需求
在一些导入功能里,甲方经常会给我们一些格式化的文本,类似 csv 那样的纯文本。比如有关质量监督的标准文件(如国家标准、地方标准、企业标准等),还有一此国际标准文件等等。提供给我们的这些文件是文件尺寸比较大的纯文本文件,文件内容是格式化的文本,具有规律的分隔字符。excel 本身提供有导入文本文件的功能,但由于标准制定和发布是比较频繁,每次的导入与整理还是比较耗时的,因些实现文本文件导入到 excel 的功能可以更快速的解决重复劳动和错误,实现流程自动化的一环。
excel 的文本文件导入功能
我们运行 excel ,点击选择打开文本文件时,会弹出一个导入向导,如下图:
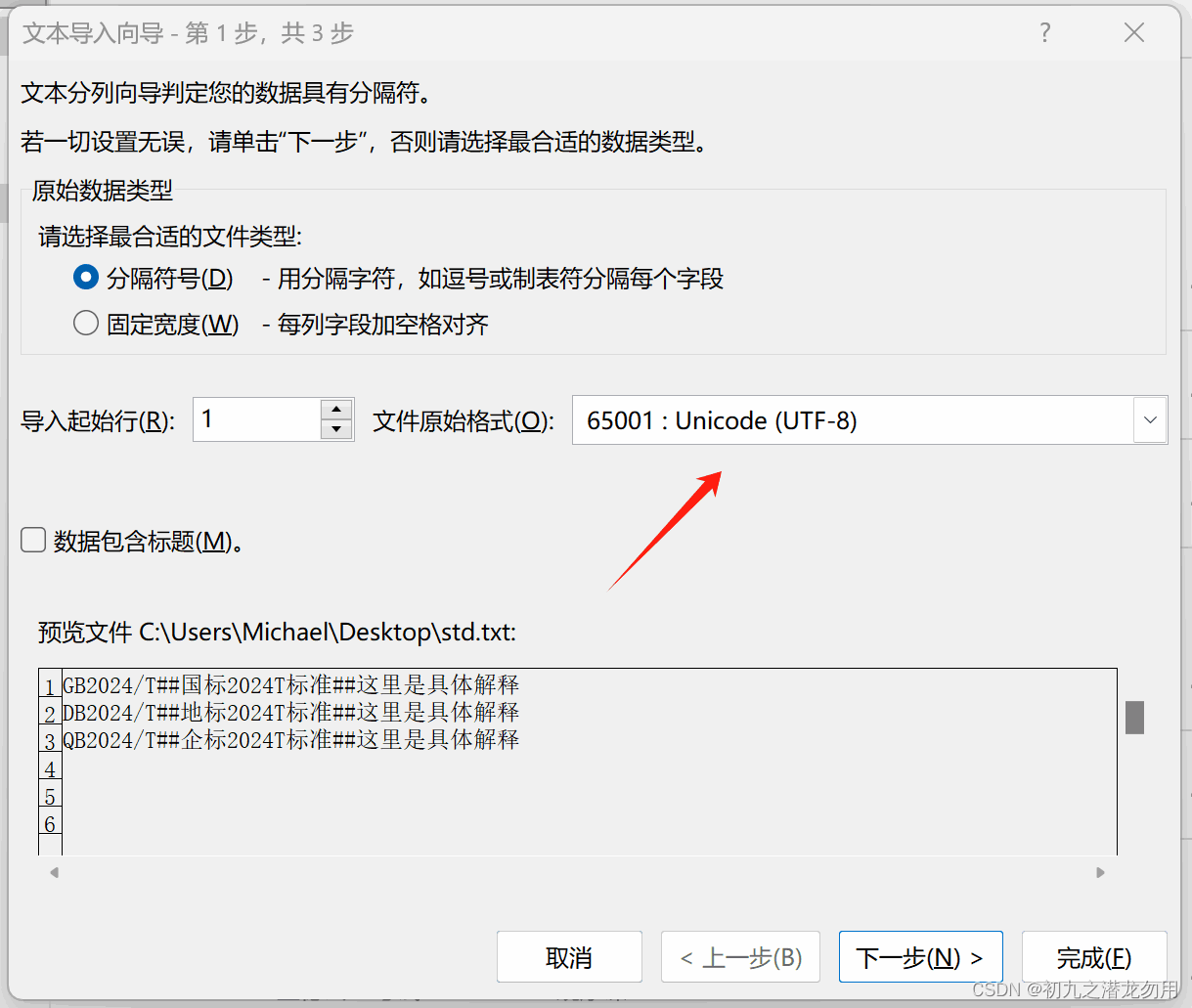
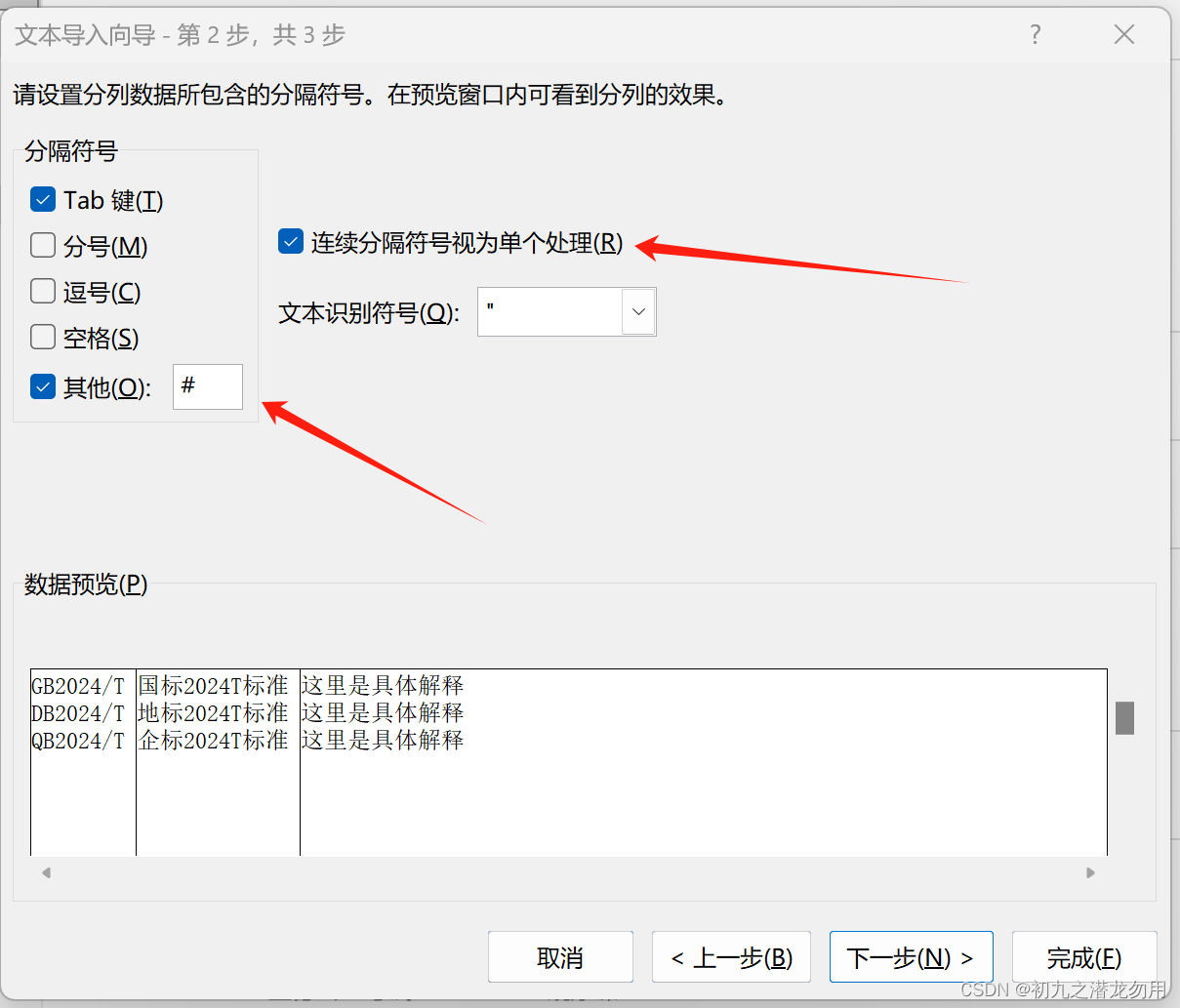
如图我们需要选择合适的文本文件原始编码,输入分隔符,选择其它的选项,如连续的分隔符号视分单个处理等。下面我们将介绍如何利用 com 来实现这一操作的自动化处理。
范例运行环境
操作系统: windows server 2019 datacenter
操作系统上安装 office excel 2016
.net版本: .netframework4.7.1 或以上
开发工具:vs2019 c#
配置office dcom
配置方法可参照我的文章《c# 读取word表格到dataset》进行处理和配置。
实现
组件库引入
opentexttoexcelfile
opentexttoexcelfile方法返回 object[] 类型,object[0] 返回生成成功的 excel 文件地址,object[1]返回错误信息,其实体为 string 类型。方法参数据说明见下表:
| 序号 | 参数 | 类型 | 说明 |
|---|---|---|---|
| 1 | openfile | string | 打开的文本文件的绝对完整路径及名称。 |
| 2 | excelfile | string | 要生成的excel文件完整路径地址。 |
| 3 | splitchar | string | 分隔符 |
| 4 | replacechars | string[,] | 这是一个导入后数据整理型参数。一个二维数组,用于导入后替换相关字符的数组,第一维为查找字符串 ,第二维为要替换的字符串。 |
| 5 | validresult | int | 这是一个检验型参数。指定有效的字段生成数,如果小于1则不进行判断,否则如果生成的最终列数与此值不符,则生成错误信息以示警告。 |
| 6 | extrasplit | bool | 是否允许删除指定的一系列列值。 |
| 7 | esplits | int[] | 当extrasplit为true时,些数据生效,如定义1、6、19列等。这些列的值将在esplits参数数组中定义。esplits数组的指定生效顺序在startcol参数之后 |
