一份性能报告
coingecko 于 5 月 17 日发布的 《fastest chains》报告中显示,solana 是大型区块链中速度最快的,最高日均真实 tps 达到 1,504(已经去除了投票交易),sui 是第二快的区块链,最高日均真实 tps 达到 854,bsc 排名第三,但达到的真实 tps 还不到 sui 的一半。
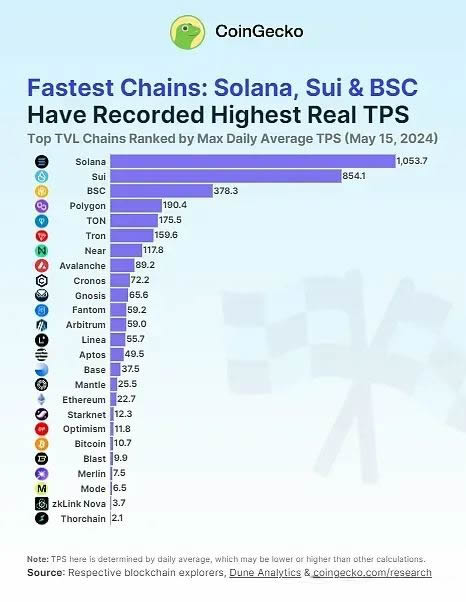
从这份报告可以看出,性能最好的 solana 和 sui 都是非 evm 兼容的区块链,更进一步,8 个非 evm 兼容区块链的平均真实 tps 为 284,17 个 evm 兼容区块链和以太坊 layer2 的平均 tps 仅为 74,非 evm 兼容区块链的性能是 evm 兼容区块链的 4 倍左右。
本文将会探讨 evm 兼容区块链的性能瓶颈,并揭开 solana 的性能之道。
evm 兼容区块链的性能瓶颈

首先,我们泛化 evm 区块链到一般区块链。一般区块链想要提升 tps,一般有如下几种做法:
- 提升节点性能:通过堆硬件资源去提升节点性能,节点的硬件要求会影响去中心化程度,例如以太坊推荐配置,cpu 4 核,内存 16g,网络带宽 25mbps,普通用户级设备都能达到,中心化程度较高;solana 推荐配置相对更高 cpu 32 核,内存 128g,网络带宽 1gbps,专业级设备才能达到,中心化程度一般;
- 改进底层协议:包括网络协议、密码学、存储等,改进区块链底层协议不改变区块链自身的属性,也不影响区块链的运行规则,可以直接提升区块链的性能,但底层技术关注度低,目前研究领域没有重大突破;
- 扩大区块:增加区块的大小可以包含更多的交易,进而提高区块链的交易吞吐量,例如比特币现金(bch)将区块从 1 mb 扩大到 8 mb,之后扩展到 32 mb。但扩大区块的同时也会增大传播延迟引发安全威胁, 比如导致分叉可能性增大和 ddos 攻击;
- 共识协议:共识协议保证了区块链各个节点对于区块链的状态更新达成一致,是区块链最重要的一重安全门,已经用于区块链的共识机制有 pow、pos、pbft 等。为了满足可扩展性的需求,一般高性能公链都会改进共识协议,并结合自身特殊机制,例如 solana 基于 poh 的共识机制,avalanche 基于雪崩的共识机制;
- 交易执行:交易执行只关心单位时间内处理的交易或计算任务数量,以太坊等区块链采用串行方式执行区块中的智能合约交易,在串行执行中,cpu 的性能瓶颈是非常明显的,严重制约了区块链的吞吐量。一般高性能公链都会采用并行执行的方式,有的还会提出更利于并行的语言模型来构建智能合约,例如 sui move。
对于 evm 区块链而言,由于限定了虚拟机,即交易的执行环境,因此最大的挑战在于交易执行。evm 主要有两个性能问题:
- 256 位:evm 设计成一台 256 位的虚拟机,目的是为了更易于处理以太坊的哈希算法,它会明确产生 256 位的输出。然而,实际运行 evm 的计算机则需要把 256 位的字节映射到本地架构来执行,一个 evm 操作码会对应多个本地操作码,从而使得整个系统变得非常低效和不实用;
