简介
在视频网站上,每个视频都有一个独特的封面图像,它们通常是吸引人的缩略图,用于代表视频内容。有时候,我们可能需要批量下载许多视频的封面图像,以进行进一步的分析或使用。本篇博客将介绍如何使用python编写一个视频封面批量下载器,使用wxpython图形用户界面库来提供交互界面,以及使用requests和beautifulsoup库来进行网络请求和html解析。
c:\pythoncode\new\youtube-dlcoverbatch.py
步骤
1. 导入所需的库:
- wxpython:用于创建图形用户界面。
- requests:用于发送http请求。
- beautifulsoup:用于解析html内容。
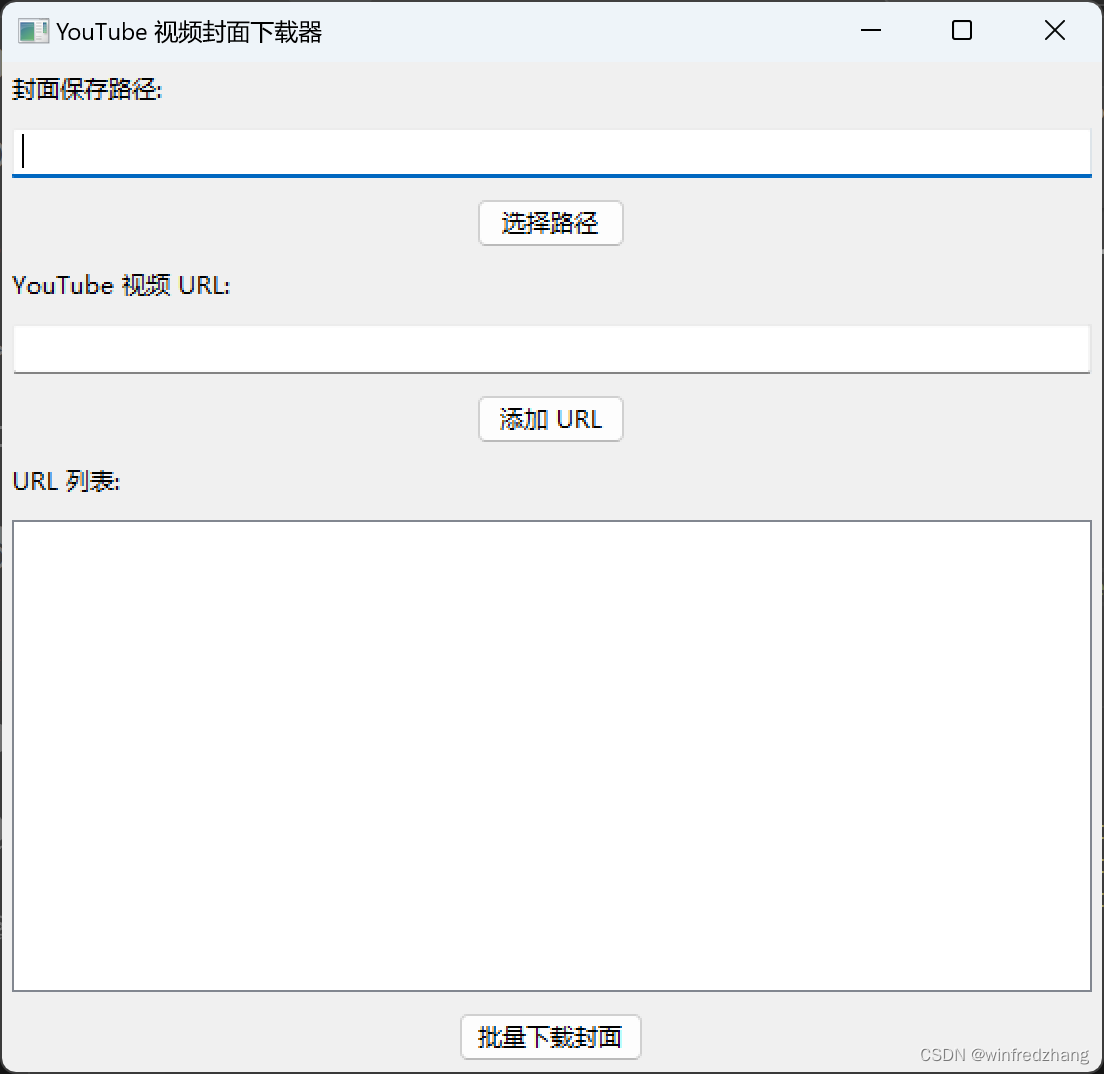
2. 创建一个downloadcoverframe类,继承自wx.frame类,作为主窗口。
- 设置窗口的大小和标题。
- 创建一个面板(panel)并将其添加到窗口中。
- 添加封面保存路径的控件,包括一个文本框和一个选择路径的按钮。
- 添加url输入的控件,包括一个文本框和一个添加url的按钮。
- 添加一个url列表框,用于显示已添加的url。
- 添加一个批量下载按钮,用于触发封面的批量下载操作。
3. 实现事件处理方法:
- on_select_save_path:处理选择路径按钮的点击事件,打开一个目录选择对话框,让用户选择保存封面的路径。
- on_add_url_button:处理添加url按钮的点击事件,将输入的url添加到url列表框中。
- on_download_button:处理批量下载按钮的点击事件,获取保存路径和url列表,遍历url列表,依次下载封面图像并保存到指定路径。
4. 使用beautifulsoup解析html内容:
- 对于每个url,发送http请求获取页面内容。
- 使用beautifulsoup解析页面内容,找到封面图像的url。
- 构造保存路径和文件名。
- 使用requests库下载封面图像并保存到指定路径。
5. 显示结果:
- 使用wxpython的弹窗对话框显示下载结果,包括成功或失败的消息提示。
完整代码
import wx
import requests
from bs4 import beautifulsoup
import os
import datetime
import random
class downloadcoverframe(wx.frame):
def __init__(self, parent, title):
super().__init__(parent, title=title, size=(400, 300))
self.panel = wx.panel(self)
# save path controls
save_path_label = wx.statictext(self.panel, label="封面保存路径:")
self.save_path_text = wx.textctrl(self.panel)
self.save_path_button = wx.button(self.panel, label="选择路径")
self.save_path_button.bind(wx.evt_button, self.on_select_save_path)
# url entry controls
url_label = wx.statictext(self.panel, label="youtube 视频 url:")
self.url_text = wx.textctrl(self.panel)
add_url_button = wx.button(self.panel, label="添加 url")
add_url_button.bind(wx.evt_button, self.on_add_url_button)
# url list control
url_list_label = wx.statictext(self.panel, label="url 列表:")
self.url_listbox = wx.listbox(self.panel)
# download button
download_button = wx.button(self.panel, label="批量下载封面")
download_button.bind(wx.evt_button, self.on_download_button)
# sizer
sizer = wx.boxsizer(wx.vertical)
sizer.add(save_path_label, 0, wx.all, 5)