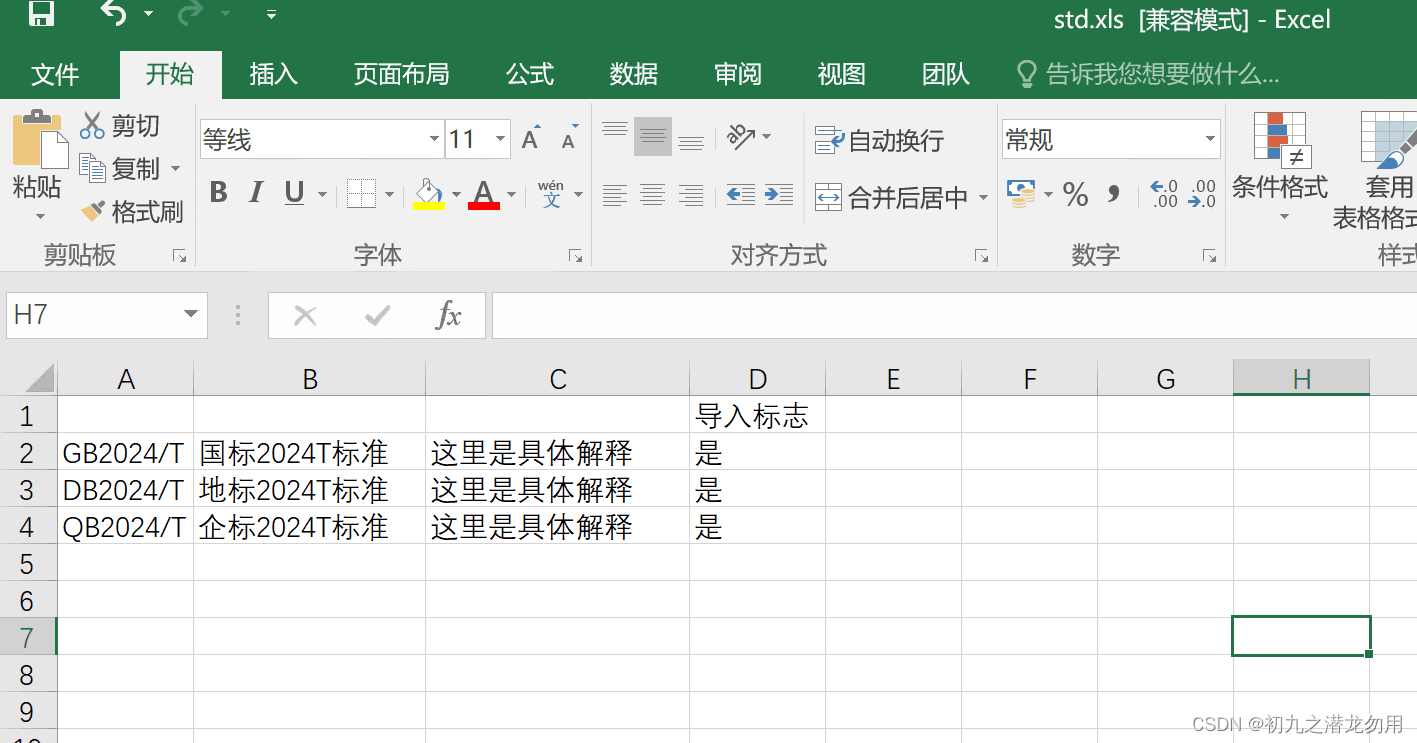
| 8 | addcols | object[,] | 这是一个整理型参数。表示要添加几个固定列及固定值,维度包括3列,如object[0,0] 存储要写入的列id,object[0,1] 存储列id的标题值,object[0,2] 存储列id的值。示例如下: object[0,0]=10; object[0,1]="导入标志"; object[0,2]="是"; |
| 9 | ref_maxcolid | int | 指定在打开文本文件之后应该生成的最大的列,一般这个参数用于最后一列都为空的情况,因为这样excel无法定位最后一个单元格,如果为0则忽略 |
| 10 | startcol | int | 这是一个整理型参数。指定额外的删除列策略,默认值为1,表示不处理,<=0 则表示删除前几列。即 math.abs(startcol) 个,默认步长为 1。 |
| 11 | offerset | int | 与startcol参数配合,默认值为1,表示删除步长。注意:改变此值会影响删除列的个数。 |
| 12 | origin | int | 文本文件的原始编码,默认为 65001,即utf-8 |
| 13 | consecutivedelimiter | bool | 如果为 true,则将连续分隔符视为一个分隔符,如“##” 则视为“#”。 默认值为 false。 |
代码
方法完整代码如下:
/*本方法通过打开一个具有一定分隔格式的文本到excel中,并且由excel进行整理
* openfile参数:打开的文件绝对完整路径及名称。splitchar参数:分隔符。replacechars参数:一个二维数组,用于整理后替换相关字符的数组,第一维为查找字符串
* ,第二维为要替换的字符串。allowtodataset参数:是否允许整理后生成一个dataset对象。validresult参数:指定有效的字段生成数,如果小于1则不进行判断,否则如果
* 生成的最终列数与此值不符,则生成错误信息。startcol参数:指定额外的分隔列策略,大于0为不处理。小于1则表示以最大列加上此值为基准行进行倒序删除,
* 删除位移为offerset参数指定的数值。extrasplit参数:是否指定一系列列值进行删除,这些列可能是无规律的,如1、6、19列等。这些列的值将在esplits参数数组中定义
* 注意esplits数组的指定生效顺序在startcol参数之后,如果startcol参数有效的话。obj_table参数:是否有目标参照表sql语句返回的结果与文本列进行对应
* xmlcfg 文件,如果您有xml配置文件,则可以忽略除openfile以外所有的参数传递,本函数将分析此配置文件的内容,如果分析失败则整个函数将失败