- 缺少标准库:solidity 中没有标准库,必须自己用 solidity 代码实现,虽然 openzeppelin 使这一情况得到一定改善,他们提供了一个 solidity 实现的标准库(通过将代码包含在合约中或是以 delegatecall 的形式调用部署好的合约),但是 evm 字节码的执行速度远不如预编译好的标准库。
如果站在执行优化的角度,evm 还存在两大不足:
- 难以做静态分析:区块链中的并行执行意味着同时处理不相关的交易,把不相关的交易看作互不影响的事件。实现并行执行主要挑战是确定哪些交易是不相关的,哪些是独立的,目前部分高性能公链会预先对交易做静态分析,evm 的动态跳转(dynamic jumps)机制导致代码很难被静态分析;
- jit 编译器不成熟:jit 编译器(just in time compiler)是现代虚拟机常用的优化手段,jit 最主要的目标是把解释执行变成编译执行。在运行时,虚拟机将热点代码编译成与本地平台相关的机器码,并进行各种层次的优化。目前虽然有 evm jit 的项目,但还处于实验阶段,不够成熟。
因此从虚拟机的选择上,高性能公链更多采用的是基于 wasm, ebpf 字节码或 move 字节码的虚拟机,而非 evm。例如 solana 使用自己独特的虚拟机 svm 和基于 ebpf 的字节码 sbf。
fastest chains:solana

solana 因其 poh(proof of history )机制以及低延迟高吞吐量而闻名,是最著名的「以太坊杀手」之一。
poh 的核心是一个类似于可验证延迟函数(vdf)的简单哈希算法。solana 使用一个序列预映像抵抗的哈希函数(sha-256)实现,该函数持续运行,用一次迭代的输出作为下一次的输入。这个计算在每个验证者的单个核心上运行。
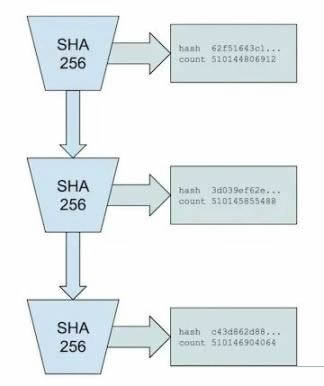
虽然序列生成是顺序和单线程的,但验证可以并行进行,从而在多核系统上实现高效的验证。虽然哈希速度存在上界,但硬件改进可能提供额外的性能提升。
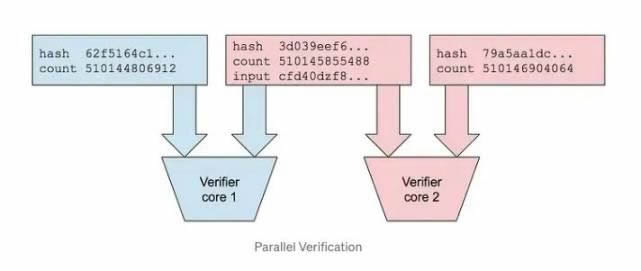
solana 共识流程
poh 机制作为可靠且无需信任的时间源,在网络内创建可验证且有序的事件记录。基于 poh 的计时允许 solana 网络以预定且透明的方式轮换领导者。这种轮换以固定的时间间隔进行,为 4 个槽(slot),每个槽目前设置为 400 毫秒。这种领导者轮换机制确保每个参与的验证者都有公平的机会成为领导者,是 solana 网络维护去中心化和安全的重要机制,防止任何单个验证者在网络上获得过多的权力。
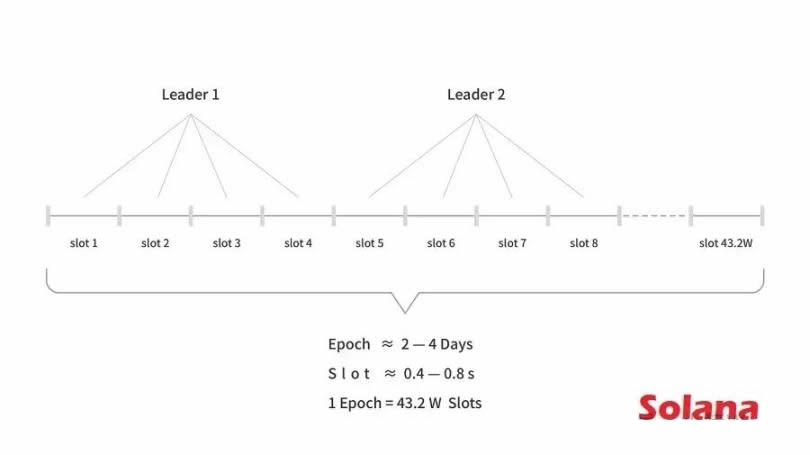
每个槽的时间段,领导者提出一个新块,其中包含从用户收到的交易。领导者验证这些交易,打包成一个区块,然后将该块广播到网络的其余验证者。这种提议和广播区块的过程称为区块生产,网络中的其他验证者必须对区块的有效性进行投票。验证者检查区块的内容,确保交易有效并遵守网络规则。如果一个区块获得了绝大多数权益权重的投票,则该区块被视为已确认。此确认过程对于维护 solana 网络安全和防止双花至关重要。
