一.正则表达式概述
1.正则表达式定义
1.1 定义
- 使用字符串描述、匹配一系列符合某个规则的字符串
1.2 了解
- 普通字符: 大小写字母、数字、标点符号及一些其它符号
- 元字符: 在正则表达式中具有特殊意义的专用字符
1.3 层次分类
- 基础正则表达式
- 扩展正则表达式
- 编程语言支持的高级正则表达式
1.4 linux三剑客(grep sed awk)支持的正则表达式
- shell是不支持正则表达式的(shell支持的是通配符)。shell中的正则表达式只有个别命令支持的,一般常用的是linux三剑客
| 支持正则的shell命令 | 正则类型 |
|---|---|
| grep | 默认使用基本正则表达式(bre)(要使用扩展正则需要加转义字符) |
| egrep 或 grep -e | 使用扩展的正则表达式(ere) |
| sed | 默认使用基本正则表达式(bre) |
| awk | 使用扩展正则表达式(ere) |
2.基础正则表达式的元字符
基础正则表达式是常用的正则表达式部分
| \ | 表示转义字符,去掉特殊符号的特殊含义 |
| . | 匹配任意单个字符 |
| ^ | 匹配字符串开头的位置 |
| $ | 匹配字符串末尾的位置 |
| * | 匹配前面的字符出现0~+∞ |
| [list] | 匹配list列表中的一个字符(列表中只要有一个符合即可) |
| [^list] | 匹配任意非list列表中的一个字符 |
| {n} | 匹配前面的子表达式n次 |
| {n,} | 匹配前面的子表达式最少n次 |
| {,n} | 匹配前面的子表达式最多n次 |
| {n,m} | 匹配前面的子表达式n到m次 |
| [ ] | 代表单个字符 |
| \? | 1次或0次 |
| ^$ | 空行 |
| .* | 1~+∞ |
2.1 转义字符的运用
2.1.1 将特殊含义的字符转换为普通字符的含义
| 被转义的特殊字符 | 转义前的含义作用 |
| \ = | 具有赋值的作用,或则进行字符判断 |
| \ ! | 取反 |
| \ & | 单个&符可以将命令挂在后台上,两个是逻辑符号且的作用 |
| \ $ | 取值变量的作用 |
2.1.2 将普通字符转换为特殊作用的字符
| 被赋予新含义的普通字符 | 现在拥有的作用 |
| \n | 换行 |
| \t | 转化为制表符 |
| \w(小写) | 匹配包括下划线的任何单词字符 |
| \w(大写) | 匹配任何非单词字符。等通于"[^a-za-z0-9_]" |
| \r | 转换后是回车符 |
| \d | 匹配一个数字字符 |
| \d | 匹配一个非数字字符。等价于[^0-9] |
| \s(小写) | 空白符 |
| \s(大写) | 非空白符 |
2.1.3 中括号表达式
普通中括号包围的字符组,表示某个单个字符匹配中括号内的任意字符即匹配成功
- x[abc]z : 可以匹配包含“xaz”、“xbz”、“xcz”的字符串
- 取反表示法: 中括号内开头使用 ^ ,表示只要不是中括号内的字符就匹配
x[ ^abc]z : 可以匹配包含 “xdz”、“xez” 等字符串,但不能匹配包含“xaz”、“xbz”、“xcz”的字符串
特殊元字符在中括号中匹配
- 想要在中括号中匹配: ^ ,需要将其放在 中括号非开头的位置 ,如:[a^]
- 想要在中括号中匹配: - ,需要将其放在 开头位置或结尾位置 ,如:[abc-]、[-abc]
- 想要在中括号中匹配: ] ,需要将其放在 开头位置 ,如:[]abc]
2.1.4 位置匹配
只匹配字符,不匹配字符
- ^ : 匹配行首
- $ : 匹配行尾
- \b 匹配单词边界处的位置(开头和结尾) \bword\b 等价于 \<word\>
- \< 匹配单词开头处的位置
- \> 匹配单词结尾处的位置
- \b 匹配非单词边界处的位置
2.1.5 字符类
| [:alnum:] | 字母和数字 |
| [:alpha:] | 代表任何英文大小写字母 a-z a-z |
| [:lower:] | 小写字母 |
| [:upper:] | 大写字母 |