*ref_maxcolid,由用户指定在打开文本文件之后应该生成的最大的列,一般这个参数用于最后一列都为空的情况,因为这样excel无法定位最后一个单元格,如果为0则跳过
*/
public object[] opentexttoexcelfile(string openfile, string splitchar, string[,] replacechars, int validresult, bool extrasplit, int[] esplits, object[,] addcols, int ref_maxcolid, int startcol = 1, int offerset = 1)
{
object[] rv = new object[4];
rv[0] = ""; //存储返回生成的excel文件
rv[1] = ""; //返回错误信息或附加的信息
rv[2] = null;
rv[3] = "";
try
{
//创建excel应用对象
excelapplication excel = new excelapplication();
workbooks workbook = excel.workbooks;
object[,] dlist = new object[ref_maxcolid, 2];
for (int i = 0; i < ref_maxcolid; i++)
{
dlist[i, 0] = i + 1;
dlist[i, 1] = excel.xlcolumndatatype.xltextformat;
}
workbook.opentext(openfile, 20936, 1, excel.xltextparsingtype.xldelimited,
excel.xltextqualifier.xltextqualifierdoublequote, false, false, false, false, false, true, splitchar,
dlist,
type.missing, type.missing, type.missing, type.missing, type.missing);
excel.range _range;
int maxcolid = excel.cells.specialcells(excel.xlcelltype.xlcelltypelastcell, type.missing).column;
if (ref_maxcolid > 0)
{
maxcolid = ref_maxcolid;
}
int maxrowid = excel.cells.specialcells(excel.xlcelltype.xlcelltypelastcell, type.missing).row;
