背景
在开发中,数据的变更与维护工作一般较频繁。当我们执行数据库的dml操作时,必须谨慎考虑变更对数据可能产生的后果,以及变更是否能够顺利执行。若出现意外数据丢失、操作失误或语法错误等情况,我们必须迅速将数据库恢复到变更之前的状态,以确保数据的一致性和完整性。然而,回滚操作通常需要开发人员手动编写回滚sql脚本,这不仅繁琐复杂,而且极易出错。
为了解决这个问题,odc(oceanbase developer center)v4.2.0支持在执行数据库变更任务时自动生成备份回滚 sql 以提高开发效率、减少错误率,保证数据的一致性和完整性。当单条误操作 sql 受影响的数据量在10万以内时,您可使用该方法进行数据恢复。
功能体验
点击「工单」-> 「新建工单」-> 「数据库变更」,在 odc 的「新建数据库变更」页面中,勾选「生成备份回滚方案」并填写工单详情。
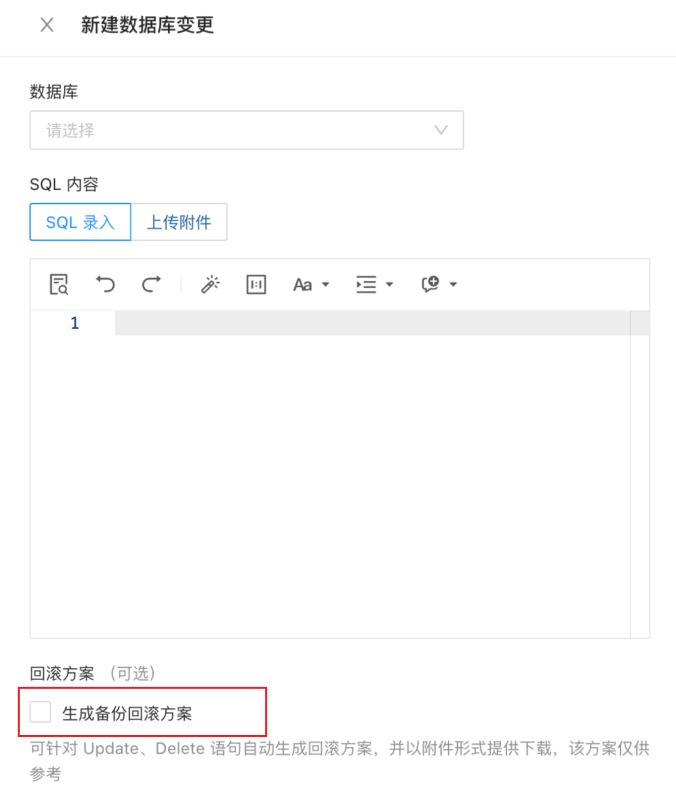
- 点击「新建」后待工单审批通过。
- odc 会根据您填写的「sql内容」生成对应的「备份回滚方案」,您可以在工单的「任务详情」中的「任务信息」页面点击「下载备份回滚方案」以下载 odc 生成的「备份回滚方案」文件:
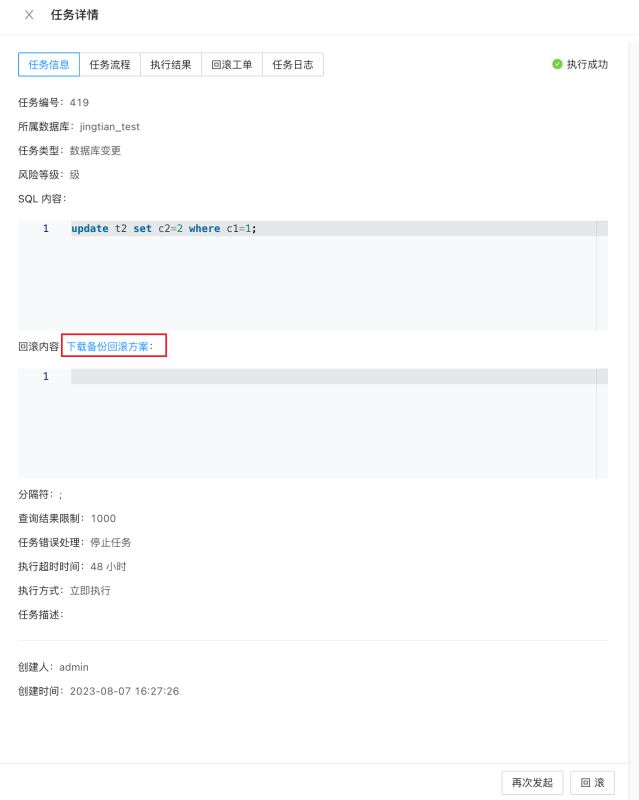
也可以在工单「任务详情」中的「任务流程」中点击「下载备份回滚方案」以下载该文件。
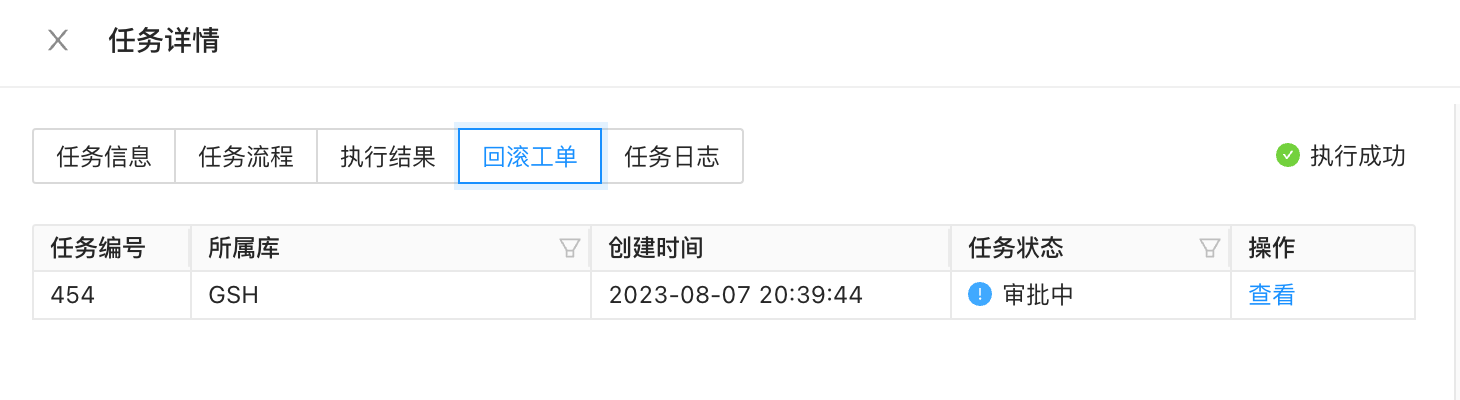
- 如需回滚该工单您可以在此工单的「任务详情」页面的右下脚点击「回滚」重新发起数据库变更工单以申请回滚操作。发起回滚工单后您可以在此工单的「任务详情」中的「回滚工单」页面查看此工单关联的回滚工单。
例如,针对 「sql内容」为以下的数据库变更任务:
update t2 set c2=11 where c1=1; update tab2 set c2=11 where id=1;
生成的「备份回滚方案」示例如下:
/* [sql]: update t2 set c2=11 where c1=1 [query sql]: select t2.* from t2 where c1=1; */ replace into `jingtian_test`.`t2` values (1,11,1); /* [sql]: update tab2 set c2=11 where id=1 [error message]: it is not supported to generate rollback plan for tables without primary key or unique key */
包含以下几部分内容:
- 原始的变更 sql 语句(仅针对 update/delete 语句)。
- 查询原始变更数据的 sql 语句。
- 生成的回滚 sql。
- 若针对一条 update/delete 变更 sql 无法生成回滚 sql,则其原因会显示在
[error message]中。
odc 如何自动生成一条回滚 sql
下面是 odc 根据一条 sql 生成对应的回滚 sql 的流程图:

- sql 解析:通过 sql 解析器遍历 sql 语法树从而将一条 sql 解析为 sql 对象。
- sql 校验:基于 sql 对象校验是符合能够生成对应的回滚 sql 的条件,包括:
- 判断是否是 update/delete sql,odc 仅针对 update/delete 语句生成对应的回滚 sql;
- 若是 ob mysql 模式,判断变更表是否具有主键或唯一建,对于没有主键或唯一键的表执行的变更 sql 不支持生成回滚 sql。
- 基于 sql 对象生成查询原始变更数据的 sql。
- 查询原始变更数据。
- 基于 sql 对象和原始变更数据生成对应的回滚 sql:
- ob mysql 模式针对 update 语句生成 replace into 的回滚 sql;
- ob oracle 模式针对 update 语句生成 delete 语句和 insert into 语句;
- 针对 delete 语句生成 insert into 语句。
接下来详解介绍每一个流程的具体实现。
sql 解析
sql 解析可以理解为对 sql 进行建模,将原始 sql 语句转化为一个 sql 对象。我们根据 sql 的词法和语法文件可以生成 sql 的词法分析器和语法分析器。词法分析阶段将 sql 语句拆解成 token 序列,并识别出关键词、标识、常量等,而语法分析阶段基于词法分析的结果,构造出一棵抽象语法数。例如一条 sql:
update tab1, tab2 set tab1.c2 = 100, tab2.c2=200 where tab1.c1 = tab2.c1;
生成对应的抽象语法树如下图:
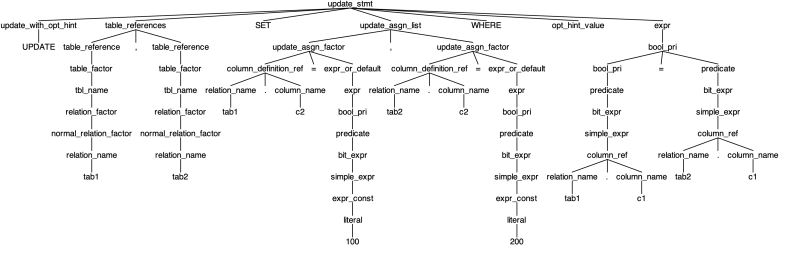
通过遍历语法树将其转化为一个 sql 对象:
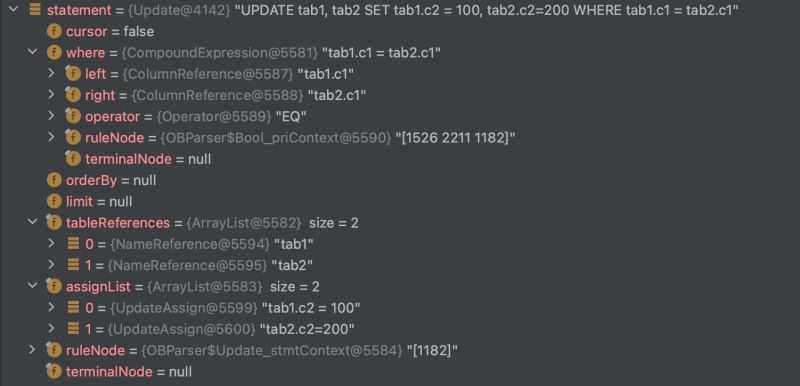
可以看到,这个 sql 对象实际上是将 sql 语句结构化了,对 sql 的各个部分都定义了相应的抽象,比如针对 where 的查询条件我们定义成了 compoundexpression对象。通过将 sql 语句解析成对象,我们就可以围绕这个对象编写生成对应回滚 sql 的处理逻辑。
sql 校验
sql 校验阶段就是基于解析出来的 sql statement 对象去做一些校验的逻辑:
- 判断该 sql 的类型是否是 update/delete 类型。
- 针对 ob mysql 模式,我们需要做格外的校验变更表是否具有主键或者唯一键的逻辑判断。之所以有这个校验逻辑是由于首先后续的批量查询策略逻辑依赖主键/唯一键,其次针对 update 语句生成的回滚 sql 是 replace into,该语句也依赖主键/唯一键。通过 sql 对象我们可以获取到 update 语句的 table_references 对象,我们就基于这个变更的 table 名用以下去查询校验该 table 是否具有主键或者唯一键:
-- 查询主键 show index from table_name where non_unique = 0 and key_name='primary'; -- 查询唯一建 show index from table_name where non_unique = 0;
而针对 ob oracle 模式,我们直接采用 rowid 作为每一张变更表的唯一建,因此不需要有校验变更表是否具有主键或者唯一键的逻辑。
- 校验该变更 sql 是否符合能够生成回滚 sql 的语句。比如如下 sql:
update t1, t2 set col1=2222, col2=333 where t1.c1=t2.c1;
由于 table_references 中涉及多个表,但是 set column_name=... 时没有指明该column_name 的表名,导致我们仅根据这一条 sql 无法直接确认变更的字段属于哪个表,因此该 sql 不符合能够生成回滚 sql 的语句。这种情况只需稍做修改,指明列所属的表就可以支持生成回滚 sql:
update t1, t2 set t1.col1=2222, t2.col2=333 where t1.c1=t2.c1;
查询原始变更数据
如何基于一条 sql 生成对应的查询原始数据的 sql 呢?其实核心逻辑就是基于解析出的 sql 对象和 sql 语句格式去获取我们需要的信息进而拼接出查询 sql。拿 update 语句为例,以下是 ob mysql 的 update 语句的格式:
update [ignore] table_references
set update_asgn_list
[where where_condition]
[order by order_list]
[limit row_count];
table_references:
tbl_name [partition (partition_name,...)] [, ...]
update_asgn_list:
column_name = expr [, ...]