当前领导者的时间段结束,网络不会停止或等待区块确认,而是会移动到下一个时间段,为后续领导者提供区块生产的机会,整个过程重新开始。这种方法可确保 solana 网络保持高吞吐量并保持弹性,即使某些验证者遇到技术问题或离线也是如此。
solana 性能之道
由于 solana 网络可以提前确认领导者,因此 solana 不需要公共内存池来保存用户的交易。当用户提交交易时,rpc 服务器将其转换为 quic 数据包,并立即将其转发领导者的验证者。这种方法被称为gulf stream,它允许快速的领导者转换和交易的预执行,减少了其他验证者的内存负载。
solana 的区块数据带入到内核空间,然后传递给 gpu 以进行并行签名验证,一旦 gpu 上验证了签名,数据就会传递给 cpu 进行交易执行,最后返回到内核空间做数据持久化。这种将数据划分为不同硬件部件的多个处理过程,称为流水线技术,能最大化硬件利用率,加快区块的验证和传输速度。
由于 solana 的交易显式指定访问哪些账户,solana 的交易调度器可以利用读写锁机制并行执行交易。solana 交易调度器每个线程都有自己管理的队列,顺序且独立地处理交易,尝试锁定(读写锁)交易的账户并执行交易,账户冲突的交易会稍后执行。这种多线程并行执行技术称为 sealevel。
领导者传播区块的过程,将 quic 数据包(可选地使用纠删码)划分为较小的数据包,并将它们分发给具有分层结构的验证者。这种技术称为 turbine,主要是减少领导者的带宽使用。
验证者在投票过程中,使用一种针对分叉投票的共识机制。验证者无需等待投票即可继续进行区块生产;相反,区块生产者会持续监控有效的新投票,并实时将其纳入当前区块中。这种共识机制称为 towerbft,通过实时合并分叉投票,solana 确保了更高效、更精简的共识流程,从而提高了整体性能。
针对区块的持久化过程,solana 开发了 cloudbreak 数据库,通过以特定方式对账户数据结构进行分区,以受益于顺序操作的速度并采用内存映射文件,从而最大限度地提高 ssd 的效率。
为减轻验证者负担,solana 将数据存储从验证者转移到名为 archiver 的节点网络。交易状态的历史记录被拆分为很多碎片,并使用纠删码技术。archiver 用于存储状态的碎片,但不参与共识。
总结
solana 的愿景是成为一个其软件按照硬件的速度扩展的区块链,因此 solana 充分利用当今计算机中可用的所有 cpu、gpu 和带宽能力,以最大化性能,理论最大速度能达到 65,000 tps。
正是因为 solana 的高性能和拓展性,让 solana 成为处理高频交易和复杂智能合约的首选区块链平台,无论是年初的 depin/ai 赛道,还是近期火热的 meme 赛道,solana 都展现出巨大的潜力。
以太坊 etf 推出后,solana 也成为下一个 etf 呼声最大的加密货币,尽管 sec 仍将 solana 列为证券,短时间内不会批准其他加密货币 etf。但在加密市场,共识即价值,solana 的共识或许正变得和比特币与以太坊一样坚不可摧。





发表评论