| [:blank:] | 空白字符 |
| [:space:] | 包括空格、制表符 (水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围广 |
| [:cntrl:] | 不可打印的控制字符(退格、删除、警铃...) |
| [:digit:] | 十进制数字 |
| [:xdigit:] | 十六进制数字 |
| [:graph:] | 可打印的非空白字符 |
| [:print:] | 可打印字符 |
| [:punct:] | 标点符号 |
2.1.6 量词
\{m\} : 表示匹配前一个字符或前一个子表达式m次
\{m,n\} : (m<n)表示匹配前一个字符或前一个字表达式最少m次,最多n次
\{m,\} : 表示匹配前一个字符或前一个子表达式至少m次
\{,n\} : 表示匹配前一个字符或前一个字表达式最多n次(匹配0次也算是成功)
* 表示前一个字符或前一个子表达式匹配0次或多次,等价于:{0,}
- .* 匹配任意长度的任意字符
3.扩展正则表达式的元字符
支持awk和egrep使用,如果grep和sed想要正常使用(grep -e sed -r)
| 元字符 | 作用含义 |
| + | 匹配前面子表达式1次及以上 |
| ? | 匹配前面子表达式0次或者1次 |
| () | 将括号中的字符串作为一个整体 |
| | | 以"或"的方式匹配字符串 |
3.1 扩展常用的量词
- + 表示匹配前一个字符或前一个子表达式1或多次,即至少一次 等价于 {1, }
- ? 表示匹配前一个字符或前一个子表达式0或1次,等价于 {0,1} 等价于 {,1}
3.2 分组捕获和反向引用
使用小括号()包围一部分正则表达式,这部分正则表达式即成为一个分组整体,也称为一个子表达式。
分组后可以使用 \n 来反向引用对应的分组匹配结果,n是1-9的正整数,\1表示第一个分组表达式的匹配结果,\2表达第二个分组表达式的匹配结果。
注意:反向引用引用的是分组匹配后的结果,不是分组表达式
例如:正则表达式:(abc|def) and \1xyz 可以匹配字符串“abc and abcxyz ” 或“def and defxyz”,但是不能匹配“abc and defxyz” 或 “def and abcxyz”
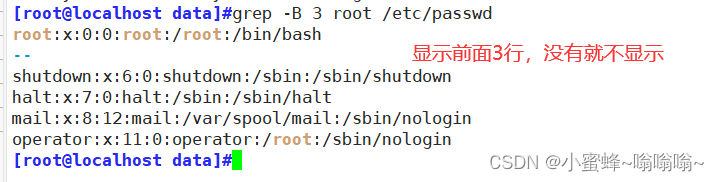
二.grep 命令
1.命令简介
grep 是一种强大的文本搜索工具,它能使用正则表达式,并把匹配的行打印出来
格式:
grep [options] pattern [file] options表示:选项; pattern 表示:匹配的的表达式; file 表示:文件名 例如:grep -i "root" /etc/passwd
2.常用选项
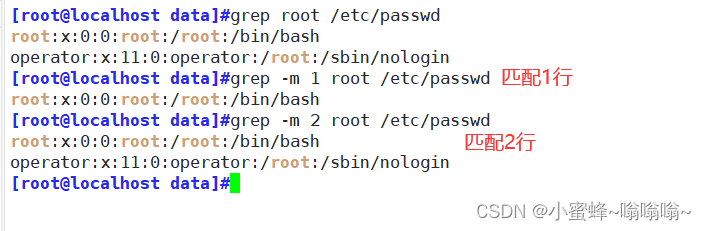
| -m 数字 | 匹配到数字行停止 |
| -v | 取反 |
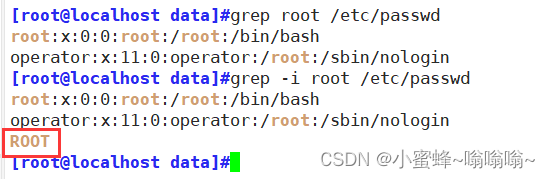
| -i | 忽略字符大小写 |
| -n | 显示匹配的行号 |
| -c | 统计匹配的行数 |
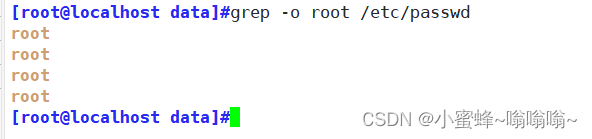
| -o | 仅显示匹配到的字符串 |
| -q | 静默模式,不输出任何信息 |
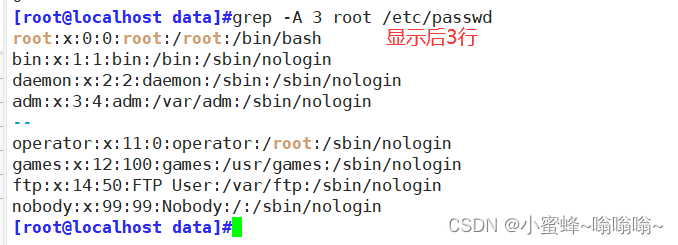
| -a 数字 | after 后数字行 |
| -b 数字 | before 前数字行 |
| -c 数字 | context 前后各数字行 |
| -e | 实现多个选项间的逻辑 or 关系 |
| -e | 使用ere,相当于egrep |
| -w | 匹配整个单词 |
| -f | 不支持正则表达式,相当于fgrep |
| -f | 处理两个文件相同内容,把第一个文件作为匹配条件 |
| -r | 递归目录,但不处理软连接 开始搜索目录 |
| -r | 递归目录,但处理软连接 |
操作:
-m
-i
-n