int _addcol = 0;
if (addcols != null)
{
_addcol = addcols.getlength(0);
}
int delcount = 0;
if (startcol <= 0)
{
for (int i = (maxcolid + startcol); i >= 1; i -= offerset)
{
_range = excel.get_range(excel.cells[1, i], excel.cells[65536, i]);
_range.select();
_range.delete(type.missing);
delcount++;
}
}
if ((extrasplit) && (esplits != null))
{
for (int j = 0; j < esplits.getlength(0); j++)
{
int colid = esplits[j];
_range = excel.get_range(excel.cells[1, colid], excel.cells[65536, colid]);
_range.select();
_range.delete(type.missing);
delcount++;
}
}
if ((validresult > 0) && ((maxcolid - delcount + _addcol) != validresult))
{
rv[1] = "生成的最终数据结果与指定的列数目不符合。\r\n用户指定的有效列为:" +
validresult.tostring() + "\r\n系统生成的列:" + (maxcolid - delcount).tostring() + "附加的列:" + _addcol.tostring() +
"\r\n系统检测到的最大列:" + maxcolid.tostring(); //返回错误信息
return rv;
}
//创建模板的映像解析文件,最终以变量 desfilename 为输出对象
fileex commonapi = new fileex();
string _file = "", _path = "";
_path = path.getdirectoryname(openfile);
if (_path.length > 3)
{
_path += "\\";
}
_file = path.getfilenamewithoutextension(openfile);
string _validfilename = commonapi.getvalidfilename(_path, _file, ".xlsx");
string _lastfile = _path + _validfilename;
rv[0] = _lastfile;