sizer.add(self.save_path_text, 0, wx.all | wx.expand, 5)
sizer.add(self.save_path_button, 0, wx.all | wx.center, 5)
sizer.add(url_label, 0, wx.all, 5)
sizer.add(self.url_text, 0, wx.all | wx.expand, 5)
sizer.add(add_url_button, 0, wx.all | wx.center, 5)
sizer.add(url_list_label, 0, wx.all, 5)
sizer.add(self.url_listbox, 1, wx.all | wx.expand, 5)
sizer.add(download_button, 0, wx.all | wx.center, 5)
self.panel.setsizer(sizer)
def on_select_save_path(self, event):
dialog = wx.dirdialog(self.panel, "选择封面保存路径")
if dialog.showmodal() == wx.id_ok:
save_path = dialog.getpath()
self.save_path_text.setvalue(save_path)
dialog.destroy()
def on_add_url_button(self, event):
url = self.url_text.getvalue().strip()
if url:
self.url_listbox.append(url)
self.url_text.clear()
def on_download_button(self, event):
save_path = self.save_path_text.getvalue()
if not os.path.exists(save_path):
wx.messagebox("保存路径不存在", "错误", wx.ok | wx.icon_error)
return
urls = self.url_listbox.getstrings()
if not urls:
wx.messagebox("url 列表为空", "错误", wx.ok | wx.icon_error)
return
try:
# current_time = datetime.datetime.now().strftime("%y%m%d%h%m%s%f")
for url in urls:
response = requests.get(url)
soup = beautifulsoup(response.content, "html.parser")
cover_url = soup.find("meta", property="og:image")["content"]
current_time = datetime.datetime.now().strftime("%y%m%d%h%m%s") + str(random.randint(100, 999))
filename = os.path.join(save_path, f"{current_time}.jpg")
with open(filename, "wb") as f:
f.write(requests.get(cover_url).content)
wx.messagebox("封面已批量下载到指定路径", "成功", wx.ok | wx.icon_information)
except exception as e:
wx.messagebox(f"下载封面失败:{e}", "错误", wx.ok | wx.icon_error)
if __name__ == "__main__":
app = wx.app()
frame = downloadcoverframe(none, "youtube 视频封面下载器")
frame.show()
app.mainloop()总结
本篇博客介绍了如何使用python编写一个视频封面批量下载器。通过使用wxpython库创建图形用户界面,可以方便地输入url并选择保存路径。同时,使用requests库发送http请求和beautifulsoup库解析html内容,可以提取封面图像的url并进行下载。这个下载器可以帮助用户快速批量下载视频的封面图像,为后续的分析和使用提供便利。
到此这篇关于使用python实现视频封面批量下载器的文章就介绍到这了,更多相关python视频封面下载内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论