-c

-o
-q

-a -b -c

-e

-w

-e

扩展正则中这些元字符可直接使用: ? 、 + 、 { 、 } 、 | 、 ( 和 ) 。
基础正则中这些元字符前需要加反斜线转义: \? 、 \+ 、 \{ 、 \} 、 \| 、 \( 和 \) 。
grep sed 默认使用基础正则表达式
grep -e 、 sed -r 、 egrep 、 awk 扩展正则表达式
-r

3.操作
① 统计当前主机的连接状态

② 统计当前连接主机数

③ 匹配qq号

④ 匹配电话号码

⑤ 匹配邮箱

⑥ 统计 /etc/fstab 下面有多少单词

三.sed命令
1.关于sed
1.1 简介
sed 是从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行,直到最后一行。每当处理一行时,把当前处理的行存储在临时缓冲区中,称为模式空间(patternspace),接着用 sed 命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。一次处理一行的设计模式使得 sed 性能很高,sed 在读取大文件时不会出现卡顿的现象。如果使用 vi 命令打开几十m上百m的文件,明显会出现有卡顿的现象,这是因为 vi 命令打开文件是一次性将文件加载到内存,然后再打开。sed 就避免了这种情况,一行一行的处理,打开速度非常快,执行速度也很快。
1.2 sed 编辑器的工作过程
sed 的工作流程主要包括读取、执行和显示三个过程:
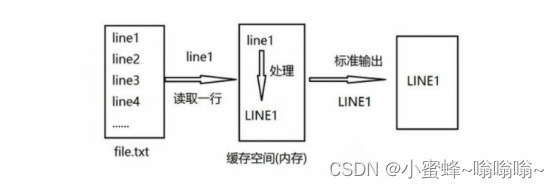
- 读取: sed 从输入流 (文件、管道、标准输入) 中读取一行内容并存储到临时的缓冲区中(又称模式空间,pattern space )。
- 执行: 默认情况下,所有的 sed 命令都在模式空间中顺序地执行,除非指定了行的地址,否则 sed 命令将会在所有的行上依次执行。
- 显示: 发送修改后的内容到输出流。在发送数据后,模式空间将会被清空。在所有的文件内容都被处理完成之前,上述过程将重复执行, 直至所有内容被处理完。
注意:默认情况下所有的 sed 命令都是在模式空间内执行的,因此输入的文件并不会发生任何变化,除非使用 "sed -i" 修改源文件、或使用重定向输出到新的文件中。
1.3 玛玛哈哈
怎么解决 sed 命令处理容量过大,或内容过多而导致执行效率缓慢的问题?