if (file.exists(_lastfile))
{
file.delete(_lastfile);
}
worksheet worksheet = (worksheet)excel.activesheet;
//解决替换字符的要求
if (replacechars != null)
{
for (int i = 0; i < replacechars.getlength(0); i++)
{
string _find = replacechars[i, 0], _rep = replacechars[i, 1];
worksheet.cells.replace(_find, _rep, excel.xllookat.xlpart, excel.xlsearchorder.xlbyrows, false, false, false, false);
}
}
_range = excel.get_range(excel.cells[1, 1], excel.cells[1, 1]);
_range.entirerow.insert(type.missing, type.missing);
if (addcols != null)
{
int ref_col = 0;
string ref_fname = "", ref_fvalue = "";
excel.range _newrange;
for (int ad = 0; ad < addcols.getlength(0); ad++)
{
ref_col = (int)addcols[ad, 0];
ref_fname = addcols[ad, 1].tostring();
ref_fvalue = addcols[ad, 2].tostring();
_range = excel.get_range(excel.cells[1, ref_col], excel.cells[1, ref_col]);
_range.entirecolumn.insert(type.missing, type.missing);
// ref_col=_newrange.column;
excel.cells[1, ref_col] = ref_fname;
if (maxrowid > 0)
{
excel.cells[2, ref_col] = ref_fvalue;
_newrange = excel.get_range(excel.cells[2, ref_col], excel.cells[2, ref_col]);
_newrange.copy(excel.get_range(excel.cells[2, ref_col], excel.cells[maxrowid + 1, ref_col]));
}
}
}
