一、初识describe()函数
在数据分析和处理的过程中,我们经常需要了解数据的基本统计信息,如均值、标准差、最小值、最大值等。pandas库中的describe()函数为我们提供了这样的功能,它可以快速生成数据集的描述性统计信息。
二、describe()函数的基本用法
describe()函数是pandas库中dataframe和series对象的一个方法,它默认返回以下统计信息:
count:非空值的数量mean:平均值std:标准差min:最小值25%:第一四分位数(q1)50%:第二四分位数(中位数,q2)75%:第三四分位数(q3)max:最大值
使用示例:
import pandas as pd
# 创建一个简单的dataframe
data = {
'a': [1, 2, 3, 4, 5],
'b': [5, 4, 3, 2, 1],
'c': [10, 20, 30, 40, 50]
}
df = pd.dataframe(data)
# 使用describe()函数
description = df.describe()
print(description)输出:
a b c
count 5.000000 5.000000 5.000000
mean 3.000000 3.000000 30.000000
std 1.581139 1.581139 15.811388
min 1.000000 1.000000 10.000000
25% 2.000000 2.000000 20.000000
50% 3.000000 3.000000 30.000000
75% 4.000000 4.000000 40.000000
max 5.000000 5.000000 50.000000
三、定制describe()函数的输出
describe()函数提供了多个参数,允许我们定制输出的统计信息。
percentiles:指定要包括的其他百分位数,例如percentiles=[.25, .5, .75]将返回第一、第二和第三四分位数。include:指定要包括的数据类型,默认为'all',可以设置为'all','nums', 或'object'。exclude:指定要排除的数据类型。
使用示例:
import pandas as pd
# 创建一个简单的dataframe
data = {
'a': [1, 2, 3, 4, 5],
'b': [5, 4, 3, 2, 1],
'c': [10, 20, 30, 40, 50]
}
df = pd.dataframe(data)
# 使用describe()函数定制输出
custom_description = df.describe(percentiles=[.30, .60, .90])
print(custom_description)输出:
a b c
count 5.000000 5.000000 5.000000
mean 3.000000 3.000000 30.000000
std 1.581139 1.581139 15.811388
min 1.000000 1.000000 10.000000
30% 2.200000 2.200000 22.000000
50% 3.000000 3.000000 30.000000
60% 3.400000 3.400000 34.000000
90% 4.600000 4.600000 46.000000
max 5.000000 5.000000 50.000000
四、describe()函数与数据可视化
describe()函数输出的统计信息经常与数据可视化结合使用,以更直观地了解数据的分布。例如,我们可以使用matplotlib库来绘制箱线图(boxplot)。
使用示例:
import pandas as pd
from matplotlib import pyplot as plt
# 创建一个简单的dataframe
data = {
'a': [1, 2, 3, 4, 5],
'b': [5, 4, 3, 2, 1],
'c': [10, 20, 30, 40, 50]
}
df = pd.dataframe(data)
# 使用describe()函数定制输出
custom_description = df.describe(percentiles=[.30, .60, .90])
print(custom_description)
# 绘制箱线图
df.boxplot()
plt.show()效果展示:
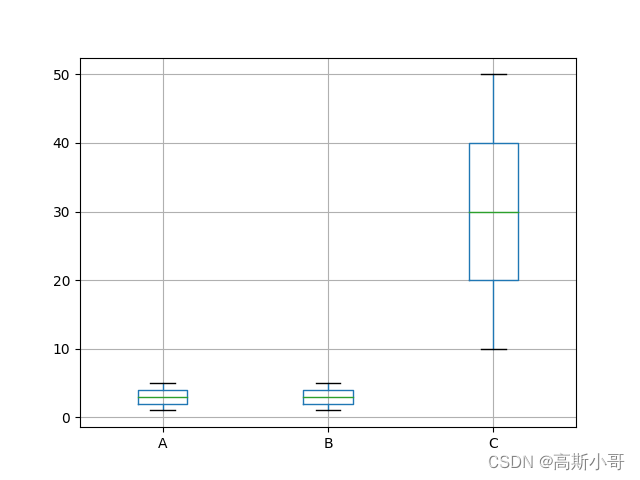
五、深入理解统计指标
了解describe()函数输出的统计指标对于正确解读数据至关重要。例如,标准差可以告诉我们数据集的离散程度,中位数则可以告诉我们数据集的中心趋势,而不受极端值的影响。
六、总结与进阶学习
describe()函数是pandas库中非常实用的一个函数,它可以帮助我们快速了解数据集的基本统计信息。通过定制输出、结合数据可视化以及深入理解统计指标,我们可以更好地分析和处理数据。在进阶学习中,你还可以探索其他与describe()函数相关的统计方法和可视化工具,以提高你的数据处理和分析能力。
希望这篇博客能帮助你更好地理解和使用pandas中的describe()函数!
到此这篇关于python pandas describe()函数的使用介绍的文章就介绍到这了,更多相关python pandas describe()函数内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论