方案一:
使用 split 命令进行文件分割(如果文件是百万行的,那么我们就创建一个单独的目录,将文件分割为一百个一万行的文本),再使用 sed 命令进行处理,除了使用 split 分割,也可以使用一个遍历分割shell脚本进行执行。
方案二:
cat 文件名 | sed 处理 (这个方案只能针对中型的文件文本,如果文本量过大,处理效果不好)
2.sed 命令与选项操作符
1. 格式
sed [option]... 'script;script;...' [input file...]
选项 自身脚本语法 支持标准输入管道2.常用选项
| -e | 用指定命令或者脚本来处理输入的文本文件 只有一个操作命令时省略,一般在执行多个操作命令使用 |
| -f | 用指定的脚本文件来处理输入的文本文件 |
| -n | 不输出模式空间内容到屏幕,即不自动打印 可以与 p 命令一起使用完成输出 |
| -r -e | 使用扩展正则表达式 |
| -h | 显示帮助 |
| -i | 直接修改目标文件 |
| -i.xxx | 备份文件并原处编辑 |
| -s | 将多个文件视为独立文件,而不是单个连续的长文件流 |
3.操作符
“操作”用于指定文件对操作的动作行为,也就是 sed 的命令。
通常情况下是采用的 “[n1[,n2]]” 操作参数的格式。n1、n2是可选的,代表选择进行操作的行数,如操作需要在5~20行之间进行,则表示为 “5,20 动作行为”
| s | 替换,替换指定字符 |
| d | 删除,删除选定的行 |
| a | 增加,在当前行下方增加一行指定内容 |
| i | 插入,在选定行上方插入一行指定内容 |
| c | 替换,将选定行替换为指定内容 |
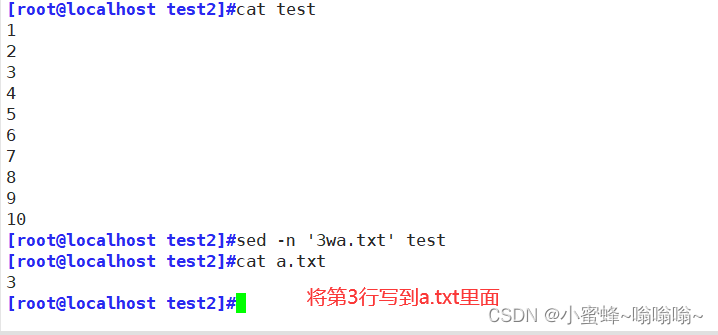
| w | 保存模式匹配的行至指定文件 |
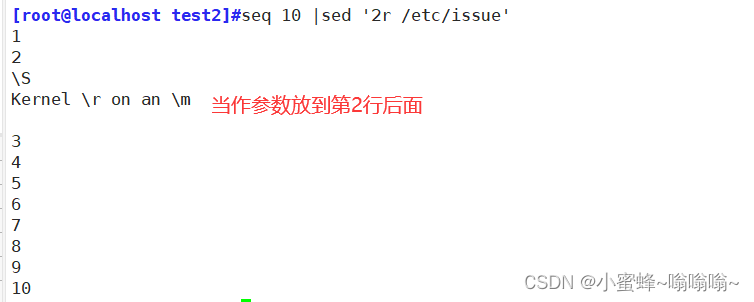
| r | 读取指定文件的文本至模式空间中匹配的行后 |
| y | 字符转换,转换前后的字符长度必须相同 |
| p | 打印行内容。如果同时指定行,表示打印指定行;如果不指定行,则表示打印所有内容;如果有非打印字符,则以ascii码输出。其通常与"-n"选项一起使用 |
| = | 打印行号 |
| l(小写l) | 打印数据流中的文本和不可打印的ascii字符(如结束符$ 制表符\t) |
操作:





