1 用字典的方法去重
- 方法1,用字典去重
- dict1(i) = ""
- 方法2,用字典去重 + 统计次数
- dict2(i) = dict2(i) + 1
- 方法3,用字典报重复,但没去重复
- if not dict3.exists(i) then
sub test_dict1()
dim dict1 as object
set dict1 = createobject("scripting.dictionary")
dim dict2 as object
set dict2 = createobject("scripting.dictionary")
dim dict3 as object
set dict3 = createobject("scripting.dictionary")
arr1 = range("b1:b10")
'去重
for each i in arr1
dict1(i) = ""
next
for each j in dict1.keys()
debug.print j
next
debug.print
'去重 + 统计次数
for each i in arr1
dict2(i) = dict2(i) + 1
next
for each j in dict2.keys()
debug.print j
next
debug.print
for each k in dict2.items()
debug.print k
next
debug.print
for each i in arr1
if not dict3.exists(i) then
dict3.add i, ""
else
debug.print "存在重复值"
exit sub
end if
next
end sub2 用数组的方法去重
2.1 用数组循环的方法,去数组重复也可以
- 双循环
- 关键点1:双循环的目的是,循环拿1个数组,和另外一个循环的所有数做对比
- 关键点2:在外层赋值
- 关键点3:赋值的计数变量得独立,因为不知道有几个非重复数
sub test_arr1()
dim arr2
arr1 = array(1, 2, 3, 4, 5, 1, 2, 3, 1, 2, 1)
redim arr2(ubound(arr1)) '在外面需要1次redim到位
for i = lbound(arr1) to ubound(arr1)
for j = lbound(arr2) to ubound(arr2)
if arr1(i) = arr2(j) then
goto line1
end if
next
arr2(k) = arr1(i)
k = k + 1
line1: next
for each i in arr2
debug.print i
next
end sub2.2 用循环数组方法,判断 每次内部循环,每次是否可以走一个完整循环
- 判断 每次内部循环,每次是否可以走一个完整循环
- 为了配合后面得index选择性的停在ubound+1上,否则都停在ubound+1上没法区分
- array的index指针停在ubound+1就证明内部循环完整走完没有exit for,证明无重复
sub test_arr2()
dim arr2
arr1 = array(1, 2, 3, 4, 5, 1, 2, 3, 1)
redim arr2(lbound(arr1) to ubound(arr1)) '这样也没问题,一般有重复的列肯定更长
'redim arr2(lbound(arr1) to 99999) 这样也可以,就是故意搞1个极大数
k = 0
for i = lbound(arr1) to ubound(arr1)
for j = lbound(arr2) to k
if arr1(i) = arr2(j) then
exit for '为了配合后面得index选择性的停在ubound+1上,否则都停在ubound+1上没法区分
end if
next
if j = k + 1 then 'array的index指针停在ubound+1就证明内部循环完整走完没有exit for,证明无重复
arr2(k) = arr1(i)
k = k + 1
end if
next
debug.print
for each m in arr2
debug.print m;
next
debug.print
end sub2.3用数组的方法查重复次数
2.3.1 用数组的方法查某个目标值的重复次数
sub test001()
'查某个值得重复次数
arr1 = array(1, 2, 3, 4, 5, 1, 2, 3, 6, 7, 8, 9)
target1 = 1
debug.print "arr1的最小index=" & lbound(arr1)
debug.print "arr1的最大index=" & ubound(arr1)
for i = lbound(arr1) to ubound(arr1)
if arr1(i) = target1 then
debug.print target1 & "第" & m & "个" & "index=" & i
end if
next
end sub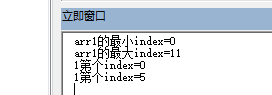
2.3.2 用数组+字典的方法查 每个元素重复次数
查所有元素的次数
sub test002()
'如果用循环方法查每个重复的值的重复次数
arr1 = array(1, 2, 3, 4, 5, 1, 2, 3, 6, 7, 8, 9)
dim dict1 as object
set dict1 = createobject("scripting.dictionary")
debug.print "arr1的最小index=" & lbound(arr1)
debug.print "arr1的最大index=" & ubound(arr1)
arr2 = arr1
for i = lbound(arr1) to ubound(arr1)
m = 1
for j = lbound(arr2) to ubound(arr2)
if arr1(i) = arr2(j) then
dict1(arr1(i)) = m
m = m + 1
end if
next
next
for each i in dict1.keys()
debug.print i & "," & dict1(i)
next
end sub
只查部分元素的重复次数
sub test002()
'如果用循环方法查每个重复的值的重复次数
arr1 = array(1, 2, 3, 4, 5, 1, 2, 3, 6, 7, 8, 9)
dim dict1 as object
set dict1 = createobject("scripting.dictionary")
debug.print "arr1的最小index=" & lbound(arr1)
debug.print "arr1的最大index=" & ubound(arr1)
arr2 = arr1
for i = lbound(arr1) to ubound(arr1)
m = 1
for j = lbound(arr2) to ubound(arr2)
if arr1(i) = arr2(j) then
if m >= 2 then
dict1(arr1(i)) = m
end if
m = m + 1
end if
next
next
for each i in dict1.keys()
debug.print i & "," & dict1(i)
next
end sub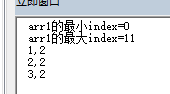
2.3.3 用纯数组的方法查呢?
- 不够好
- 因为还是得先 去重,否则就会如下很愚蠢的显示结果
sub test002()
'如果用循环方法查每个重复的值的重复次数
arr1 = array(1, 2, 3, 4, 5, 1, 2, 3, 6, 7, 8, 9)
debug.print "arr1的最小index=" & lbound(arr1)
debug.print "arr1的最大index=" & ubound(arr1)
arr2 = arr1 '每个元素必然至少重复1次
for i = lbound(arr1) to ubound(arr1)
m = 0
for j = lbound(arr2) to ubound(arr2)
if arr1(i) = arr2(j) then
m = m + 1
end if
next
debug.print arr1(i) & "重复了" & m & "次"
next
end sub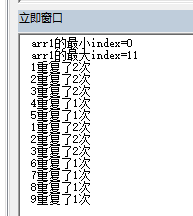
其他方法
没看懂
https://cloud.tencent.com/developer/article/1468729
用collection方法的
https://www.cnblogs.com/sylar-liang/p/5563610.html
到此这篇关于vba数组去重(字典去重多种方法+数组去重2种方法)的文章就介绍到这了,更多相关vba数组去重内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论