order_list:
column_name [asc|desc] [, column_name [asc|desc]...]简单示例
比如基于以下 sql:
update tab1, tab2 set tab1.c2 = 100, tab2.c2=200 where tab1.c1 = tab2.c1;
通过 sql 解析后基于 sql 对象我们可以获取该 sql statement 的 table_references、update_asgn_list 和 where_condition,通过 update_asgn_list 我们可以知道该 sql 涉及的变更表有2个:tab1 和 tab2,进而我们就可以针对每个变更表生成的查询 sql :
select * from tab1 where tab1.c1 = tab2.c1; select * from tab2 where tab1.c1 = tab2.c1;
当然以上的示例 sql 是一个最简单的例子,复杂一点的场景比如涉及 多表 join 和 子查询 的场景又该怎么生成对应的查询 sql 呢?其实不管 sql 多复杂我们的核心都是基于 sql statement 去拼接出查询 sql。
考虑如下涉及多表 join 的 sql:
update tab1 v1 inner join tab2 v2 inner join tab3 v3 on v1.c1 = v2.c1 and v1.c1=v3.c1 set v1.c2=200, v2.c2=200;
针对这条 sql 我们通过解析 table_references、 update_asgn_list 从而拼接的查询 sql 如下:
select v1.* from tab1 v1 inner join tab2 v2 inner join tab3 v3 on v1.c1 = v2.c1 and v1.c1=v3.c1; select v2.* from tab1 v1 inner join tab2 v2 inner join tab3 v3 on v1.c1 = v2.c1 and v1.c1=v3.c1;
批量查询策略
获取到基于原始 sql 生成的查询 sql 后,我们就可以执行查询 sql 来获取原始数据了。在查询数据的时候可能会遇上这个问题:一次查询出的数据过大,导致内存溢出怎么办?针对这个问题传统的处理方式也有很多,比如通过 limit 分页查询,但是这种方式在我们的场景下不适用,比如如果原始 sql 就带了 limit 那么这种方式就失效了。odc 采用根据表的主键或唯一键(优先采用主键)拼接批量查询 sql 的方式来解决这个问题。
ob mysql 模式
比如我们通过查询 sql 可以获取到表 tab1 的主键列为 c1,如果原始的查询 sql 如下:
select tab1.* from tab1 where c3 > 1;
我们先查询出所有变更行数据的主键值:
select tab1.c1 from tab1 where c3 > 1;
通过以上 sql 我们就可以查询出变更的总行数以及每一行的主键值,若总变更行数为 1500 且设置的批量查询的大小为 1000,也就是每次查询最多获取 1000 行的数据,那么基于以上查询 sql 得到的批量查询 sql 为:
select tab1.* from tab1 where c3 > 1 and c1 in (1,2,3, ..., 1000); select tab1.* from tab1 where c3 > 1 and c1 in (1001,1002,1003, ..., 1500);
这样以来就可以做到批量查询原始变更数据了。由于增加的 where 条件也是走索引的,因此也不存在性能瓶颈问题。
ob oracle 模式
针对 oracle 模式我们直接利用 rowid 来拼接批量查询 sql。比如原始 sql;
select tab1.* from tab1 where c3 > 1;
我们先查询出所有变更行数据的 rowid 值:
select rowid from tab1 where c3 > 1;
那么基于以上查询 sql 得到的批量查询 sql 为:
select tab1.* from tab1 where c3 > 1 and rowid in (...);
生成回滚 sql
通过以上处理逻辑,我们已经获得了原始变更数据,那么接下来就是最后一步基于变更行数据生成回滚 sql 了。
update 语句
ob mysql 模式
针对 ob mysql 模式,update 语句生成的对应回滚 sql 为 replace into 语句,replace into 用于实时覆盖写入数据。写入数据时,会先根据主键或唯一键判断待写入的数据是否已经存在于表中,并根据判断结果选择不同的方式写入数据:
- 如果待写入数据已经存在,则先删除该行数据,然后插入新的数据。
- 如果待写入数据不存在,则直接插入新数据。
这里要求变更表必须有主键或者是唯一索引,否则 replace into 会直接插入数据(等效于 insert into),这可能会导致表中出现重复的数据。
最终 odc 生成的完整的备份回滚 sql 文件如下所示:
/* [sql]: update tab set col2=2 where col=1; [query sql]: select tab.* from tab where col=1; */ replace into `schema_name`.`tab` values (1,1,1);
ob oracle 模式
针对 ob oracle 模式,会先生成 delte 语句来删除变更数据,然后生成 insert into 语句插入原始的变更前的数据,从而避免插入数据时存在主键或者唯一键的冲突。
/* [sql]: update tab1 set c2=2 where c1=1 [query sql]: select tab1.* from tab1 where c1=1; */ delete from tab1 where c1=1; insert into "test"."tab1" values (1,1);
delete 语句
针对 delete 语句,生成的回滚 sql 为 insert into 语句。例如针对以下变更 sql:
delete from tab where col=1;
最终生成的备份回滚文件内容如下:
/* [sql]: delete from tab where col=1; [query sql]: select tab.* from tab where col=1; */ insert into `schema_`.`tab` values (1,1,1);
结语
以上就是oceanbase自动生成回滚sql的全过程(数据库变更时)的详细内容,更多关于oceanbase生成回滚sql的资料请关注代码网其它相关文章!





发表评论