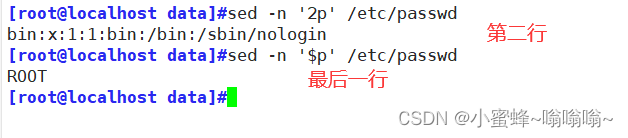
显示第二行内容

4.脚本格式
由 ‘地址+命令’ 组成
- ① 不给地址 对全文进行处理
- ② 单地址
数字 指定的数字行
$ 最后一行
- ③ 地址范围
x,x 从第x行到第x行 3,6 从第3行到第6行
x,+x 从x行到+x行 3,+4 从3行到第7行
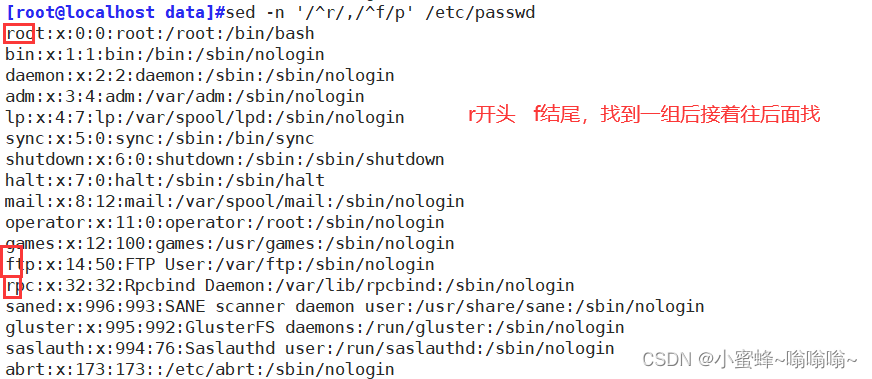
/pat1/,/pat2/ 第一个正则表达式和第二个正则表达式之间的行
- ④ 步进 ~
1~2 奇数行
2~2 偶数行
n;打印下一行

操作:


小问题:
如何打印一段时间间的日志

5.搜索替代
s/pattern/string/修饰符 查找替换,支持使用其它分隔符,可以是其它形式:s@@@,s### 替换修饰符: g 行内全局替换 p 显示替换成功的行 w /path/file 将替换成功的行保存至文件中 & 指代之前找到的内容

指代变量

分组替换
sed -nr 's/正则匹配/\1/p'

还可以变换顺序

操作:
取ip
①

②

或者

提取版本号

提取0644

6.变量
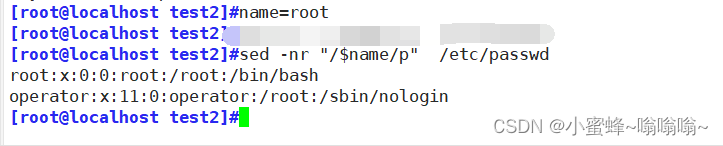

修改端口


修改网卡名

总结
到此这篇关于shell正则表达式、grep命令和sed命令举例详解的文章就介绍到这了,更多相关shell正则表达式grep命令和sed命令内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论