worksheet.saveas(@_lastfile, excel.xlfileformat.xladdin, missing.value, missing.value, missing.value, missing.value, missing.value, missing.value, missing.value, missing.value);
excel.activeworkbook.close(false, type.missing, type.missing);
excel.quit();
rv[1] = "准备数据成功,共有记录" + maxrowid.tostring() + "行。字段" + (maxcolid - delcount + _addcol).tostring() + "列。";
}
catch (exception e)
{
rv[0] = "";
rv[1] = e.message;
}
return rv;
}调用
调用示例代码如下:
string splitchar = "#";
int validresult = 4;
int origin = 65001; //utf-8
bool consecutivedelimiter=true; //如果为 true,则将连续分隔符视为一个分隔符,如“##” 则视为“#”
object[,] addcols = new object[1, 3];
addcols[0,0]=4;
addcols[0,1]="导入标志";
addcols[0,2] = "是";
object[] rv2 = opentexttoexcelfile("d:\\std.txt", "d:\\std.xls", splitchar, null, validresult, false, null, addcols, 0, 1, 1, origin, consecutivedelimiter);
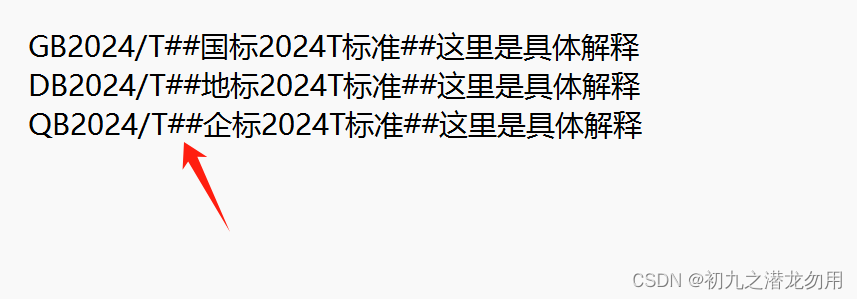
response.write("result:"+rv2[0] + "<br>" + rv2[1]);导入的文本文件示例(以两个#号为分隔符)如下图:
导入成功后如下图所示:
小结
1、opentexttoexcelfile方法是一种兼容旧 excel 版本的写法(如2003),我们可以根据实际需要进行改造。
2、许多参数是根据我们在使用过程中的实际需要而设置,以满足特殊需要,简化后期处理。
3.原始文件的编码请参照本文excel 的文本文件导入功能部分的图示所示,选择框中就是对应的编码代码,如65001表示utf-8,这也是默认值。20936 则表示简体中文(gb2312-80)等等。
到此这篇关于c#实现格式化文本并导入到excel的文章就介绍到这了,更多相关c#格式化文本内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论