {
return entity.queryresult{}, err
}
return queryresslice, nil
}
下面是外部依赖的定义:
type setuconfig struct {
setuapiurl string `yaml:"setu_api_url"`
qwauth []string `yaml:"qw_auth"`
cronstr string `yaml:"cron_str"`
r18 int64 `yaml:"r_18"`
tags []string `yaml:"tags"`
picsize []string `yaml:"pic_size"`
proxy string `yaml:"proxy"`
}
// queryresult 请求结果
type queryresult struct {
error string `json:"error"`
archiveslice []archive `json:"data"`
//picpaths []string
}
输出:
假设已经有mock文件:
// mock_reposetu 是通过mockgen自动生成的,用于模拟reposetu接口的mock文件
func testcrontab_getsetudescslice(t *testing.t) {
testcases := []struct{
name string
setuconfig config.setuconfig
getarchiveinfosliceres entity.queryresult
getarchiveinfosliceerr error
wanterr bool
}{
{
name: "success",
setuconfig: config.setuconfig{
r18: 0,
tags: []string{"tag1", "tag2"},
picsize: []string{"large"},
proxy: "",
},
getarchiveinfosliceres: entity.queryresult{
archiveslice: []entity.archive{
{
urls: []string{"pic1.url", "pic2.url"},
title: "pic1",
artists: []string{"artist1"},
},
},
},
getarchiveinfosliceerr: nil,
wanterr: false,
},
{
name: "error",
setuconfig: config.setuconfig{
r18: 1,
tags: []string{"tag3"},
picsize: []string{"small", "medium"},
proxy: "",
},
getarchiveinfosliceres: entity.queryresult{},
getarchiveinfosliceerr: errors.new("get archive info slice error"),
wanterr: true,
},
}
for _, tc := range testcases {
t.run(tc.name, func(t *testing.t) {
ctx := context.background()
// 创建mock对象
mockreposetu := mock_reposetu.newmockreposetu(ctrl)
m := &crontab{reposetu: mockreposetu}
// 设置mock对象返回值
mockreposetu.expect().getarchiveinfoslice(ctx, &entity.query{
r18: tc.setuconfig.r18,
num: 1,
tag: tc.setuconfig.tags,
size: tc.setuconfig.picsize,
proxy: tc.setuconfig.proxy,
}).return(tc.getarchiveinfosliceres, tc.getarchiveinfosliceerr)
res, err := m.getsetudescslice(ctx, tc.setuconfig)
if tc.wanterr {
require.error(t, err)
} else {
require.noerror(t, err)
require.equal(t, tc.getarchiveinfosliceres, res)
}
})
}
}
测试用例解释:
测试用例"success"模拟了getsetudescslice调用成功的情况,
设置查询条件r18=0,tags="tag1", "tag2",picsize="large",期望返回多条图片信息;
测试用例"error"模拟了getsetudescslice调用失败的情况,
设置查询条件r18=1,tags="tag3",picsize="small", "medium",期望返回错误信息。
生成的代码太长,几点总结:
- gomock代码可以正常生成,但是外部repo定义最好清晰明了,可以直接把interface定义贴上去,会被认知到。
- 粘贴到ide中,发现主要问题是包名导入问题,简单修改即可
生成的代码有一些报错:
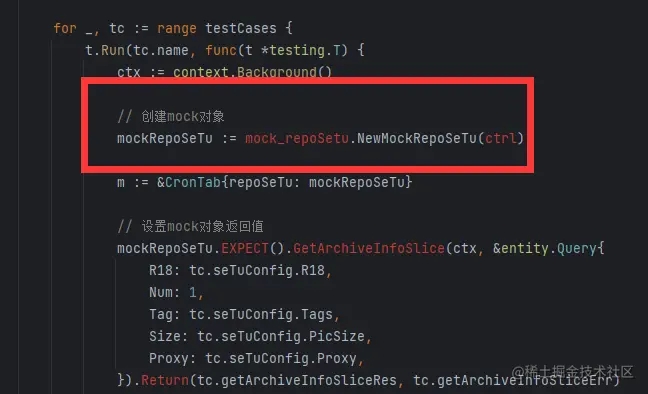
修改引入的类型名后即可:
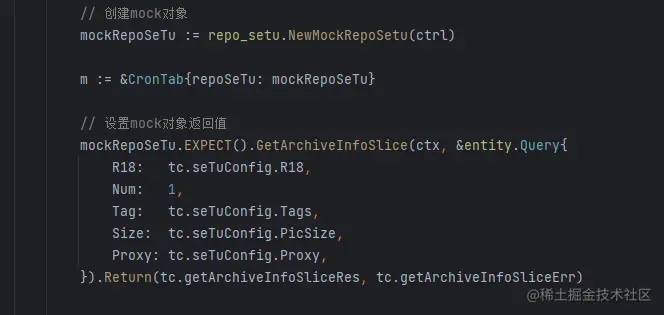
修改后运行成功:
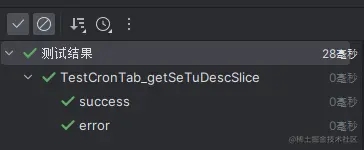
如果需要生成后人工修改量更低的话,需要更精确的上下文信息(包名、函数定义、描述等)
一些痛点
- chatgpt单次对话有长度限制,所以一次尽量只进行一个函数的单元测试生成。
- 需要外部 repo mock的待测函数,需要的上下文很多,并且引入的无关字段需要剪枝避免污染输入
- 一些复杂的私有包,看起来是比较不好支持的(尝试过在prompt中教会他,但是效果不好)
- 一些复杂逻辑和边界情况,ai可能口是心非(写的用例和表述不一致,比如经典的20%*20%=400%,但是他知道这是错的)
- 对于分层不是很清晰的项目,对函数/repo打桩可能很困难,这个时候要描述清楚就比较困难了,gomonkey可能比较适用
其他用法
- 写好测试方法,让gpt帮助扩充用例集
- code review,下面的代码就是gpt给出的代码建议
帮我优化下面的代码
// piccompress modify size to compress pictures.
func piccompress(picdata []byte) (newpicdata []byte, err error) {
oldbuf := bytes.newbuffer(picdata)
pic, _, err := image.decode(oldbuf)
if err != nil {
return
}
newpic := resize.resize(uint(pic.bounds().dx()/2), 0, pic, resize.lanczos3)
var newbuf bytes.buffer
err = png.encode(&newbuf, newpic)
if err != nil {
return
}
newpicdata, err = ioutil.readall(&newbuf)
if err != nil {
return
}
return
}
您好!下面是一个优化版的代码,主要改进在于:
减少对象的创建,避免额外的内存分配和垃圾回收。
增加错误检查,避免可能的错误被忽略。
以下是优化版代码:
// piccompress modify size to compress pictures.
func piccompress(picdata []byte) ([]byte, error) {
reader := bytes.newreader(picdata)
pic, _, err := image.decode(reader)
if err != nil {
return nil, err
}
newpic := resize.resize(uint(pic.bounds().dx()/2), 0, pic, resize.lanczos3)
var writer bytes.buffer
err = png.encode(&writer, newpic)
if err != nil {
return nil, err
}
return writer.bytes(), nil
}
尝试减少了对象的创建,使用了 bytes.reader 代替了 bytes.newbuffer 和 ioutil.readall。
在处理图片过程中,使用 bytes.buffer 代替了 newbuf 这个额外的对象。
同时也将函数的返回值简化,只返回处理后的 []byte 和可能的错误,避免了空值的返回。最后,增加错误检查,保证代码健壮性。以上就是golang使用chatgpt生成单元测试实践的详细内容,更多关于golang chatgpt单元测试的资料请关注代码网其它相关文章!





发表评论